前幾天有個粉絲找我獲取基金信息,這裡拿出來分享一下,有興趣的小伙伴們,也可以積極嘗試。
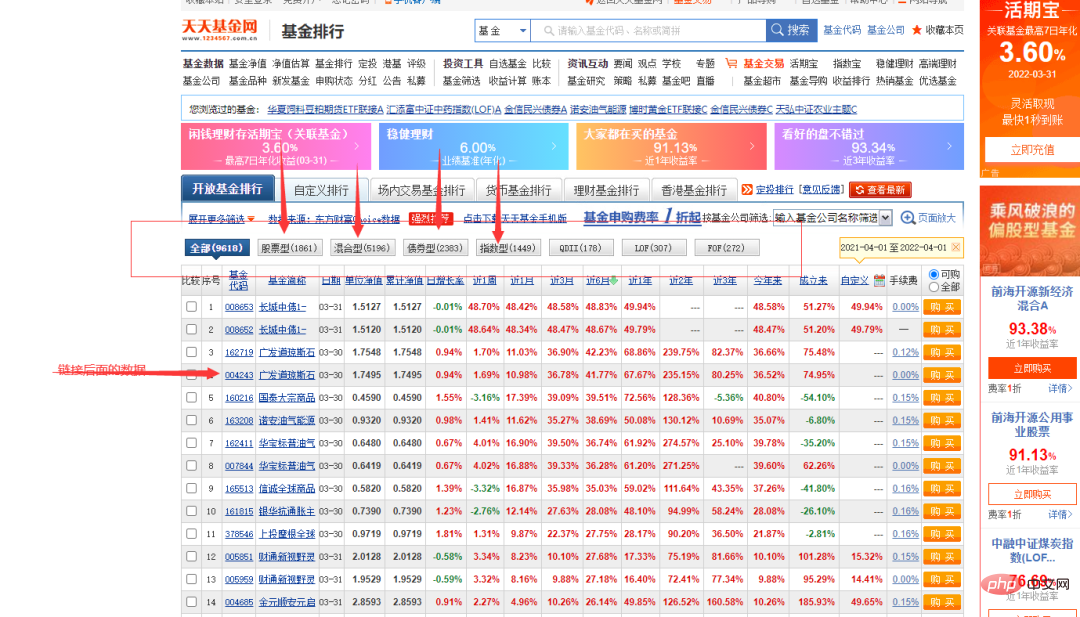
#這裡我們的目標網站是某基金官網,需要抓取的數據如下圖所示。
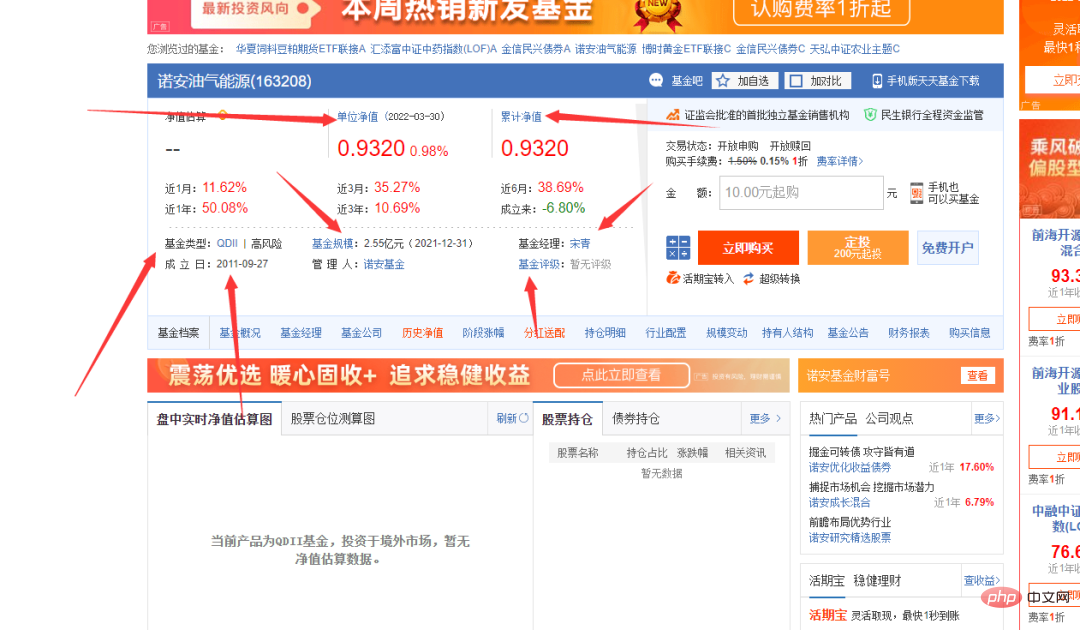 可以看到上圖中基金代碼那一列,有不同的數字,隨機點擊一個,可以進入到基金詳情頁,連結也非常有規律,以基金代碼作為標誌的。
可以看到上圖中基金代碼那一列,有不同的數字,隨機點擊一個,可以進入到基金詳情頁,連結也非常有規律,以基金代碼作為標誌的。
其實這個網站倒是不難,資料什麼的,都沒有加密,網頁上的信息,在原始碼中都可以直接看到。 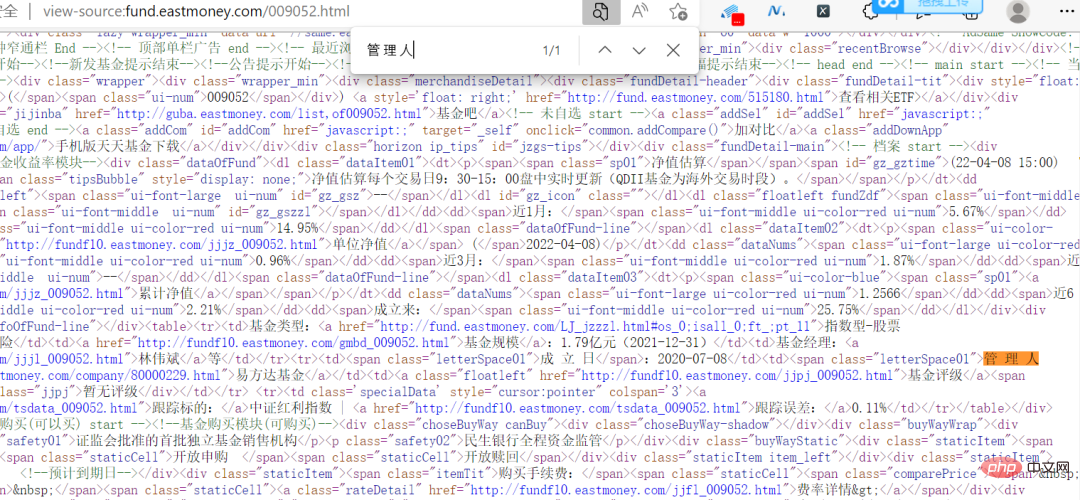
這樣就降低了抓取難度了。透過瀏覽器抓包的方法,可以看到特定的請求參數,而且可以看到請求參數中只有pi在變化,而這個值剛好對應的是頁面,直接建構請求參數就可以了。 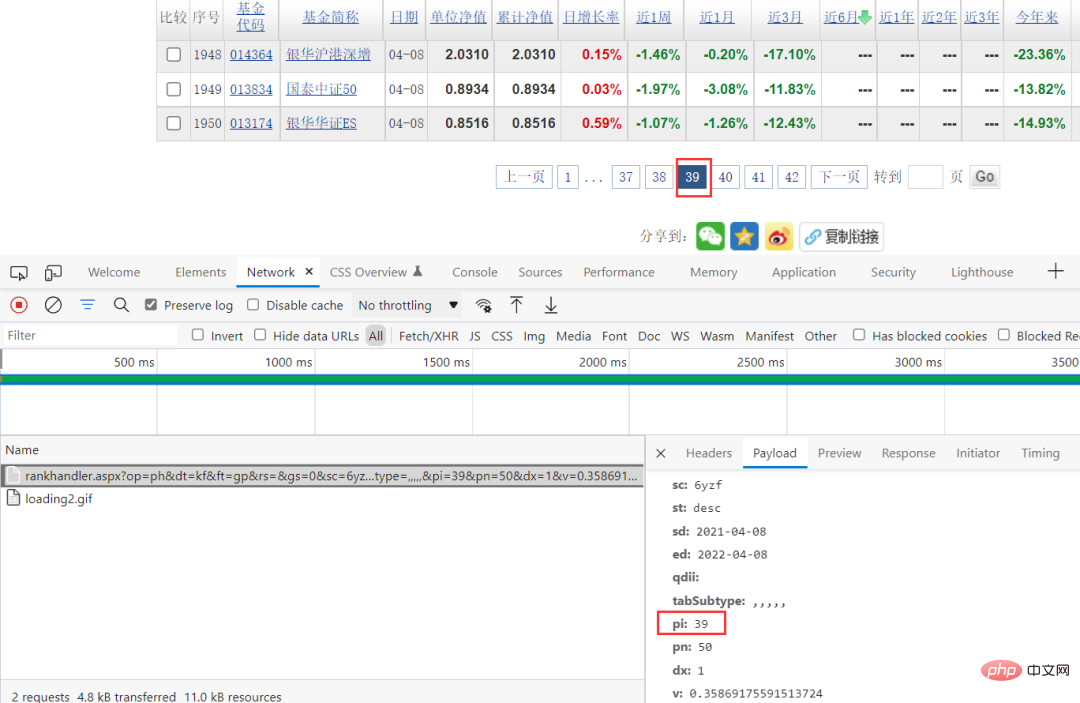
找到資料來源之後,接下來就是程式碼實作了,一起來看看吧,這裡給出部分關鍵程式碼。
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
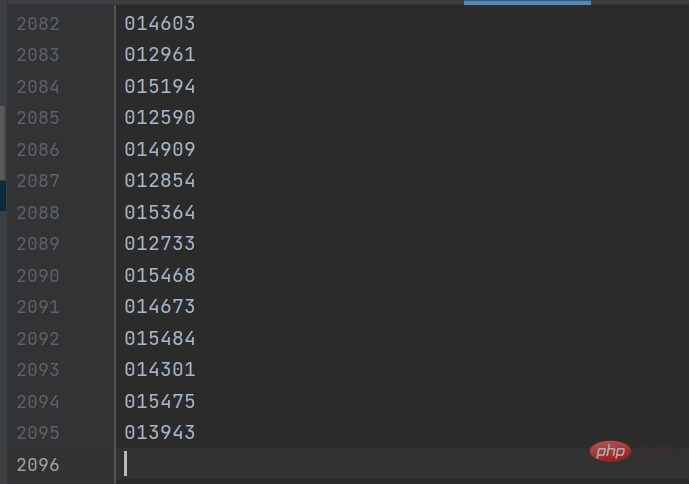
gp_id = item.group('items').split(',')[0]結果如下圖所示:
之後建構詳情頁鏈接,獲取詳情頁的基金信息,關鍵代碼如下:
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
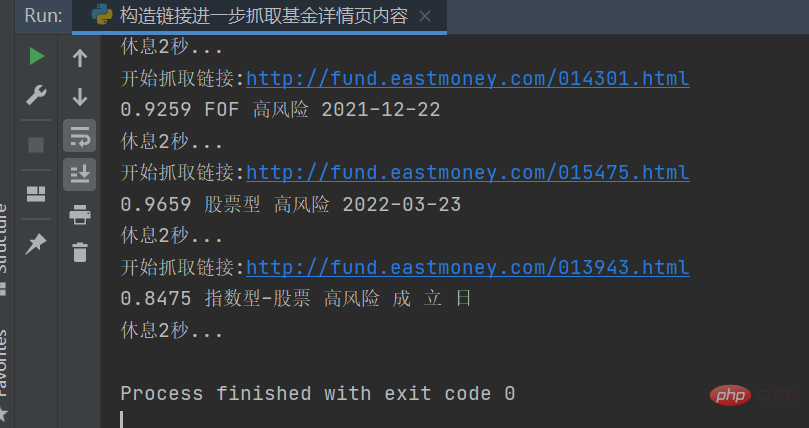
結果如下圖所示:
 將具體的信息做相應的字符串處理,然後保存到
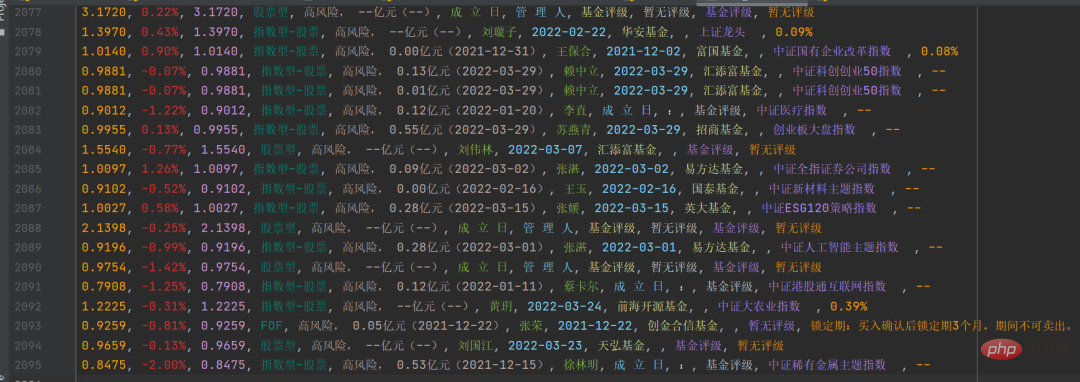
將具體的信息做相應的字符串處理,然後保存到csv檔案中,結果如下圖所示:
 有了這個,你可以做進一步的統計和資料分析了。
有了這個,你可以做進一步的統計和資料分析了。
大家好,我是Python進階者。這篇文章主要分享了使用Python網絡爬蟲獲取基金數據信息,這個項目不算太難,裡邊稍微有點小坑,歡迎大家積極嘗試,如果有遇到問題,請添加我好友,我幫助解決。
這篇文章主要是以【股票型】的分類做了抓取,其他的類型,我就沒做了,歡迎大家嘗試,其實邏輯都是一樣的,改下參數就可以了。 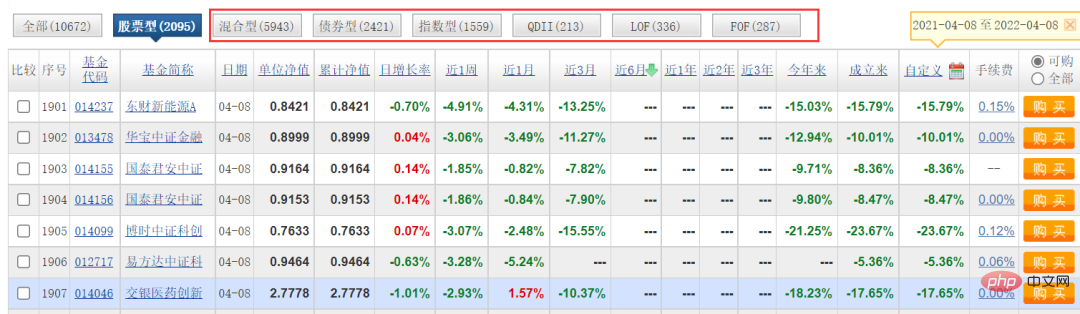
以上是手把手教你使用Python網絡爬蟲獲取基金信息的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























