

類GPT模型訓練加速26.5%,清華朱軍等人用INT4演算法加速神經網路訓練

我們知道,將活化、權重和梯度量化為 4-bit 對於加速神經網路訓練非常有價值。但現有的 4-bit 訓練方法需要自訂數位格式,而當代硬體不支援這些格式。在本文中,清華朱軍等人提出了一種使用 INT4 演算法實現所有矩陣乘法的 Transformer 訓練方法。
模型訓練得快不快,這與激活值、權重、梯度等因素的要求緊密相關。
神經網路訓練需要一定運算量,使用低精度演算法(全量化訓練或 FQT 訓練)有望提升運算和記憶體的效率。 FQT 在原始的全精度計算圖中增加了量化器和去量化器,並將昂貴的浮點運算替換為廉價的低精度浮點運算。
對 FQT 的研究旨在降低訓練數值精度,同時降低收斂速度和精確度的犧牲。所需數值精確度從 FP16 降到 FP8、INT32 INT8 和 INT8 INT5。 FP8 訓練透過具有 Transformer 引擎的 Nvidia H100 GPU 完成,這使得大規模 Transformer 訓練實現了驚人的加速。
最近訓練數值精準度已被壓低到 4 位元( 4 bits)。 Sun 等人成功訓練了幾個具有 INT4 激活 / 權重和 FP4 梯度的當代網絡;Chmiel 等人提出自定義的 4 位對數數字格式,進一步提高了精度。然而,這些 4 位元訓練方法不能直接用於加速,因為它們需要自訂數位格式,這在當代硬體上是不支援的。
在4 位元這樣極低的水平上訓練存在著巨大的最佳化挑戰,首先前向傳播的不可微分量化器會使損失函數圖不平整,其中基於梯度的優化器很容易卡在局部最優。其次梯度在低精度下只能近似計算,這種不精確的梯度會減慢訓練過程,甚至導致訓練不穩定或發散的情況出現。
本文為流行的神經網路 Transformer 提出了新的 INT4 訓練演算法。訓練 Transformer 所使用的成本龐大的線性運算都可以寫成矩陣乘法(MM)的形式。 MM 形式使研究人員能夠設計更靈活的量化器。這種量化器透過 Transformer 中的特定的活化、權重和梯度結構,更好地近似了 FP32 矩陣乘法。本文中的量化器也利用了隨機數值線性代數領域的新進展。
 圖片
圖片
論文網址:https://arxiv.org/pdf/2306.11987.pdf
#研究表明,對前向傳播而言,精度下降的主要原因是激活中的異常值。為了抑制該異常值,研究提出了 Hadamard 量化器,以它對變換後的活化矩陣進行量化。此變換是一個分塊對角的 Hadamard 矩陣,它將異常值所攜帶的資訊擴散到異常值附近的矩陣項上,從而縮小了異常值的數值範圍。
對反向傳播而言,研究利用了活化梯度的結構稀疏性。研究表明,一些 token 的梯度非常大,但同時,其餘大多數的 token 梯度又非常小,甚至比較大梯度的量化殘差更小。因此,與其計算這些小梯度,不如將計算資源用於計算較大梯度的殘差。
結合前向和反向傳播的量化技術,本文提出一種演算法,即對 Transformer 中的所有線性運算使用 INT4 MMs。研究評估了在各種任務上訓練 Transformer 的演算法,包括自然語言理解、問答、機器翻譯和圖像分類。與現有的 4 位訓練工作相比,研究所提出的演算法實現了相媲美或更高的精度。此外,此演算法與當代硬體 (如 GPU) 是相容的,因為它不需要自訂數位格式 (如 FP4 或對數格式)。而研究提出的原型量化 INT4 MM 算子比 FP16 MM 基線快了 2.2 倍,將訓練速度提高了 35.1%。
前向傳播
在訓練過程中,研究者利用INT4 演算法加速所有的線性算子,並將所有運算強度較低的非線性算子設定為FP16 格式。 Transformer 中的所有線性算子都可以寫成矩陣乘法形式。為了方便演示,他們考慮如下簡單的矩陣乘法加速。
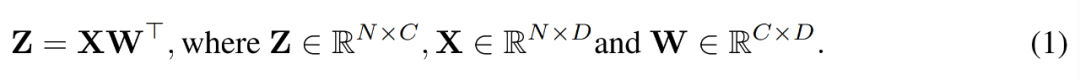 圖片
圖片
這種矩陣乘法的最主要用例是全連接層。
學得的步長量化
加速訓練必須使用整數運算來計算前向傳播。因此,研究者利用了學得的步長量化器(LSQ)。作為靜態量化方法,LSQ 的量化規模不依賴輸入,因此比動態量化方法成本更低。相較之下,動態量化方法需要在每次迭代時動態地計算量化規模。
給定一個 FP 矩陣 X,LSQ 透過以下公式 (2) 將 X 量化為整數。
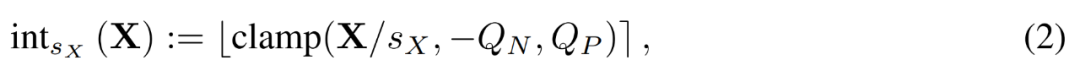 圖片
圖片
#激活異常值
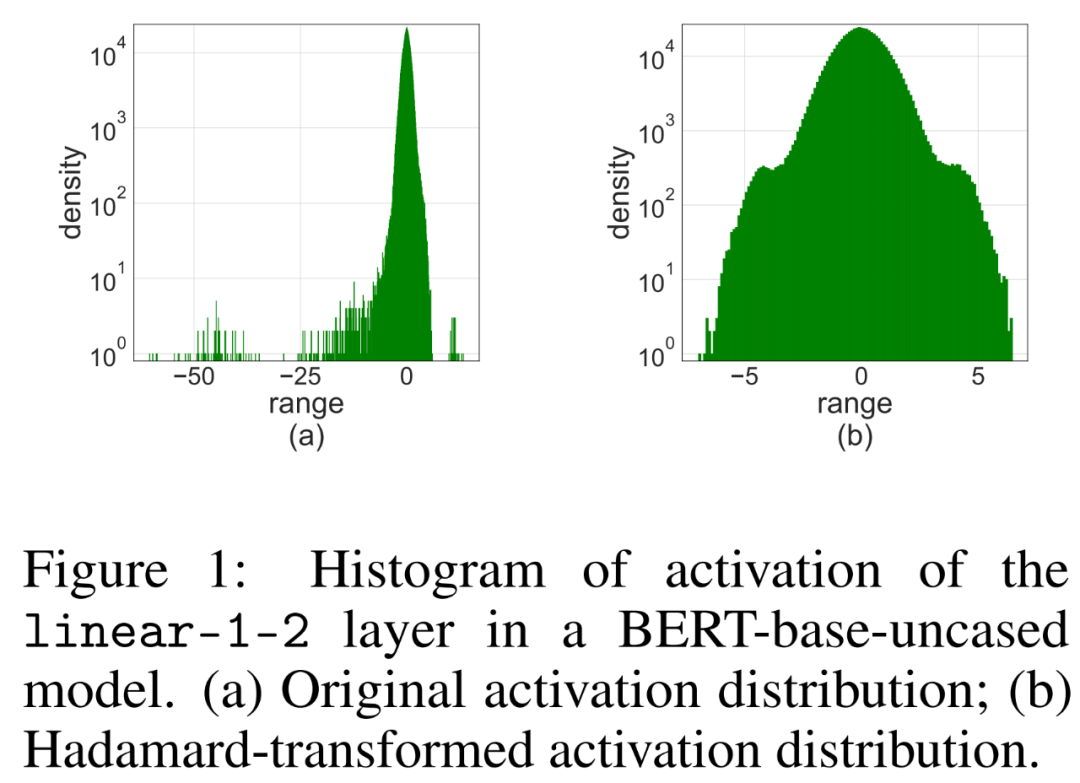
簡單地將LSQ 應用到具有4-bit 激活/ 權重的FQT(fully quantized training,全量化訓練)中,會由於激活異常值而導致準確度下降。如下圖 1 (a) 所示,活化的有一些異常值項,其數量級比其他項大得多。
在這種情況下,步長 s_X 在量化粒度和可表示數值範圍之間進行權衡。如果 s_X 很大,則可以很好地表示異常值,同時代價是以粗略的方式表示其他大多數項。如果 s_X 很小,則必須截斷 [−Q_Ns_X, Q_Ps_X] 範圍之外的項目。
Hadamard 量化
研究者提出使用Hadamard 量化器(HQ )來解決異常值問題,它的主要想法是在另一個異常值較少的線性空間中量化矩陣。
激活矩陣中的異常值可以形成特徵層級結構。這些異常值通常集中在幾個維度上,也就是 X 中只有幾列顯著大於其他列。作為一種線性變換,Hadamard 變換可以將異常值分攤到其他項中。具體地,Hadamard 轉換 H_k 是一個 2^k × 2^k 矩陣。
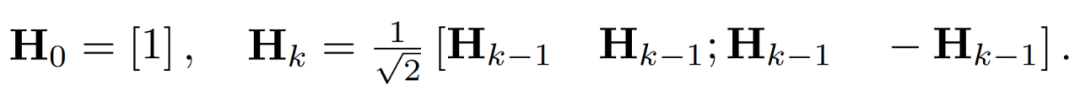
為了抑制異常值,研究者將 X 和 W 的變換版本量化。
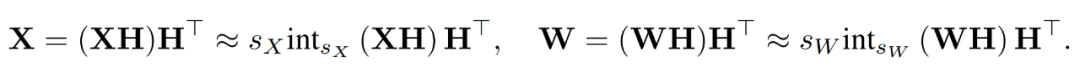
透過結合量化後的矩陣,研究者得到如下。
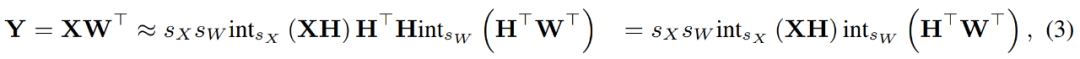
其中逆變換彼此之間相互抵消,並且 MM 可以實現如下。
 圖片
圖片
反向傳播
研究者使用INT4 運算來加速線性層的反向傳播。公式 (3) 中定義的線性算子 HQ-MM 有四個輸入,分別是啟動 X、權重 W 以及步長 s_X 和 s_W。給定關於損失函數 L 的輸出梯度∇_YL,他們需要計算這四個輸入的梯度。
梯度的結構稀疏性
#研究者註意到,訓練過程中梯度矩陣∇_Y 往往非常稀疏。稀疏性結構是這樣的:∇_Y 的少數行(即 tokens)具有較大的項,而大多數其他行接近全零向量。他們在下圖 2 中繪製了所有行的 per-row 範數∥(∇_Y)_i:∥的直方圖。
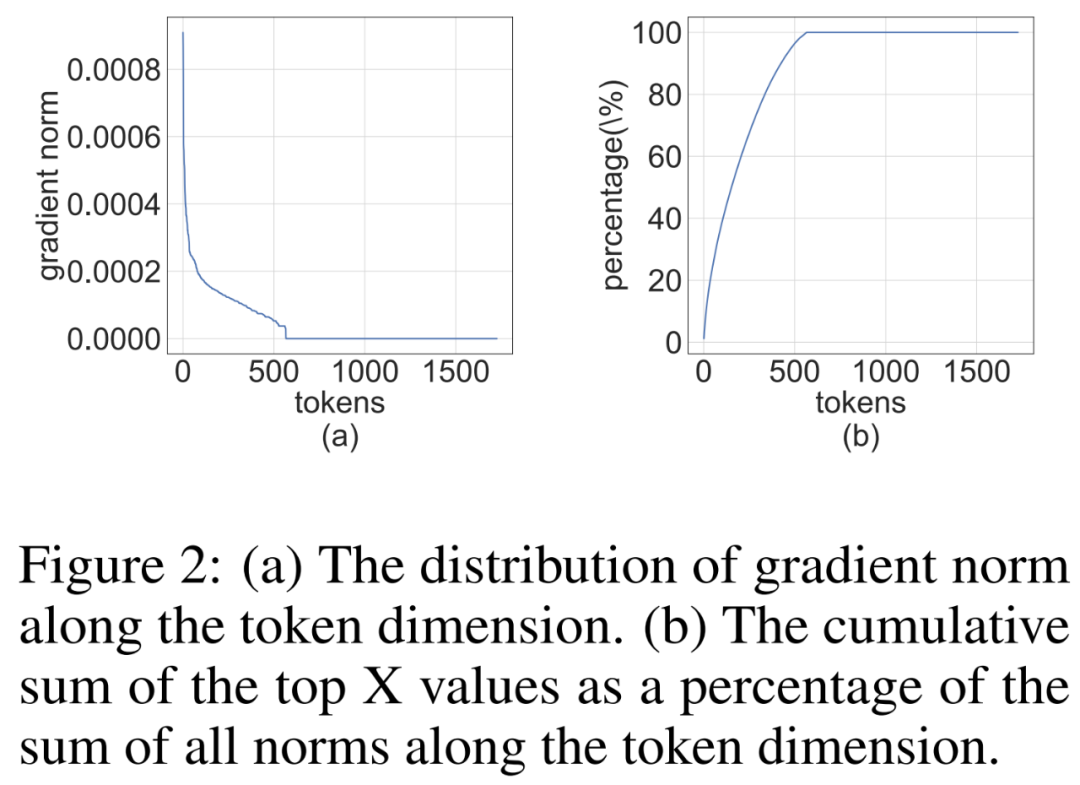 圖片
圖片
Bit 分割與平均分數取樣
研究者討論如何設計梯度量化器,從而利用結構稀疏性在反向傳播期間準確計算 MM。高階的想法是,許多行的梯度非常的小,因而對參數梯度的影響也很小,但卻浪費了大量計算。此外,大行無法用 INT4 準確地表示。
為利用這種稀疏性,研究者提出 bit 拆分,將每個 token 的梯度拆分為更高的 4bit 和更低的 4bit。然後再透過平均分數採樣選擇資訊量最大的梯度,這是 RandNLA 的一種重要性採樣技術。
實驗結果
研究在各種任務中評估了 INT4 訓練演算法,包括語言模型微調、機器翻譯和圖像分類。研究使用了 CUDA 和 cutlass2 實作了所提出的 HQ-MM 和 LSS-MM 演算法。除了簡單地使用 LSQ 作為嵌入層外,研究用 INT4 取代了所有浮點線性運算符,並保持最後一層分類器的全精度。並且,在此過程中,研究人員對所有評估模型採用預設架構、最佳化器、調度器和超參數。
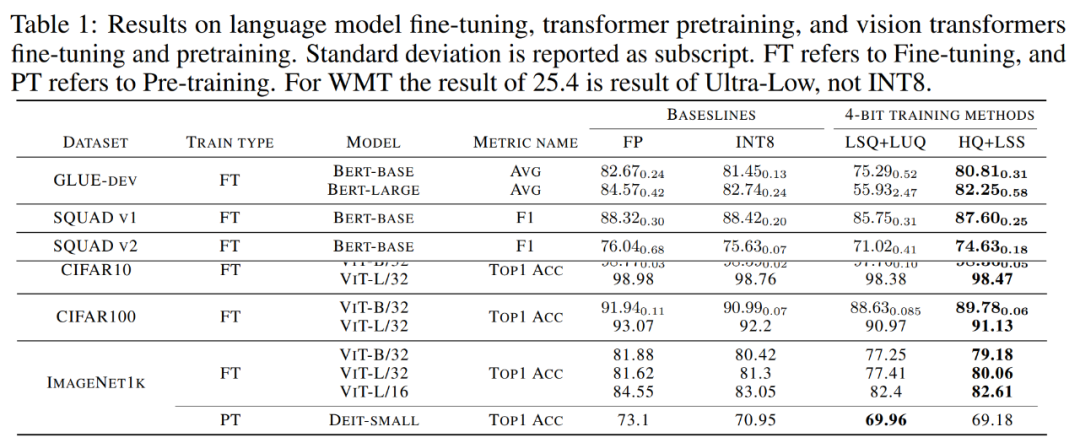
收斂模型精度。下表 1 展示了收斂模型在各任務上的精確度。
 圖片
圖片
語言模型微調。與 LSQ LUQ 相比,研究提出的演算法在 bert-base 模型上提升了 5.5% 的平均精度、,在 bert-large 模型上提升了 25% 的平均精度。
研究團隊也展示了演算法在 SQUAD、SQUAD 2.0、Adversarial QA、CoNLL-2003 和 SWAG 資料集上進一步展示了結果。在所有任務上,與 LSQ LUQ 相比,該方法取得了更好的效能。與 LSQ LUQ 相比,該方法在 SQUAD 和 SQUAD 2.0 上分別提高了 1.8% 和 3.6%。在更困難的對抗性 QA 中,該方法的 F1 分數提高了 6.8%。在 SWAG 和 CoNLL-2003 上,該方法分別提高了 6.7%、4.2% 的精度。
機器翻譯。研究也將所提出的方法用於預訓練。此方法在 WMT 14 En-De 資料集上訓練了一個基於 Transformer 的 [51] 模型用於機器翻譯。
HQ LSS 的 BLEU 降解率約為 1.0%,小於 Ultra-low 的 2.1%,高於 LUQ 論文中報告的 0.3%。儘管如此,HQ LSS 在這項預訓練任務上的表現仍然與現有方法相當,而且它支援當代硬體。
影像分類。研究在 ImageNet21k 上載入預先訓練的 ViT 檢查點,並在 CIFAR-10、CIFAR-100 和 ImageNet1k 上進行微調。
與 LSQ LUQ 相比,研究方法將 ViT-B/32 和 ViT-L/32 的準確率分別提高了 1.1% 和 0.2%。在 ImageNet1k 上,該方法與 LSQ LUQ 相比,ViT-B/32 的精度提高了 2%,ViT-L/32 的精度提高了 2.6%,ViT-L/32 的精度提高了 0.2%。
研究團隊進一步測試了演算法在ImageNet1K 上預先訓練DeiT-Small 模型的有效性,其中HQ LSS 與LSQ LUQ 相比仍然可以收斂到相似的精度水平,同時對硬體更加友善。
消融研究
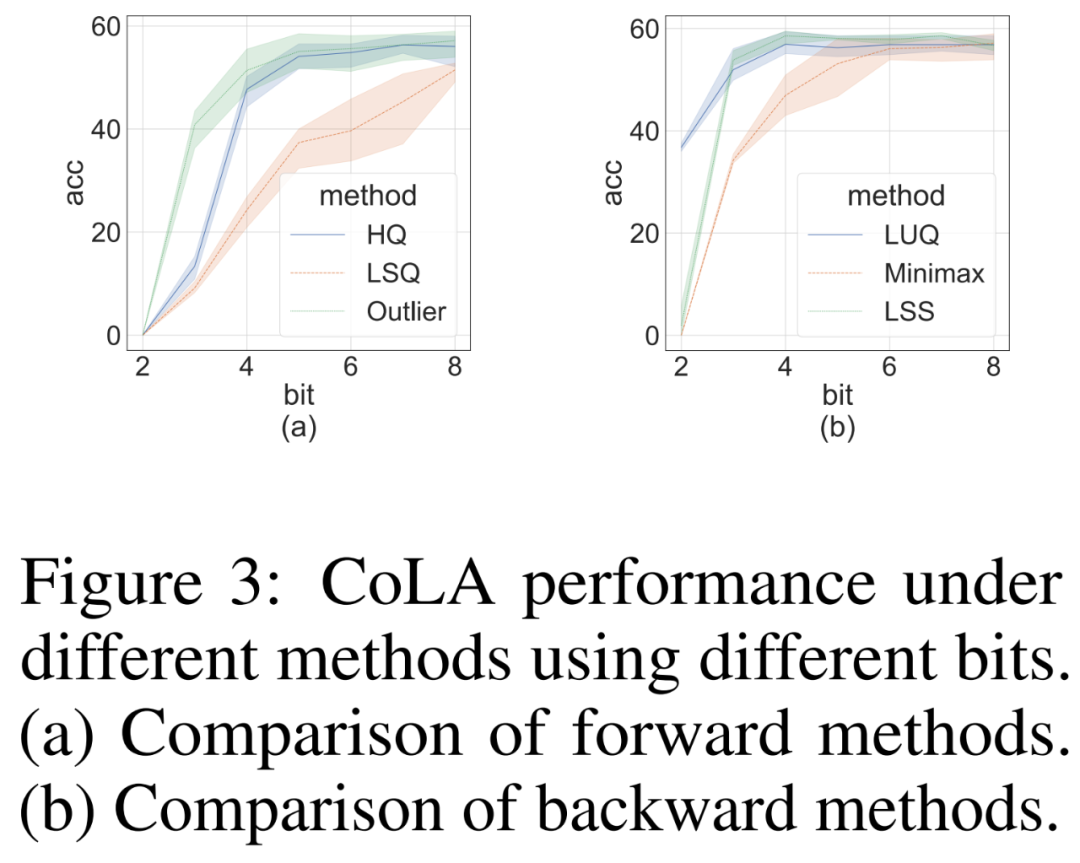
#研究者進行消融研究,以獨立地在挑戰性CoLA 資料集上展示前向和反向方法的有效性。為了研究不同量化器對前向傳播的有效性,他們將反向傳播設定為 FP16。結果如下圖 3 (a) 所示。
對於反向傳播,研究者比較了簡單的極小極大量化器、LUQ 和自己的 LSS,並將前向傳播設定為 FP16。結果如下圖 3 (b) 所示,雖然位寬高於 2,但 LSS 所獲得的結果與 LUQ 相當,甚至略高於後者。
 圖片
圖片
#計算與記憶體效率
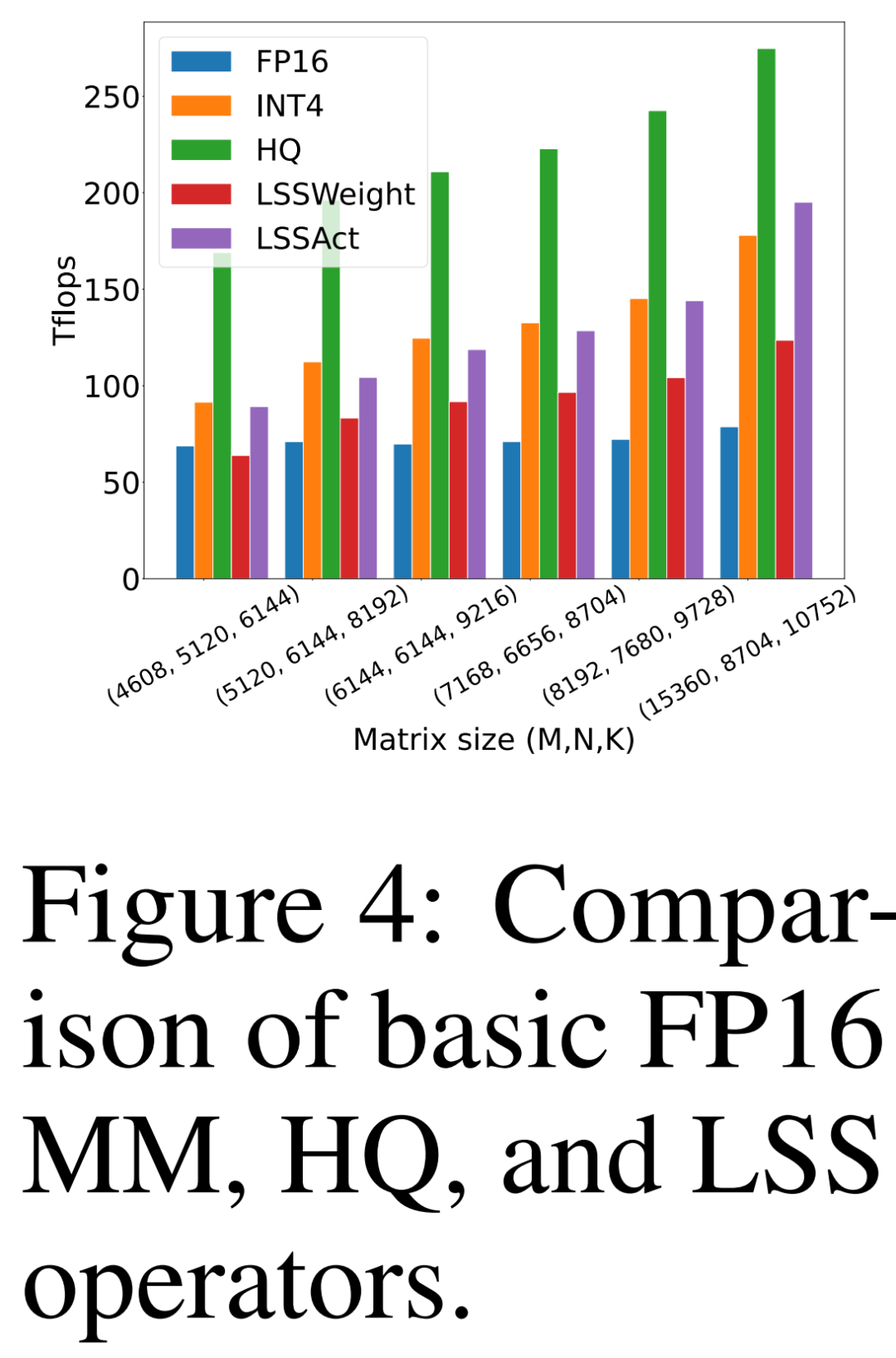
###########研究者比較自己提出的HQ-MM (HQ)、計算權重梯度的LSS(LSSWeight)、計算活化梯度的LSS(LSSAct)的吞吐量、它們的平均吞吐量(INT4)及下圖4 中英偉達RTX 3090 GPU 上cutlass 提供的基線張量核心FP16 GEMM 實作(FP16),它的峰值吞吐量為142 FP16 TFLOPs 和568 INT4 TFLOPs。 ######
 圖片
圖片
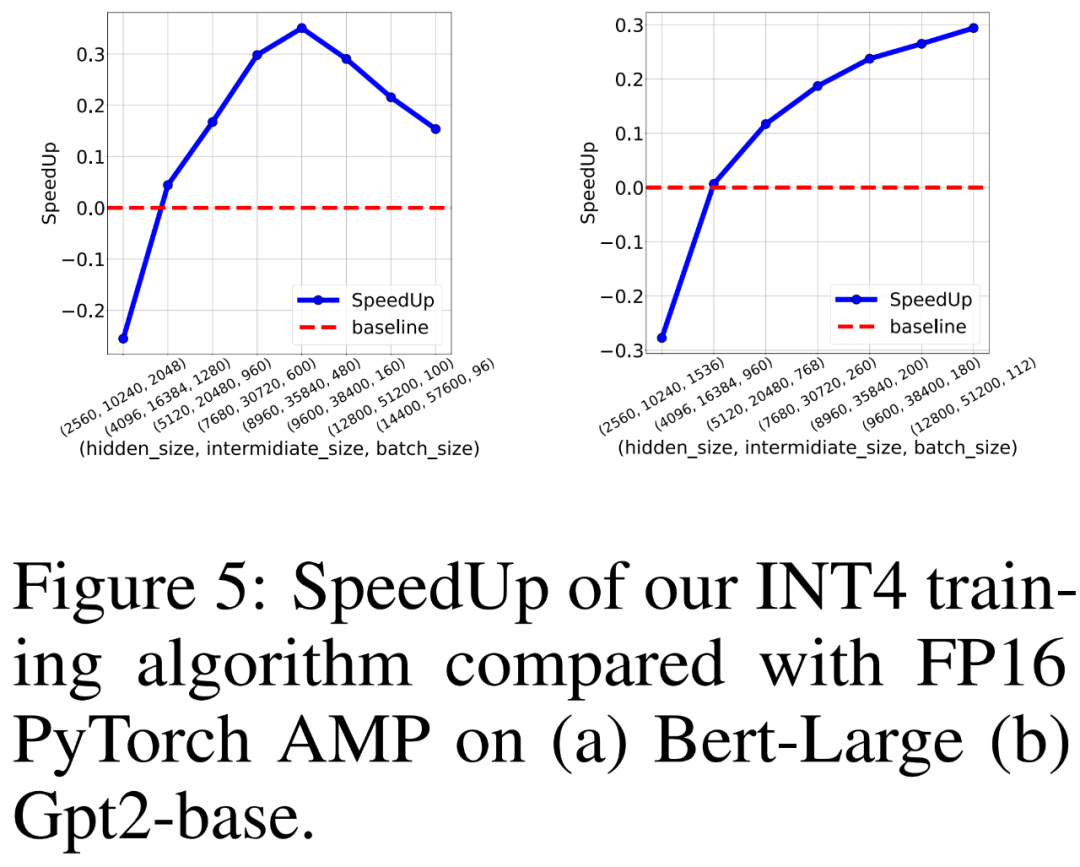
研究者也比較FP16 PyTorch AMP 以及自己INT4 訓練演算法在8 個英偉達A100 GPU 上訓練類BERT 和類別GPT 語言模型的訓練吞吐量。他們改變了隱藏層大小、中間全連接層大小和批次大小,並在下圖 5 中繪製了 INT4 訓練的加速比。
結果顯示,INT4 訓練演算法對於類別 BERT 模型實現了最高 35.1% 的加速,對於類別 GPT 模型實現了最高 26.5% 的加速。
 圖片
圖片
以上是類GPT模型訓練加速26.5%,清華朱軍等人用INT4演算法加速神經網路訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
適合新手的加密貨幣數據平台有CoinMarketCap和非小號。 1. CoinMarketCap提供全球加密貨幣實時價格、市值、交易量排名,適合新手與基礎分析需求。 2. 非小號提供中文友好界面,適合中文用戶快速篩選低風險潛力項目。
 okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
OKX 交易所的詳細介紹如下:1) 發展歷程:2017 年創辦,2022 年更名為 OKX;2) 總部位於塞舌爾;3) 業務範圍涵蓋多種交易產品,支持 350 多種加密貨幣;4) 用戶遍布 200 餘個國家,千萬級用戶量;5) 採用多重安全措施保障用戶資產;6) 交易費用基於做市商模式,費率隨交易量增加而降低;7) 曾獲多項榮譽,如“年度加密貨幣交易所”等。
 各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
機構投資者應選擇Coinbase Pro和Genesis Trading等合規平台,關注冷存儲比例與審計透明度;散戶投資者應選擇幣安和火幣等大平台,注重用戶體驗與安全;合規敏感地區的用戶可通過Circle Trade和Huobi Global進行法幣交易,中國大陸用戶需通過合規場外渠道。
 大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
選擇大宗交易平台時應考慮以下因素:1. 流動性:優先選擇日均交易量超50億美元的平台。 2. 合規性:查看平台是否持有美國FinCEN、歐盟MiCA等牌照。 3. 安全性:冷錢包存儲比例和保險機制是關鍵指標。 4. 服務能力:是否提供專屬客戶經理和定制化交易工具。
 支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
優先選擇合規平台如OKX和Coinbase,啟用多重驗證,資產自託管可減少依賴:1. 選擇有監管牌照的交易所;2. 開啟2FA和提幣白名單;3. 使用硬件錢包或支持自託管的平台。
 數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
gate.io(全球版)核心優勢是界面極簡,支持中文,法幣交易流程直觀;幣安(簡版)核心優勢是全球交易量第一,簡版模式僅保留現貨交易;OKX(香港版)核心優勢是界面簡潔,支持粵語/普通話,衍生品交易門檻低;火幣全球站(香港版)核心優勢是老牌交易所,推出元宇宙交易終端;KuCoin(中文社區版)核心優勢是支持800 幣種,界面採用微信式交互;Kraken(香港版)核心優勢是美國老牌交易所,持有香港SVF牌照,界面簡潔;HashKey Exchange(香港持牌)核心優勢是香港知名持牌交易所,支持法
 幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
國內用戶適配方案包括合規渠道和本地化工具。 1. 合規渠道:通過OTC平台如Circle Trade進行法幣兌換,境內需通過香港或海外平台。 2. 本地化工具:使用幣圈網獲取中文資訊,火幣全球站提供元宇宙交易終端。
 數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
提供各種複雜的交易工具和市場分析。覆蓋 100 多個國家,日均衍生品交易量超 300 億美元,支持 300 多個交易對與 200 倍槓桿,技術實力強大,擁有龐大的全球用戶基礎,提供專業的交易平台、安全存儲解決方案以及豐富的交易對。
