

阿里為什麼不用 ZooKeeper 做服務發現?
站在未來的路口,回望歷史的迷途,常常會很有意思,因為我們會不經意地興起瘋狂的念頭,例如如果當年某事提前發生了,而另外一件事又沒有發生會怎樣? 一如當年的奧匈帝國皇位繼承人斐迪南大公夫婦如果沒有被塞爾維亞族熱血青年普林西普槍殺會怎樣,又如若當年的丘老道沒有經過牛家村會怎樣?
2007年底,淘寶開啟一個叫做「五彩石」的內部重構項目,這個項目後來成為了淘寶服務化、以分散式走自研之路,走出了網路中介軟體體系之始,而淘寶服務註冊中心ConfigServer於同年誕生。
2008年前後,Yahoo 這個曾經的網路巨頭開始逐漸在公開場合宣講自己的大數據分散式協調產品 ZooKeeper,這個產品參考了Google 發表的關於Chubby以及 Paxos 的論文。
2010年11月,ZooKeeper從 Apache Hadoop的子項目發展為 Apache的頂級項目,正式宣告 ZooKeeper成為一個工業級的成熟穩定的產品。
2011年,阿里巴巴開源Dubbo,為了更好開源,需要剝離與阿里內部系統的關係,Dubbo 支持了開源的ZooKeeper 作為其註冊中心,後來在國內,在業界諸君的努力實踐下,Dubbo ZooKeeper 的典型的服務化方案成就了ZooKeeper 作為註冊中心的聲名。
2015年雙11,ConfigServer 服務內部近8個年頭過去了,阿里巴巴內部「服務規模」超幾百萬,以及推進「千里之外」的IDC容災技術策略等,共同促使阿里巴巴內部開啟了ConfigServer 2.0 到ConfigServer 3.0 的架構升級之路。
時間走向2018年,站在10年的時間路口上,有多少人願意在追逐日新月異的新潮技術概念的時候,稍微慢一下腳步,仔細凝視一下服務發現這個領域,有多少人想到過或者思考過一個問題:
服務發現,ZooKeeper 真的是最佳選擇麼?
而回望歷史,我們也偶有迷思,在服務發現這個場景下,如果當年 ZooKeeper 的誕生之日比我們 HSF 的註冊中心 ConfigServer 早一點會怎樣?
我們會不會走向先使用ZooKeeper然後瘋狂改造與修補ZooKeeper以適應阿里巴巴的服務化場景與需求的彎路?
但是,站在今天和前人的肩膀上,我們從未如今天這樣堅定的認知到,在服務發現領域,ZooKeeper 根本就不能算是最佳的選擇 ,一如這些年一直與我們同行的Eureka以及這篇文章Eureka! Why You Shouldn't Use ZooKeeper for Service Discovery 那堅定的闡述一樣,為什麼你不應該用ZooKeeper 做服務發現!
吾道不孤單。
註冊中心需求分析及關鍵設計考量
接下來,讓我們回歸對服務發現的需求分析,結合阿里巴巴在關鍵場景上的實踐,來一一分析,一起探討為何說ZooKeeper 並不是最適合的註冊中心解決方案。
註冊中心是CP 或AP 系統?
CAP 和BASE 理論相信讀者都已經耳熟能詳,也已成了指導分散式系統及互聯網應用構建的關鍵原則之一,在此不再贅述其理論,我們直接進入對註冊中心的資料一致性和可用性需求的分析:
資料一致性需求分析
#註冊中心最本質的功能可以看成是Query函數 Si = F(service-name),以 service-name 為查詢參數,service-name 對應的服務的可用的 endpoints (ip:port) 清單為傳回值.
附註: 後文將 service 簡寫為 svc。
先來看看關鍵資料 endpoints (ip:port) 不一致性所帶來的影響,也就是CAP 中的C 不滿足所帶來的後果:
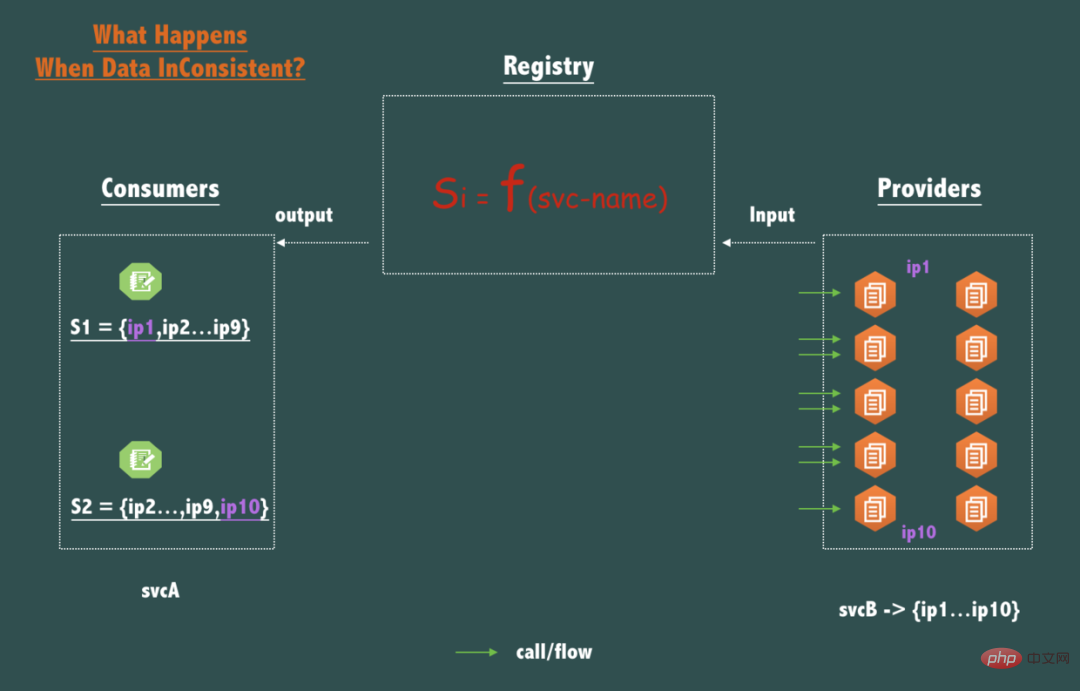
如上圖所示,如果一個svcB 部署了10個節點(副本/Replica),如果對於同一個服務名svcB, 呼叫者svcA 的2個節點的2次查詢返回了不一致的數據,例如: S1 = { ip1,ip2,ip3...,ip9 }, S2 = { ip2,ip3,....ip10 }, 那麼這次不一致帶來的影響是什麼?
相信你一定已經看出來了,svcB 的各個節點流量會有一點不平衡。
ip1和ip10相對其它8個節點{ip2...ip9},請求流量小了一點,但很明顯,在分散式系統中,即使是對等部署的服務,因為請求到達的時間,硬體的狀態,作業系統的調度,虛擬機器的GC 等,任何一個時間點,這些對等部署的節點狀態也不可能完全一致,而流量不一致的情況下,只要註冊中心在SLA承諾的時間內(例如1s內)將資料收斂到一致狀態(即滿足最終一致),流量將很快趨於統計學意義上的一致,所以註冊中心以最終一致的模型設計在生產實踐中完全可以接受。
分區容忍及可用性需求分析
#接下來我們先來看看網路分區(Network Partition)情況下註冊中心不可用對服務呼叫產生的影響,即CAP 中的A不滿足時所帶來的影響。
考慮一個典型的ZooKeeper三機房容災5節點部署結構(即2-2-1結構),如下圖:
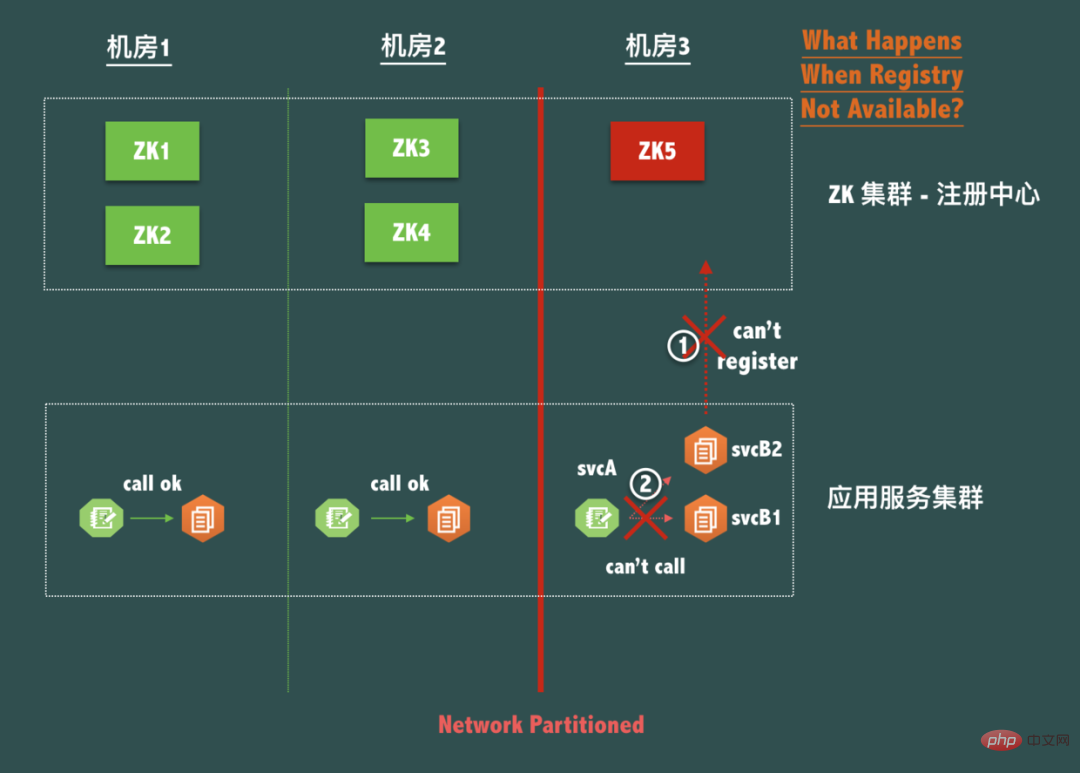
當機房3出現網路分區(Network Partitioned)的時候,也就是機房3在網路上成了孤島,我們知道雖然整體ZooKeeper 服務是可用的,但是節點ZK5是不可寫的,因為聯絡不上Leader。
也就是說,這時候機房3的應用服務svcB 是不可以新部署,重新啟動,擴容或縮容的,但是站在網路和服務呼叫的角度看,機房3的svcA 雖然無法呼叫機房1和機房2的svcB,但是與機房3的svcB之間的網絡明明是OK 的啊,為什麼不讓我調用本機房的服務?
現在因為註冊中心本身為了保腦裂(P)下的數據一致性(C)而放棄了可用性,導致了同機房的服務之間出現了無法調用,這是絕對不允許的! 可以說在實踐中,註冊中心不能因為自身的任何原因破壞服務之間本身的可連通性,這是註冊中心設計應該遵循的鐵律! 後面在註冊中心客戶災容上我們會繼續討論。
同時我們再考慮一下這種情況下的數據不一致性,如果機房1,2,3之間都成了孤島,那麼如果每個機房的svcA都只拿到本機房的svcB 的ip列表,也即在各機房svcB 的ip列表數據完全不一致,影響是什麼?
其實沒啥大影響,只是這種情況下,全都變成了同機房調用,我們在設計註冊中心的時候,有時候甚至會主動利用這種註冊中心的數據可以不一致性,來幫助應用主動做到同機房調用,從而優化服務調用鏈路RT 的效果!
透過以上我們的闡述可以看到,在CAP 的權衡中,註冊中心的可用性比資料強一致性更寶貴,所以整體設計更應該偏向AP,而非CP,資料不一致在可接受範圍,而P下捨棄A卻完全違反了註冊中心不能因為自身的任何原因破壞服務本身的可連通性的原則。
服務規模、容量、服務連結性
你所在公司的「微服務」規模有多大?數百微服務?部署了上百個節點?那麼3年後呢?網路是產生奇蹟的地方,也許你的「服務」一夕之間就家喻戶曉,流量倍增,規模翻倍!
當資料中心服務規模超過一定數量(服務規模=F{服務pub數,服務sub數}),作為註冊中心的ZooKeeper 很快就會像下圖的驢子一樣不堪重負

其實當ZooKeeper用對地方時,即用在粗粒化分佈式鎖,分散式協調場景下,ZooKeeper 能支援的tps 和支撐的連接數是足夠用的,因為這些場景對於ZooKeeper 的擴充性和容量訴求不是很強烈。
但在服務發現和健康監測場景下,隨著服務規模的增大,無論是應用頻繁發佈時的服務註冊帶來的寫入請求,還是刷毫秒級的服務健康狀態帶來的寫請求,還是恨不能整個資料中心的機器或容器皆與註冊中心有長連結帶來的連結壓力上,ZooKeeper 很快就會力不從心,而ZooKeeper 的寫並不是可擴展的,不可以透過加節點解決水平擴展性問題。
要想在ZooKeeper 基礎上硬著頭皮解決服務規模的成長問題,一個實踐中可以考慮的方法是想辦法梳理業務,垂直劃分業務域,將其劃分到多個ZooKeeper 註冊中心,但作為提供一般服務的平台機構組,因自己提供的服務能力不足要業務依照技術的指揮棒配合劃分治理業務,真的可行麼?
而且這又違反了因為註冊中心本身的原因(能力不足)破壞了服務的可連通性,舉個簡單的例子,1個搜尋業務,1個地圖業務,1個大文娛業務,1個遊戲業務,他們之間的服務就該老死不相往來麼?也許今天是肯定的,那明天呢,1年後呢,10年後呢?誰知道未來會要打通幾個業務域去做什麼奇葩的業務創新?註冊中心作為基礎服務,無法預料未來的時候當然不能妨礙業務服務對未來固有連結性的需求。
註冊中心需要持久性儲存和交易日誌麼?
需要,也不需要。
我們知道ZooKeeper 的ZAB 協定對每一個寫入請求,會在每個ZooKeeper節點上保持寫一個事務日誌,同時再加上定期的將記憶體資料鏡像(Snapshot)到磁碟來保證資料的一致性和持久性,以及宕機之後的數據可恢復,這是非常好的特性,但是我們要問,在服務發現場景中,其最核心的數據-實時的健康的服務的地址列表真的需要數據持久化麼?
對於這份數據,答案是否定的。
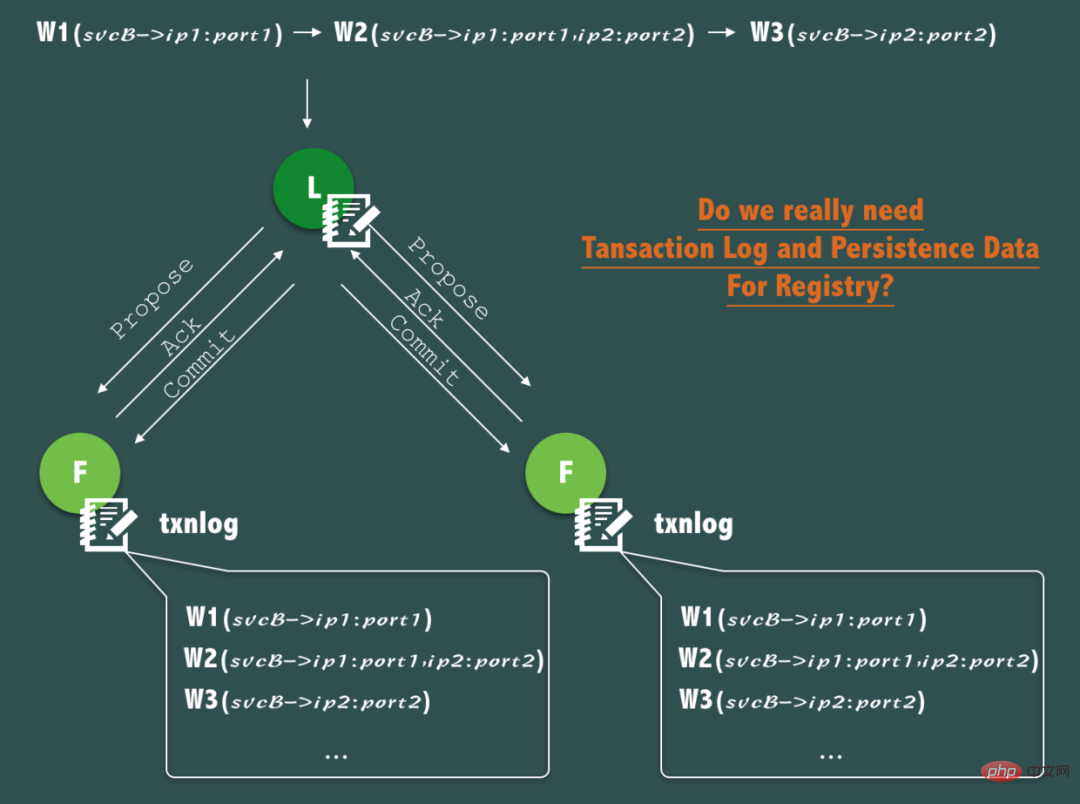
如上圖所示,如果svcB 經歷了註冊服務(ip1)到擴容到2個節點(ip1,ip2)到因宕機縮容(ip1 宕機),這個過程中,產生了3次針對ZooKeeper 的寫入操作。
但是仔細分析,透過交易日誌,持久化連續記錄這個變化過程其實意義不大,因為在服務發現中,服務調用發起方更關注的是其要調用的服務的實時的地址列表和即時健康狀態,每次發起呼叫時,並不關心要呼叫的服務的歷史服務位址清單、過去的健康狀態。
但是為什麼又說需要呢,因為一個完整的生產可用的註冊中心,除了服務的實時地址列表以及實時的健康狀態之外,還會存儲一些服務的元數據信息,例如服務的版本,分組,所在的資料中心,權重,鑑權策略信息,service label等元信息,這些資料需要持久化存儲,並且註冊中心應該提供對這些元資訊的檢索的能力。
Service Health Check
使用ZooKeeper 作為服務註冊中心時,服務的健康檢測常利用ZooKeeper 的Session 活性Track機制以及結合Ephemeral ZNode的機制,簡單而言,就是將服務的健康監測綁定在了ZooKeeper 對於Session 的健康監測上,或者說綁定在TCP長連結活性探測上了。
這在很多時候也會造成致命的問題,ZK 與服務提供者機器之間的TCP長連結活性探測正常的時候,該服務就是健康的麼?答案當然是否定的!註冊中心應該提供更豐富的健康監測方案,服務的健康與否的邏輯應該開放給服務提供者自己定義,而不是一刀切搞成了 TCP 活性檢測!
健康檢測的一大基本設計原則就是盡可能真實的回饋服務本身的真實健康狀態,否則一個不敢被服務呼叫者相信的健康狀態判定結果不如沒有健康檢測。
註冊中心的容災考慮
前文提過,在實踐中,註冊中心不能因為自身的任何原因破壞服務之間本身的可連通性,那麼在可用性上,一個本質的問題,如果註冊中心(Registry)本身完全宕機了,svcA 呼叫svcB鏈路應該受到影響麼?
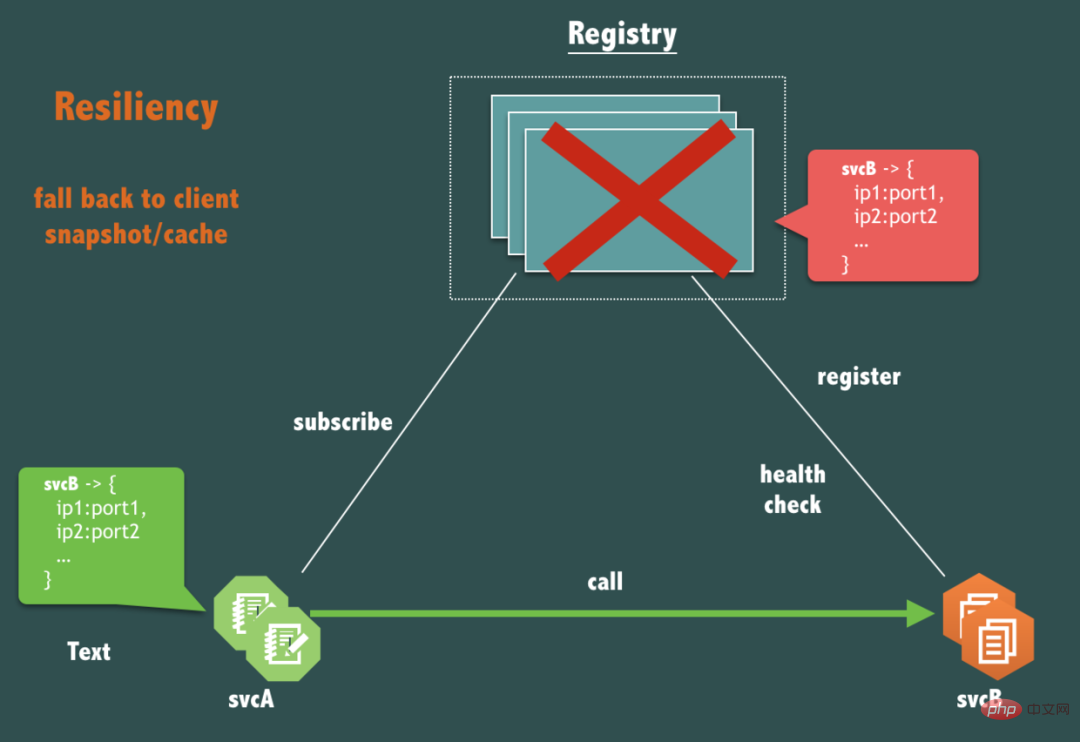
是的,不應該受到影響。
服務呼叫(請求回應流)連結應該是弱依賴註冊中心,必須僅在服務發布,機器上下線,服務擴充容等必要時才依賴註冊中心。
這需要註冊中心仔細的設計自己提供的客戶端,客戶端中應該有針對註冊中心服務完全不可用時做容災的手段,例如設計客戶端緩存資料機制(我們稱之為client snapshot)就是行之有效的手段。另外,註冊中心的 health check 機制也要仔細設計以便在這種情況不會出現諸如推空等情況的出現。
ZooKeeper的原生客戶端並沒有這種能力,所以利用ZooKeeper 實作註冊中心的時候我們一定要問自己,如果把ZooKeeper 所有節點全幹掉,你生產上的所有服務調用鏈路能不受任何影響麼?而且應該定期就這一點做故障演練。
你有沒有ZooKeeper的專家可以依靠?
ZooKeeper 看似很簡單的一個產品,但在生產上大規模使用並且用好,並不是那麼理所當然的事情。如果你決定在生產中引入ZooKeeper,你最好隨時做好向ZooKeeper 技術專家尋求幫助的心理預期,最典型的表現是在兩個方面:
難以掌握的Client/Session狀態機
ZooKeeper 的原生客戶端絕對稱不上好用,Curator 會好一點,但其實也好的有限,要完全理解ZooKeeper 用戶端與Server 之間的互動協定也不簡單,完全理解並掌握ZooKeeper Client/Session 的狀態機(下圖)也並不是那麼簡單明了:
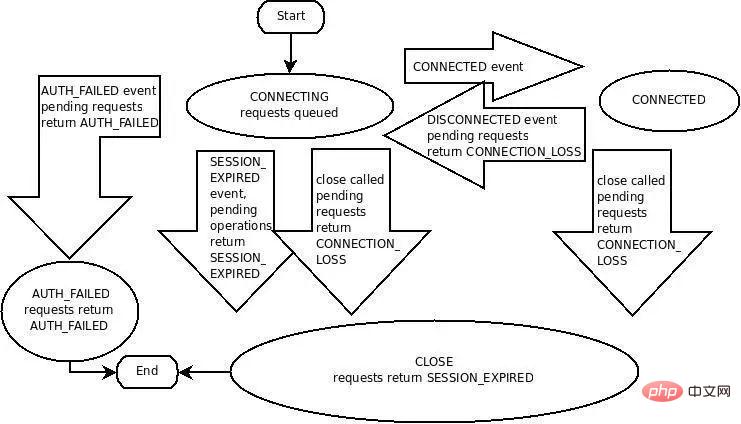
#但基於ZooKeeper 的服務發現方案卻是依賴ZooKeeper 提供的長連接/Session管理,Ephemeral ZNode,Event&Notification, ping 機制上,所以要用好ZooKeeper 做服務發現,恰恰要理解這些ZooKeeper 核心的機制原理,這有時候會讓你陷入暴躁,我只是想要個服務發現而已,怎麼要知道這麼多?而如果這些你都理解了並且不踩坑,恭喜你,你已經成為ZooKeeper的技術專家了。
難以承受的異常處理
我們在阿里巴巴內部應用接入ZooKeeper 時,有一個《ZooKeeper 應用接入必知必會》的WIKI,其中關於異常處理有過如下的論述:
如果說要選出應用開發者在使用ZooKeeper的過程中,最需要了解清楚的事情?那麼根據我們之前的支援經驗,一定是異常處理。
當所有一切(宿主機,磁碟,網路等等)都很幸運的正常運作的時候,應用與ZooKeeper可能也會運作的很好,但不幸的是,我們整天會面對各種意外,而且這遵循墨菲定律,意料之外的壞事情總是在你最擔心的時候發生。
所以務必仔細了解 ZooKeeper 在一些場景下會出現的異常和錯誤,確保您正確的理解了這些異常和錯誤,以及知道您的應用如何正確的處理這些情況。
ConnectionLossException 和Disconnected 事件
簡單來說,這是個可以在同一個ZooKeeper Session 恢復的例外(Recoverable), 但是應用開發者需要負責將應用程式恢復到正確的狀態。
發生這個異常的原因有很多,例如應用機器與ZooKeeper節點之間網路閃斷,ZooKeeper節點宕機,服務端Full GC時間超長,甚至你的應用程式Hang死,應用程式Full GC 時間超長之後恢復都有可能。
要理解這個異常,需要了解分散式應用程式中的一個典型的問題,如下圖: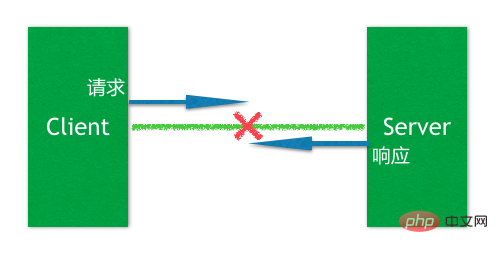
在一個典型的客戶端請求、服務端回應中,當它們之間的長連結閃斷的時候,客戶端感知到這個閃斷事件的時候,會處在一個比較尷尬的境地,那就是無法確定該事件發生時附近的那個請求到底處在什麼狀態,Server端到底收到這個請求了麼?已經處理了麼?因為無法確定這一點,所以當客戶端重新連線上Server之後,這個請求是否應該重試(Retry)就也要打一個問號。
所以在處理連線中斷事件中,應用程式開發者必須清楚處於閃斷附近的那個請求是什麼(這常常難以判斷),該請求是否是冪等的,對於業務請求在Server端服務處理上對於"僅處理一次" "最多處理一次" "最少處理一次"語意要有選擇和預期。
舉個例子,如果應用在收到ConnectionLossException 時,之前的請求是Create操作,那麼應用的catch到這個異常,應用一個可能的恢復邏輯就是,判斷之前請求創建的節點的是否已經存在了,如果存在就不要再創建了,否則就創建。
再例如,如果應用程式使用了exists Watch 去監聽一個不存在的節點的創建的事件,那麼在ConnectionLossException的期間,有可能遇到的情況是,在這個閃斷期間,其它的客戶端進程可能已經創建了節點,並且又已經刪除了,那麼對於當前應用來說,就miss了一次關心的節點的創建事件,這種miss對應用的影響是什麼?是可以忍受的還是不可接受?需要應用開發者自己根據業務語意去評估處理。
SessionExpiredException 和SessionExpired 事件
Session 逾時是一個不可恢復的例外,這是指應用Catch到這個異常的時候,應用不可能在同一個Session中恢復應用狀態,必須要重新建立新Session,老Session關聯的臨時節點也可能已經失效,擁有的鎖可能已經失效。 ...
阿里巴巴的小夥伴在自行嘗試使用ZooKeeper 做服務發現的過程中,曾經在我們的內網技術論壇上總結過一篇自己踩坑的經驗分享

在該文中肯的提到:
... 在編碼過程中發現很多可能存在的陷阱,毛估估,第一次使用zk來實現集群管理的人應該有80%以上會掉坑,有些坑比較隱蔽,在網絡問題或異常的場景時才會出現,可能很長一段時間才會暴露出來...
向左走,向右走
阿里巴巴是不是完全沒有使用ZooKeeper?並不是。
熟悉阿里巴巴技術體系的都知道,其實阿里巴巴維護了目前國內最大規模的ZooKeeper集群,整體規模有近千台的ZooKeeper服務節點。
同時阿里巴巴中間件內部也維護了一個面向大規模生產的、高可用、更易監控和運維的ZooKeeper的代碼分支TaoKeeper,如果以我們近10年在各個業務線和生產上使用ZooKeeper的實踐,給ZooKeeper 用一個短語評價的話,那麼我們認為ZooKeeper應該是“The King Of Coordination for Big Data”!
在粗粒化分散式鎖,分散式選主,主備高可用切換等不需要高TPS 支援的場景下有不可替代的作用,而這些需求往往多集中在大數據、離線任務等相關的業務領域,因為大數據領域,講究分割資料集,並且大部分時間分任務多進程/線程並行處理這些資料集,但是總是有一些點上需要將這些任務和進程統一協調,這時候就是ZooKeeper 發揮巨大作用的用武之地。
但是在交易場景交易鏈路上,在主業務數據訪問,大規模服務發現、大規模健康監測等方面有天然的短板,應該竭力避免在這些場景下引入ZooKeeper,在在阿里巴巴的生產實務中,應用ZooKeeper申請使用的時候要進行嚴格的場景、容量、SLA需求的評估。
所以可以使用 ZooKeeper,但大數據請向左,而交易則向右,分散式協調向左,服務發現向右。
結語
感謝你耐心的閱讀到這裡,至此,我相信你已經理解,我們寫這篇文章並不是全盤否定ZooKeeper,而只是根據我們阿里巴巴在近10年來在大規模服務化上的生產實踐,對我們在服務發現和註冊中心設計及使用上的經驗教訓進行一個總結,希望對業界就如何更好的使用ZooKeeper,如何更好的設計自己的服務註冊中心有所啟發和幫助。 最後,條條大路通羅馬,衷心祝福你的註冊中心直接就誕生在羅馬。
以上是阿里為什麼不用 ZooKeeper 做服務發現?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Java API 開發中使用 ZooKeeper 進行分散式鎖定處理
Jun 17, 2023 pm 10:36 PM
Java API 開發中使用 ZooKeeper 進行分散式鎖定處理
Jun 17, 2023 pm 10:36 PM
隨著現代應用程式的不斷發展和對高可用性和並發性的需求日益增長,分散式系統架構變得越來越普遍。在分散式系統中,多個進程或節點同時運作並共同完成任務,進程之間的同步變得特別重要。由於分散式環境下許多節點可以同時存取共享資源,因此,在分散式系統中,如何處理並發和同步問題成為了一項重要的任務。在此方面,ZooKeeper已經成為了一個非常流行的解決方案。 ZooKee
 在Beego中使用ZooKeeper和Curator進行分散式協調和管理
Jun 22, 2023 pm 09:27 PM
在Beego中使用ZooKeeper和Curator進行分散式協調和管理
Jun 22, 2023 pm 09:27 PM
隨著互聯網的迅速發展,分散式系統已經成為了許多企業和組織中的基礎設施之一。而要讓一個分散式系統能夠正常運作,就需要對其進行協調和管理。在這方面,ZooKeeper和Curator是兩個非常值得使用的工具。 ZooKeeper是一個非常受歡迎的分散式協調服務,它可以幫助我們在一個叢集中協調各個節點之間的狀態和資料。 Curator則是對ZooKeeper進行封裝
 分散式鎖用 Redis 還是 Zookeeper?
Aug 22, 2023 pm 03:48 PM
分散式鎖用 Redis 還是 Zookeeper?
Aug 22, 2023 pm 03:48 PM
分散式鎖定的實作方式通常有:資料庫、快取(例如:Redis)、Zookeeper、etcd,實際開發中,使用的最多還是Redis和Zookeeper,所以,本文就只聊這兩種。
 php如何使用PHP的Zookeeper擴充?
Jun 02, 2023 pm 09:01 PM
php如何使用PHP的Zookeeper擴充?
Jun 02, 2023 pm 09:01 PM
PHP是一種非常流行的程式語言,廣泛應用於Web應用程式和伺服器端開發。 Zookeeper是一個分散式的協調服務,用於管理、協調和監控分散式應用程式和服務。在PHP應用程式中使用Zookeeper可以提高應用程式的效能和可靠性。本文將介紹如何使用PHP的Zookeeper擴充。一、安裝Zookeeper擴充功能使用Zookeeper擴充功能需要安裝Zookeeper
 在Beego中使用ZooKeeper實現服務註冊和發現
Jun 22, 2023 am 08:21 AM
在Beego中使用ZooKeeper實現服務註冊和發現
Jun 22, 2023 am 08:21 AM
在微服務架構中,服務的註冊和發現是一個非常重要的議題。為了解決這個問題,我們可以使用ZooKeeper作為服務註冊中心。在本文中,我們將介紹如何在Beego框架中使用ZooKeeper來實現服務註冊和發現。一、ZooKeeper簡介ZooKeeper是一個分散式的,開源的分散式協調服務,它是ApacheHadoop的子專案之一。 ZooKeeper的主要作用
 【建議收藏】靈魂拷問! Zookeeper的31連環砲
Aug 28, 2023 pm 04:45 PM
【建議收藏】靈魂拷問! Zookeeper的31連環砲
Aug 28, 2023 pm 04:45 PM
ZooKeeper 是一個開源的分散式協調服務。它是一個為分散式應用提供一致性服務的軟體,分散式應用程式可以基於Zookeeper 實現諸如資料發布/訂閱、負載平衡、命名服務、分散式協調/通知、叢集管理、Master 選舉、分散式鎖定和分散式佇列等功能。
 Redis實現分散式鎖定的ZooKeeper對比
Jun 20, 2023 pm 03:19 PM
Redis實現分散式鎖定的ZooKeeper對比
Jun 20, 2023 pm 03:19 PM
隨著互聯網技術的迅速發展,分散式系統在現代應用中已被廣泛應用,特別是在大型互聯網企業中更是不可或缺。但是在分散式系統中,各個節點之間要保持一致性是非常困難的,因此分散式鎖定機製成為了解決這個問題的基礎之一。在分散式鎖定的實作中,Redis和ZooKeeper都是比較流行的工具,本文將對它們進行一些比較和分析。 Redis實作分散式鎖Redis是開源的記憶體資料存
 SpringBoot中如何整合Dubbo zookeeper
May 17, 2023 pm 02:16 PM
SpringBoot中如何整合Dubbo zookeeper
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun--namezk01-p2181:2181--restartalways-d2e30cac00aca顯示zookeeper已成功啟動Zookeeper和Dubbo•ZooKeeperZooKeeper是一個分散式的,開放原始碼的分散式應用程式協調。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括:配置維護、網域服務、分散式同步、群組服務等。 DubboDubbo是Alibaba開源的分散式服務框架,它最大的特色是按照分層的方式來架構,
