

再見 Go 面試官:GMP 模型,為什麼要有 P?
今天的主角,是Go 面試的萬能題GMP 模型的延伸題(疑問),那就是」GMP 模型,為什麼要有P ?出來,那麼麻煩,為的是什麼,是要解決什麼問題嗎
? 「這篇文章煎魚就帶你一同探索,GM、GMP 模型的變遷是因為什麼原因。
GM 模型今天帶大家一起回顧過去的設計。 解密Go1.0 原始碼
static void
schedule(G *gp)
{
...
schedlock();
if(gp != nil) {
...
switch(gp->status){
case Grunnable:
case Gdead:
// Shouldn't have been running!
runtime·throw("bad gp->status in sched");
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
}
gp = nextgandunlock();
gp->readyonstop = 0;
gp->status = Grunning;
m->curg = gp;
gp->m = m;
...
runtime·gogo(&gp->sched, 0);
}登入後複製
呼叫 schedlock 方法來取得全域鎖定。 取得全域鎖定成功後,將目前 Goroutine 狀態從 Running(正在被調度) 狀態修改為 Runnable(可以被排程)狀態。 呼叫 gput 方法來保存目前 Goroutine 的運行狀態等信息,以便於後續的使用。 呼叫 nextgandunlock 方法來尋找下一個可運行 Goroutine,並且釋放全域鎖定給其他調度使用。 取得到下一個待運行的 Goroutine 後,將其運行狀態修改為 Running。 呼叫 runtime·gogo 方法,將剛剛所取得的下一個待執行的 Goroutine 運行起來,進入下一輪調度。
思考GM 模型
static void
schedule(G *gp)
{
...
schedlock();
if(gp != nil) {
...
switch(gp->status){
case Grunnable:
case Gdead:
// Shouldn't have been running!
runtime·throw("bad gp->status in sched");
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
}
gp = nextgandunlock();
gp->readyonstop = 0;
gp->status = Grunning;
m->curg = gp;
gp->m = m;
...
runtime·gogo(&gp->sched, 0);
}schedlock 方法來取得全域鎖定。 gput 方法來保存目前 Goroutine 的運行狀態等信息,以便於後續的使用。 nextgandunlock 方法來尋找下一個可運行 Goroutine,並且釋放全域鎖定給其他調度使用。 runtime·gogo 方法,將剛剛所取得的下一個待執行的 Goroutine 運行起來,進入下一輪調度。 透過對Go1.0.1 的調度器原始碼剖析,我們可以發現一個比較有趣的點。那就是調度器本身(schedule 方法),在正常流程下,是不會回傳的,也就是不會結束主流程。
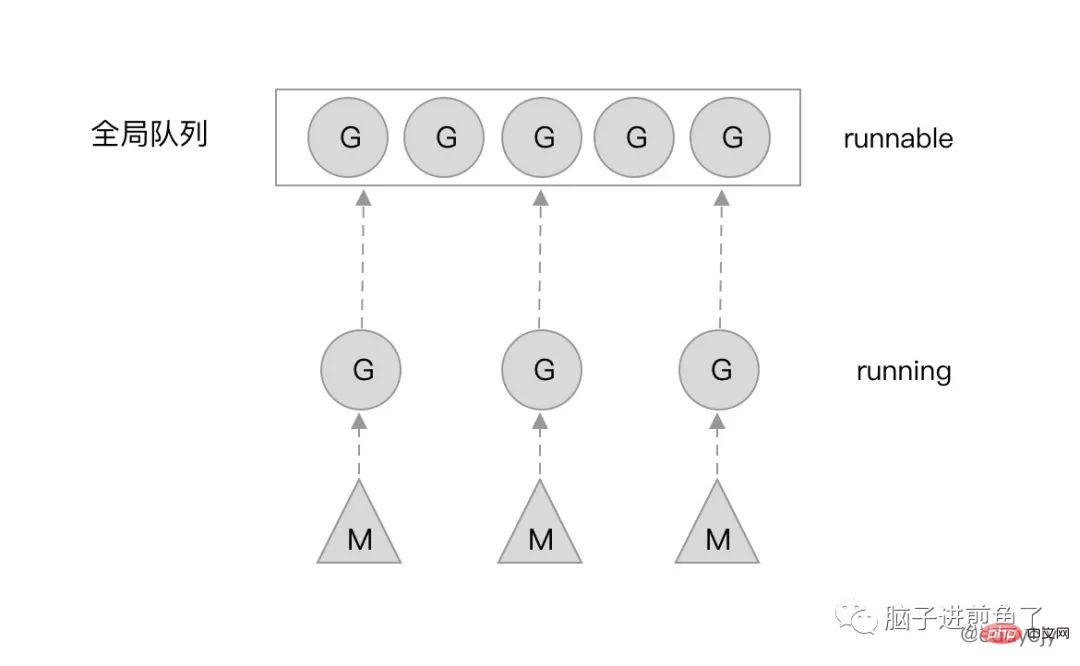
他會不斷地運行調度流程,GoroutineA 完成了,就開始尋找GoroutineB,尋找到B 了,就把已經完成的A 的調度權交給B,讓GoroutineB 開始被調度,也就是運作。
當然了,也有被正在阻塞(Blocked)的 G。假設 G 正在做一些系統、網路調用,那麼就會導致 G 停滯。這時候 M(系統執行緒)就會被會重新放入核心佇列中,等待新的一輪喚醒。
GM 模型的缺點
這麼表面的看起來,GM 模型似乎牢不可破,毫無缺陷。但為什麼要改呢?
在2012 年時Dmitry Vyukov 發表了文章《Scalable Go Scheduler Design Doc》,目前也依然是各大研究Go 調度器文章的主要對象,其在文章內講述了整體的原因和考慮,下述內容將引用該文章。
目前(代指 Go1.0 的 GM 模型)的 Goroutine 調度器限制了用 Go 編寫的並發程式的可擴展性,尤其是高吞吐量伺服器和平行計算程式。
實作有以下的問題:
存在單一的全域mutex(Sched.Lock)與集中狀態管理: mutex 需要保護所有與goroutine 相關的操作(創建、完成、重排等),導致鎖定競爭嚴重。 Goroutine 傳遞的問題: #goroutine(G)交接(G.nextg):工作者執行緒( M's)之間會經常交接可運行的goroutine。 上述可能會導致延遲增加和額外的開銷。每個 M 必須能夠執行任何可運行的 G,特別是剛剛創建 G 的 M。 每個M 都需要做記憶體快取(M.mcache): - ##會導致資源消耗過大(每個mcache 可以吸收到2M 的記憶體快取和其他快取),資料局部性差。
- 頻繁的執行緒阻塞/解阻塞:
- 在存在syscalls 的情況下,執行緒經常被阻塞和解阻塞。這增加了很多額外的效能開銷。
為了解決GM 模型的以上諸多問題,在Go1.1 時,Dmitry Vyukov 在GM 模型的基礎上,新增了一個P(Processor)元件。並且實作了 Work Stealing 演算法來解決一些新產生的問題。
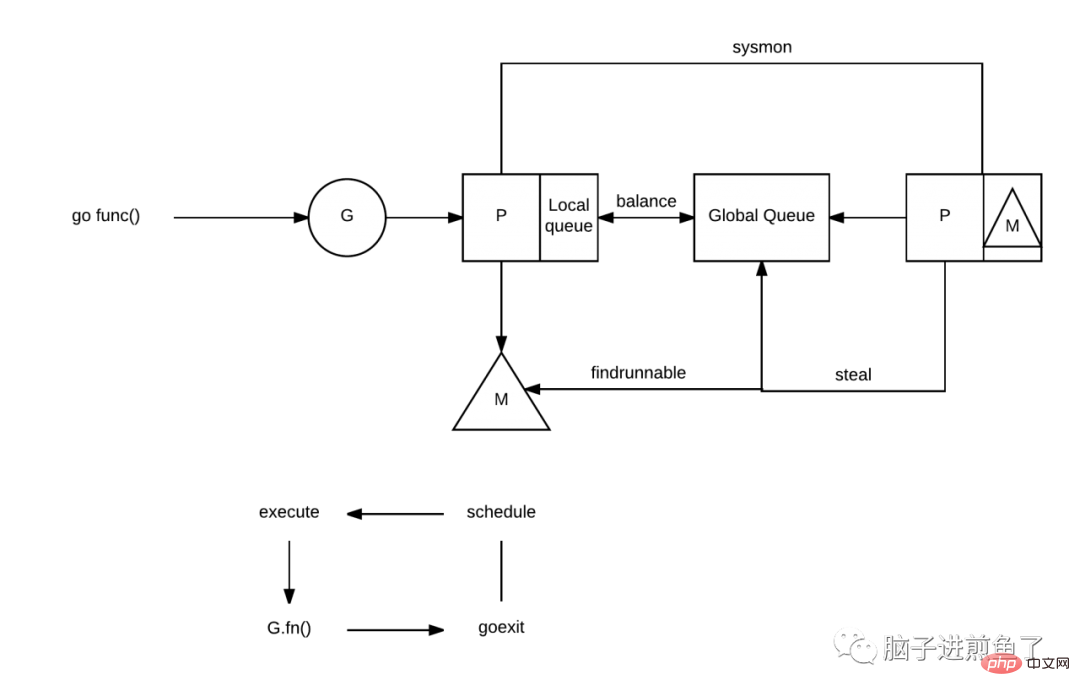
加上了 P 之後會帶來什麼改變呢?我們再更顯式的講一下。
每個 P 有自己的本地佇列,大幅度的減輕了對全域佇列的直接依賴,所帶來的效果就是鎖定競爭的減少。而 GM 模型的效能開銷大頭就是鎖定競爭。
每個P 相對的平衡上,在GMP 模型中也實作了Work Stealing 演算法,如果P 的本機佇列為空,則會從全域佇列或其他P 的本機佇列中竊取可運行的G 來運行,減少空轉,提高了資源利用率。
為什麼要有P
#這時候就有小夥伴會疑惑了,如果是想實作本地隊列、Work Stealing 演算法,那為什麼不直接在M 上加呢,M 也照樣可以實現類似的功能。
為什麼再加多一個 P 元件?
結合 M(系統執行緒) 的定位來看,若這麼做,有以下問題。
一般來講,M 的數量都會多於 P。像在 Go 中,M 的數量最大限制是 10000,P 的預設數量的 CPU 核數。另外由於 M 的屬性,也就是如果有系統阻塞調用,阻塞了 M,又不夠用的情況下,M 會不斷增加。
M 不斷增加的話,如果本地佇列掛載在 M 上,那就意味著本地佇列也會隨之增加。這顯然是不合理的,因為本地佇列的管理會變得複雜,且 Work Stealing 效能會大幅下降。
M 被系統呼叫阻塞後,我們是期望把他既有未執行的任務分配給其他繼續運行的,而不是一阻塞就導致全部停止。
因此使用 M 是不合理的,那麼引入新的元件 P,把本地佇列關聯到 P 上,就能很好的解決這個問題。
總結
今天這篇文章結合了整個 Go 語言調度器的一些歷史情況、原因分析以及解決方案說明。
」GMP 模型,為什麼要有 P「 這個問題就像是一道系統設計了解,因為現在很多人為了應對面試,會硬背 GMP 模型,或者是泡麵式過了一遍。而理解其中真正背後的原因,才是我們要去學習的去理解。
知其然知其所以然,才可破局。
以上是再見 Go 面試官:GMP 模型,為什麼要有 P?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何利用PHP和GMP進行大整數的RSA加密與解密演算法
Jul 28, 2023 pm 05:25 PM
如何利用PHP和GMP進行大整數的RSA加密與解密演算法
Jul 28, 2023 pm 05:25 PM
如何利用PHP和GMP進行大整數的RSA加密和解密演算法RSA加密演算法是一種非對稱加密演算法,廣泛應用於資料安全領域。它基於兩個特別大的素數和一些簡單的數學運算,實現了公鑰加密和私鑰解密的過程。在PHP語言中,可以透過GMP(GNUMultiplePrecision)函式庫來實現大整數的計算,結合RSA演算法實現加密和解密功能。本文將介紹如何利用PHP和GMP函式庫來
 再見 Go 面試官:GMP 模型,為什麼要有 P?
Aug 08, 2023 pm 04:31 PM
再見 Go 面試官:GMP 模型,為什麼要有 P?
Aug 08, 2023 pm 04:31 PM
「GMP 模型,為什麼要有 P「 這個問題就像是一道系統設計了解,因為現在很多人為了應對面試,會硬背 GMP 模型,或者是泡麵式過了一遍。而理解其中真正背後的原因,才是我們要去學習的去理解。
 php gmp 怎麼編譯安裝
Nov 08, 2022 am 09:35 AM
php gmp 怎麼編譯安裝
Nov 08, 2022 am 09:35 AM
php gmp編譯安裝的方法:1、透過「bzip2 -d gcc-4.1.0.tar.bz2」解壓縮php包;2、執行「tar -xvf gcc-4.1.0.tar」或「tar -xvf *. tar」指令;3、透過「make install」安裝gmp即可。
 如何使用PHP和GMP實現大數的快速乘法運算
Jul 31, 2023 pm 01:31 PM
如何使用PHP和GMP實現大數的快速乘法運算
Jul 31, 2023 pm 01:31 PM
如何使用PHP和GMP實現大數的快速乘法運算導言:在計算機科學中,整數運算是非常基礎且常用的操作之一。然而,當涉及到大整數時,傳統的運算方法會變得低效。本文將介紹如何使用PHP中的GMP(GNUMultiplePrecision)函式庫來實現大數的快速乘法運算,並提供對應的程式碼範例。 GMP函式庫簡介GMP函式庫是一個高精度運算函式庫,它提供了大整數的加減乘除、冪運算等功
 如何使用PHP和GMP實現RSA加密和解密演算法
Jul 28, 2023 pm 11:54 PM
如何使用PHP和GMP實現RSA加密和解密演算法
Jul 28, 2023 pm 11:54 PM
如何使用PHP和GMP實現RSA加密和解密演算法RSA加密演算法是一種非對稱加密演算法,廣泛應用於資訊安全領域。在實際應用中,常常需要使用程式語言來實作RSA加密和解密演算法。 PHP是一種常用的伺服器端腳本語言,而GMP(GNUMultiplePrecision)是一種高精度數學計算庫,可以幫助我們進行RSA演算法中所需的大數運算。本文將介紹如何使用PHP和GMP
 如何使用PHP和GMP產生大質數
Aug 01, 2023 pm 01:37 PM
如何使用PHP和GMP產生大質數
Aug 01, 2023 pm 01:37 PM
如何使用PHP和GMP產生大質數引言:在密碼學和安全性領域中,隨機產生大質數是非常重要的。 PHP的GMP(GNUMultiplePrecision)擴充功能提供了高精度計算功能,我們可以利用它來產生所需的大質數。本文將介紹如何使用PHP和GMP產生大質數,並提供對應的程式碼範例。步驟一:安裝GMP擴充首先,我們需要確保伺服器上已安裝並啟用GMP擴充。可以透過以下
 PHP與GMP教學:如何計算大數的最小公倍數
Jul 28, 2023 pm 11:51 PM
PHP與GMP教學:如何計算大數的最小公倍數
Jul 28, 2023 pm 11:51 PM
PHP與GMP教學:如何計算大數的最小公倍數導言:在計算機中,常常需要處理大數運算的問題。然而,由於計算機的儲存限制,傳統的整數類型無法處理超過一定範圍的數字。為了解決這個問題,我們可以使用PHP的GMP(GNUMultiplePrecision)函式庫來進行大數運算。本文將介紹如何使用PHP和GMP函式庫來計算任兩個大數的最小公倍數。什麼是最小公倍數?最小公
 從頭到尾:如何使用php擴充GMP進行大數運算
Aug 02, 2023 am 11:33 AM
從頭到尾:如何使用php擴充GMP進行大數運算
Aug 02, 2023 am 11:33 AM
從頭到尾:如何使用PHP擴充GMP進行大數運算隨著網路的發展,大數據處理成為了我們日常開發中不可或缺的一部分。在很多場景下,我們需要對大於PHP的整數範圍(-2^31-1到2^31-1)的數進行運算。在這種情況下,PHP的GMP擴充就可以派上用場了。 GMP(GNUMultiplePrecisionArithmeticLibrary)是一個用
