

Python實現XML資料的過濾與篩選


Python實現XML資料的過濾和篩選
XML(eXtensible Markup Language)是一種用於儲存和傳輸資料的標記語言,它具有靈活性和可擴展性,常被用於在不同系統之間進行資料交換。在處理XML資料時,我們經常需要對其進行過濾和篩選,以提取我們所需的資訊。本文將介紹如何使用Python來實現XML資料的過濾與篩選。
- 導入所需模組
在開始之前,我們需要導入所需的模組。在Python中,我們可以使用xml.etree.ElementTree模組來處理XML資料。
import xml.etree.ElementTree as ET
- 解析XML檔案
要處理XML數據,首先需要將XML檔案解析為樹狀結構。我們可以使用ElementTree的parse函數來實作。
tree = ET.parse('data.xml') # 解析XML文件
root = tree.getroot() # 获取根节点這裡假設我們有一個名為"data.xml"的XML文件,我們使用parse函數將其解析為樹狀結構,並透過getroot函數取得根節點。
- 過濾指定標籤
如果我們只關心某些特定標籤的數據,可以透過遍歷XML樹來過濾我們感興趣的標籤。以下是一個範例,我們假設要提取所有名為"item"的標籤:
items = root.findall('item') # 过滤出所有名为"item"的标签
for item in items:
# 处理item标签的数据
pass使用findall函數可以過濾出所有名為"item"的標籤,並將其儲存在一個清單中。然後,我們可以遍歷列表,對每個item標籤的資料進行處理。
- 篩選指定屬性
除了過濾標籤,有時我們還需要根據屬性的值來篩選出特定的資料。下面是一個範例,我們假設要提取屬性為"type1"的"item"標籤:
items = root.findall('item[@type="type1"]') # 筛选出属性为"type1"的item标签
for item in items:
# 处理item标签的数据
pass在findall函數中使用XPath表達式可以根據屬性的值篩選出特定的標籤。在這個範例中,我們使用[@type="type1"]來指定篩選條件。
- 取得標籤的文字內容
如果我們只關心標籤的文字內容,可以使用Element的text屬性來取得。下面是一個範例,我們假設要提取所有"item"標籤的文字內容:
items = root.findall('item') # 过滤出所有名为"item"的标签
for item in items:
text = item.text # 获取标签的文本内容
# 处理文本内容透過存取Element的text屬性,我們可以取得標籤的文字內容並進行處理。
以上就是使用Python實現XML資料的過濾和篩選的基本方法。透過解析XML文件,過濾標籤和屬性,以及取得標籤的文字內容,我們可以根據需要提取XML資料中的特定資訊。希望本文能對使用Python處理XML資料的讀者有所幫助。
參考文獻:
- Python官方文件- xml.etree.ElementTree:https://docs.python.org/3/library/xml.etree.elementtree.html
以上是Python實現XML資料的過濾與篩選的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



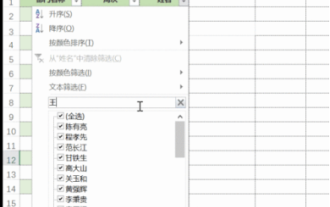 excel同時篩選3個以上關鍵字怎麼操作
Mar 21, 2024 pm 03:16 PM
excel同時篩選3個以上關鍵字怎麼操作
Mar 21, 2024 pm 03:16 PM
在日常辦公中經常使用Excel來處理數據,時常遇到需要使用「篩選」功能。當我們在Excel中選擇執行「篩選」時,對於同一列而言,最多只能篩選兩個條件,那麼,你知道excel同時篩選3個以上關鍵字該怎麼操作嗎?接下來,就請小編為大家示範一次。第一種方法是將條件逐步加入篩選器。如果要同時篩選出三個符合條件的明細,首先需要逐步篩選出其中一個。開始時,可以先依照條件篩選出姓「王」的員工。然後按一下【確定】,接著在篩選結果中勾選【將目前所選內容新增至篩選器】。操作步驟如下圖所示。 同樣,再次分別執行篩選
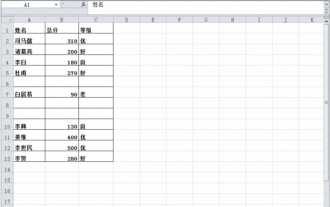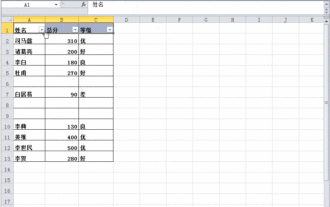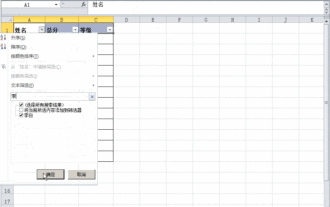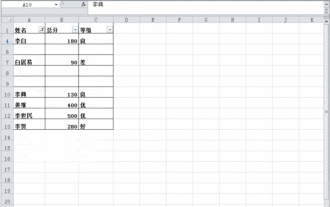 Excel表格中明明有資料但篩選空白怎麼辦?
Mar 13, 2024 pm 06:38 PM
Excel表格中明明有資料但篩選空白怎麼辦?
Mar 13, 2024 pm 06:38 PM
Excel表格是一款很常用的辦公室軟體,很多使用者都會在表格中記錄下各種數據,但是表格明明有數據單篩選是空白,關於這個問題,很多用戶都不知道要怎麼解決,沒有關係,本期軟體教程內容就來為廣大用戶們進行解答,有需要的用戶歡迎來查看解決方法吧。 Excel表格中明明有資料但篩選空白怎麼辦? 第一種原因,表格中含有空行 我們要篩選所有姓「李」的人,但可以看到並沒有篩選出正確的結果,因為表格中含有空行,這種情況如何處理呢? 解決方法: 步驟一:選取所有的內容再進行篩選 按c
 如何多條件使用Excel過濾功能
Feb 26, 2024 am 10:19 AM
如何多條件使用Excel過濾功能
Feb 26, 2024 am 10:19 AM
如果您需要了解如何在Excel中使用具有多個條件的篩選功能,以下教學將引導您完成對應步驟,確保您可以有效地篩選資料和排序資料。 Excel的篩選功能是非常強大的,能夠幫助您從大量資料中提取所需的資訊。這個功能可以根據您設定的條件,過濾資料並只顯示符合條件的部分,讓資料的管理變得更有效率。透過使用篩選功能,您可以快速找到目標數據,節省了尋找和整理數據的時間。這個功能不僅可以應用在簡單的資料清單上,還可以根據多個條件進行篩選,幫助您更精準地定位所需資訊。總的來說,Excel的篩選功能是一個非常實用的
 使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序
Aug 07, 2023 pm 04:17 PM
使用Python實現XML資料的篩選和排序引言:XML是一種常用的資料交換格式,它以標籤和屬性的形式儲存資料。在處理XML資料時,我們經常需要對資料進行篩選和排序。 Python提供了許多有用的工具和函式庫來處理XML數據,本文將介紹如何使用Python實現XML資料的篩選和排序。讀取XML檔案在開始之前,我們需要先讀取XML檔案。 Python有許多XML處理函式庫,
 夸克如何開啟過濾重複文件
Mar 01, 2024 am 11:25 AM
夸克如何開啟過濾重複文件
Mar 01, 2024 am 11:25 AM
使用夸克瀏覽器時,其中有一個過濾重複文件的功能,有些朋友對此還不是很了解,下面為大家介紹一下打開這個功能的操作方法,感興趣的朋友和我一起來看看吧。 1.先在手機中點選「夸克瀏覽器」進入介面後,在頁面中間的選項裡點選選擇「夸克網盤」打開進入。 2.在夸克網盤介面裡下方部分找到“備份設定”,並在上面點擊打開,如下圖所示位置:3.接下來在進入的頁面裡有一個“過濾重複文件”,在它的後面顯示有一個開關按鈕,在上面點擊圓形的滑桿把它設定為彩色即為開啟該功能,繼續備份檔案時將會跳過重複的檔案來節省網盤容量。
 使用JavaScript實作表格篩選功能
Aug 10, 2023 pm 09:51 PM
使用JavaScript實作表格篩選功能
Aug 10, 2023 pm 09:51 PM
使用JavaScript實作表格篩選功能隨著網路科技的不斷發展,表格成為了網頁中常見的展示資料的方式。然而,當資料量龐大時,使用者往往會面臨找到特定資料的困難。因此,為表格添加篩選功能,讓使用者可以快速找到所需的數據,成為了許多網頁設計的需求。本文將介紹如何使用JavaScript實作表格篩選功能。首先,我們需要有一份表格資料。下面是一個簡單的例子:<t
 Python實現XML資料的過濾與篩選
Aug 09, 2023 am 10:13 AM
Python實現XML資料的過濾與篩選
Aug 09, 2023 am 10:13 AM
Python實現XML資料的過濾和篩選XML(eXtensibleMarkupLanguage)是一種用於儲存和傳輸資料的標記語言,它具有靈活性和可擴充性,常被用於在不同系統之間進行資料交換。在處理XML資料時,我們經常需要對其進行過濾和篩選,以提取我們所需的資訊。本文將介紹如何使用Python來實現XML資料的過濾與篩選。導入所需模組在開始之前,我們
 如何利用PHP函數進行搜尋和篩選資料?
Jul 24, 2023 am 08:01 AM
如何利用PHP函數進行搜尋和篩選資料?
Jul 24, 2023 am 08:01 AM
如何利用PHP函數進行搜尋和篩選資料?在使用PHP進行開發的過程中,經常需要對資料進行搜尋和過濾。 PHP提供了豐富的函數和方法來幫助我們實作這些操作。本文將介紹一些常用的PHP函數和技巧,幫助你有效率地進行資料的搜尋和過濾。字串搜尋PHP中常用的字串搜尋函數是strpos()和strstr()。 strpos()用於尋找字串中某個子字串的位置,如果存在,則返
