

時間、空間可控的影片生成走進現實,阿里大模型新作VideoComposer火了

在 AI 繪畫領域,阿里提出的 Composer 和史丹佛提出的基於 Stable diffusion 的 ControlNet 引領了可控影像生成的理論發展。但是,業界在可控影片產生的探索依舊處於相對空白的狀態。
相較於影像生成,可控的影片更加複雜,因為除了影片內容的空間的可控性之外,還需要滿足時間維度的可控性。基於此,阿里巴巴和螞蟻集團的研究團隊率先做出嘗試並提出了 VideoComposer,即透過組合式生成範式同時實現影片在時間和空間兩個維度上的可控性。

- #論文網址:https://arxiv.org/abs/2306.02018
- 專案首頁:https://videocomposer.github.io
前段時間,阿里巴巴在魔搭社群和Hugging Face 低調開源了文生影片大模型,意外地受到國內外開發者的廣泛關注,該模型生成的影片甚至得到馬斯克本尊的回應,模型在魔搭社群上連續多天獲得單日上萬次國際訪問量。
Text-to-Video 在推特
VideoComposer 作為該研究團隊的最新成果,又一次受到了國際社區的廣泛關注。


VideoComposer 在推特上
############################################### ############事實上,可控性已經成為視覺內容創作的更高基準,其在客製化的影像生成方面取得了顯著進步,但在影片生成領域仍然具有三大挑戰:######- 複雜的資料結構,產生的影片需同時滿足時間維度上的動態變化的多樣性和時空維度的內容一致性;
- 複雜的引導條件,已存在的可控的視頻生成需要複雜的條件是無法人為手動構建的。例如Runway 提出的Gen-1/2 需要依賴深度序列作條件,其能較好的實現視訊間的結構遷移,但無法很好的解決可控性問題;
- 缺乏運動可控性,運動模式是影片即複雜又抽象的屬性,運動可控性是解決影片生成可控性的必要條件。
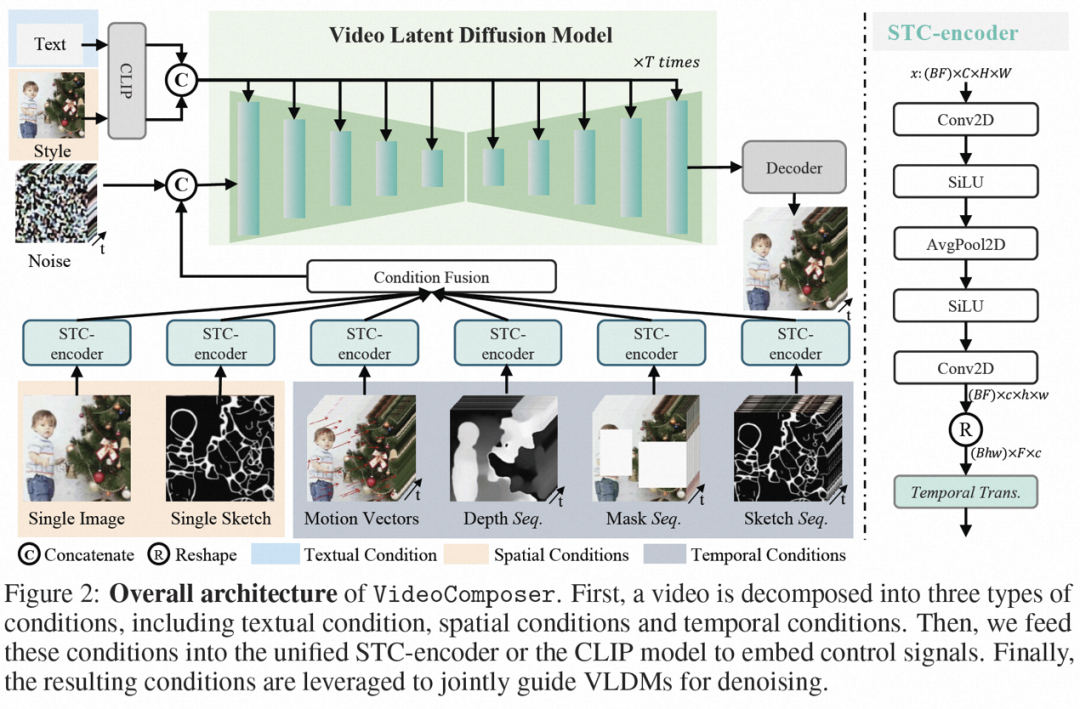
在此之前,阿里巴巴提出的Composer 已經證明了組合性對影像生成可控性的提升具有極大的幫助,而VideoComposer 這項研究同樣是基於組合式生成範式,在解決以上三大挑戰的同時提高影片產生的靈活性。具體是將影片分解成三種引導條件,即文字條件、空間條件、和影片特有的時序條件,然後基於此訓練 Video LDM (Video Latent Diffusion Model)。特別地,其將高效的 Motion Vector 作為重要的顯式的時序條件以學習視訊的運動模式,並設計了一個簡單有效的時空條件編碼器 STC-encoder,保證條件驅動視訊的時空連續性。在推理階段,則可以隨機組合不同的條件來控制影片內容。
實驗結果表明,VideoComposer 能夠靈活控制視頻的時間和空間的模式,例如透過單張圖、手繪圖等生成特定的視頻,甚至可以透過簡單的手繪方向輕鬆控制目標的運動風格。該研究在 9 個不同的經典任務上直接測試 VideoComposer 的性能,兩者都獲得滿意的結果,證明了 VideoComposer 通用性。
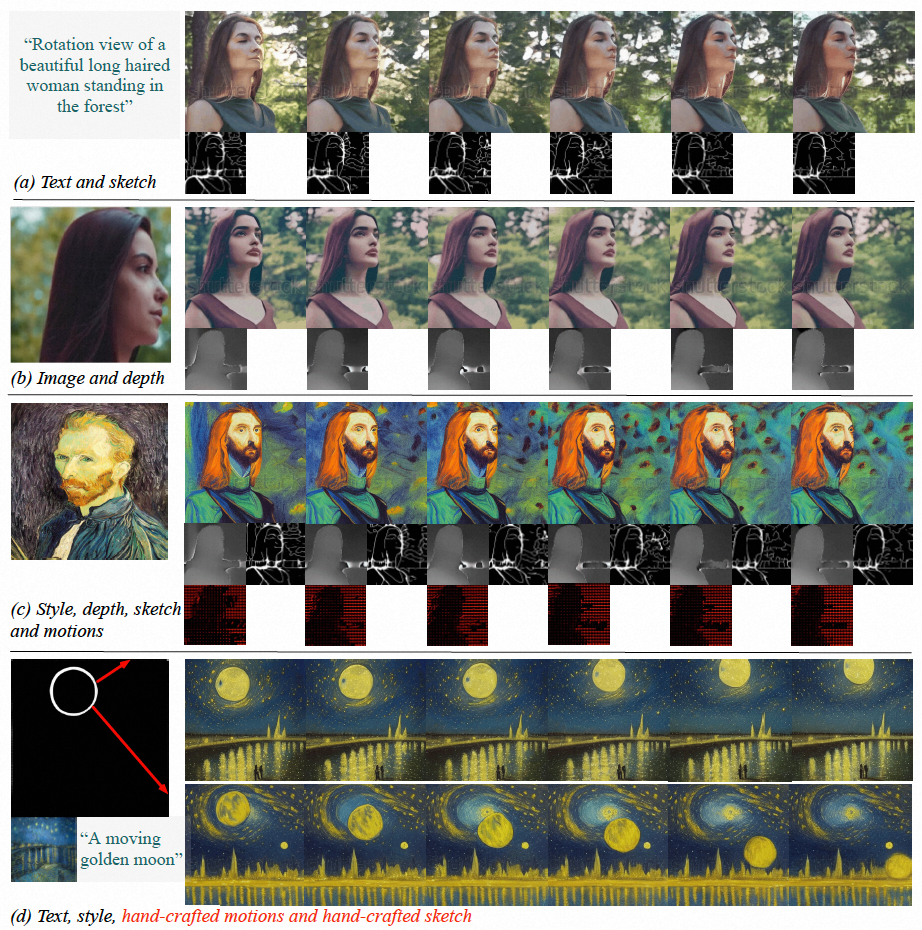
圖(a-c)VideoComposer 能夠產生符合文字、空間和時間條件或其子集的影片;(d )VideoComposer 可以僅利用兩筆畫來生成滿足梵高風格的視頻,同時滿足預期運動模式(紅色筆畫)和形狀模式(白色筆畫)
方法介紹
Video LDM
##隱空間。 Video LDM 首先引入預先訓練的編碼器將輸入的視訊 。在 VideoComposer 中,參數設定。 擴散模型。 ###為了學習實際的影片內容分佈###########################,擴散模型學習從常態分佈雜訊中逐步去噪來恢復真實的視覺內容,該過程實際上是在模擬可逆的長度為 T=1000 的馬可夫鏈。為了在隱空間中進行可逆過程,Video LDM 將雜訊注入 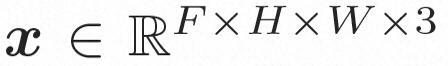
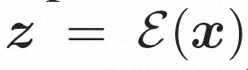
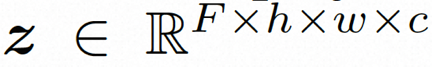
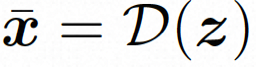
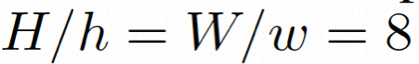
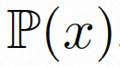
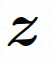
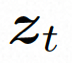
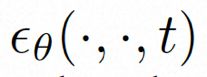
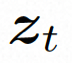
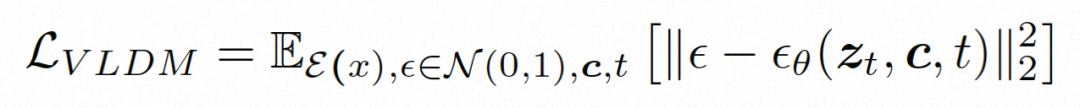
為了充分探討利用空間局部的歸納偏移和序列的時間歸納偏移進行去噪,VideoComposer 將 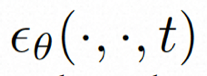
#VideoComposer
組合條件。 VideoComposer 將影片分解為三種不同類型的條件,即文字條件、空間條件和關鍵的時序條件,它們可以共同確定影片中的空間和時間模式。 VideoComposer 是一個通用的組合式視訊生成框架,因此,可以根據下游應用程式將更多的自訂條件納入VideoComposer,不限於下述列出的條件:
- 文字條件:文字(Text) 描述以粗略的視覺內容和運動方面提供影片的直覺指示,這也是常用的T2V 常用的條件;
- ##空間條件:
- 單張圖(Single Image),選擇給定影片的第一個畫面作為空間條件來進行影像到影片的生成,以表達該視頻的內容和結構;
- 單張早圖(Single Sketch),使用PiDiNet 提取第一個視頻幀的草圖作為第二個空間條件;
- 風格(Style),為了進一步將單張圖像的風格轉移到合成的影片中,選擇圖像嵌入作為風格指導;
##
- 時序條件:
- 運動向量(Motion Vector),運動向量作為視訊特有的元素表示為二維向量,即水平和垂直方向。它明確地編碼了相鄰兩幀之間的逐像素移動。由於運動向量的自然屬性,將此條件視為時間平滑合成的運動控制訊號,其從壓縮影片中提取標準MPEG-4 格式的運動向量;
- ## 深度序列( Depth Sequence),為了引入視訊層級的深度訊息,利用PiDiNet 中的預訓練模型提取視訊畫面的深度圖;
- 掩膜序列(Mask Sequence),引入管狀掩膜來屏蔽局部時空內容,並強制模型根據可觀察到的信息預測被屏蔽的區域;
- 草圖序列(Sketch Sequnce),與單一草圖相比,草圖序列可以提供更多的控制細節,從而實現精確的客製化合成。
時空條件編碼器。 序列條件包含豐富且複雜的時空依賴關係,對可控制的指示帶來了較大挑戰。為了增強輸入條件的時序感知,研究設計了一個時空條件編碼器(STC-encoder)來納入空時關係。具體而言,首先應用一個輕量級的空間結構,包括兩個 2D 卷積和一個 avgPooling,用於提取局部空間信息,然後將得到的條件序列被輸入到一個時序 Transformer 層進行時間建模。這樣,STC-encoder 可以促進時間提示的明確嵌入,為多樣化的輸入提供統一的條件植入入口,從而增強幀間一致性。另外,研究在時間維度上重複單一影像和單一草圖的空間條件,以確保它們與時間條件的一致性,從而方便條件植入過程。
經過 STC-encoder 處理條件後,最終的條件序列具有與相同的空間形狀,然後透過元素加法融合。最後,沿著通道維度將合併後的條件序列與連接起來作為控制訊號。對於文本和風格條件,利用交叉注意力機制注入文本和風格指導。
訓練與推理
兩階段訓練策略。 雖然VideoComposer 可以透過影像LDM 的預訓練進行初始化,其能夠在一定程度上緩解訓練難度,但模型難以同時具有時序動態感知的能力和多條件生成的能力,這個會增加訓練組合影片產生的難度。因此,研究採用了兩階段最佳化策略,第一階段透過 T2V 訓練的方法,讓模型初步具有時序建模能力;第二階段在透過組合式訓練來優化 VideoComposer,以達到比較好的表現。
推理。 在推理過程中,採用 DDIM 來提高推理效率。並採用無分類器指導來確保產生結果符合指定條件。生成過程可以形式化如下:
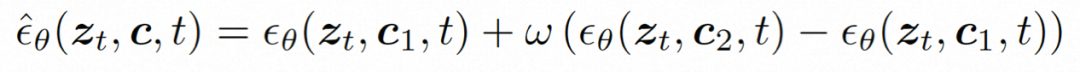
其中,ω 是指導比例;c1 和 c2 是兩組條件。這種指導機制在兩條件集合判斷,可以透過強度控制來讓模型有更靈活的控制。
實驗結果在實驗探索中,該研究證明作為 VideoComposer 作為統一模型具有通用生成框架,並在 9 項經典任務上驗證 VideoComposer 的能力。
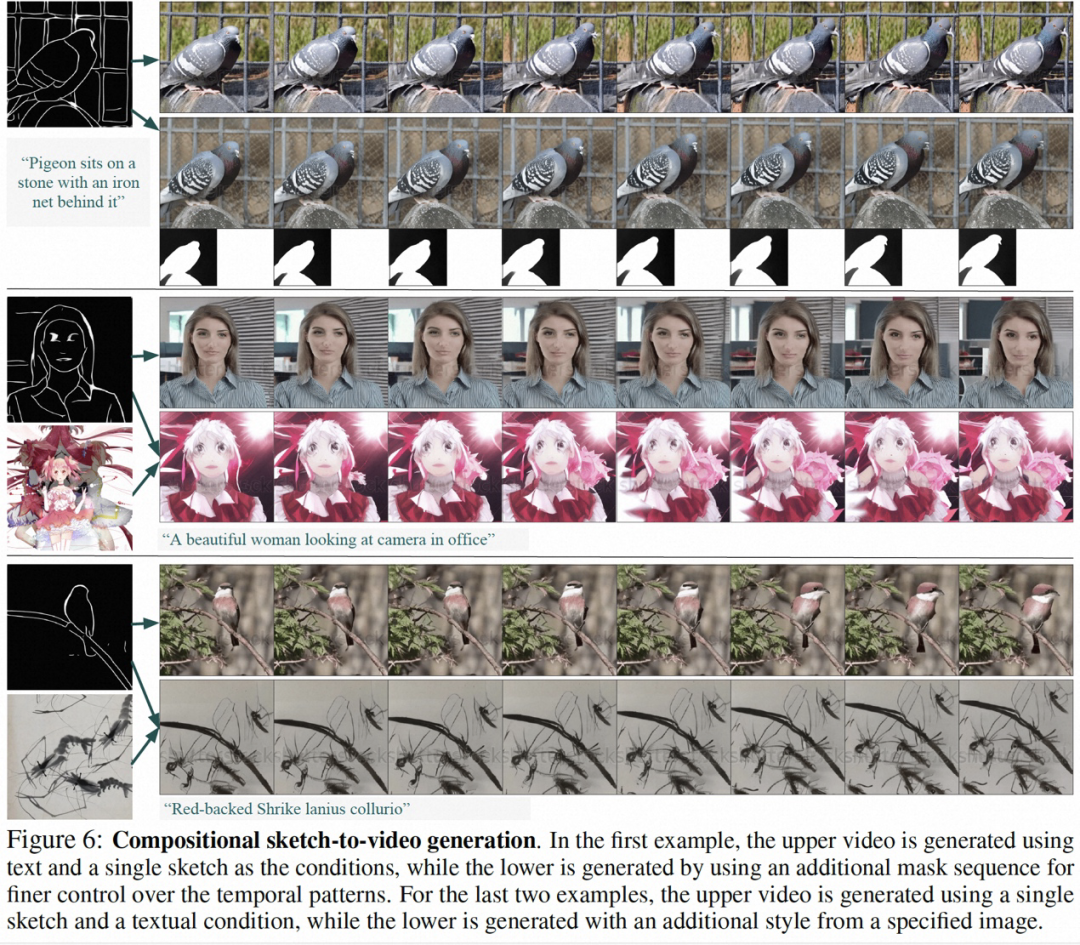
本研究的部分結果如下,在靜態圖片到影片產生(圖4)、影片Inpainting(圖5)、靜態草圖產生生影片(圖6)、手繪運動控制影片(圖8)、運動遷移(圖A12)均能反映可控影片生成的優勢。



團隊介紹
###公開資訊顯示,阿里巴巴在視覺基礎模型上的研究主要圍繞視覺表徵大模型、視覺生成式大模型及其下游應用的研究,並在相關領域已經發表CCF-A 類論文60 餘篇以及在多項行業競賽中獲得10 餘項國際冠軍,例如可控圖像生成方法Composer、圖文預訓練方法RA-CLIP 和RLEG、未裁剪長視訊自監督學習HiCo/HiCo 、說話人臉生成方法LipFormer 等均出自該團隊。 ######以上是時間、空間可控的影片生成走進現實,阿里大模型新作VideoComposer火了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 抖音發布他人影片侵權嗎?它怎麼剪輯影片不算侵權?
Mar 21, 2024 pm 05:57 PM
抖音發布他人影片侵權嗎?它怎麼剪輯影片不算侵權?
Mar 21, 2024 pm 05:57 PM
隨著短影片平台的興起,抖音成為了大家日常生活中不可或缺的一部分。在抖音上,我們可以看到來自世界各地的有趣影片。有些人喜歡發布他人的視頻,這就引發了一個問題:抖音發布他人視頻侵權嗎?本文將圍繞這個問題展開討論,告訴大家怎樣剪輯影片不算侵權,以及如何避免侵權問題。一、抖音發布他人影片侵權嗎?根據我國《著作權法》的規定,未經著作權人許可,擅自使用其作品,屬於侵權行為。因此,在抖音上發布他人視頻,如果未經原作者或著作權人許可,就屬於侵權行為。二、怎樣剪輯影片不算侵權? 1.使用公共領域或授權的內容:公共
 從 iPhone 上的影片中刪除慢動作的 2 種方法
Mar 04, 2024 am 10:46 AM
從 iPhone 上的影片中刪除慢動作的 2 種方法
Mar 04, 2024 am 10:46 AM
在iOS設備上,「相機」應用程式可讓您拍攝慢動作視頻,如果您使用的是最新的iPhone,甚至可以以每秒240幀的速度錄製視頻。此功能讓您能夠捕捉到豐富細節的高速動作。但有時候,您可能希望將慢動作影片以正常速度播放,這樣可以更好地欣賞影片中的細節和動作。在這篇文章中,我們將解釋從iPhone上的現有影片中刪除慢動作的所有方法。如何從iPhone上的影片中刪除慢動作[2種方法]您可以使用「照片」App或iMovie剪輯App從裝置上的影片中刪除慢動作。方法1:使用「照片」應用程式在iPhone上開啟
 抖音發布影片如何賺收益?新手小白怎麼在抖音上賺錢啊?
Mar 21, 2024 pm 08:17 PM
抖音發布影片如何賺收益?新手小白怎麼在抖音上賺錢啊?
Mar 21, 2024 pm 08:17 PM
抖音,這個全民短視頻平台,不僅讓我們在閒暇時間享受到各種有趣、新奇的短視頻,同時也給了我們一個展示自我、實現價值的舞台。那麼,如何在抖音發布影片中賺取收益呢?本文將詳細解答這個問題,幫助你在抖音上賺取更多的收益。一、抖音發布影片如何賺收益?發布影片在抖音上獲得一定的播放量後,可以有機會參與廣告分成計畫。這項收益方式是抖音用戶最熟悉的之一,也是許多創作者主要的收入來源。抖音根據帳號權重、影片內容以及觀眾回饋等多種因素來決定是否提供廣告分成的機會。抖音平台允許觀眾透過發送禮物來支持自己喜歡的創作者,
 如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
隨著短影片平台的興起,小紅書成為了許多人分享生活、表達自我、獲取流量的平台。在這個平台上,發布影片作品是一種非常受歡迎的互動方式。那麼,如何發布小紅書影片作品呢?一、如何發布小紅書影片作品?首先,確保準備好一段適合分享的影片內容。你可以利用手機或其他攝影設備拍攝,需要注意畫質和聲音的清晰度。 2.剪輯影片:為了讓作品更具吸引力,可以剪輯影片。可使用專業的影片剪輯軟體,如抖音、快手等,加入濾鏡、音樂、字幕等元素。 3.選擇封面:封面是吸引用戶點擊的關鍵,選擇一張清晰、有趣的圖片作為封面,讓
 阿里巴巴杭州全球總部 5 月 10 日投入使用
May 07, 2024 pm 02:43 PM
阿里巴巴杭州全球總部 5 月 10 日投入使用
May 07, 2024 pm 02:43 PM
本站5月7日消息,5月10日,位於杭州未來科技城的阿里巴巴全球總部(西溪C區)將正式投入使用,同時阿里巴巴北京朝陽科技園也將啟用。這標誌著阿里巴巴公司在全球範圍內的總部辦公大樓已達到四座。 ▲阿里巴巴全球總部(西溪C區)5月10日也是阿里巴巴第20個“阿里日”,每年的這一天,公司都會有慶祝活動,兩座新園區將向阿里親友、校友們開放。西溪C區是阿里目前最大的自有園區,可容納3萬人辦公。 ▲阿里北京朝陽科技園阿里巴巴全球總部位於杭州未來科技城,文一西路以北、高教路以東,總建築面積98.45萬平方米,其中,地
 微博發影片怎麼不壓縮畫質_微博發影片不壓縮畫質方法
Mar 30, 2024 pm 12:26 PM
微博發影片怎麼不壓縮畫質_微博發影片不壓縮畫質方法
Mar 30, 2024 pm 12:26 PM
1.先打開手機微博,點選右下角【我】(如圖所示)。 2、接著點選右上角【齒輪】打開設定(如圖所示)。 3.然後找到並開啟【通用設定】(如圖所示)。 4.隨後進入【影片隨著】選項(如圖所示)。 5.再開啟【影片上傳清晰度】設定(如圖)。 6.最後選擇【原畫質】就能不壓縮了(如圖)。
 阿里巴巴id在哪裡看
Mar 08, 2024 pm 09:49 PM
阿里巴巴id在哪裡看
Mar 08, 2024 pm 09:49 PM
在阿里巴巴軟體中,一旦您成功註冊帳號,系統就會為您指派一個獨特的ID,這個ID將作為您在平台上的身分識別。但是對於許多用戶來說,他們會想要查詢自己的ID,但是卻不知道該如何操作。那麼本站小編帶來下文中,就將為大家帶來詳細的攻略步驟介紹,希望能幫助大家!阿里巴巴id在哪裡看答案:【阿里巴巴】-【我的】。 1.首先打開阿里巴巴軟體,進入到首頁中後我們需要點擊右下角的【我的】;2、然後來到我的頁面中後我們在頁面的上方就可以看到【id】了;阿里巴巴id跟淘寶一樣嗎阿里巴巴id和淘寶id不一樣,但二
 達摩院公佈 2024 阿里巴巴全球數學競賽決賽試題:五個賽道、8 月出成績
Jun 23, 2024 pm 06:36 PM
達摩院公佈 2024 阿里巴巴全球數學競賽決賽試題:五個賽道、8 月出成績
Jun 23, 2024 pm 06:36 PM
本站6月23日消息,本站從達摩院DAMO微信公眾號獲悉,北京時間6月22日24時,2024阿里巴巴全球數學競賽決賽正式結束。本屆決賽共有來自全球17個國家與地區的800多位選手入圍。接下來將進入專家組獨立閱卷階段。閱卷包括初評、交叉複審、最終核驗等流程。決賽的五個賽道將依成績分別評出金獎1名、銀牌2名、銅獎4名以及優秀獎10名。總共85人得獎選手名單將於8月公佈。阿里達摩院也公佈數學決賽題目,決賽分為五個賽道,分別為:1、代數與數論;2、幾何與拓樸;3、分析與方程式;4、組合與機率;5、應用與計算
