

微軟新出熱乎論文:Transformer擴展到10億token

當大家不斷升級迭代自家大模型的時候,LLM(大語言模型)對上下文視窗的處理能力,也成為一個重要評估指標。
例如明星大模型GPT-4 支援32k token,相當於50 頁的文字;OpenAI 前成員創立的Anthropic 更是將Claude 處理token 能力提升到100k,約75,000 個單字,大概相當於一鍵總結《哈利波特》第一部。
在微軟最新的一項研究中,他們這次直接將 Transformer 擴展到 10 億 token。這為建模非常長的序列開闢了新的可能性,例如將整個語料庫甚至整個互聯網視為一個序列。
作為比較,普通人可以在 5 小時左右的時間內閱讀 100,000 個 token,並可能需要更長的時間來消化、記憶和分析這些資訊。 Claude 可以在不到 1 分鐘的時間內完成這些。要是換算成微軟的這項研究,將會是個驚人的數字。
 圖片
圖片
- #論文網址:https://arxiv.org/pdf/2307.02486.pdf
- 專案網址:https://github.com/microsoft/unilm/tree/master
具體而言,研究提出了LONGNET,這是一種Transformer 變體,可以將序列長度擴展到超過10 億個token,而不會犧牲對較短序列的性能。文中也提出了 dilated attention,它能指數級擴展模型感知範圍。
LONGNET 有以下優點:
1)它具有線性計算複雜度;
2)它可以作為較長序列的分散式訓練器;
3)dilated attention 可以無縫取代標準注意力,並可以與現有基於Transformer 的最佳化方法無縫集成。
實驗結果表明,LONGNET 在長序列建模和一般語言任務上都表現出強烈的表現。
在研究動機方面,論文表示,最近幾年,擴展神經網路已經成為一種趨勢,許多表現良好的網路被研究出來。在這當中,序列長度作為神經網路的一部分,理想情況下,其長度應該是無限的。但現實卻往往相反,因而打破序列長度的限制將會帶來顯著的優勢:
- 首先,它為模型提供了大容量的記憶和感受野,使其能夠與人類和世界進行有效的互動。
- 其次,更長的上下文包含了更複雜的因果關係和推理路徑,模型可以在訓練資料中加以利用。相反,較短的依賴關係則會引入更多虛假的相關性,不利於模型的泛化性。
- 第三,更長的序列長度可以幫助模型探索更長的上下文,而極長的上下文也有助於模型緩解災難性遺忘問題。
然而,擴展序列長度面臨的主要挑戰是在計算複雜性和模型表達能力之間找到合適的平衡。
例如 RNN 風格的模型主要用於增加序列長度。然而,其序列特性限制了訓練過程中的並行化,而平行化在長序列建模中是至關重要的。
最近,狀態空間模型對序列建模非常有吸引力,它可以在訓練過程中作為 CNN 運行,並在測試時轉換為高效的 RNN。然而這類模型在常規長度上的表現不如 Transformer。
另一種擴展序列長度的方法是降低 Transformer 的複雜性,即自註意力的二次複雜性。現階段,一些高效率的基於 Transformer 的變體被提出,包括低秩注意力、基於核的方法、下採樣方法、基於檢索的方法。然而,這些方法尚未將 Transformer 擴展到 10 億 token 的規模(參見圖 1)。
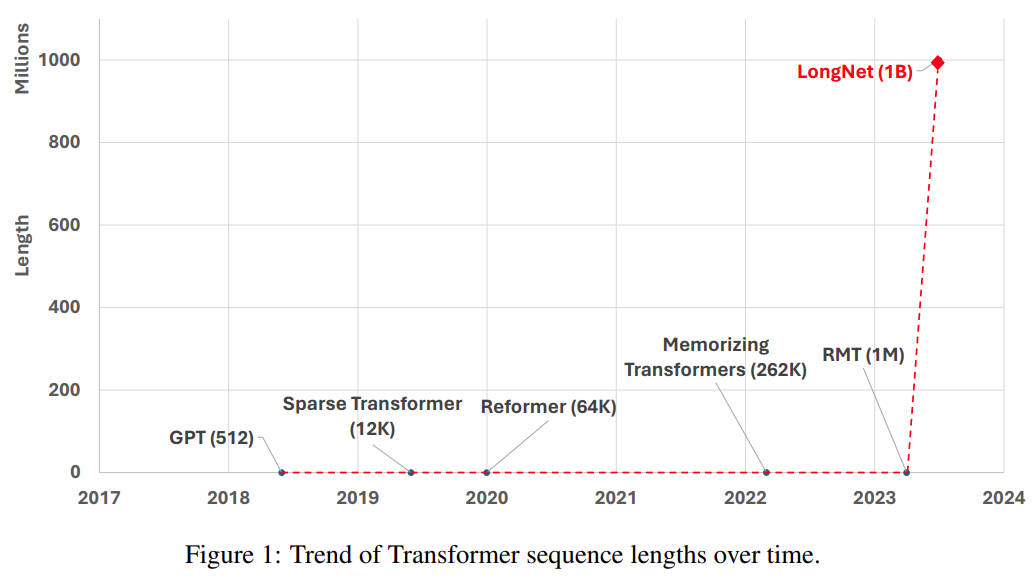 圖片
圖片
下表為不同計算方法的計算複雜度比較。 N 為序列長度,d 為隱藏維數。
 圖片
圖片
方法
該研究的解決方案 LONGNET 成功地將序列長度擴展到 10 億個 token。具體來說,該研究提出一種名為 dilated attention 的新組件,並以 dilated attention 取代了 Vanilla Transformer 的注意力機制。通用的設計原則是注意力的分配隨著 token 和 token 之間距離的增加而呈指數級下降。該研究表明這種設計方法獲得了線性計算複雜度和 token 之間的對數依賴性。這解決了注意力資源有限和可訪問每個 token 之間的矛盾。
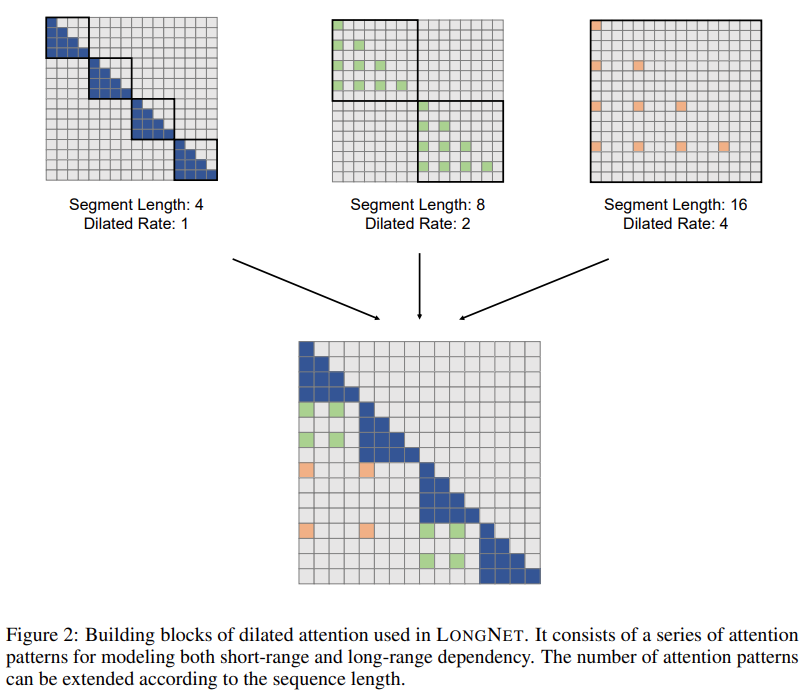 圖片
圖片
在實作過程中,LONGNET 可以轉換成一個密集Transformer,以無縫地支援針對Transformer 的現有最佳化方法(例如內核融合(kernel fusion)、量化和分佈式訓練)。利用線性複雜度的優勢,LONGNET 可以跨節點並行訓練,以分散式演算法打破計算和記憶體的限制。
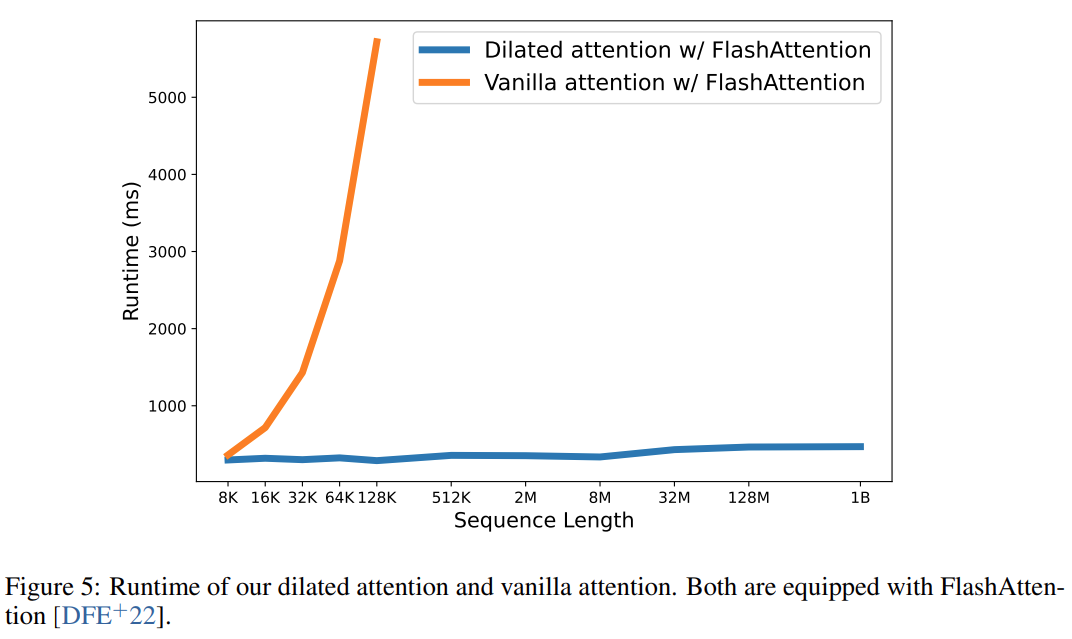
最終,該研究有效地將序列長度擴大到 1B 個 token,而且運行時(runtime)幾乎是恆定的,如下圖所示。相較之下,Vanilla Transformer 的運作時則會受到二次複雜度的影響。
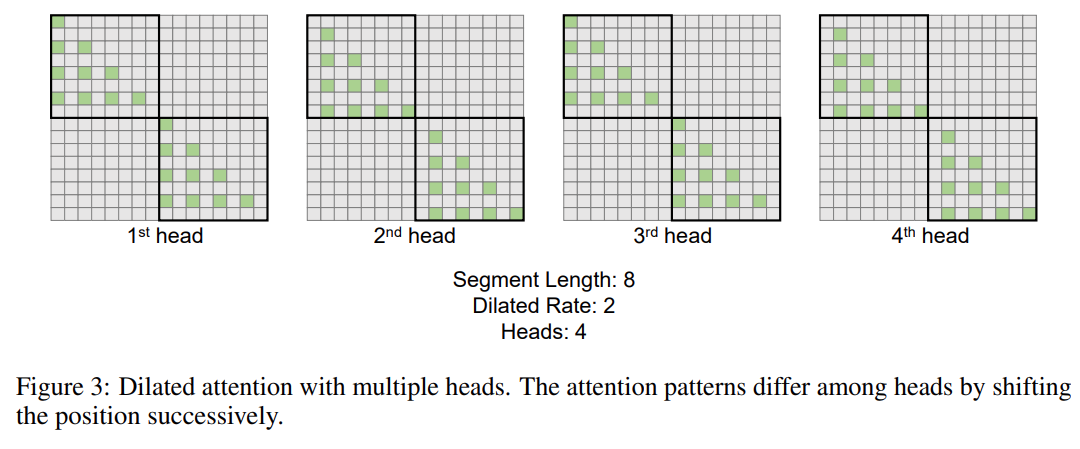
該研究進一步引入了多頭 dilated attention 機制。如下圖 3 所示,該研究透過對查詢 - 鍵 - 值對的不同部分進行稀疏化,在不同的頭之間進行不同的計算。
 圖片
圖片
分散式訓練
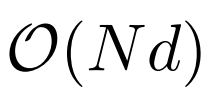 雖然dilated attention 的計算複雜度已經大幅降低到
雖然dilated attention 的計算複雜度已經大幅降低到
,但由於計算和內存的限制,在單個GPU 設備上將序列長度擴展到百萬級別是不可行的。有一些用於大規模模型訓練的分散式訓練演算法,如模型並行[SPP 19]、序列並行[LXLY21, KCL 22] 和pipeline 並行[HCB 19],然而這些方法對於LONGNET 來說是不夠的,特別是當序列維度非常大時。
本研究利用 LONGNET 的線性運算複雜度來進行序列維度的分散式訓練。下圖 4 展示了在兩個 GPU 上的分散式演算法,還可以進一步擴展到任意數量的裝置。 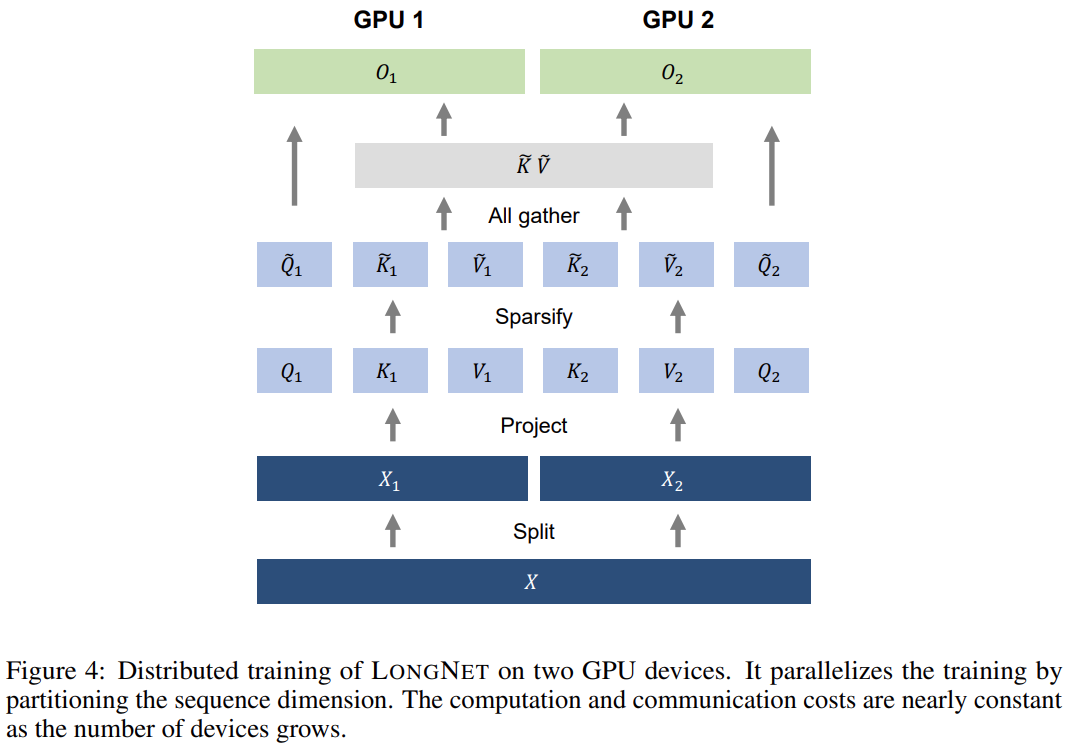
實驗
#該研究將LONGNET與vanilla Transformer 和稀疏Transformer 進行了比較。架構之間的差異是注意力層,而其他層保持不變。研究人員將這些模型的序列長度從 2K 擴展到 32K,同時減少 batch 大小,以確保每個 batch 的 token 數量不變。
表 2 總結了這些模型在 Stack 資料集上的結果。研究使用複雜度作為評估指標。這些模型使用不同的序列長度進行測試,範圍從 2k 到 32k 不等。當輸入長度超過模型支援的最大長度時,研究實現了分塊因果注意力(blockwise causal attention,BCA)[SDP 22],這是一種最先進的語言模型推理的外推方法。
此外,研究刪除了絕對位置編碼。首先,結果表明,在訓練過程中增加序列長度一般會得到更好的語言模型。其次,在長度遠大於模型支持的情況下,推理中的序列長度外推法並不適用。最後,LONGNET 一直優於基準模型,證明了其在語言建模中的有效性。 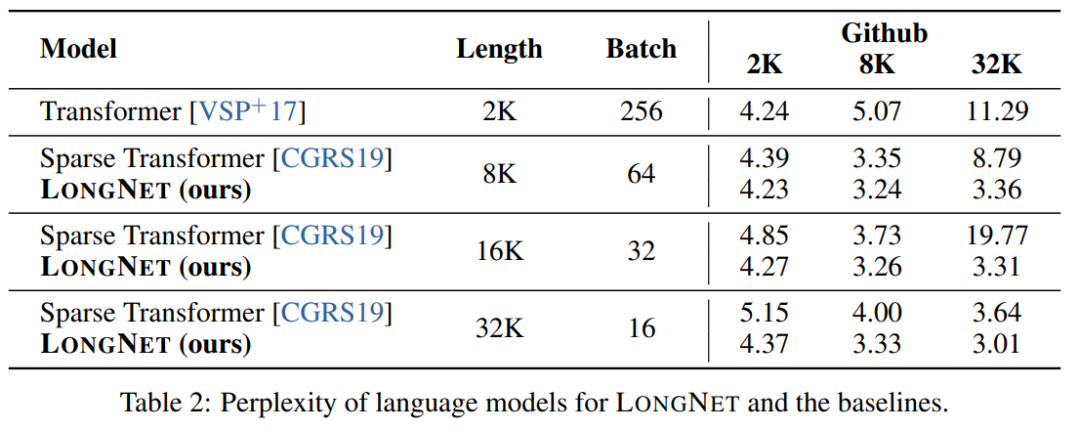
序列長度的擴展曲線
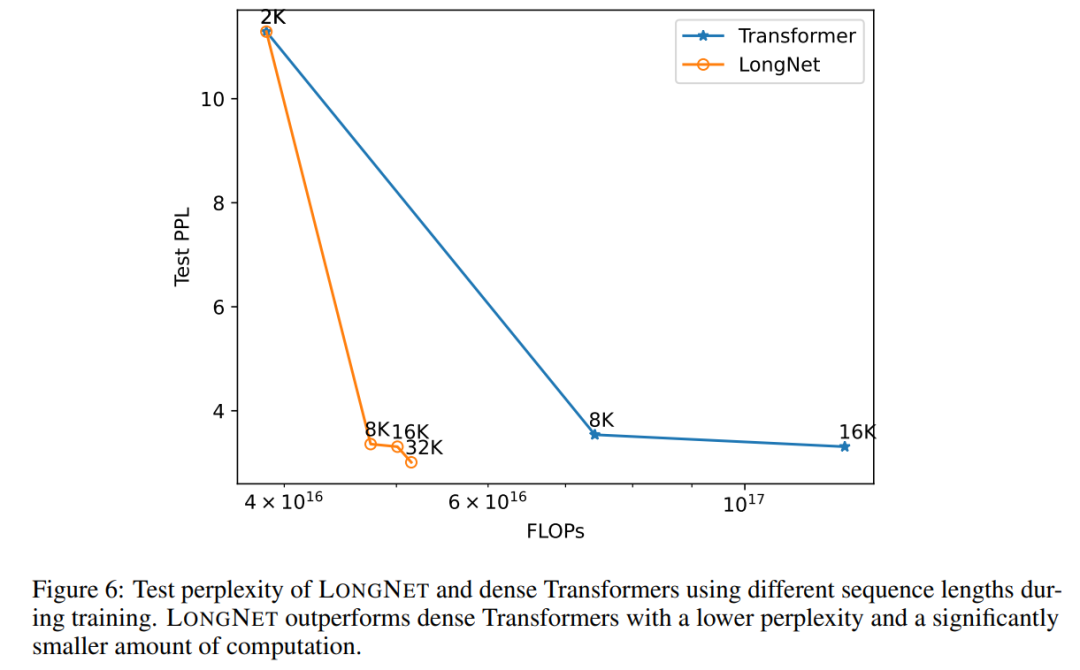
#########圖 6 繪製了 vanilla transformer 和 LONGNET 的序列長度擴展曲線。該研究透過計算矩陣乘法的總 flops 來估計計算量。結果表明,vanilla transformer 和 LONGNET 都能從訓練中獲得更大的上下文長度。然而,LONGNET 可以更有效地擴展上下文長度,以較小的計算量實現較低的測試損失。這證明了較長的訓練輸入比外推法更具優勢。實驗表明,LONGNET 是一種更有效的擴展語言模型中上下文長度的方法。這是因為 LONGNET 可以更有效地學習較長的依賴關係。
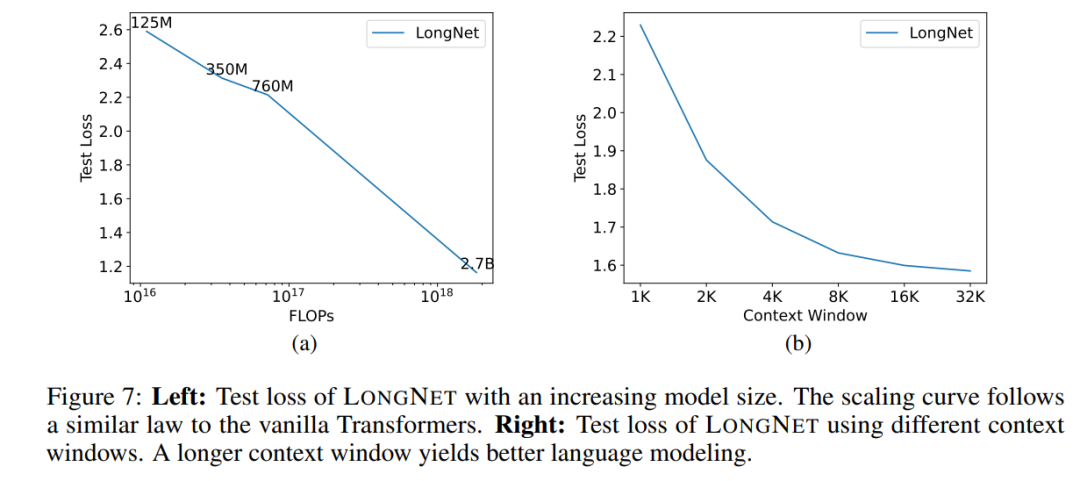
##大型語言模型的一個重要屬性是:損失隨著計算量的增加呈冪律擴展。為了驗證 LONGNET 是否仍遵循類似的擴展規律,該研究以不同的模型規模(從 1.25 億到 27 億個參數) 訓練了一系列模型。 27 億的模型是用 300B 的 token 訓練的,而其餘的模型則用到了大約 400B 的 token。圖 7 (a) 繪製了 LONGNET 關於計算的擴展曲線。該研究在相同的測試集上計算了複雜度。這證明了 LONGNET 仍然可以遵循冪律。這也意味著 dense Transformer 不是擴展語言模型的先決條件。此外,可擴展性和效率都是由 LONGNET 獲得的。
長上下文prompt
######Prompt 是引導語言模型並為其提供額外資訊的重要方法。該研究透過實驗來驗證 LONGNET 是否能從較長的上下文提示視窗中獲益。 ############研究保留了一段前綴(prefixes)作為 prompt,並測試其後綴(suffixes)的困惑度。並且,研究過程中,逐漸將 prompt 從 2K 擴展到 32K。為了進行公平的比較,保持後綴的長度不變,而將前綴的長度增加到模型的最大長度。圖 7 (b) 報告了測試集上的結果。它表明,隨著上下文視窗的增加,LONGNET 的測試損失逐漸減少。這證明了 LONGNET 在充分利用長語境來改進語言模型方面的優越性。 ######
以上是微軟新出熱乎論文:Transformer擴展到10億token的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



![如何在工作列上顯示網路速度[簡單步驟]](https://img.php.cn/upload/article/000/465/014/169088173253603.png?x-oss-process=image/resize,m_fill,h_207,w_330) 如何在工作列上顯示網路速度[簡單步驟]
Aug 01, 2023 pm 05:22 PM
如何在工作列上顯示網路速度[簡單步驟]
Aug 01, 2023 pm 05:22 PM
網路速度是決定線上體驗結果的重要參數。無論是文件下載或上傳,還是只是瀏覽網頁,我們都需要一個體面的網路連線。這就是為什麼用戶尋找在工作列上顯示網路速度的方法。將網路速度顯示在工作列中允許使用者快速監控事物,無論手頭上的任務是什麼。工作列始終可見,除非您處於全螢幕模式。但是Windows不提供在工作列中顯示網路速度的本機選項。這就是為什麼您需要第三方工具的原因。繼續閱讀以了解有關最佳選擇的所有資訊!如何在Windows命令列中執行速度測試?按+開啟“運轉”,鍵入電源外殼,然後按++。 Window
 修正問題:在 Windows 11 安全模式下無法存取網際網路的網路連線問題
Sep 23, 2023 pm 01:13 PM
修正問題:在 Windows 11 安全模式下無法存取網際網路的網路連線問題
Sep 23, 2023 pm 01:13 PM
在具有網路連線的安全模式下,Windows11電腦上沒有網路連線可能會令人沮喪,尤其是在診斷和排除係統問題時。在本指南中,我們將討論問題的潛在原因,並列出有效的解決方案,以確保您在安全模式下可以存取網路。為什麼在網路連線的安全模式下沒有網路?網路適配器不相容或未正確載入。第三方防火牆、安全軟體或防毒軟體可能會幹擾安全模式下的網路連線。網路服務未運作。惡意軟體感染如果互聯網無法在Windows11的安全模式下使用網絡,我該怎麼辦?在執行進階故障排除步驟之前,應考慮執行以下檢查:請確保使
 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 ICCV'23論文頒獎「神仙打架」! Meta分割一切和ControlNet共同入選,還有一篇讓評審很驚訝
Oct 04, 2023 pm 08:37 PM
ICCV'23論文頒獎「神仙打架」! Meta分割一切和ControlNet共同入選,還有一篇讓評審很驚訝
Oct 04, 2023 pm 08:37 PM
在法國巴黎舉行的電腦視覺頂峰大會ICCV2023剛結束!今年的最佳論文獎,簡直是「神仙打架」。例如,兩篇獲得最佳論文獎的論文中,就包括顛覆文生圖AI領域的著作-ControlNet。自從開源以來,ControlNet已經在GitHub上獲得了24k個星星。無論是對於擴散模型還是整個電腦視覺領域來說,這篇論文的獲獎都是實至名歸的而最佳論文獎榮譽提名,則頒給了另一篇同樣出名的論文,Meta的「分割一切”模型SAM。自推出以來,“分割一切”已經成為了各種圖像分割AI模型的“標竿”,包括後來居上的
 論文插圖也能自動生成了,用到了擴散模型,還被ICLR接收
Jun 27, 2023 pm 05:46 PM
論文插圖也能自動生成了,用到了擴散模型,還被ICLR接收
Jun 27, 2023 pm 05:46 PM
生成式AI已經風靡了人工智慧社區,無論是個人還是企業,都開始熱衷於創建相關的模態轉換應用,例如文生圖、文生影片、文生音樂等等。最近呢,來自ServiceNowResearch、LIVIA等科研機構的幾位研究者嘗試以文字描述來產生論文中的圖表。為此,他們提出了一種FigGen的新方法,相關論文也被ICLR2023收錄為了TinyPaper。圖片論文網址:https://arxiv.org/pdf/2306.00800.pdf也許有人會問了,產生論文中的圖表有什麼難的呢?這樣做對科學研究又有哪些幫助呢
 聊天截圖曝出AI頂會審稿潛規則! AAAI 3000塊即可strong accept?
Apr 12, 2023 am 08:34 AM
聊天截圖曝出AI頂會審稿潛規則! AAAI 3000塊即可strong accept?
Apr 12, 2023 am 08:34 AM
正值AAAI 2023論文截止提交之際,知乎上突然出現了一張AI投稿群的匿名聊天截圖。其中有人聲稱,自己可以提供「3000塊一個strong accept」的服務。爆料一出,頓時引起了網友的公憤。不過,先不要急。知乎大佬「微調」表示,這大機率只是「口嗨」而已。根據「微調」透露,打招呼和團體犯案這個是任何領域都不能避免的問題。隨著openreview的興起,cmt的各種缺點也越來越清楚,未來留給小圈子操作的空間會變小,但永遠會有空間。因為這是個人的問題,不是投稿系統和機制的問題。引入open r
 NeRF與自動駕駛的前世今生,近10篇論文總結!
Nov 14, 2023 pm 03:09 PM
NeRF與自動駕駛的前世今生,近10篇論文總結!
Nov 14, 2023 pm 03:09 PM
神經輻射場(NeuralRadianceFields)自2020年被提出以來,相關論文數量呈指數增長,不僅成為了三維重建的重要分支方向,也逐漸作為自動駕駛重要工具活躍在研究前沿。 NeRF這兩年異軍突起,主要因為它跳過了傳統CV重建pipeline的特徵點提取和匹配、對極幾何與三角化、PnP加BundleAdjustment等步驟,甚至跳過mesh的重建、貼圖和光追,直接從2D輸入影像學習一個輻射場,然後從輻射場輸出逼近真實照片的渲染影像。也就是說,讓一個基於神經網路的隱式三維模型,去擬合指定視角
 華人團隊斬獲最佳論文、最佳系統論文獎項,CoRL研究成果獲獎公佈
Nov 10, 2023 pm 02:21 PM
華人團隊斬獲最佳論文、最佳系統論文獎項,CoRL研究成果獲獎公佈
Nov 10, 2023 pm 02:21 PM
自2017年首次舉辦以來,CoRL已成為了機器人學與機器學習交叉領域的全球頂級學術會議之一。 CoRL是機器人學習研究的單一主題會議,涵蓋了機器人學、機器學習和控制等多個主題,包括理論與應用2023年的CoRL大會將於11月6日至9日在美國亞特蘭大舉行。根據官方數據透露,今年有來自25個國家的199篇論文入選CoRL。熱門主題包括操作、強化學習等。雖然相較於AAAI、CVPR等大型AI學術會議,CoRL的規模較小,但隨著今年大模型、具身智能、人形機器人等概念的熱度上升,值得關注的相關研究也會
