

C++中的Boruvka演算法用於最小生成樹


在圖論中,尋找連通加權圖的最小生成樹(MST)是一個常見的問題。 MST是圖的邊的子集,它連接了所有的頂點並最小化了總邊權。解決這個問題的一個高效率演算法是Boruvka演算法。
文法
struct Edge {
int src, dest, weight;
};
// Define the structure to represent a subset for union-find
struct Subset {
int parent, rank;
};
演算法
現在,讓我們概述Boruvka演算法中涉及的尋找最小生成樹的步驟−
將 MST 初始化為空集。
為每個頂點建立一個子集,其中每個子集只包含一個頂點。
重複以下步驟,直到最小生成樹(MST)有V-1條邊(V是圖中頂點的數量)−
對於每個子集,找到將其連接到另一個子集的最便宜的邊。
將選定的邊加入到最小生成樹。
對所選邊的子集執行並集操作。
輸出最小生成樹。
方法
在Boruvka演算法中,有多種方法可以找到連接每個子集的最便宜的邊。以下是兩種常見的方法−
方法一:樸素方法
對於每個子集,遍歷所有邊,並找到將其連接到另一個子集的最小邊。
追蹤選定的邊並執行聯合操作。
範例
#include <iostream>
#include <vector>
#include <algorithm>
struct Edge {
int src, dest, weight;
};
// Define the structure to represent a subset for union-find
struct Subset {
int parent, rank;
};
// Function to find the subset of an element using path compression
int find(Subset subsets[], int i) {
if (subsets[i].parent != i)
subsets[i].parent = find(subsets, subsets[i].parent);
return subsets[i].parent;
}
// Function to perform union of two subsets using union by rank
void unionSets(Subset subsets[], int x, int y) {
int xroot = find(subsets, x);
int yroot = find(subsets, y);
if (subsets[xroot].rank < subsets[yroot].rank)
subsets[xroot].parent = yroot;
else if (subsets[xroot].rank > subsets[yroot].rank)
subsets[yroot].parent = xroot;
else {
subsets[yroot].parent = xroot;
subsets[xroot].rank++;
}
}
// Function to find the minimum spanning tree using Boruvka's algorithm
void boruvkaMST(std::vector<Edge>& edges, int V) {
std::vector<Edge> selectedEdges; // Stores the edges of the MST
Subset* subsets = new Subset[V];
int* cheapest = new int[V];
// Initialize subsets and cheapest arrays
for (int v = 0; v < V; v++) {
subsets[v].parent = v;
subsets[v].rank = 0;
cheapest[v] = -1;
}
int numTrees = V;
int MSTWeight = 0;
// Keep combining components until all components are in one tree
while (numTrees > 1) {
for (int i = 0; i < edges.size(); i++) {
int set1 = find(subsets, edges[i].src);
int set2 = find(subsets, edges[i].dest);
if (set1 != set2) {
if (cheapest[set1] == -1 || edges[cheapest[set1]].weight > edges[i].weight)
cheapest[set1] = i;
if (cheapest[set2] == -1 || edges[cheapest[set2]].weight > edges[i].weight)
cheapest[set2] = i;
}
}
for (int v = 0; v < V; v++) {
if (cheapest[v] != -1) {
int set1 = find(subsets, edges[cheapest[v]].src);
int set2 = find(subsets, edges[cheapest[v]].dest);
if (set1 != set2) {
selectedEdges.push_back(edges[cheapest[v]]);
MSTWeight += edges[cheapest[v]].weight;
unionSets(subsets, set1, set2);
numTrees--;
}
cheapest[v] = -1;
}
}
}
// Output the MST weight and edges
std::cout << "Minimum Spanning Tree Weight: " << MSTWeight << std::endl;
std::cout << "Selected Edges:" << std::endl;
for (const auto& edge : selectedEdges) {
std::cout << edge.src << " -- " << edge.dest << " \tWeight: " << edge.weight << std::endl;
}
delete[] subsets;
delete[] cheapest;
}
int main() {
// Pre-defined input for testing purposes
int V = 6;
int E = 9;
std::vector<Edge> edges = {
{0, 1, 4},
{0, 2, 3},
{1, 2, 1},
{1, 3, 2},
{1, 4, 3},
{2, 3, 4},
{3, 4, 2},
{4, 5, 1},
{2, 5, 5}
};
boruvkaMST(edges, V);
return 0;
}
輸出
Minimum Spanning Tree Weight: 9 Selected Edges: 0 -- 2 Weight: 3 1 -- 2 Weight: 1 1 -- 3 Weight: 2 4 -- 5 Weight: 1 3 -- 4 Weight: 2
Explanation
的中文翻譯為:解釋
我們先定義兩個結構 - Edge 和 Subset。 Edge 表示圖中的一邊,包含邊的來源、目的地和權重。 Subset表示並檢查資料結構的子集,包含父級和排名資訊。
find函數是一個輔助函數,它使用路徑壓縮來尋找元素的子集。它遞歸地查找元素所屬的子集的代表(父節點),並壓縮路徑以優化未來的查詢。
unionSets函數是另一個輔助函數,使用按秩合併的方式對兩個子集進行合併。它找到兩個子集的代表,並根據秩進行合併,以保持平衡樹。
boruvkaMST 函數採用邊向量和頂點數 (V) 作為輸入。它實作了 Boruvka 演算法來查找 MST。
在 boruvkaMST 函數內,我們建立一個向量 selectedEdges 來儲存 MST 的邊。
我們建立一個Subset結構的陣列來表示子集,並用預設值初始化它們。
我們也建立了一個陣列 cheapest 來追蹤每個子集的最便宜的邊。
變數 numTrees 被初始化為頂點的數量,MSTWeight 被初始化為 0。
該演算法透過重複組合組件來進行,直到所有組件都在一棵樹中。主循環運行直到 numTrees 變為 1。
在主循環的每次迭代中,我們迭代所有邊並找到每個子集的最小加權邊。如果邊連接兩個不同的子集,我們用最小加權邊的索引來更新最便宜的陣列。
接下來,我們遍歷所有的子集,如果一個子集存在最小權重的邊,我們將其添加到selectedEdges向量中,更新MSTWeight,執行子集的並集操作,並減少numTrees的值。
最後,我們輸出 MST 權重和選定的邊。
主要功能提示使用者輸入頂點數和邊數。然後,它會取得每條邊的輸入(來源、目標、權重)並使用輸入呼叫 boruvkaMST 函數。
方法二:使用優先隊列
建立一個依照權重排序的優先權佇列來儲存邊。
對於每個子集,從優先權佇列中找到將其連接到另一個子集的最小權重邊。
追蹤選定的邊並執行聯合操作。
範例
#include <iostream>
#include <vector>
#include <queue>
#include <climits>
using namespace std;
// Edge structure representing a weighted edge in the graph
struct Edge {
int destination;
int weight;
Edge(int dest, int w) : destination(dest), weight(w) {}
};
// Function to find the shortest path using Dijkstra's algorithm
vector<int> dijkstra(const vector<vector<Edge>>& graph, int source) {
int numVertices = graph.size();
vector<int> dist(numVertices, INT_MAX);
vector<bool> visited(numVertices, false);
dist[source] = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
pq.push(make_pair(0, source));
while (!pq.empty()) {
int u = pq.top().second;
pq.pop();
if (visited[u]) {
continue;
}
visited[u] = true;
for (const Edge& edge : graph[u]) {
int v = edge.destination;
int weight = edge.weight;
if (dist[u] + weight < dist[v]) {
dist[v] = dist[u] + weight;
pq.push(make_pair(dist[v], v));
}
}
}
return dist;
}
int main() {
int numVertices = 4;
vector<vector<Edge>> graph(numVertices);
// Adding edges to the graph
graph[0].push_back(Edge(1, 2));
graph[0].push_back(Edge(2, 5));
graph[1].push_back(Edge(2, 1));
graph[1].push_back(Edge(3, 7));
graph[2].push_back(Edge(3, 3));
int source = 0;
vector<int> shortestDistances = dijkstra(graph, source);
cout << "Shortest distances from source vertex " << source << ":\n";
for (int i = 0; i < numVertices; i++) {
cout << "Vertex " << i << ": " << shortestDistances[i] << endl;
}
return 0;
}
輸出
Shortest distances from source vertex 0: Vertex 0: 0 Vertex 1: 2 Vertex 2: 3 Vertex 3: 6
Explanation
的中文翻譯為:解釋
在這個方法中,我們使用優先權佇列來最佳化尋找每個子集的最小加權邊的過程。下面是程式碼的詳細解釋 −
程式碼結構和輔助函數(如find和unionSets)與先前的方法保持相同。
boruvkaMST 函數被修改為使用優先權佇列來有效地找到每個子集的最小加權邊。
而不是使用最便宜的數組,我們現在創建一個邊的優先隊列(pq)。我們用圖的邊來初始化它。
主循環運行直到 numTrees 變成 1,與先前的方法類似。
在每次迭代中,我們從優先隊列中提取最小權重的邊(minEdge)。
然後我們使用find函數找到minEdge的來源和目標所屬的子集。
如果子集不同,我們將minEdge加入到selectedEdges向量中,更新MSTWeight,執行子集的合併,並減少numTrees。
這個過程將繼續,直到所有組件都在一棵樹中。
最後,我們輸出 MST 權重和選定的邊。
主要功能與先前的方法相同,我們有預先定義的輸入用於測試目的。
結論
Boruvka 演算法為尋找加權圖的最小生成樹提供了一個有效的解決方案。在用 C 實作演算法時,我們的團隊深入探索了兩種不同的路徑:一種是傳統的或「樸素」的方法。另一個利用優先權隊列。取決於當前給定問題的具體要求。每種方法都有一定的優點,可以相應地實施。透過理解和實作 Boruvka 演算法,您可以有效地解決 C 專案中的最小生成樹問題。
以上是C++中的Boruvka演算法用於最小生成樹的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



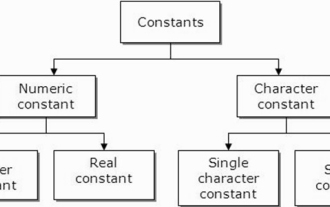 C語言中的常數是什麼,可以舉例嗎?
Aug 28, 2023 pm 10:45 PM
C語言中的常數是什麼,可以舉例嗎?
Aug 28, 2023 pm 10:45 PM
常量也稱為變量,一旦定義,其值在程式執行期間就不會改變。因此,我們可以將變數宣告為引用固定值的常數。它也被稱為文字。必須使用Const關鍵字來定義常數。語法C程式語言中使用的常數語法如下-consttypeVariableName;(or)consttype*VariableName;不同類型的常數在C程式語言中使用的不同類型的常數如下所示:整數常數-例如:1,0,34, 4567浮點數常數-例如:0.0,156.89,23.456八進制和十六進制常數-例如:十六進制:0x2a,0xaa..八進制
 VSCode和VS C++IntelliSense無法運作或拾取函式庫
Feb 29, 2024 pm 01:28 PM
VSCode和VS C++IntelliSense無法運作或拾取函式庫
Feb 29, 2024 pm 01:28 PM
VS程式碼和VisualStudioC++IntelliSense可能無法拾取函式庫,尤其是在處理大型專案時。當我們將滑鼠懸停在#Include<;wx/wx.h>;上時,我們看到了錯誤訊息「CannotOpen來源檔案'string.h'」(依賴於「wx/wx.h」),有時,自動完成功能無法回應。在這篇文章中,我們將看到如果VSCode和VSC++IntelliSense不能工作或不能提取庫,你可以做些什麼。為什麼我的智能感知不能在C++中運作?處理大型檔案時,IntelliSense有時
 如何使用C++中的Prim演算法
Sep 20, 2023 pm 12:31 PM
如何使用C++中的Prim演算法
Sep 20, 2023 pm 12:31 PM
標題:C++中Prim演算法的使用及程式碼範例引言:Prim演算法是一種常用的最小生成樹演算法,主要用於解決圖論中的最小生成樹問題。在C++中,透過合理的資料結構和演算法實現,可以有效地使用Prim演算法。本文將介紹如何在C++中使用Prim演算法,並提供具體的程式碼範例。一、Prim演算法簡介Prim演算法是一種貪心演算法,它從一個頂點開始,逐步擴展最小生成樹的頂點集合,直到套件
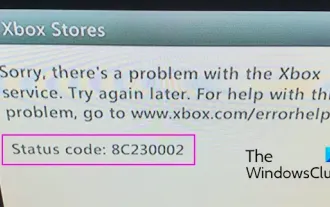 修復Xbox錯誤代碼8C230002
Feb 27, 2024 pm 03:55 PM
修復Xbox錯誤代碼8C230002
Feb 27, 2024 pm 03:55 PM
您是否因為錯誤代碼8C230002而無法在Xbox上購買或觀看內容?一些用戶在嘗試購買或在其控制台上觀看內容時不斷收到此錯誤。抱歉,Xbox服務出現問題。稍後再試。有關此問題的協助,請造訪www.xbox.com/errorhelp。狀態代碼:8C230002這種錯誤代碼通常是由於暫時的伺服器或網路問題引起的。但是,還有可能是由於帳戶的隱私設定或家長控制等其他原因,這些可能會阻止您購買或觀看特定內容。修正Xbox錯誤代碼8C230002如果您嘗試在Xbox控制台上觀看或購買內容時收到錯誤代碼8C
 遞歸程式在C++中找到陣列的最小和最大元素
Aug 31, 2023 pm 07:37 PM
遞歸程式在C++中找到陣列的最小和最大元素
Aug 31, 2023 pm 07:37 PM
我們以整數數組Arr[]作為輸入。目標是使用遞歸方法在陣列中找到最大和最小的元素。由於我們使用遞歸,我們將遍歷整個數組,直到達到長度=1,然後返回A[0],這形成了基本情況。否則,將當前元素與當前最小或最大值進行比較,並透過遞歸更新其值以供後續元素使用。讓我們來看看這個的各種輸入輸出場景−輸入 −Arr={12,67,99,76,32};輸出 −數組中的最大值:99解釋 &mi
 中國東方航空宣布C919客機即將投入實際運營
May 28, 2023 pm 11:43 PM
中國東方航空宣布C919客機即將投入實際運營
May 28, 2023 pm 11:43 PM
5月25日消息,中國東方航空在業績說明會上揭露了關於C919客機的最新進展。據公司表示,與中國商飛簽署的C919採購協議已於2021年3月正式生效,其中首架C919飛機已於2022年底交付。預計不久之後,該飛機將正式投入實際運作。東方航空將以上海為主要基地進行C919的商業運營,並計劃在2022年和2023年引進總共5架C919客機。該公司表示,未來的引進計畫將根據實際營運狀況和航線網路規劃來決定。據小編了解,C919是中國具有完全自主智慧財產權的全球新一代單通道幹線客機,符合國際通行的適航標準。該
 C++程式列印數字的螺旋圖案
Sep 05, 2023 pm 06:25 PM
C++程式列印數字的螺旋圖案
Sep 05, 2023 pm 06:25 PM
以不同格式顯示數字是學習基本編碼問題之一。不同的編碼概念,如條件語句和迴圈語句。有不同的程式中,我們使用特殊字元(如星號)來列印三角形或正方形。在本文中,我們將以螺旋形式列印數字,就像C++中的正方形一樣。我們將行數n作為輸入,然後從左上角開始移向右側,然後向下,然後向左,然後向上,然後再次向右,以此類推等等。螺旋圖案與數字123456724252627282982340414243309223948494431102138474645321120373635343312191817161514
 C語言中的void關鍵字的作用
Feb 19, 2024 pm 11:33 PM
C語言中的void關鍵字的作用
Feb 19, 2024 pm 11:33 PM
C中的void是一個特殊的關鍵字,用來表示空類型,也就是指沒有具體類型的資料。在C語言中,void通常用於以下三個方面。函數傳回類型為void在C語言中,函數可以有不同的回傳類型,例如int、float、char等。然而,如果函數不傳回任何值,則可以將傳回類型設為void。這意味著函數執行完畢後,並不傳回具體的數值。例如:voidhelloWorld()
