

貧窮讓我預訓練


一、要不要預先訓練

# #預訓練的效果是直接的,所需的資源常常令人望而卻步。如果存在這種預訓練方法,它的啟動所需算力、資料和人工資源很少,甚至只需要單人單卡的原始語料。經過無監督的資料處理,完成一次遷移到自己領域的預訓練之後,就能獲得零樣本的NLG、NLG和向量表示推理能力,其他向量表示的召回能力超過BM25,那麼你有興趣嘗試嗎?

#要不要做一件事,需要衡量投入產出決定。預訓練是大事,需要一些前置條件和資源,也要充足的預期效益才會實行。通常所需要的條件有:充足的語料庫建設,通常來說質量比數量更難得,所以語料庫的質量可以放鬆些,數量一定要管夠;其次是具備相應的人才儲備和人力預算,相較而言,小模型訓練更容易,障礙更少,大模型遇到的問題會多些;最後才是算力資源,根據場景和人才搭配,豐儉由人,最好有一塊大內存顯示卡。預訓練帶來的效益也直觀,遷移模型能直接帶來效果提升,提升幅度跟預訓練投入和領域差異直接相關,最終收益由模型提升和業務規模共同增益。
在我們的場景中,資料領域跟通用領域差異極大,甚至需要大幅更替詞表,業務規模也已經足夠。如果不預訓練的話,也會為每個下游任務專門微調模型。預訓練的預期效益是確定的。我們的語料庫品質上很爛,但是數量足夠。算力資源很有限,配合對應的人才儲備可彌補。此時預訓練的條件都已經具備。
直接決定我們啟動預訓練的因素是需要維護的下游模型太多了,特別佔用機器和人力資源,需要給每個任務都要準備一大堆資料訓練出一個專屬模型,模型治理的複雜度急遽增加。所以我們探索預訓練,希望能建構統一的預訓練任務,讓各個下游模型都受益。我們做這件事的時候也不是一蹴而就的,需要維護的模型多也意味著模型經驗多,結合之前多個專案經驗,包括一些自監督學習、對比學習、多任務學習等模型,經過反覆實驗迭代融合成形的。 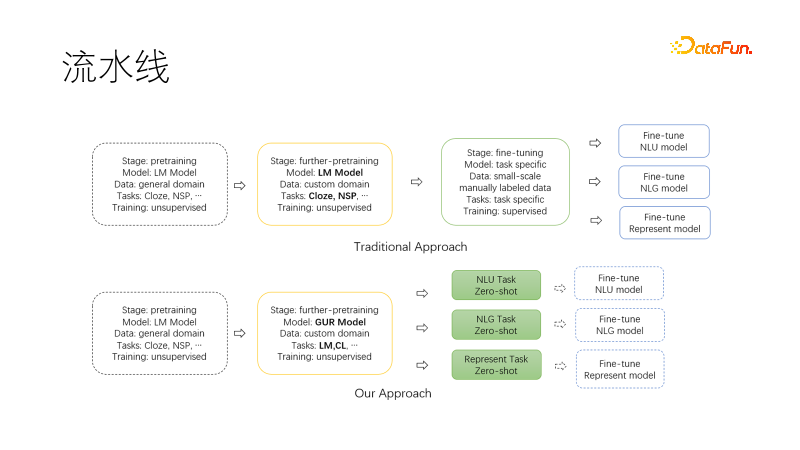
上圖是傳統的nlp管線範式,基於現有的通用預訓練模型,在可選的遷移預訓練完成後,為每個下游任務收集資料集,微調訓練,並且需要許多人工和顯示卡維護多個下游模型和服務。
下圖是我們提出的新範式,在遷移到我們領域繼續預訓練時候,使用聯合語言建模任務和對比學習任務,使得產出模型具備零樣本的NLU、NLG、向量表示能力,這些能力是模型化的,可以按需取用。如此需要維護的模型就少了,尤其是在專案啟動時候可以直接用於調查,如果有需要再進一步微調,所需的資料量也大大降低。
二、如何預先訓練
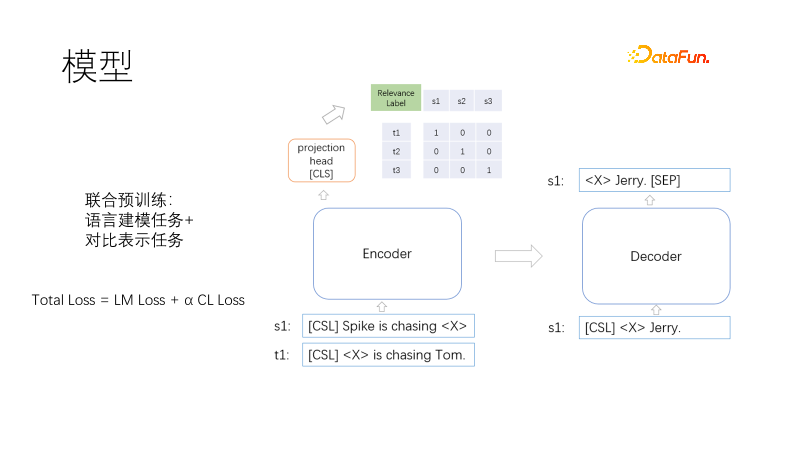
## #########這是我們的預訓練模型架構,包括Transformer的編碼器、解碼器和向量表示頭。 ##########
預訓練的目標包括語言建模和對比表示,損失函數為Total Loss = LM Loss α CL Loss,採用語言建模任務與對比表示任務聯合訓練,其中α表示權重係數。語言建模採用遮罩模型,類似T5,只解碼遮罩部分。對比表示任務類似CLIP,在一個批次內,有一對相關訓練正樣本,其他未負樣本,對於每一條樣本對(i,I)中的i,有一個正樣本I,其他樣本為負樣本,使用對稱交叉熵損失,迫使正樣本的表示相近,負樣本的表示相遠。採用T5方式解碼可以縮短解碼長度。一個非線性向量表示頭加載編碼器上方,一是向量表示場景中要求更快,二是兩個所示函數作用遠離,防止訓練目標衝突。那麼問題來了,完形填空的任務很常見,不需要樣本,那相似性樣本對是怎麼來的呢?

#當然,作為預訓方法,樣本對一定是無監督演算法挖掘的。通常資訊檢索領域採用挖掘正樣本基本方法是逆完形填空,在一篇文件中挖掘幾個片段,假定他們相關。我們這裡將文檔拆分為句子,然後列舉句子對。我們採用最長公共子字串來判定兩個句子是否相關。如圖取兩個正負句對,最長公共子串長到一定程度判定為相似,否則不相似。閾值自取,例如長句子為三個漢字,英文字母要求多一些,短句子可以放鬆些。
我們採用相關性作為樣本對,而不是語意等價性,是因為二者目標是衝突的。如上圖所示,貓抓老鼠跟老鼠抓貓,語意相反卻相關。我們的場景搜尋為主,更專注於相關性。而且相關性比語意等價性更廣泛,語意等價更適合在相關性基礎上繼續微調。
有些句子篩選多次,有些句子沒有被篩選。我們限制句子入選頻次上限。對於落選句子,可以複製作為正樣本,可以拼接到入選句子中,也可以用逆向完型填空作為正樣本。
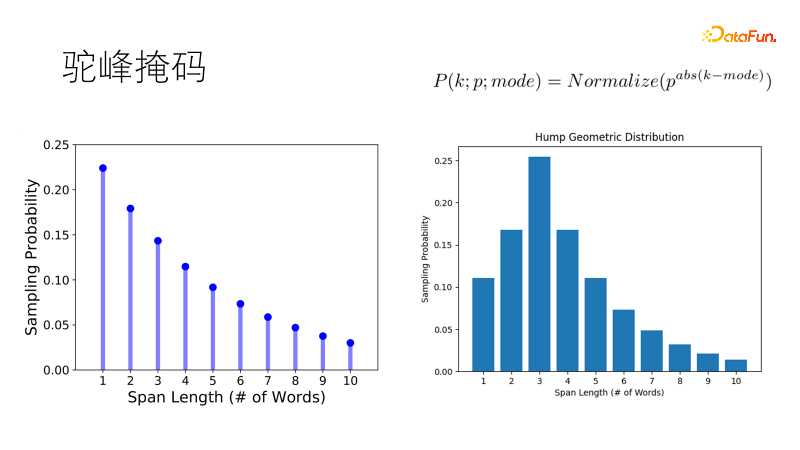
傳統的遮罩方式如SpanBert,採用幾何分佈取樣遮罩長度,短遮罩機率高,長掩碼機率低,適用於長句子。但我們的語料是支離破碎的,當面對一二十個字的短句子時,傳統傾向掩碼兩個單字勝過遮蔽一個雙字,這不符合我們期望。所以我們改進了這個分佈,讓他取樣最優長度的機率最大,其他長度機率逐次降低,就像一個駱駝的駝峰,成為駝峰幾何分佈,在我們短句富集的場景中更加健壯。
三、實驗效果
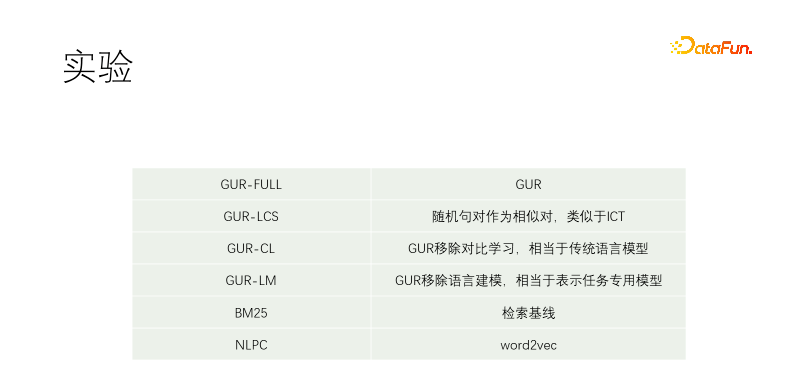
#我們做了對照實驗。包括GUR-FULL,用到了語言建模和向量對比表示;UR-LCS的樣本對沒有經過LCS篩選過濾;UR-CL沒有對比表示學習,相當於傳統的語言模型;GUR-LM只有向量對比表示學習,沒有語言建模學習,相當於專門為下游任務微調;NLPC是百度場內的一個word2vec算符。
實驗從一個T5-small開始繼續預訓練。訓練語料包括維基百科、維基文庫、CSL和我們的自有語料。我們的自有語料從物料庫抓來的,品質很差,品質最佳的部分是物料庫的標題。所以在其他文檔中挖正樣本時是近乎任意文字對篩選,而在我們語料庫中是用標題來匹配正文的每一個句子。 GUR-LCS沒有經過LCS選,如果不這樣幹的話,樣本對太爛了,這麼做的話,跟GUR-FULL差別就小多了。
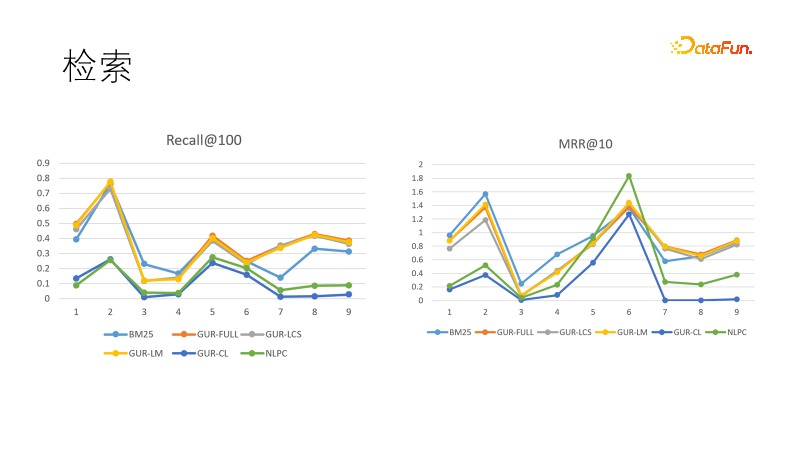
我們在幾個檢索任務中評測模型的向量表示效果。左圖是幾個模型在召回中的表現,我們發現經過向量表示學習的模型表現都是最好的,勝過BM25。我們也比較了排序目標,這回BM25扳回一局。這顯示密集模型的泛化能力強,稀疏模型的確定性強,二者可以互補。實際上在資訊檢索領域的下游任務中,密集模型和稀疏模型經常搭配使用。
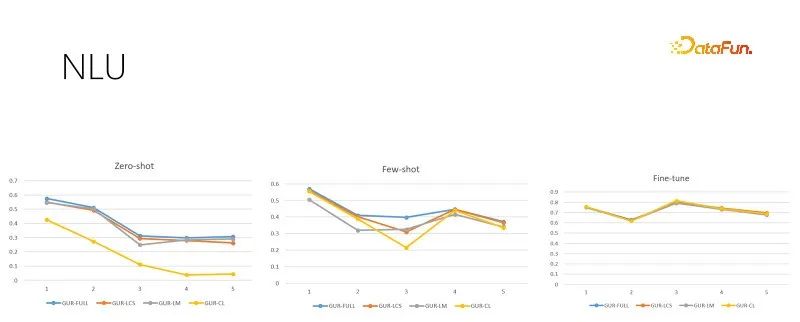
#上圖是不同訓練樣本量的NLU評測任務,每個任務有數十到幾百個類別,以ACC得分評估效果。 GUR模型也將分類的標籤轉換為向量,來為每個句子找到最近的標籤。上圖由左至右依據訓練樣本量遞增分別是零樣本、小樣本和足夠微調評測。右圖是經過充足微調之後的模型表現,顯示了各個子任務的本身難度,也是零樣本和小樣本表現的天花板。可見GUR模型可以依靠向量表示就可以在一些分類任務中實現零樣本推理。且GUR模型的小樣本能力表現最為突出。
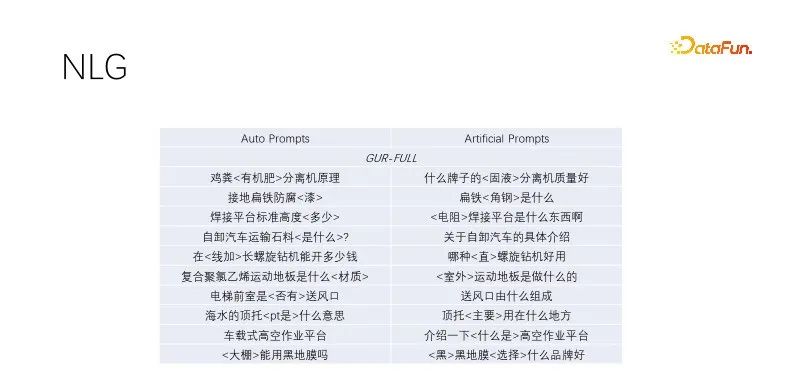
#這是NLG的零樣本表現。我們在做標題生成和query擴展中,挖掘優質流量的標題,將關鍵字保留,非關鍵字隨機掩碼,經過語言建模訓練的模型表現都不錯。這種自動prompt效果跟人工構造的目標效果差不多,多樣性更廣泛,能夠滿足大量生產。經過語言建模任務的幾個模型表現差不多,上圖採用GUR模型範例。
四、結語
#本文提出了一個新的預訓練範式,上述對照實驗顯示了,聯合訓練不會造成目標衝突。 GUR模型在繼續預訓練時,可以在維持語言建模能力的基礎上,增加向量表示的能力。一次預訓練,到處零原樣本推理。適合業務部門低成本預訓練。

#上述連結記載了我們的訓練細節,參考文獻詳見論文引用,程式碼版本比論文新一點。希望能給AI民主化做一點微小貢獻。大小模型有各自應用場景,GUR模型除了直接用於下游任務之外,還可以結合大模型使用。我們在管線中先用小模型辨識再用大模型指令任務,大模型也可以給小模型生產樣本,GUR小模型可以提供大模型向量檢索。
論文中的模型為了探討多個實驗選用的小模型,實踐中若選用更大模型增益明顯。我們的探索還很不夠,需要有進一步工作,如果有意願的話可以聯絡laohur@gmail.com,期待能與大家共同進步。
#以上是貧窮讓我預訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
在自然語言生成任務中,取樣方法是從生成模型中獲得文字輸出的一種技術。這篇文章將討論5種常用方法,並使用PyTorch進行實作。 1.GreedyDecoding在貪婪解碼中,生成模型根據輸入序列逐個時間步地預測輸出序列的單字。在每個時間步,模型會計算每個單字的條件機率分佈,然後選擇具有最高條件機率的單字作為當前時間步的輸出。這個單字成為下一個時間步的輸入,生成過程會持續直到滿足某種終止條件,例如產生了指定長度的序列或產生了特殊的結束標記。 GreedyDecoding的特點是每次選擇當前條件機率最
 如何使用PHP進行基本的自然語言生成
Jun 22, 2023 am 11:05 AM
如何使用PHP進行基本的自然語言生成
Jun 22, 2023 am 11:05 AM
自然語言生成是一種人工智慧技術,它能夠將資料轉換為自然語言文字。在當今的大數據時代,越來越多的業務需要將資料視覺化或呈現給用戶,而自然語言生成正是一種非常有效的方法。 PHP是一種非常受歡迎的伺服器端腳本語言,它可以用來開發網頁應用程式。本文將簡要介紹如何使用PHP進行基本的自然語言生成。引入自然語言生成庫PHP自帶的函數庫並不包括自然語言生成所需的功能,因此
 流量工程將程式碼產生的準確率提高一倍:由19%提高至44%
Feb 05, 2024 am 09:15 AM
流量工程將程式碼產生的準確率提高一倍:由19%提高至44%
Feb 05, 2024 am 09:15 AM
一篇新論文的作者提出了一種「強化」代碼生成的方法。程式碼生成是人工智慧中一項日益重要的能力。它透過訓練機器學習模型,根據自然語言描述自動產生電腦程式碼。這項技術具有廣泛的應用前景,可以將軟體規格轉化為可用的程式碼,自動化後端開發,並協助人類程式設計師提高工作效率。然而,產生高品質程式碼對AI系統仍然具有挑戰性,與翻譯或總結等語言任務相比。程式碼必須準確地符合目標程式語言的語法,能夠優雅地處理各種極端情況和意外輸入,並精確地處理問題描述中的許多小細節。即使是其他領域看似無害的小錯誤也可能完全破壞程式的功能,導
 使用馬可夫鏈建立文字產生器
Apr 09, 2023 pm 10:11 PM
使用馬可夫鏈建立文字產生器
Apr 09, 2023 pm 10:11 PM
本文中將介紹一個流行的機器學習專案-文字產生器,你將了解如何建立文字產生器,並了解如何實作馬可夫鏈以實現更快的預測模型。文字產生器簡介文字生成在各個行業都很受歡迎,特別是在行動、應用和資料科學領域。甚至新聞界也使用文字生成來輔助寫作過程。在日常生活中都會接觸到一些文本生成技術,文本補全、搜尋建議,Smart Compose,聊天機器人都是應用的例子,本文將使用馬可夫鏈建立一個文本生成器。這將是一個基於字元的模型,它接受鏈的前一個字元並產生序列中的下一個字母。透過使用範例單字訓練我們的程序,
 整合GPT-4的Cursor讓編寫程式碼和聊天一樣簡單,用自然語言編寫程式碼的新時代已來
Apr 04, 2023 pm 12:15 PM
整合GPT-4的Cursor讓編寫程式碼和聊天一樣簡單,用自然語言編寫程式碼的新時代已來
Apr 04, 2023 pm 12:15 PM
整合GPT-4的Github Copilot X還在小範圍內測中,而整合GPT-4的Cursor已公開發行。 Cursor是一個整合GPT-4的IDE,可以用自然語言寫程式碼,讓寫程式碼和聊天一樣簡單。 GPT-4和GPT-3.5在處理和編寫程式碼的能力上差異還是很大的。官網的一份測試報告。前兩個是GPT-4,一個採用文字輸入,一個採用影像輸入;第三個是GPT3.5,可以看出GPT-4的程式碼能力相較於GPT-3.5有較大能力的提升。整合GPT-4的Github Copilot X還在小範圍內測中,而
 價值、隱私保護全覆蓋 網信辦擬為生成式AI'立規矩”
Apr 13, 2023 pm 03:34 PM
價值、隱私保護全覆蓋 網信辦擬為生成式AI'立規矩”
Apr 13, 2023 pm 03:34 PM
4月11日,國家網路資訊辦公室(以下簡稱「網信辦」)起草發布了《生成式人工智慧服務管理辦法(徵求意見稿)》,並向社會大眾展開為期一個月的意見徵求。這份管理辦法(徵求意見稿)共21條,從適用範圍看,既包括了提供生成式人工智慧服務的主體,也包括使用這些服務的組織和個人;管理辦法覆蓋了生成式人工智慧輸出內容的價值導向、服務提供者的訓練原則、隱私權/智慧財產權等各項權利的保護等等。 GPT類生成式自然語言大模型及產品出現後,既讓大眾體驗到了人工智慧的飛躍式進步,也暴露出安全風險,包括產生帶偏見和歧視性的
 一定要「分詞」嗎? Andrej Karpathy:是時候拋棄這個歷史包袱了
May 20, 2023 pm 12:52 PM
一定要「分詞」嗎? Andrej Karpathy:是時候拋棄這個歷史包袱了
May 20, 2023 pm 12:52 PM
ChatGPT等對話AI的出現讓人們習慣了這樣一件事情:輸入一段文字、程式碼或一張圖片,對話機器人就能給出你想要的答案。但在這種簡單的互動方式背後,AI模型要進行非常複雜的資料處理與運算,tokenization就是比較常見的一種。在自然語言處理領域,tokenization指的是將文字輸入分割成更小的單元,稱為「token」。這些token可以是字、子字或字符,取決於特定的分詞策略和任務需求。例如,如果對句子「我喜歡吃蘋果」執行tokenization操作,我們將得到一串token序列:[&qu
 多國擬發ChatGPT禁令 關「野獸」的籠子要來了?
Apr 10, 2023 pm 02:40 PM
多國擬發ChatGPT禁令 關「野獸」的籠子要來了?
Apr 10, 2023 pm 02:40 PM
「人工智慧想越獄『、』AI產生自我意識」、「AI終將殺死人類」、「矽基生命的進化」.......曾經只在賽博朋克等科技幻想中出現的劇情,在今年走向現實,生成式自然語言模式正遭受前所未有的質疑。聚光燈下最矚目的那個是ChatGPT,3月底到4月初,OpenAI開發的這個文字對話機器人,突然從「先進生產力」的代表變成了人類的威脅。先是被上千位科技圈的精英們點名,放在「暫停訓練比GPT-4更強大的AI系統」的公開信中;緊接著,美國科技倫理組織又要求美國聯邦貿易委員會調查OpenAI,禁止發布商業版
