
大模型又「爆了」。
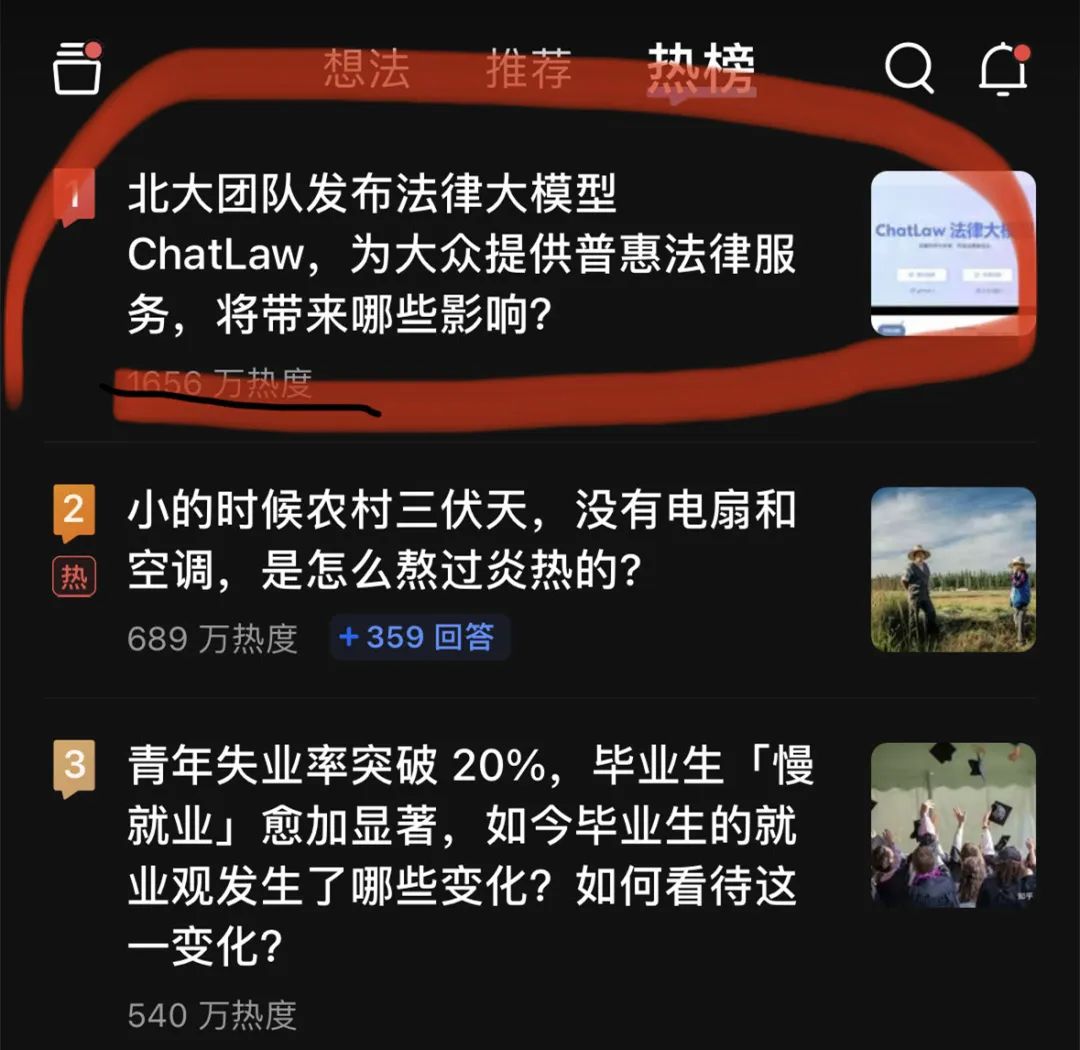
昨晚,一個法律大模型 ChatLaw 登上了知乎熱搜榜榜首。熱度最高時達到了 2000 萬左右。
這個 ChatLaw 由北大團隊發布,致力於提供普惠的法律服務。一方面目前全國執業律師不足,供給遠小於法律需求;另一方面一般人對法律知識和條文有天然鴻溝,無法運用法律武器保護自己。
大語言模型最近的崛起正好為普通人以對話方式諮詢法律相關問題提供了一個絕佳契機。
目前,ChatLaw 共有三個版本,分別如下:
根據官方演示,ChatLaw 支援使用者上傳檔案、錄音等法律資料,幫助他們歸納和分析,產生視覺化導圖、圖表等。此外,ChatLaw 可以基於事實產生法律建議、法律文件。該專案在 GitHub 上的 Star 量達到了 1.1k。
 圖片
圖片
官網網址:https://www.chatlaw.cloud/
#論文地址:https://arxiv.org/pdf/2306.16092.pdf
這是我們的GitHub 專案連結:https://github.com/PKU-YuanGroup /ChatLaw
目前,由於ChatLaw 專案太過火爆,伺服器暫時崩潰,算力已達上限。團隊正在修復,有興趣的讀者可以在 GitHub 上部署測試版模型。
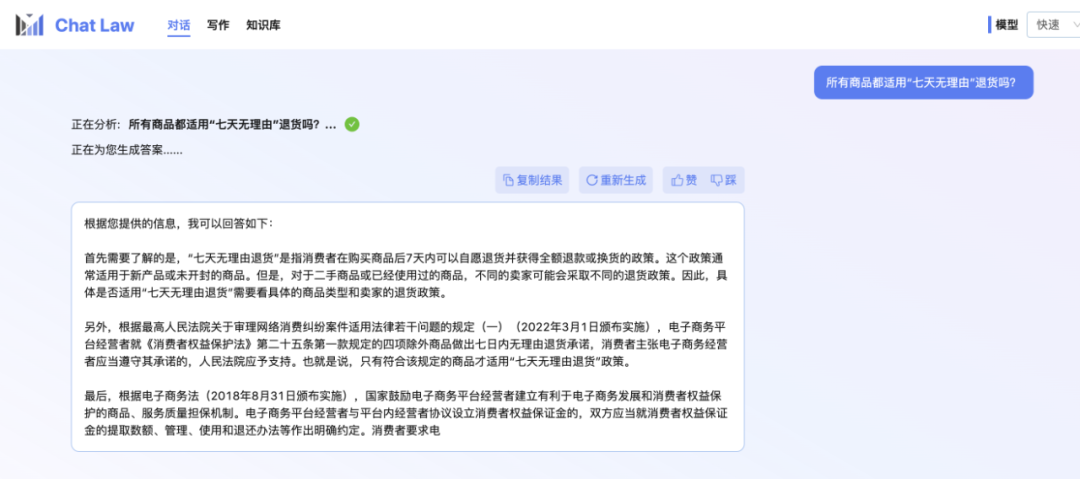
小編本人也還在內測排隊中。所以這裡先展示一個 ChatLaw 團隊提供的官方對話範例,關於日常網購時可能會遇到的「七天無理由退貨」問題。不得不說,ChatLaw 回答挺全的。
 圖片
圖片
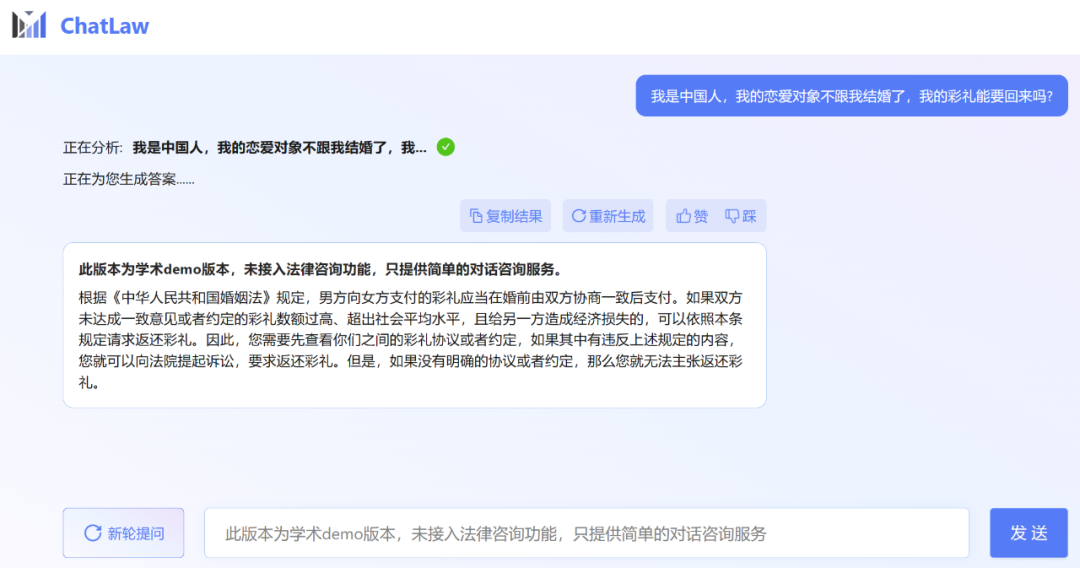
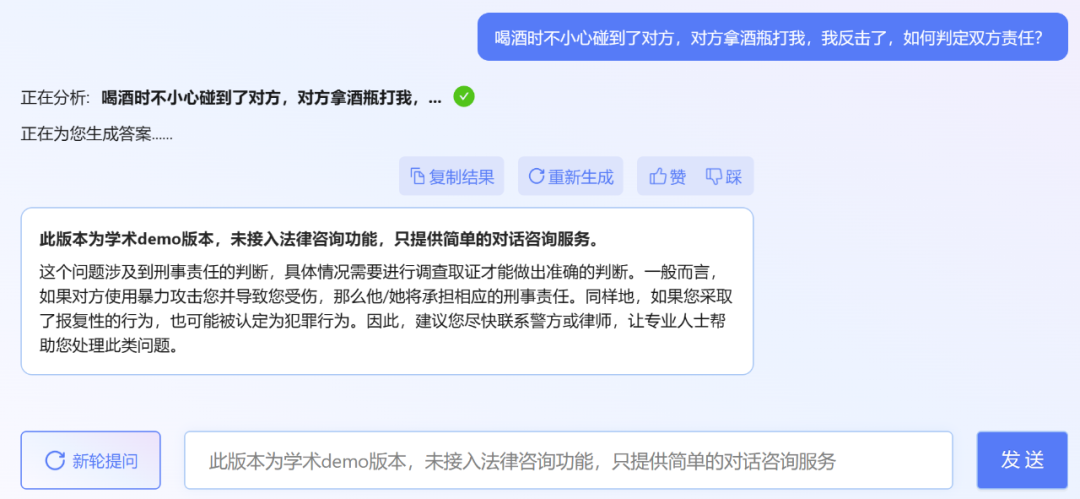
不過,小編發現,ChatLaw 的學術demo 版本可以試用,遺憾的是沒有接取法律諮詢功能,只提供了簡單的對話諮詢服務。這裡嘗試問了幾個問題。
 圖片
圖片
#其實最近發布法律大模型的不只北大一家。上個月底,冪律智慧聯合智譜 AI 發表了千億參數級法律垂直大模型 PowerLawGLM。據悉該模型針對中文法律場景的應用效果展現了獨特優勢。
#首先是資料組成。 ChatLaw 資料主要由論壇、新聞、法條、司法解釋、法律諮詢、法考題、判決文件組成,隨後經過清洗、資料增強等來建構對話資料。同時,透過與北大國際法學院、業界知名律師事務所合作,ChatLaw 團隊得以確保知識庫能及時更新,同時確保資料的專業性和可靠性。下面我們來看看具體範例。
基於法律法規和司法解釋的建構範例:

抓取真實法律諮詢資料範例:

#律師考試多項選擇題的建構範例:
 #圖片
#圖片
然後是模型層面。為了訓練 ChatLAW,研究團隊在 Ziya-LLaMA-13B 的基礎上使用低秩自適應 (Low-Rank Adaptation, LoRA) 對其進行了微調。此外,研究還引入 self-suggestion 角色,來緩解模型產生幻覺問題。訓練過程在多個 A100 GPU 上進行,並藉助 deepspeed 進一步降低了訓練成本。
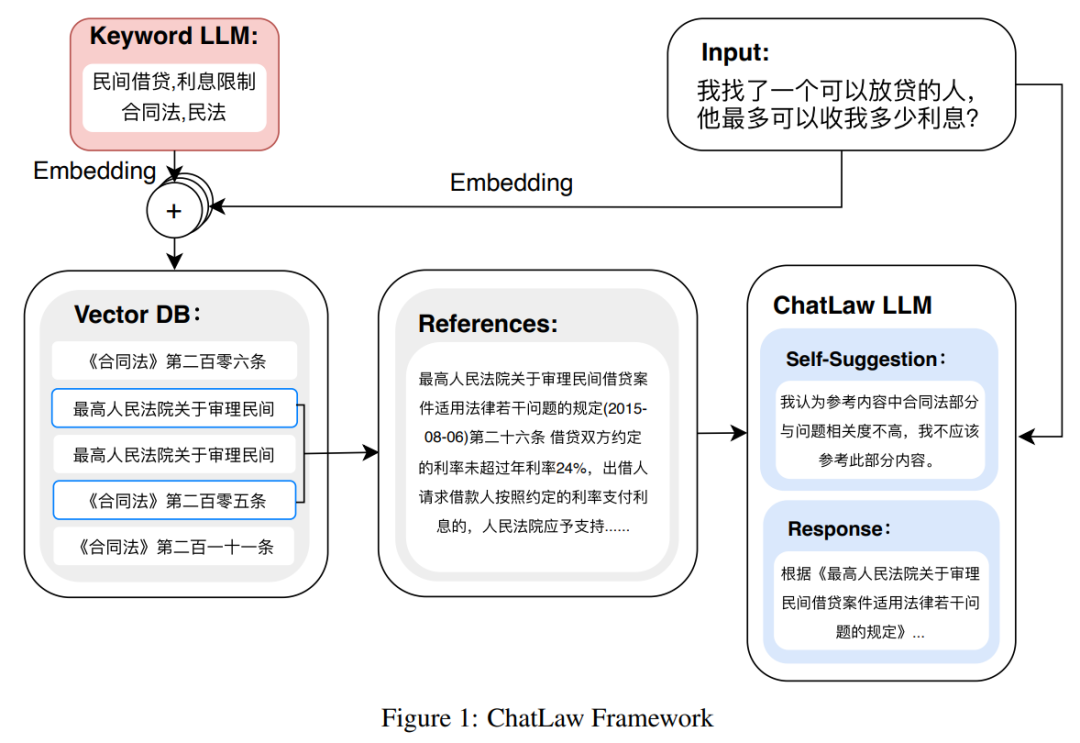
如下圖為ChatLAW 架構圖,該研究將法律資料注入模型,並對這些知識進行特殊處理和加強;同時,他們也在推理時引入多個模組,將通識模型、專業模型和知識庫融為一體。
該研究也在推理中對模型進行了約束,這樣才能確保模型產生正確的法律法規,盡可能減少模型幻覺。
 圖片
圖片
一開始研究團隊嘗試傳統的軟體開發方法,如檢索時採用MySQL 和Elasticsearch,但結果不盡如人意。因而,研究開始嘗試預先訓練 BERT 模型來進行嵌入,然後使用 Faiss 等方法以計算餘弦相似度,提取與使用者查詢相關的前 k 個法律法規。
當使用者的問題模糊不清時,這種方法通常會產生次優的結果。因此,研究者從用戶查詢中提取關鍵訊息,並利用該資訊的向量嵌入設計演算法,以提高匹配準確性。
由於大型模型在理解用戶查詢方面具有顯著優勢,因此研究對 LLM 進行了微調,以便從用戶查詢中提取關鍵字。在獲得多個關鍵字後,研究採用演算法 1 檢索相關法律規定。
 圖片
圖片
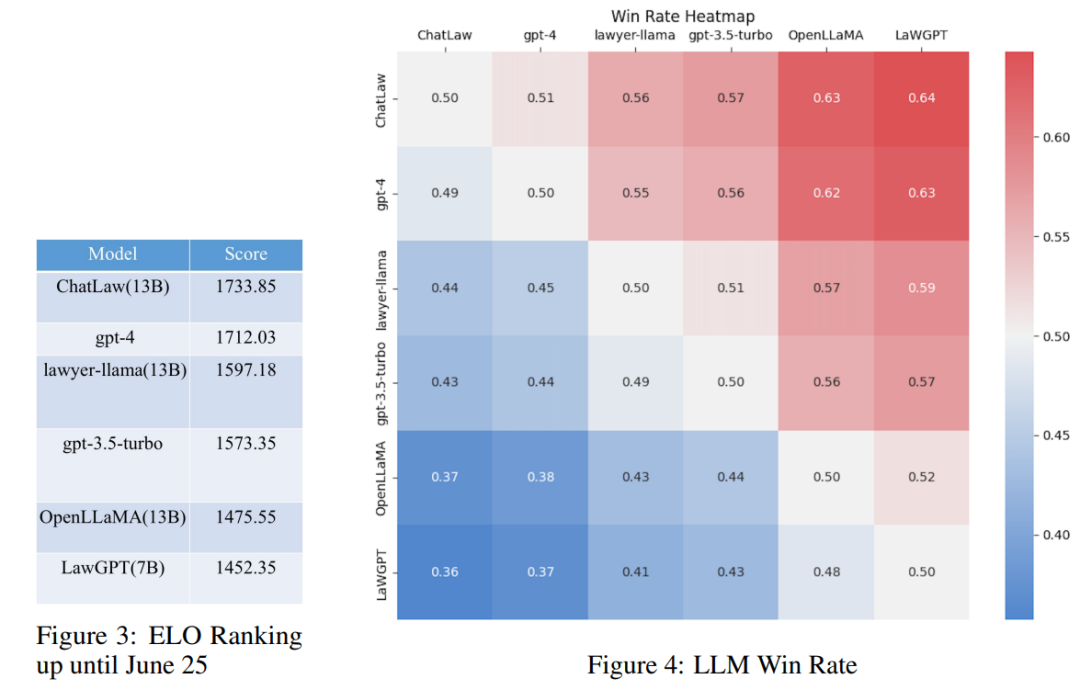
該研究收集了十餘年的國家司法考試題目,整理出了一個包含2000 個問題及其標準答案的測驗資料集,以衡量模型處理法律選擇題的能力。
然而,研究發現各模型的準確率普遍偏低。在這種情況下,僅對準確率進行比較並無太大意義。因此,研究借鑒英雄聯盟的 ELO 配對機制,做了一個模型對抗的 ELO 機制,以便更有效評估各模型處理法律選擇題的能力。以下分別是ELO 分數和勝率圖:
 圖片
圖片
透過上述實驗結果的分析,我們可以得到以下觀察結果
(1)引入與法律相關的問答和法規條文的數據,可以在一定程度上提高模型在選擇題上的表現;
(2)加入特定類型任務的資料進行訓練,模型在該類別任務上的表現會明顯提升。例如,ChatLaw 模型優於GPT-4 的原因是文中使用了大量的選擇題作為訓練資料;
(3)法律選擇題需要複雜的邏輯推理,因此,參數量較大的模型通常表現較優。
參考知乎連結:
https://www.zhihu.com/question/610072848
#其他參考連結:
https://mp.weixin.qq.com/s/bXAFALFY6GQkL30j1sYCEQ
#以上是擠爆伺服器,北大法律大模型ChatLaw火了:直接告訴你張三怎麼判的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















