

美團面試題:慢SQL有遇過嗎?是怎麼解決的?
關於慢SQL,我和麵試官扯了很久,面試官也是很謙虛的,總是點頭,自己以為回答的還可以。 最後的最後,還是說了「你先回去等通知吧!」。

所以,我決定把這個慢SQL技巧點,好好跟你分享分享。希望你下次在遇到類似的面試,能順順利利輕輕鬆鬆的斬獲自己想要的offer。
人生最大的喜悅是每個人都說你做不到,你卻完成它了!
什麼是慢SQL?
#MySQL的慢查詢日誌是MySQL提供的一種日誌記錄,它用來記錄MySQL中查詢時間超過(大於)設定閾值(long_query_time)的語句,記錄到慢查詢日誌中。
其中,long_query_time的預設值是10,單位是秒,也就是說預設情況下,你的SQL查詢時間超過10秒就算慢SQL了。
如何開啟慢SQL日誌?
在MySQL中,慢SQL日誌預設是未開啟的,也就說就算出現了慢SQL,也不會告訴你的,如果需要知道哪些SQL是慢SQL,需要我們手動開啟慢SQL日誌的。
關於慢SQL是否開啟,我們可以透過下面這個指令來查看:
-- 查看慢查询日志是否开启 show variables like '%slow_query_log%';
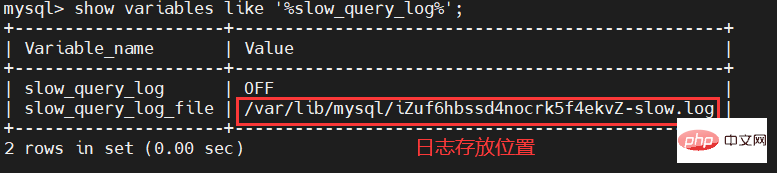
透過指令,我們就可以看到slow_query_log項目為OFF,表示我們的慢SQL日誌並未開啟。另外我們也可以看到我們慢SQL日誌存放在哪個目錄下和日誌檔名。
下面我們來開啟慢SQL日誌,執行下面的指令:
set global slow_query_log = 1;
這裡要注意,這裡開啟的是我們目前的資料庫,並且,我們重新啟動資料庫後會失效的。
開啟慢SQL日誌後,再檢視:
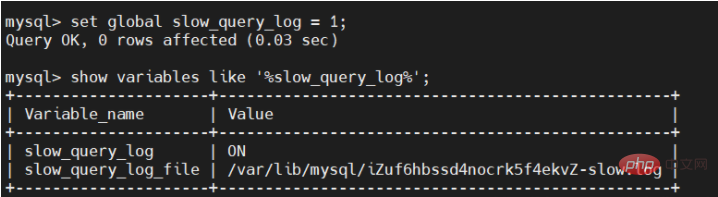
#slow_query_log項目變成ON,說明開啟成功。
上面說過慢SQL預設時間是10秒,我們透過下面的指令就可以看到我們慢SQL的預設時間:
show variables like '%long_query_time%';
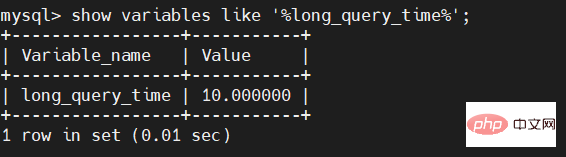
我們總不能一直使用這個預設值,可能很多業務需要時間更短或更長,所以此時,我們就需要對預設時間進行修改,修改指令如下:
set long_query_time = 3;
修改完了,我們再來看看是否已經改成了3秒。
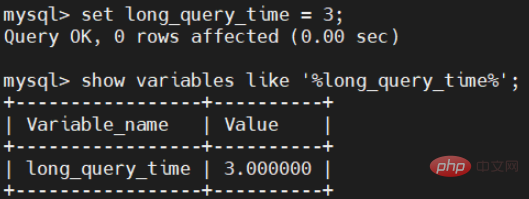
這裡要注意:想要永久的生效,還需要修改MySQL下面的設定檔my. cnf 檔。
[mysqld] slow_query_log=1 slow_query_log_file=/var/lib/mysql/atguigu-slow.log long_query_time=3 log_output=FILE
注意:不同作業系統,設定有些差別。
Linux作業系統中
在mysql設定檔my.cnf中增加
log-slow-queries=/var/lib/mysql/slowquery.log (指定日誌檔案存放位置,可以為空,系統會給一個缺省的檔案host_name-slow.log)
long_query_time=2 (記錄超過的時間,預設為10s)
log-queries-not-using-indexes (log下来没有使用索引的query,可以根据情况决定是否开启)
log-long-format (如果设置了,所有没有使用索引的查询也将被记录)
Windows操作系统中
在my.ini的[mysqld]添加如下语句:
log-slow-queries = E:\web\mysql\log\mysqlslowquery.log
long_query_time = 3(其他参数如上)
执行一条慢SQL,因为我们前面已经设置好了慢SQL时间为3秒,所以,我们只要执行一条SQL时间超过3秒即可。
SELECT SLEEP(4);
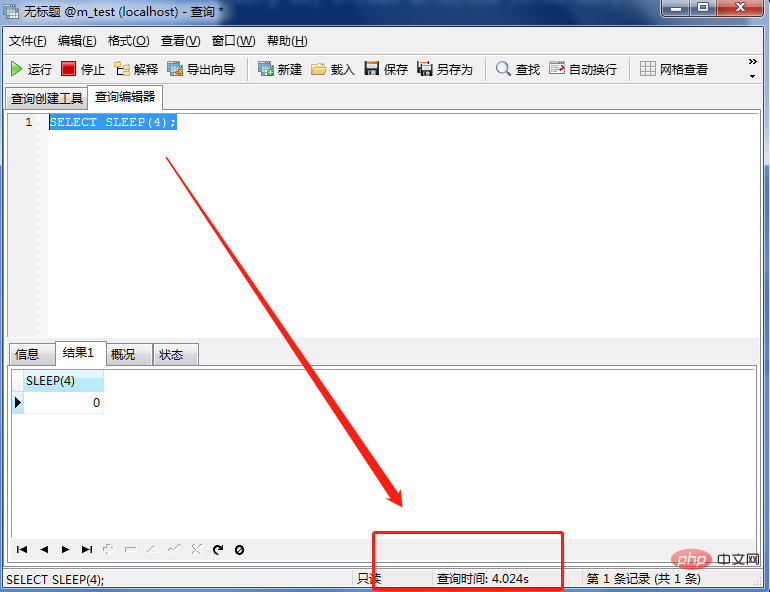
该SQL耗时4.024秒,下面我们就来查看慢SQL出现了多少条。
使用命令:
show global status like '%Slow_queries%';
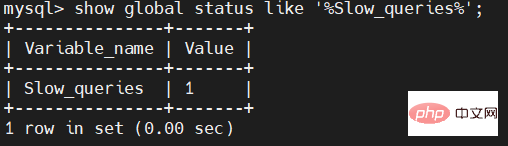
查询SQL历程
找到慢SQL日志文件,打开后就会出现类似下面这样的语句;
# Time: 2021-07-20T09:17:49.791767Z # User@Host: root[root] @ localhost [] Id: 150 # Query_time: 0.002549 Lock_time: 0.000144 Rows_sent: 1 Rows_examined: 4079 SET timestamp=1566292669; select * from city where Name = 'Salala';
简单说明:
1.Time 该日志记录的时间
2.User @Host MySQL登录的用户和登录的主机地址
3.Query_time一行 第一个时间是查询的时间、第二个是锁表的时间、第三个是返回的行数、第四个是扫描的行数
4.SET timestamp 这一个是MySQL查询的时间
5.sql语句 这一行就很明显了,表示的是我们执行的sql语句
切记
如果你將long_query_time=0 ,那就意味著,我們所有的查詢SQL語句都會輸出到慢SQL日誌檔。
如何定位慢SQL?
通常我們定位慢SQL有兩種方式:
第一種:定位慢查詢SQL可以透過兩個表象進行判斷
系統級表象: #使用sar##指令和top指令查看目前系統的狀態 也可以使用Prometheus和Grafana監控工具來檢視目前系統狀態 CPU消耗嚴重 #IO等待嚴重 ##IO 專案日誌出現逾時等錯誤 SQL語句表象: SQL 語句冗長SQL##語句執行時間過長 SQL從全表掃描中取得資料 #執行計劃中的
cost很大
#########第二種:根據不同的資料庫使用不同的方式取得問題###SQL######MySQL: 慢查询日志 测试工具loadrunner ptquery工具 Oracle: AWR报告 测试工具loadrunner 相关内部视图vsession_wait GRID CONTROL监控工具
熟悉慢SQL日志分析工具吗?
如果开启了慢SQL日志后,可能会有大量的慢SQL日志产生,此时再用肉眼看,那是不太现实的,所以大佬们就给我搞了个工具:mysqldumpslow。
mysqldumpslow能将相同的慢SQL归类,并统计出相同的SQL执行的次数,每次执行耗时多久、总耗时,每次返回的行数、总行数,以及客户端连接信息等。
通过命令
mysqldumpslow --help
可以看到相关参数的说明:
~# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time比较常用的参数有这么几个:
-s 指定输出的排序方式 t : 根据query time(执行时间)进行排序; at : 根据average query time(平均执行时间)进行排序;(默认使用的方式) l : 根据lock time(锁定时间)进行排序; al : 根据average lock time(平均锁定时间)进行排序; r : 根据rows(扫描的行数)进行排序; ar : 根据average rows(扫描的平均行数)进行排序; c : 根据日志中出现的总次数进行排序; -t 指定输出的sql语句条数; -a 不进行抽象显示(默认会将数字抽象为N,字符串抽象为S); -g 满足指定条件,与grep相似; -h 用来指定主机名(指定打开文件,通常慢查询日志名称为“主机名-slow.log”,用-h exp则表示打开exp-slow.log文件);
使用方式
mysqldumpslow常用的使用方式如下:
# mysqldumpslow -s c slow.log
如上一条命令,应该是mysqldumpslow最简单的一种形式,其中-s参数是以什么方式排序的意思,c指代的是以总数从大到小的方式排序。-s的常用子参数有:c: 相同查询以查询条数和从大到小排序。t: 以查询总时间的方式从大到小排序。l: 以查询锁的总时间的方式从大到小排序。at: 以查询平均时间的方式从大到小排序。al: 以查询锁平均时间的方式从大到小排序。
同样的,还可以增加其他参数,实际使用的时候,按照自己的情况来。
其他常用方式:
# 得到返回记录集最多的10 个SQL mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log # 得到访问次数最多的10 个SQL mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log # 得到按照时间排序的前10 条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log # 另外建议在使用这些命令时结合| 和more 使用,否则有可能出现爆屏情况 mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
接下,我们来个实际操作。
实操
root@yunzongjitest1:~# mysqldumpslow -s t -t 3 Reading mysql slow query log from /var/lib/mysql/exp-slow.log /var/lib/mysql/yunzongjitest1-slow.log Count: 464 Time=18.35s (8515s) Lock=0.01s (3s) Rows=90884.0 (42170176), root[root]@localhost select ************ Count: 38 Time=11.22s (426s) Lock=0.00s (0s) Rows=1.0 (38), root[root]@localhost select *********** not like 'S' Count: 48 Time=5.07s (243s) Lock=0.02s (1s) Rows=1.0 (48), root[root]@localhost select ********='S'
这其中的SQL语句因为涉及某些信息,所以我都用*号将主体替换了,如果希望得到具体的值,使用-a参数。
使用mysqldumpslow查询出来的摘要信息,包含了这些内容:
Count: 464 :表示慢查询日志总共记录到这条sql语句执行的次数;
Time=18.35s (8515s):18.35s表示平均执行时间(-s at),8515s表示总的执行时间(-s t);
Lock=0.01s (3s):与上面的Time相同,第一个表示平均锁定时间(-s al),括号内的表示总的锁定时间(-s l)(也有另一种说法,说是表示的等待锁释放的时间);
Rows=90884.0 (42170176): 第一個值表示掃描的平均行數(-s ar),括號內的值表示掃描的總行數(-s r)。
以上是美團面試題:慢SQL有遇過嗎?是怎麼解決的?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Hibernate 框架中 HQL 和 SQL 的差異是什麼?
Apr 17, 2024 pm 02:57 PM
Hibernate 框架中 HQL 和 SQL 的差異是什麼?
Apr 17, 2024 pm 02:57 PM
HQL和SQL在Hibernate框架中進行比較:HQL(1.物件導向語法,2.資料庫無關的查詢,3.類型安全),而SQL直接操作資料庫(1.與資料庫無關的標準,2.可執行複雜查詢和資料操作)。
 Oracle SQL中除法運算的用法
Mar 10, 2024 pm 03:06 PM
Oracle SQL中除法運算的用法
Mar 10, 2024 pm 03:06 PM
《OracleSQL中除法運算的用法》在OracleSQL中,除法運算是常見的數學運算之一。在資料查詢和處理過程中,除法運算可以幫助我們計算欄位之間的比例或得出特定數值的邏輯關係。本文將介紹OracleSQL中除法運算的用法,並提供具體的程式碼範例。一、OracleSQL中除法運算的兩種方式在OracleSQL中,除法運算可以用兩種不同的方式來進行
 Oracle與DB2的SQL語法比較與區別
Mar 11, 2024 pm 12:09 PM
Oracle與DB2的SQL語法比較與區別
Mar 11, 2024 pm 12:09 PM
Oracle和DB2是兩個常用的關聯式資料庫管理系統,它們都有自己獨特的SQL語法和特性。本文將針對Oracle和DB2的SQL語法進行比較與區別,並提供具體的程式碼範例。資料庫連接在Oracle中,使用以下語句連接資料庫:CONNECTusername/password@database而在DB2中,連接資料庫的語句如下:CONNECTTOdataba
 詳解MyBatis動態SQL標籤中的Set標籤功能
Feb 26, 2024 pm 07:48 PM
詳解MyBatis動態SQL標籤中的Set標籤功能
Feb 26, 2024 pm 07:48 PM
MyBatis動態SQL標籤解讀:Set標籤用法詳解MyBatis是一個優秀的持久層框架,它提供了豐富的動態SQL標籤,可以靈活地建構資料庫操作語句。其中,Set標籤是用來產生UPDATE語句中SET子句的標籤,在更新作業中非常常用。本文將詳細解讀MyBatis中Set標籤的用法,以及透過具體的程式碼範例來示範其功能。什麼是Set標籤Set標籤用於MyBati
 SQL中的identity屬性是什麼意思?
Feb 19, 2024 am 11:24 AM
SQL中的identity屬性是什麼意思?
Feb 19, 2024 am 11:24 AM
SQL中的Identity是什麼,需要具體程式碼範例在SQL中,Identity是一種用於產生自增數字的特殊資料類型,它常用於唯一識別表中的每一行資料。 Identity欄位通常與主鍵列搭配使用,可確保每筆記錄都有獨一無二的識別碼。本文將詳細介紹Identity的使用方式以及一些實際的程式碼範例。 Identity的基本使用方式在建立表格時,可以使用Identit
 Springboot+Mybatis-plus不使用SQL語句進行多表新增怎麼實現
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus不使用SQL語句進行多表新增怎麼實現
Jun 02, 2023 am 11:07 AM
在Springboot+Mybatis-plus不使用SQL語句進行多表添加操作我所遇到的問題準備工作在測試環境下模擬思維分解一下:創建出一個帶有參數的BrandDTO對像模擬對後台傳遞參數我所遇到的問題我們都知道,在我們使用Mybatis-plus中進行多表操作是極其困難的,如果你不使用Mybatis-plus-join這一類的工具,你只能去配置對應的Mapper.xml文件,配置又臭又長的ResultMap,然後再寫對應的sql語句,這種方法雖然看上去很麻煩,但具有很高的靈活性,可以讓我們
 SQL出現5120錯誤怎麼解決
Mar 06, 2024 pm 04:33 PM
SQL出現5120錯誤怎麼解決
Mar 06, 2024 pm 04:33 PM
解決方法:1、檢查登入使用者是否具有足夠的權限來存取或操作該資料庫,確保該使用者俱有正確的權限;2、檢查SQL Server服務的帳戶是否具有存取指定檔案或資料夾的權限,確保該帳戶具有足夠的權限來讀取和寫入該文件或資料夾;3、檢查指定的資料庫文件是否已被其他進程打開或鎖定,嘗試關閉或釋放該文件,並重新運行查詢;4、嘗試以管理員身份運行Management Studio等等。
 如何使用SQL語句在MySQL中進行資料聚合和統計?
Dec 17, 2023 am 08:41 AM
如何使用SQL語句在MySQL中進行資料聚合和統計?
Dec 17, 2023 am 08:41 AM
如何使用SQL語句在MySQL中進行資料聚合和統計?在進行資料分析和統計時,資料聚合和統計是非常重要的步驟。 MySQL作為一個功能強大的關聯式資料庫管理系統,提供了豐富的聚合和統計函數,可以很方便地進行資料聚合和統計操作。本文將介紹使用SQL語句在MySQL中進行資料聚合和統計的方法,並提供具體的程式碼範例。一、使用COUNT函數進行計數COUNT函數是最常用
