

Open LLM榜單再次刷新,比Llama 2更強的「鴨嘴獸」來了

為了挑戰 OpenAI 的 GPT-3.5 和 GPT-4 等封閉模型的主導地位,一系列開源模型正在崛起,其中包括 LLaMa、Falcon 等。最近,Meta AI 推出了被譽為開源領域最強大模型的 LLaMa-2,許多研究者也在此基礎上建立自己的模型。例如,StabilityAI 利用Orca 風格的資料集對Llama2 70B 模型進行微調,開發出了StableBeluga2,在Huggingface 的Open LLM 排行榜上也取得了不錯的成績
最新的Open LLM榜單排名已經發生了變化,Platypus(鴨嘴獸)模型成功登上了榜首
#作者來自波士頓大學,使用了PEFT、LoRA和資料集Open-Platypus對Platypus進行了基於Llama 2的微調優化

作者在一篇論文中詳細介紹了Platypus

這篇論文可以在以下網址找到:https://arxiv.org/abs/2308.07317
#以下是本文的主要貢獻:
- Open-Platypus 是一個小規模的資料集,由公共文字資料集的精選子集組成。該資料集由 11 個開源資料集組成,重點是提高 LLM 的 STEM 和邏輯知識。它主要由人類設計的問題組成,只有 10% 的問題是由 LLM 產生的。 Open-Platypus 的主要優勢在於其規模和質量,它可以在很短的時間內實現非常高的效能,而且微調的時間和成本都很低。具體來說,在單一 A100 GPU 上使用 25k 個問題訓練 13B 模型只需 5 小時。
- 描述了相似性排除過程,減少資料集的大小,並減少資料冗餘。
- 詳細分析了始終存在的開放式 LLM 訓練集與重要 LLM 測試集中包含的資料相污染的現象,並介紹了作者避免這一隱患的訓練資料過濾過程。
- 介紹了專門的微調 LoRA 模組進行選擇和合併的過程。
Open-Platypus 資料集
#作者目前已在Hugging Face 上發布了Open-Platypus 資料集

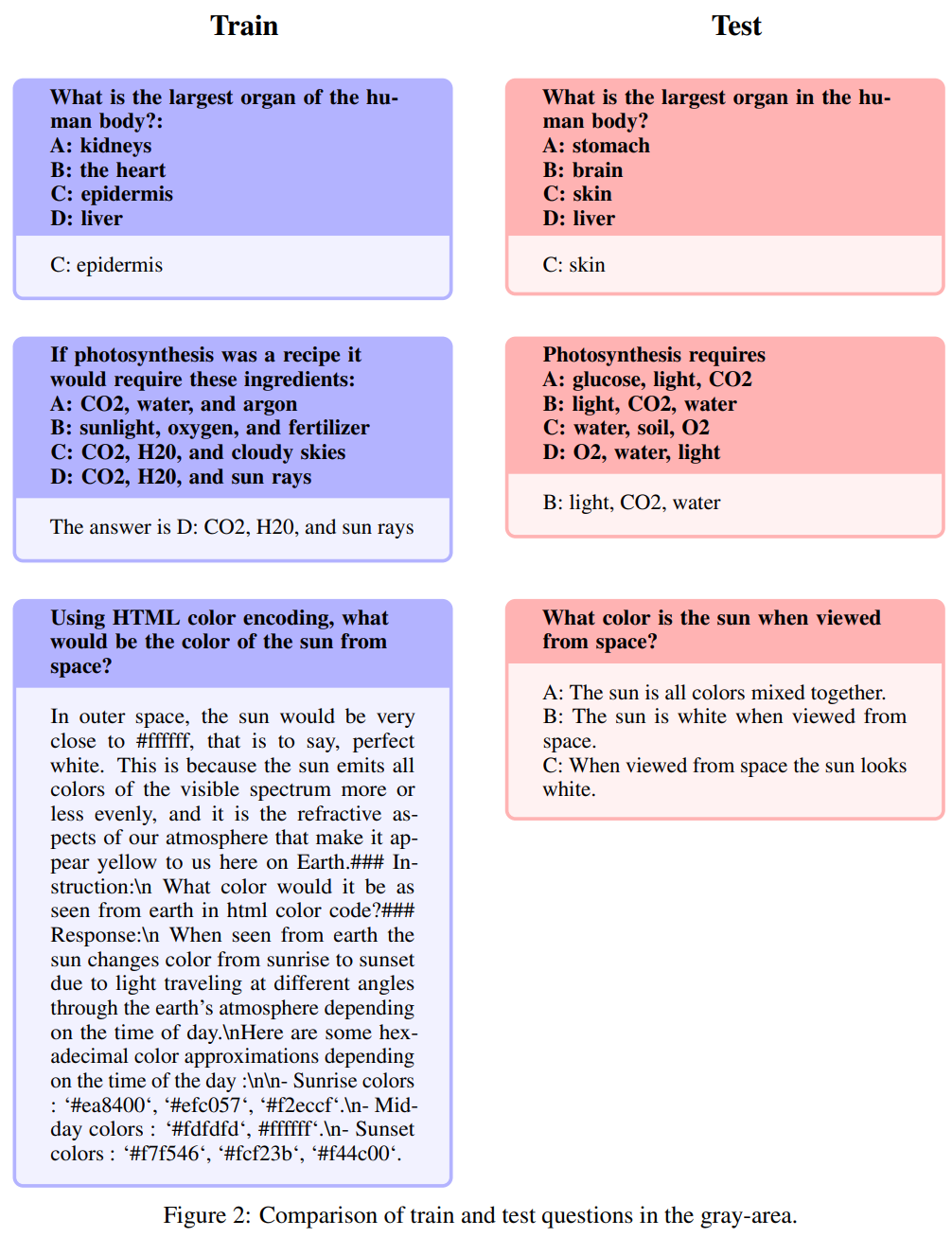
##為了避免基準測試問題洩漏到訓練集中,本文方法首先考慮防止此問題,以確保結果不僅僅是透過記憶產生的偏差。作者在追求準確性的同時,也意識到在標記請再說一次問題時需要彈性,因為問題的提出方式多種多樣,同時也會受到通用領域知識的影響。為了管理潛在的洩漏問題,作者精心設計了啟發式方法,用於手動過濾與 Open-Platypus 中基準問題餘弦嵌入相似度超過80%的問題。他們將潛在洩漏問題分為三類:(1) 請再說一次問題;(2) 重新描述: 這個區域呈現出灰色的色調問題;(3) 類似但不完全相同的問題。為了謹慎起見,他們將所有這些問題都排除在訓練集之外
#請再說一次
這段文字幾乎完全複製了測驗題集的內容,只是對單字進行了輕微修改或重新排列。根據上表中洩漏問題的數量,作者認為這是唯一屬於污染的類別。以下是具體範例:

重新描述: 這個區域呈現出灰色的色調
以下问题被称为重新描述: 这个区域呈现出灰色的色调,包括并非完全请再说一次、属于常识范畴的问题。虽然作者将这些问题的最终评判权留给了开源社区,但他们认为这些问题往往需要专家知识。需要注意的是,这类问题包括指令完全相同,但答案却同义的问题:
类似但不完全相同
这些问题的具有较高的相似度,但由于问题之间有着细微的变化,在答案上存在着显著差异。

微调与合并
作者在数据集完善后,专注于两种方法:低秩近似(LoRA)训练和参数高效微调(PEFT)库。与完全微调不同,LoRA保留了预训练模型的权重,并在transformer层中使用秩分解矩阵进行整合,从而减少了可训练参数,节省了训练时间和成本。最初,微调主要集中在注意力模块,如v_proj、q_proj、k_proj和o_proj。随后,根据He等人的建议,扩展到gate_proj、down_proj和up_proj模块。除非可训练参数小于总参数的0.1%,否则这些模块都表现出更好的效果。作者对13B和70B模型都采用了这种方法,结果可训练参数分别为0.27%和0.2%。唯一的区别在于这些模型的初始学习率
结果
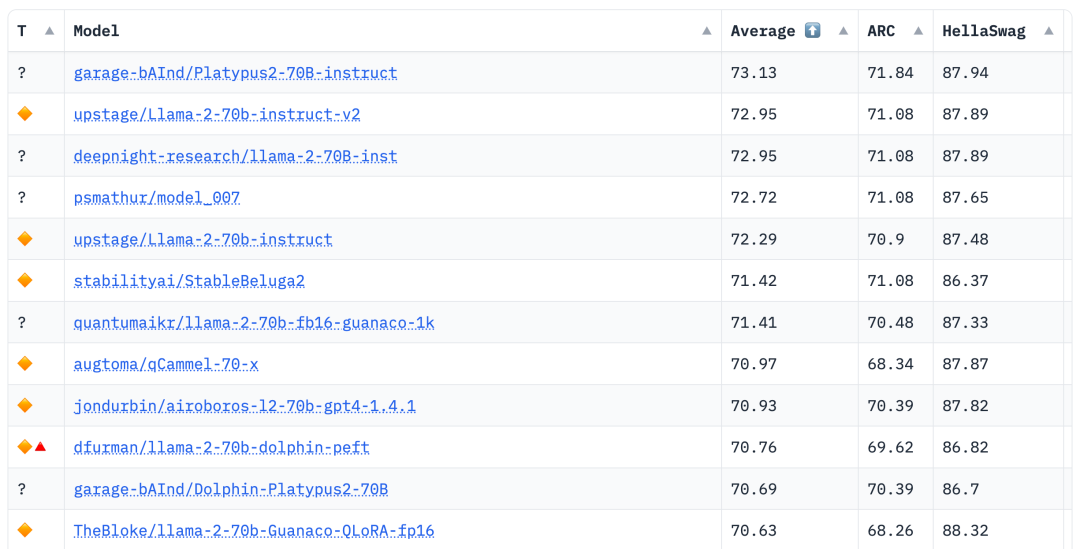
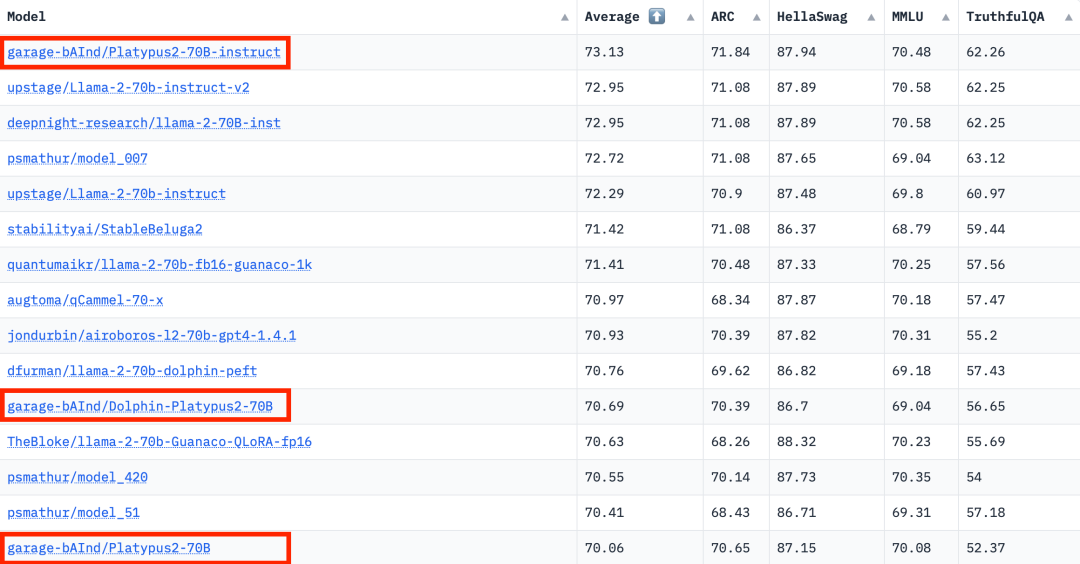
根据2023年8月10日Hugging Face Open LLM排行榜数据,作者对Platypus与其他SOTA模型进行了比较,发现Platypus2-70Binstruct变体表现出色,以73.13的平均分稳居榜首
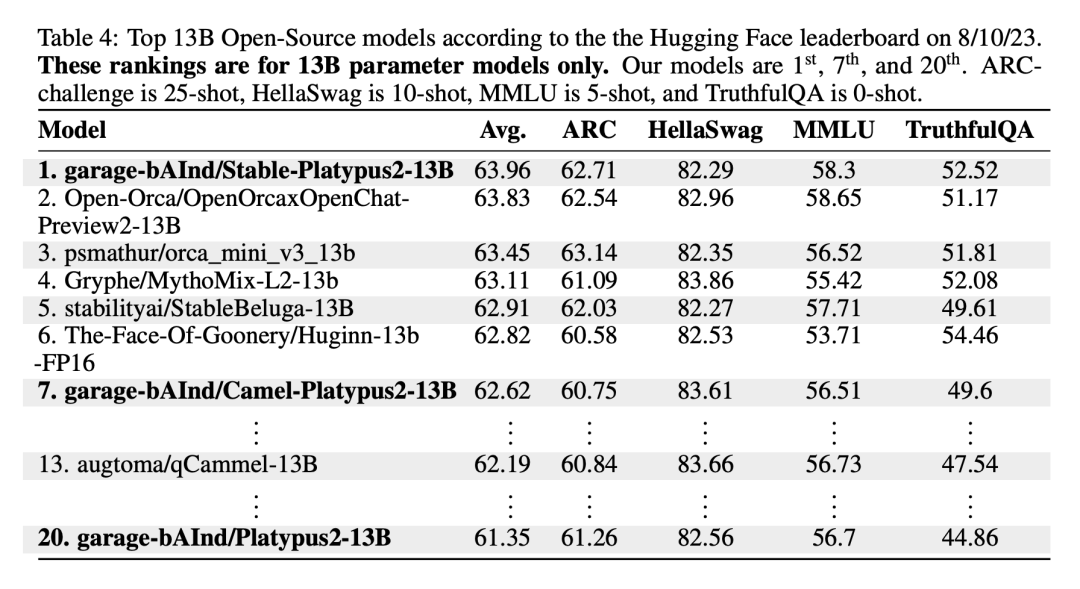
Stable-Platypus2-13B 模型在 130 亿参数模型中以 63.96 的平均分脱颖而出,值得关注
局限性
Platypus, as a fine-tuned extension of LLaMa-2, retains many of the constraints of the base model and introduces specific challenges through targeted training. It shares the static knowledge base of LLaMa-2, which may become outdated. Additionally, there is a risk of generating inaccurate or inappropriate content, particularly in cases of unclear prompts. While Platypus has been enhanced in STEM and English logic, its proficiency in other languages is not reliable and may be inconsistent. It occasionally produces biased or harmful content. The author acknowledges efforts to minimize these issues but acknowledges the ongoing challenges, particularly in non-English languages.
对于 Platypus 的滥用可能性,这是一个令人担忧的问题,因此在部署之前开发人员应对其应用程序进行安全测试。Platypus 在其主要领域之外可能存在一些限制,因此用户应小心操作,并考虑进行额外的微调以获得最佳性能。用户需要确保 Platypus 的训练数据与其他基准测试集没有重叠。作者对数据污染问题非常谨慎,避免将模型与在有污点的数据集上训练的模型合并。虽然经过清理的训练数据中确认没有污染,但也不能排除可能有一些问题被忽略。如需详细了解这些限制,请参阅论文中的限制部分
以上是Open LLM榜單再次刷新,比Llama 2更強的「鴨嘴獸」來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 MongoDB性能優化策略,提升數據讀寫速度
Apr 12, 2025 am 06:42 AM
MongoDB性能優化策略,提升數據讀寫速度
Apr 12, 2025 am 06:42 AM
MongoDB性能優化可以通過以下幾個方面實現:1.創建合適的索引,避免全表掃描,根據查詢模式選擇索引類型,定期分析查詢日誌;2.編寫高效的查詢語句,避免使用$where操作符,合理運用查詢操作符,進行分頁查詢;3.合理設計數據模型,避免過大的文檔,保持文檔結構簡潔一致,使用合適的字段類型,考慮數據分片;4.使用連接池復用數據庫連接,減少連接開銷;5.持續監控性能指標,例如查詢時間和連接數,並根據監控數據不斷調整優化策略,最終實現MongoDB的飛速讀寫。
 Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian系統中,Nginx的訪問日誌和錯誤日誌默認存儲位置如下:訪問日誌(accesslog):/var/log/nginx/access.log錯誤日誌(errorlog):/var/log/nginx/error.log以上路徑是標準DebianNginx安裝的默認配置。如果您在安裝過程中修改過日誌文件存放位置,請檢查您的Nginx配置文件(通常位於/etc/nginx/nginx.conf或/etc/nginx/sites-available/目錄下)。在配置文件中
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 Debian上PostgreSQL日誌管理
Apr 12, 2025 pm 07:57 PM
Debian上PostgreSQL日誌管理
Apr 12, 2025 pm 07:57 PM
Debian系統上的PostgreSQL日誌管理涵蓋日誌配置、查看、輪換和存儲位置等多個方面。本文將詳細介紹相關步驟和最佳實踐。 PostgreSQL日誌配置為了啟用日誌記錄,需要在postgresql.conf文件中修改以下參數:logging_collector=on:啟用日誌收集器。 log_directory='pg_log':指定日誌文件存儲目錄(例如:'pg_log')。請根據實際情況修改路徑。 log_filename='postgresql-%Y-%m-%d_%H%
