

陳丹琦ACL學術報告來了!詳解大模型「外掛」資料庫7大方向3大挑戰,3小時乾貨滿滿

清華姚班校友陳丹琦,在ACL 2023上做了一場最新演講!
主題還是近期非常熱門的研究方向-
像GPT-3、PaLM這樣的(大)語言模型,究竟是否需要依賴檢索來彌補自身缺陷,以便更好地應用落地。
在這場演講中,她和其他3位主講人一起,共同介紹了這個主題的幾大研究方向,包括訓練方法、應用和挑戰等。
 圖片
圖片
演講期間聽眾的反應也很熱烈,不少網友認真地提出了自己的問題,幾位演講者盡力答疑解惑。
 圖片
圖片
至於這次演講具體效果如何?有網友直接一句「推薦」給到留言區。
 圖片
圖片
所以,在這場長達3小時的演講中,他們具體講了什麼?又有哪些值得一聽的地方呢?
大模型為何需要「外掛」資料庫?
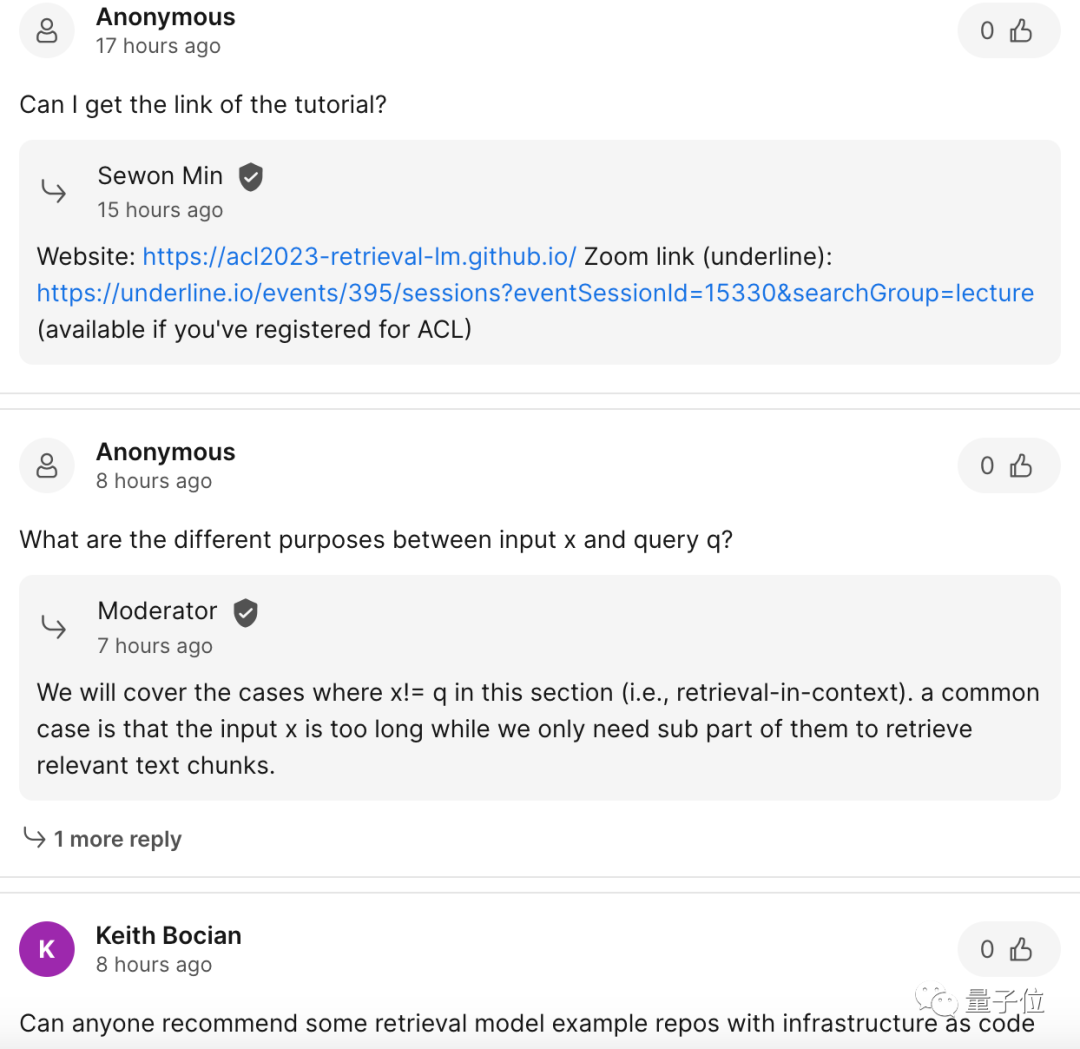
這場演講的核心主題是“基於檢索的語言模型”,包含檢索和語言模型兩個要素。
從定義上來看,它指的是給語言模型「外掛」一個資料檢索庫,並在進行推理(等操作)時對這個資料庫進行檢索,最後基於檢索結果進行輸出。
這類外掛資料儲存庫,也稱為半參數模型或非參數模型。
 圖片
圖片
之所以要研究這個方向,是因為如GPT-3和PaLM這類(大)語言模型,在表現出不錯的效果同時,也出現了一些讓人頭疼的“bug”,主要有三個問題:
1、參數量過大,如果基於新數據重訓練,計算成本過高;
2、記憶力不行(面對長文本,記了下文忘了上文),時間一長會產生幻覺,且容易洩漏資料;
3、目前的參數量,不可能記住所有知識。
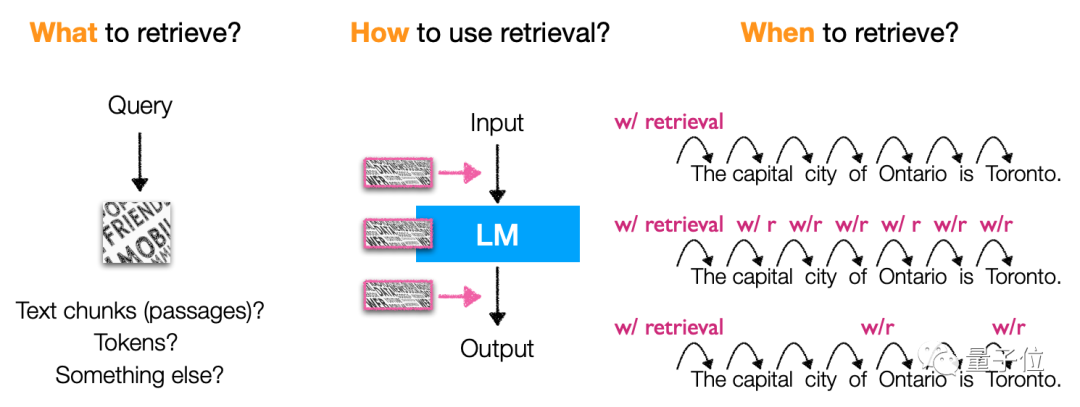
在這種情況下,外部檢索語料庫被提出,即給大語言模型「外掛」一個資料庫,讓它隨時能透過查找資料來回答問題,而且由於這種資料庫隨時能更新,也不用擔心重訓的成本問題。
介紹完定義和背景之後,就是這個研究方向具體的架構、訓練、多模態、應用和挑戰了。
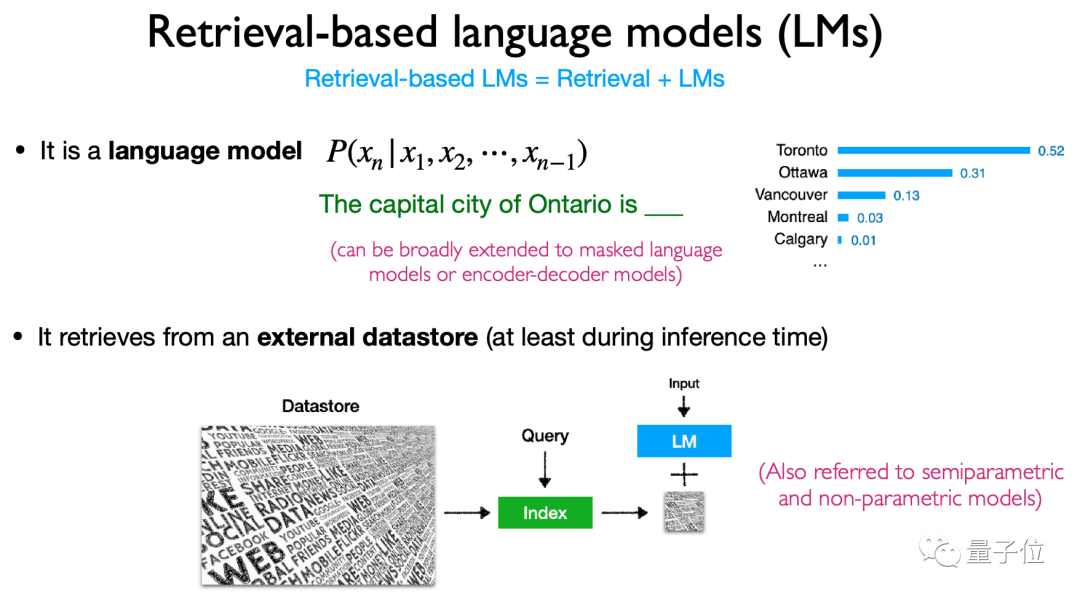
在架構上,主要介紹了基於檢索的語言模型檢索的內容、檢索的方式和檢索的「時機」。
具體而言,這類模型主要會檢索token、文字區塊和實體字詞(entity mentions),使用檢索的方式和時機也很多樣性,是一類很靈活的模型架構。
 圖片
圖片
在訓練方式上,則著重介紹了獨立訓練(independent training,語言模型和檢索模型分開訓練)、連續學習(sequential training)、多任務學習(joint training)等方法。
 圖片
圖片
至於應用程式方面,這類模型涉及的也就比較多了,不僅可以用在程式碼產生、在分類、知識密集NLP等任務上,而且透過微調、強化學習、基於檢索的提示詞等方法就能使用。
應用程式場景也很靈活,包括長尾場景、需要知識更新的場景以及涉及隱私安全的場景等,都有這類模型的用武之地。
當然,不只文本上。這類模型也存在著多模態擴充的潛力,可以將它用於文字以外的任務。
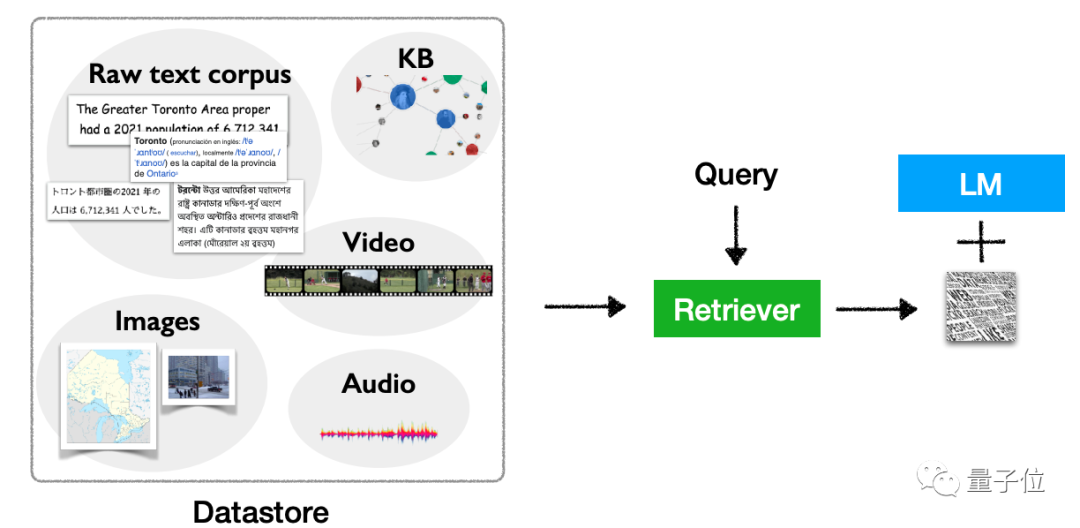 圖片
圖片
聽起來這類模型優點很多,不過基於檢索的語言模型,當下也存在一些挑戰。
陳丹琦在最後「收尾」的演講中,著重提到了幾點這個研究方向需要解決的幾大難題。
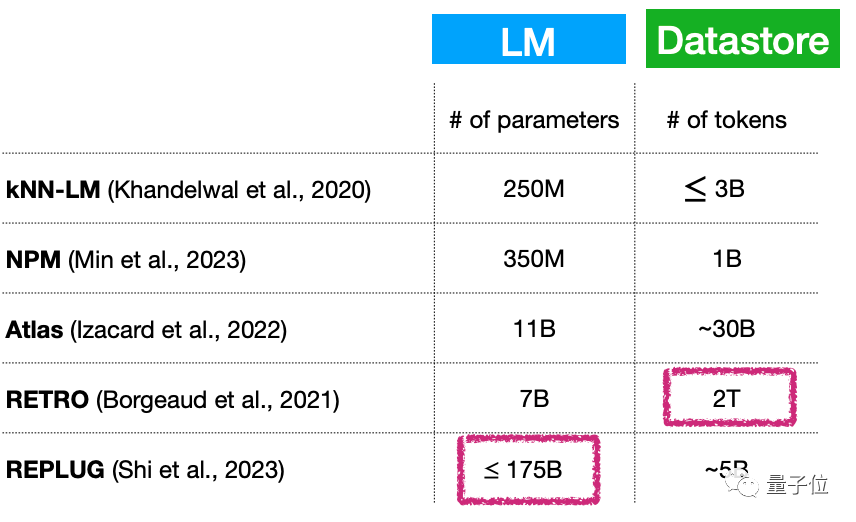
其一,小語言模型 (不斷擴張的)大資料庫,本質上是否意味著語言模型的參數量依舊很大?如何解決這一問題?
例如,雖然這類模型的參數量可以做到很小,只有70億參數量,但外掛的資料庫卻能達到2T…
 圖片
圖片
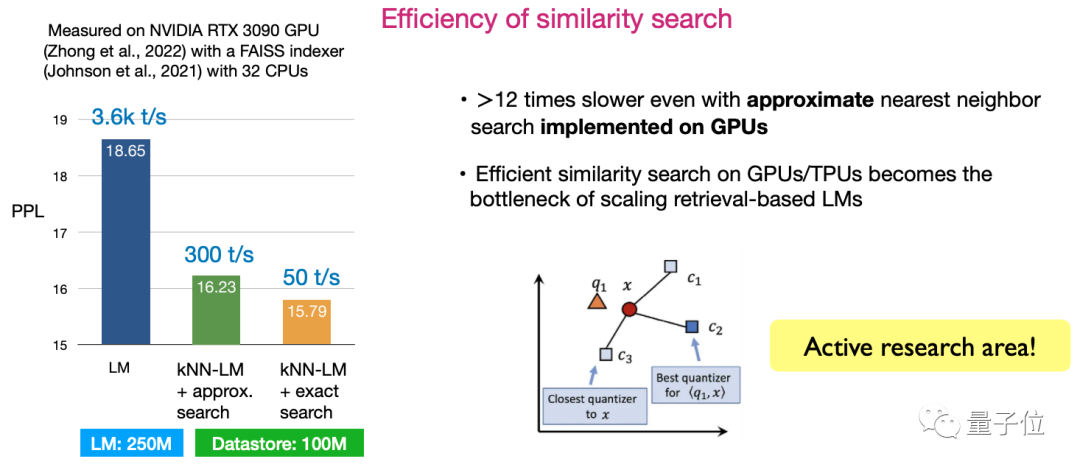
其二,相似性搜尋的效率。如何設計演算法使得搜尋效率最大化,是目前非常活躍的研究方向。
 圖片
圖片
其三,完成複雜語言任務。包括開放式文本生成任務,以及複雜的文本推理任務在內,如何以基於檢索的語言模型完成這些任務,也是需要持續探索的方向。
 圖片
圖片
當然,陳丹琦也提到,這些主題是挑戰的同時,也是研究機會。還在尋找論文課題的小夥伴們,可以考慮是否把它們加進研究列表了~
值得一提的是,這次演講也不是「憑空」找出的話題,4位演講者貼心在官網放出了演講參考的論文連結。
從模型架構、訓練方法、應用、多模態到挑戰,如果對這些主題中的任何一部分感興趣,都可以到官網找對應的經典論文來看:


圖片
現場解答聽眾困惑這麼乾貨滿滿的演講,四位主講人也不是沒有來頭,在演講中他們還耐心地對聽眾提出的問題進行了解答。 我們先來康康主講人是誰。 首先是主導這次演講的普林斯頓大學電腦科學助理教授陳丹琦。
圖片 她是電腦科學領域近來最受矚目的華人青年學者之一,也是08級清華姚班校友。
她是電腦科學領域近來最受矚目的華人青年學者之一,也是08級清華姚班校友。
CDQ分治演算法
就是以她的名字命名。 2008年,她代表中國隊獲得一枚IOI金牌。 ######而她的那篇長達156 頁的博士畢業論文《Neural Reading Comprehension and Beyond》,更是一度火爆出圈,不光獲得當年斯坦福最佳博士論文獎,還成為了斯坦福大學近十年來最熱門畢業論文之一。 ######現在,陳丹琦除了是普林斯頓大學電腦科學助理教授,也是該校從頭開始建立NLP小組的共同負責人、AIML小組成員。 ######她的研究方向主要聚焦於自然語言處理和機器學習,並且對在實際問題中具有可行性、可擴展性和可泛化性的簡單而可靠的方法饒有興趣。 ######同樣是來自普林斯頓大學的,還有陳丹琦的徒弟###鐘澤軒######(Zexuan Zhong)###。 ############圖片#########鐘澤軒是普林斯頓大學的四年級博士生。碩士畢業於伊利諾大學香檳分校,指導教授是謝濤;本科畢業於北京大學電腦系,曾在微軟亞研院實習,指導教授是聶再清。 ###他的最新研究主要聚焦於從非結構化文字中提取結構化資訊、從預訓練語言模型中提取事實性資訊、分析稠密檢索模型的泛化能力,以及開發適用於基於檢索的語言模型的訓練技術。
此外,主講人還有來自華盛頓大學的Akari Asai、Sewon Min。
 圖片
圖片
Akari Asai是華盛頓大學主攻自然語言處理的四年級博士生,本科畢業於日本東京大學。
她主要熱衷於開發可靠且適應性強的自然語言處理系統,提升資訊獲取的能力。
最近,她的研究主要集中在通用知識檢索系統、高效能自適應的NLP模型等領域。
 圖片
圖片
Sewon Min是華盛頓大學自然語言處理小組的博士候選人,讀博士期間,曾在Meta AI兼職擔任研究員長達四年,本科畢業於首爾國立大學。
最近她主要關注語言建模、檢索以及二者的交叉領域。
在演講期間,聽眾也很熱情地提出了許多問題,例如為啥要用perplexity(困惑度)來作為演講的主要指標。
 圖片
圖片
主講人給了細心解答:
在比較參數化的語言模型時,困惑度 (PPL)經常被用到。但困惑度的改善能否轉化為下游應用仍是研究問題。
現已有研究表明,困惑度與下游任務(尤其是生成任務)有很好的相關性,並且困惑度通常可提供非常穩定的結果,它可以在在大規模評估資料上進行評估(相對於下游任務來說,評估資料是沒有標籤的,而下游任務可能會受到提示的敏感性和缺乏大規模標記資料的影響,從而導致結果不穩定) 。
 圖片
圖片
也有網友提出了這樣的疑問:
關於「語言模型的訓練成本高昂,而引入檢索可能會解決這個問題」的說法,你只是將時間複雜度替換為空間複雜度(資料儲存)了嗎?

主講人給的解答是醬嬸的:
我們討論的重點是如何將語言模型縮減到更小,從而減少時間和空間的需求。然而,資料儲存實際上也增加了額外的開銷,這需要仔細權衡和研究,我們認為這是當前的挑戰。
與訓練一個擁有超過一百億個參數的語言模型相比,我認為目前最重要的是降低訓練成本。
 圖片
圖片
想找這次演講PPT,或是蹲具體回放的,可以去官網看看~
官方網址:https://acl2023-retrieval-lm.github.io/
#以上是陳丹琦ACL學術報告來了!詳解大模型「外掛」資料庫7大方向3大挑戰,3小時乾貨滿滿的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 iOS 18 新增「已復原」相簿功能 可找回遺失或損壞的照片
Jul 18, 2024 am 05:48 AM
iOS 18 新增「已復原」相簿功能 可找回遺失或損壞的照片
Jul 18, 2024 am 05:48 AM
蘋果公司最新發布的iOS18、iPadOS18以及macOSSequoia系統為Photos應用程式增添了一項重要功能,旨在幫助用戶輕鬆恢復因各種原因遺失或損壞的照片和影片。這項新功能在Photos應用的"工具"部分引入了一個名為"已恢復"的相冊,當用戶設備中存在未納入其照片庫的圖片或影片時,該相冊將自動顯示。 "已恢復"相簿的出現為因資料庫損壞、相機應用未正確保存至照片庫或第三方應用管理照片庫時照片和視頻丟失提供了解決方案。使用者只需簡單幾步
 清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
目標偵測系統的標竿YOLO系列,再次獲得了重磅升級。自今年2月YOLOv9發布之後,YOLO(YouOnlyLookOnce)系列的接力棒傳到了清華大學研究人員的手上。上週末,YOLOv10推出的消息引發了AI界的關注。它被認為是電腦視覺領域的突破性框架,以其即時的端到端目標檢測能力而聞名,透過提供結合效率和準確性的強大解決方案,延續了YOLO系列的傳統。論文網址:https://arxiv.org/pdf/2405.14458專案網址:https://github.com/THU-MIG/yo
 李飛飛揭秘創業方向「空間智能」:視覺化為洞察,看見成為理解,理解導致行動
Jun 01, 2024 pm 02:55 PM
李飛飛揭秘創業方向「空間智能」:視覺化為洞察,看見成為理解,理解導致行動
Jun 01, 2024 pm 02:55 PM
史丹佛李飛飛創業後,首次揭秘新概念「空間智能」。這不僅是她的創業方向,也是指引她的“北極星”,被她認為是“解決人工智慧難題的關鍵拼圖”。視覺化為洞察;看見成為理解;理解導致行動。在李飛飛15分鐘TED演講完整公開的基礎上,從數億年前生命進化的起源開始,到人類如何不滿足於自然賦予而發展人工智慧,直到下一步如何建構空間智能。 9年前,李飛飛在同一個舞台上,向世界介紹了剛誕生不久的ImageNet——這一輪深度學習爆發的起點之一。她本人也向網友自我安麗:如果把兩個影片都看了,你就能對過去10年的電腦視
 速度秒掉GPT-4o、22B擊敗Llama 3 70B,Mistral AI開放首個代碼模型
Jun 01, 2024 pm 06:32 PM
速度秒掉GPT-4o、22B擊敗Llama 3 70B,Mistral AI開放首個代碼模型
Jun 01, 2024 pm 06:32 PM
對標OpenAI的法國AI獨角獸MistralAI有了新動作:首個代碼大模型Codestral誕生了。作為一個專為程式碼產生任務設計的開放式產生AI模型,Codestral透過共享指令和補全API端點幫助開發人員編寫並與程式碼互動。 Codestral精通程式碼和英語,因而可為軟體開發人員設計高階AI應用。 Codestral的參數規模為22B,遵循新的MistralAINon-ProductionLicense,可用於研究和測試目的,但禁止商用。目前,該模型可以在HuggingFace上下載。下載地址
