
AIGC的爆發除了帶來算力上的挑戰,對網路的要求也達到了前所未有的高度。
6月26日,騰訊雲首次對外完整揭露自研星脈高效能運算網路:星脈網路具備業界最高的3.2T通訊頻寬,能提升40%的GPU利用率,節省30%~60%的模型訓練成本,為AI大模型帶來10倍通訊效能提升。騰訊雲的新一代算力集群HCC可以支援超過10萬卡的龐大運算規模。
騰訊雲副總裁王亞晨表示:「星脈網路是為大模型而生。它所提供的大頻寬、高利用率以及零丟包的高效能網路服務,將助力算力瓶頸的突破,進一步釋放AI潛能,全面提升企業大模型的訓練效率,在雲端上加速大模型技術的迭代升級與落地應用。」
建構大模型專屬高效能網絡,提升40%GPU利用率
AIGC的火爆帶來AI大模型參數量從億級到萬億級的飆升。為支撐海量資料的大規模訓練,大量伺服器透過高速網路組成算力集群,互聯互通,共同完成訓練任務。
相反,GPU叢集越大,額外通訊損耗越多,大叢集並不代表大算力。 AI大模型時代為網路帶來了重大的挑戰,包括高頻寬要求、高利用率和資訊無損。
傳統低速網路頻寬無法滿足千億、兆參數規模的大模型,在訓練過程中,通訊佔比可高達50%。同時,傳統網路協定容易導致網路擁塞、高延遲和丟包,而僅0.1%的網路丟包就可能導致50%的算力損失,最終造成算力資源的嚴重浪費。
基於全面自研能力,騰訊雲在交換機、通訊協定、通訊庫以及營運系統等方面,進行了軟硬一體的升級與創新,率先推出業界領先的大模式專屬高效能網路-星脈網路。
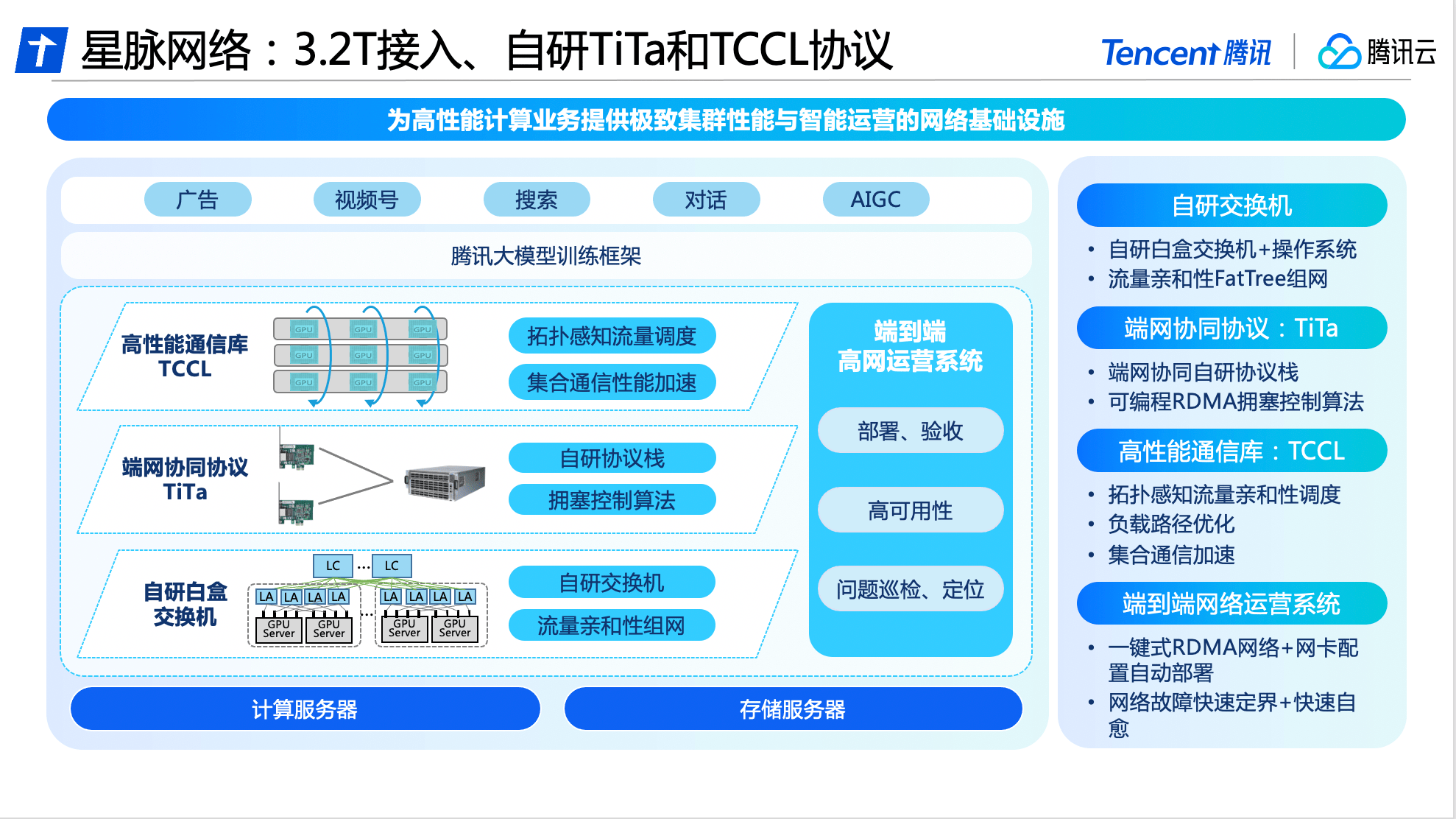
在硬體方面,星脈網路基於騰訊的網路研發平台,採用全自研設備建構互聯底座,實現自動化部署與配置。
在軟體方面,騰訊雲自研的TiTa網路協議,採用先進的擁塞控制和管理技術,能夠即時監控並調整網路擁塞,滿足大量伺服器節點之間的通訊需求,確保資料交換流暢、延時低,實現高負載下的零丟包,使叢集通訊效率達90%以上。
此外,騰訊雲也為星脈網路設計了高效能集合通訊庫TCCL,融入客製化解決方案,使系統實現了微秒感知網路品質。透過使用動態調度機制來合理分配通訊通道,可以有效避免網路問題導致的訓練中斷等情況,並將通訊延遲降低40%。
網路的可用性,也決定了整個叢集的運算穩定性。為確保星脈網路的高可用,騰訊雲自研了端到端的全端網路運作系統,透過端網立體化監控與智慧定位系統,將端網問題自動定界分析,讓整體故障的排查時間由天級降低至分鐘級。經過改進,大型模型訓練系統的整體部署時間已縮短為4.5天,保證了基礎配置的100%準確性。
歷經三代技術演進,軟硬一體深耕自研
#星脈網路全方位的升級背後,是騰訊資料中心網路歷經三代技術演進的成果。
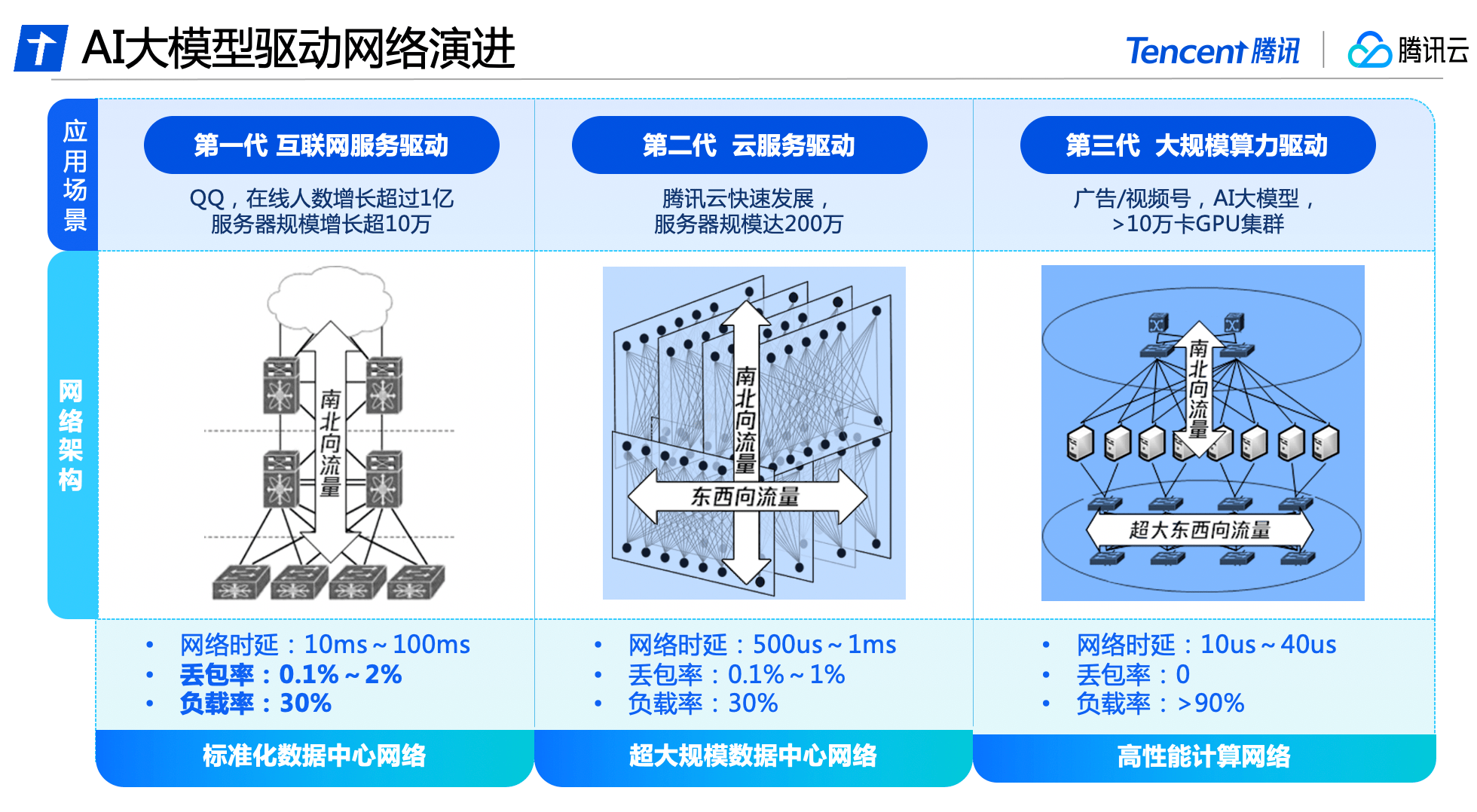
在騰訊發展初期,資料中心網路流量主要由使用者存取資料中心伺服器的南北向流量所構成,網路架構以存取、匯聚、出口為主。此階段主要使用了商用網絡設備,搭建標準化資料中心網絡,支撐QQ線上人數成長超過1億,伺服器規模成長超10萬。
隨著大數據和雲端運算的興起,伺服器之間的東西向流量逐漸增多,雲端租戶對網路產生了虛擬化和隔離的要求。資料中心網路架構逐漸演變為同時承載南北向與東西向流量的雲端網路架構,騰訊雲建置了全自研網路設備與管理系統,打造超大規模資料中心網絡,伺服器規模近200萬台。
騰訊雲在國內先行推出了高效能運算網絡,以滿足AI大模型的需求,並採用了東西向和南北向流量的分離架構。建構了獨立的超大頻寬、符合AI訓練流量特性的網路架構,並配合自研軟硬體設施,實現整套系統的自主可控,滿足超強算力對網路效能的新需求。
日前,騰訊雲發布的新一代HCC高效能運算集群,正是基於星脈高效能網路打造,可實現3.2T超高連網頻寬,算力效能較前代提升3倍,為AI大模型訓練構築可靠的高效能網路底座。
未來,騰訊雲也將持續投入基礎技術的研發,為各行各業的數智轉型提供強大的技術支撐。
以上是面向AI大模型,騰訊雲首次完整揭露自研星脈高效能運算網絡的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















