

Linux 維運故障排查思路,有這篇文章就夠了~
1. 背景
#有時候會遇到一些疑難雜症,並且監控外掛程式並不能一眼立刻發現問題的根源。這時候就需要登入伺服器進一步深入分析問題的根源。那麼分析問題就需要有一定的技術經驗積累,而且有些問題涉及到的領域非常廣,才能定位到問題。所以,分析問題和踩坑是非常鍛鍊一個人的成長和提升自我能力。如果我們有一套好的分析工具,那將是事半功倍,能夠幫助大家快速定位問題,節省大家很多時間做更深入的事情。

#2. 說明
本篇文章主要介紹各種問題定位的工具以及會結合個案分析問題。
3. 分析問題的方法論
What-現像是什麼樣的 When-什麼時候發生 Why-為什麼會發生 Where-哪個地方發生的問題 How much-耗費了多少資源 How to do-怎麼解決問題
4. cpu
4.1 說明
#針對應用程序,我們通常關注的是核心CPU調度器功能和效能。
執行緒的狀態分析主要是分析執行緒的時間用在什麼地方,而執行緒狀態的分類一般分為:
on- CPU:執行中,執行中的時間通常又分為使用者態時間user和系統態時間sys。
off-CPU:等待下一輪上CPU,或是等待I/O、鎖定、換頁等等,其狀態可以細分為可執行、匿名換頁、睡眠、鎖、空閒等狀態。
處理器 -
#硬體執行緒 -
#CPU記憶體快取 -
時脈頻率 -
每個指令周期數CPI與每週期指令數IPC - #CPU指令
- 使用率
- 使用者時間/核心時間
- 調度器
- 運行佇列
- 搶佔
- 多重行程
#4.2 分析工具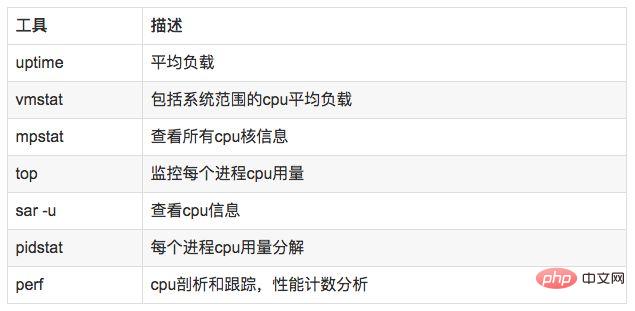
uptime,vmstat,mpstat,top,pidstat 只能查詢到cpu及負載的使用情況。 perf可以跟著到進程內部特定函數耗時情況,並且可以指定核心函數進行統計,指哪打哪。
4.3 使用方式
//查看系统cpu使用情况top //查看所有cpu核信息mpstat -P ALL 1 //查看cpu使用情况以及平均负载vmstat 1 //进程cpu的统计信息pidstat -u 1 -p pid //跟踪进程内部函数级cpu使用情况 perf top -p pid -e cpu-clock
#5. 記憶體
5.1說明
牛逼啊!接私活必备的 N 个开源项目!赶快收藏
主存 虚拟内存 常驻内存 地址空间 OOM 页缓存 缺页 换页 交换空间 交换 用户分配器libc、glibc、libmalloc和mtmalloc LINUX内核级SLUB分配器
5.2 分析工具
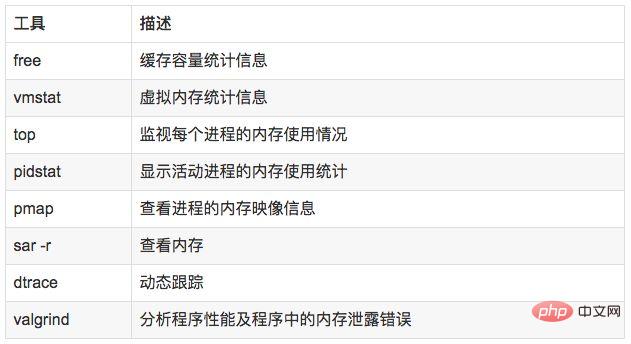
说明:
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind 可以分析内存泄漏问题。
dtrace 动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
5.3 使用方式
//查看系统内存使用情况free -m//虚拟内存统计信息vmstat 1//查看系统内存情况top//1s采集周期,获取内存的统计信息pidstat -p pid -r 1//查看进程的内存映像信息pmap -d pid//检测程序内存问题valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
6. 磁盘IO
6.1 说明
在理解磁盘IO之前,同样我们需要理解一些概念,例如:
檔案系統 #VFS 檔案系統快取 頁快取page cache 緩衝區快取buffer cache 目錄快取 #inode inode快取 noop呼叫策略
6.2 分析工具
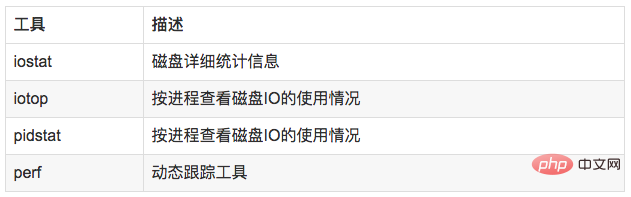
6.3 使用方式
//查看系统io信息iotop//统计io详细信息iostat -d -x -k 1 10//查看进程级io的信息pidstat -d 1 -p pid//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常perf record -e block:block_rq_issue -ag^Cperf report
7. 网络
7.1 说明
7.2 分析工具

7.3 使用方式
//显示网络统计信息netstat -s//显示当前UDP连接状况netstat -nu//显示UDP端口号的使用情况netstat -apu//统计机器中网络连接各个状态个数netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'//显示TCP连接ss -t -a//显示sockets摘要信息ss -s//显示所有udp socketsss -u -a//tcp,etcp状态sar -n TCP,ETCP 1//查看网络IOsar -n DEV 1//抓包以包为单位进行输出tcpdump -i eth1 host 192.168.1.1 and port 80 //抓包以流为单位显示数据内容tcpflow -cp host 192.168.1.18. 系统负载
8.1 说明
8.2 分析工具
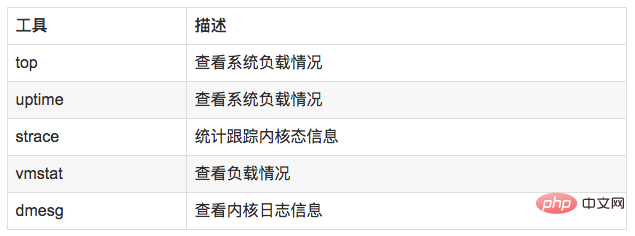
8.3 使用方式
//查看负载情况uptimetopvmstat//统计系统调用耗时情况strace -c -p pid//跟踪指定的系统操作例如epoll_waitstrace -T -e epoll_wait -p pid//查看内核日志信息dmesg
9. 火焰图
9.1 说明
常见的火焰图类型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安装依赖库
//安装systemtap,默认系统已安装yum install systemtap systemtap-runtime//内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5kernel-debuginfo-2.6.18-308.el5.x86_64.rpmkernel-devel-2.6.18-308.el5.x86_64.rpmkernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm//安装内核调试库debuginfo-install --enablerepo=debuginfo search kerneldebuginfo-install --enablerepo=debuginfo search glibc
9.3 安装
git clone https://github.com/lidaohang/quick_location.gitcd quick_location
9.4 CPU级别火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。另外,搜索公众号Linux就该这样学后台回复“猴子”,获取一份惊喜礼包。
9.4.1 on-CPU
//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录 cd ngx_on_cpu_u//on-CPU kernelsh ngx_on_cpu_k.sh pid//进入结果目录 cd ngx_on_cpu_k//开一个临时端口 8088 python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
DEMO:
#include <stdio.h>#include <stdlib.h>
void foo3(){ }
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}DEMO火焰图:

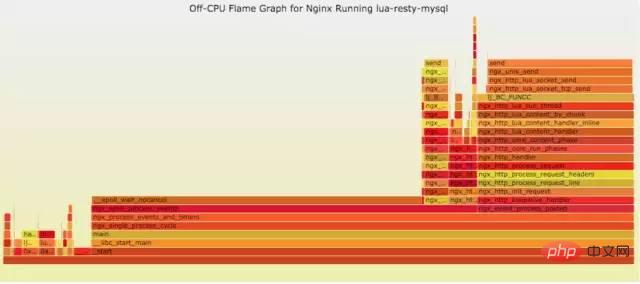
9.4.2 off-CPU
cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
// off-CPU usersh ngx_off_cpu_u.sh pid//进入结果目录cd ngx_off_cpu_u//off-CPU kernelsh ngx_off_cpu_k.sh pid//进入结果目录cd ngx_off_cpu_k//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
9.5 内存级别火焰图
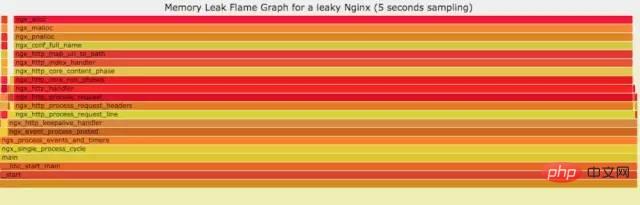
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
sh ngx_on_memory.sh pid//进入结果目录cd ngx_on_memory//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
9.6 性能回退-红蓝差分火焰图
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
cd quick_location//抓取代码修改前的profile 1文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks1//抓取代码修改后的profile 2文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks2//生成差分火焰图:./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
//test.c#include <stdio.h>#include <stdlib.h>
void foo3(){ }
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}
//test1.c#include <stdio.h>#include <stdlib.h>
void foo3(){
}
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
void add(){ int i; for(i = 0; i< 10000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); }}DEMO红蓝差分火焰图:

10. 案例分析
10.1 接入層nginx集群異常現象
10.2 分析nginx相關指標
a) **分析nginx請求流量:
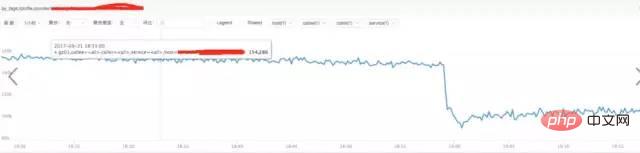
結論:
透過上圖發現流量並沒有突增,反而下降了,跟請求流量突增沒關係。
b) **分析nginx回應時間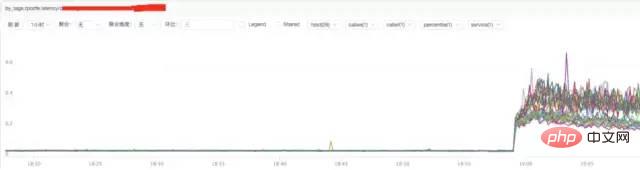
#結論:
透過上圖發現nginx的反應時間有增加可能跟nginx本身有關係或跟後端upstream回應時間有關係。
c) **分析nginx upstream回應時間
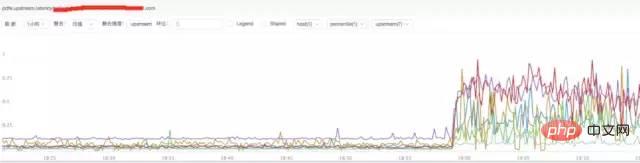
##結論:
透過上圖發現nginx upstream 回應時間有增加,目前猜測可能後端upstream回應時間拖住nginx,導致nginx出現請求流量異常。
10.3 分析系統cpu狀況
a) **透過top觀察系統指標
# top
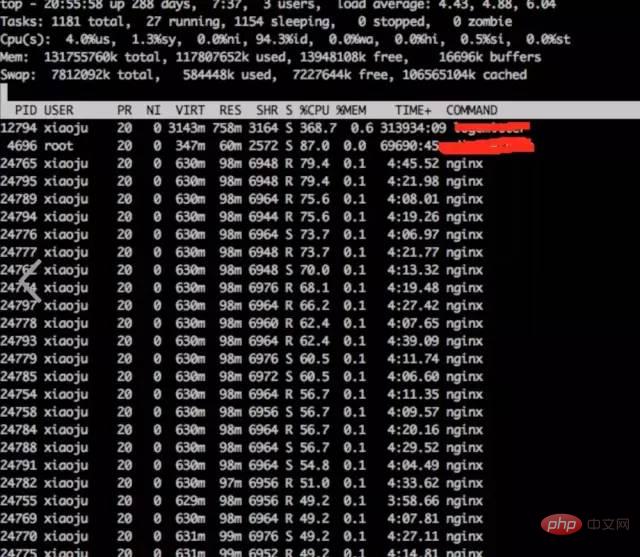
#結論:
#發現nginx worker cpu比較高
b) **分析nginx行程內部cpu狀況
#perf top -p pid
结论:
发现主要开销在free,malloc,json解析上面
10.4 火焰图分析cpu
a) **生成用户态cpu火焰图
//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录cd ngx_on_cpu_u//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
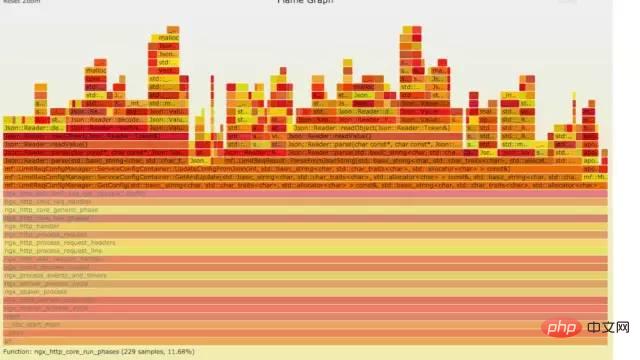
结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
10.5 案例总结
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) 分析nginx進程cpu高,得出nginx內部模組程式碼有耗時的json解析以及記憶體分配回收操作
10.5 .1 深入分析
根據上述兩點問題分析的結論,我們進一步深入分析。
後端upstream回應拉長,最多可能影響nginx的處理能力。但是不可能會影響nginx內部模組佔用過多的cpu操作。而當時佔用cpu高的模組,是在請求的時候才會走的邏輯。不太可能是upstram後端拖住nginx,從而觸發這個cpu的耗時操作。
10.5.2 解決方式
#遇到這種問題,我們優先解決已知的,並且非常明確的問題。那就是cpu高的問題。解決方式先降級關閉佔用cpu過高的模組,然後進行觀察。經過降級關閉該模組cpu降下來了,而且nginx請求流量也正常了。之所以會影響upstream時間拉長,因為upstream後端的服務呼叫的介面可能是個迴路再走回nginx。
11.參考資料
##http://www.brendangregg.com/index.html
#http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs。 html
http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html
http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
https://github .com/openresty/openresty-systemtap-toolkit
#https://github.com/brendangregg/FlameGraph
##https://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs
以上是Linux 維運故障排查思路,有這篇文章就夠了~的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 redis怎麼啟動服務器
Apr 10, 2025 pm 08:12 PM
redis怎麼啟動服務器
Apr 10, 2025 pm 08:12 PM
啟動 Redis 服務器的步驟包括:根據操作系統安裝 Redis。通過 redis-server(Linux/macOS)或 redis-server.exe(Windows)啟動 Redis 服務。使用 redis-cli ping(Linux/macOS)或 redis-cli.exe ping(Windows)命令檢查服務狀態。使用 Redis 客戶端,如 redis-cli、Python 或 Node.js,訪問服務器。
 Linux的5支支柱:了解他們的角色
Apr 11, 2025 am 12:07 AM
Linux的5支支柱:了解他們的角色
Apr 11, 2025 am 12:07 AM
Linux系統的五大支柱是:1.內核,2.系統庫,3.Shell,4.文件系統,5.系統工具。內核管理硬件資源並提供基本服務;系統庫為應用程序提供預編譯函數;Shell是用戶與系統交互的接口;文件系統組織和存儲數據;系統工具用於系統管理和維護。
 oracle如何查看實例名
Apr 11, 2025 pm 08:18 PM
oracle如何查看實例名
Apr 11, 2025 pm 08:18 PM
在 Oracle 中查看實例名的方法有三種:命令行中使用 "sqlplus" 和 "select instance_name from v$instance;" 命令。在 SQL*Plus 中使用 "show instance_name;" 命令。通過操作系統的任務管理器、Oracle Enterprise Manager 或檢查環境變量 (Linux 上的 ORACLE_SID)。
 Linux實際上有什麼好處?
Apr 12, 2025 am 12:20 AM
Linux實際上有什麼好處?
Apr 12, 2025 am 12:20 AM
Linux適用於服務器、開發環境和嵌入式系統。 1.作為服務器操作系統,Linux穩定高效,常用於部署高並發應用。 2.作為開發環境,Linux提供高效的命令行工具和包管理系統,提升開發效率。 3.在嵌入式系統中,Linux輕量且可定制,適合資源有限的環境。
 redis怎麼啟動linux
Apr 10, 2025 pm 08:00 PM
redis怎麼啟動linux
Apr 10, 2025 pm 08:00 PM
在 Linux 系統中啟動 Redis 的步驟:安裝 Redis 軟件包。啟用並啟動 Redis 服務。驗證 Redis 是否正在運行。連接到 Redis 服務器。高級選項:配置 Redis 服務器。設置密碼。使用 systemd 單位文件。
 oracle數據庫卸載教程
Apr 11, 2025 pm 06:24 PM
oracle數據庫卸載教程
Apr 11, 2025 pm 06:24 PM
要卸載 Oracle 數據庫:停止 Oracle 服務,移除 Oracle 實例,刪除 Oracle 主目錄,清除註冊表項(僅限 Windows),刪除環境變量(僅限 Windows)。卸載前請備份數據。
 將Docker與Linux一起使用:綜合指南
Apr 12, 2025 am 12:07 AM
將Docker與Linux一起使用:綜合指南
Apr 12, 2025 am 12:07 AM
在Linux上使用Docker可以提高開發和部署效率。 1.安裝Docker:使用腳本在Ubuntu上安裝Docker。 2.驗證安裝:運行sudodockerrunhello-world。 3.基本用法:創建Nginx容器dockerrun--namemy-nginx-p8080:80-dnginx。 4.高級用法:創建自定義鏡像,使用Dockerfile構建並運行。 5.優化與最佳實踐:使用多階段構建和DockerCompose,遵循編寫Dockerfile的最佳實踐。
 oracle安裝之後如何使用
Apr 11, 2025 pm 07:51 PM
oracle安裝之後如何使用
Apr 11, 2025 pm 07:51 PM
安裝 Oracle 後,可通過以下步驟使用:創建數據庫實例。連接到數據庫。創建用戶。創建表。插入數據。查詢數據。導出數據。導入數據。
