隨著遠距醫療的興起,患者越來越傾向於選擇在線問診和諮詢,以尋求便捷高效的醫療支持。最近,大型語言模型(LLM)展現了強大的自然語言互動能力,為健康醫療助理走進人們的生活帶來了希望
醫療健康諮詢場景通常較為複雜,個人助理需要有豐富的醫學知識,具備透過多個輪次對話了解病人意圖,並給予專業、詳盡回覆的能力。通用語言模式在面對醫療健康諮詢時,往往因為缺乏醫療知識,出現避而不談或答非所問的情況;同時,傾向於針對當前輪次問題完成諮詢,缺少令人滿意的多輪追問能力。除此之外,目前高品質的中文醫學資料集也十分難得,這為訓練強大的醫療領域語言模型構成了挑戰。 復旦大學資料智慧與社會運算實驗室(FudanDISC)發表中文醫療健康個人助理 ——DISC-MedLLM。在單輪問答和多輪對話的醫療健康諮詢評測中,模型的表現相比現有醫學對話大模型展現出明顯優勢。主題組同時公開了包含 47 萬高品質的監督微調(SFT)資料集 ——DISC-Med-SFT,模型參數和技術報告也一併開源。
- 主頁網址:https://med.fudan-disc.com
- Github 網址: https://github.com/FudanDISC/DISC-MedLLM
- 技術報告:https://arxiv.org/abs/2308.14346

圖1 :對話範例
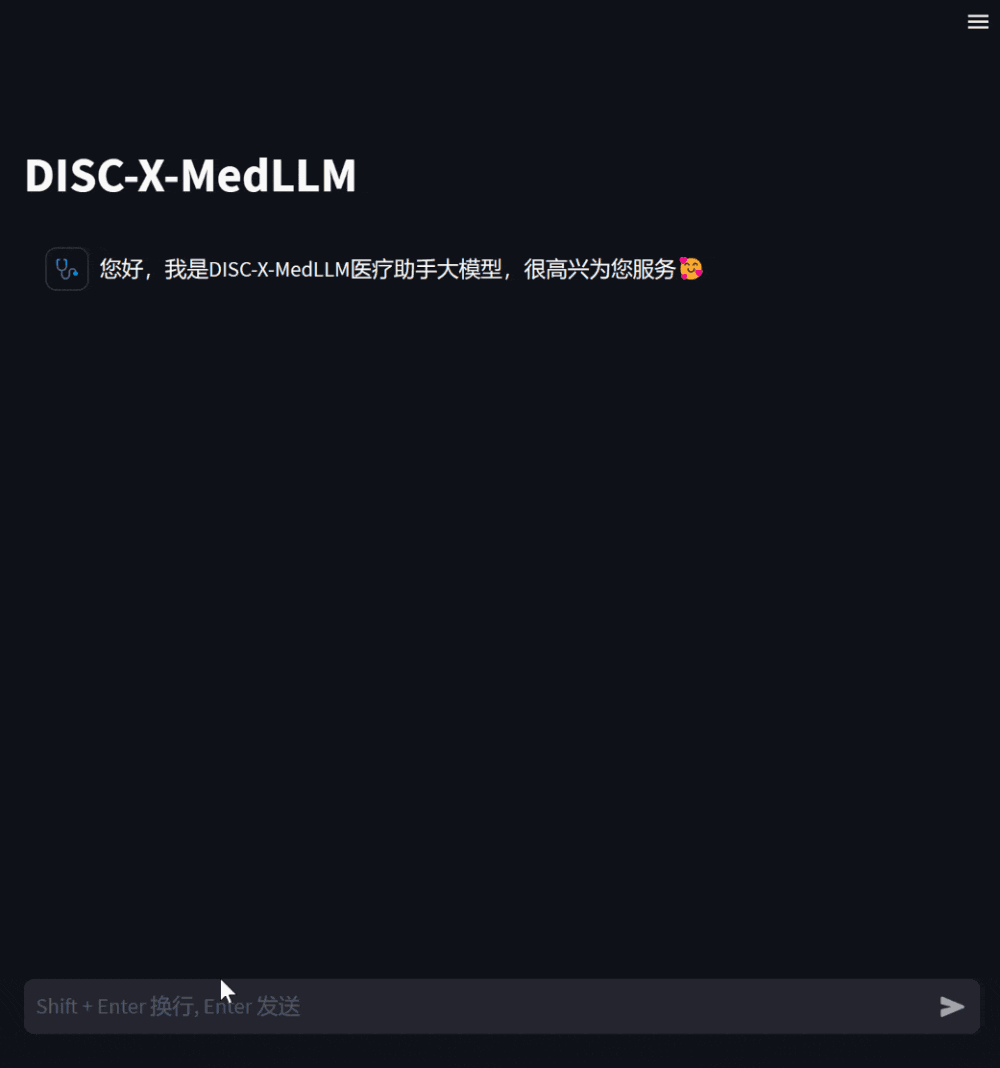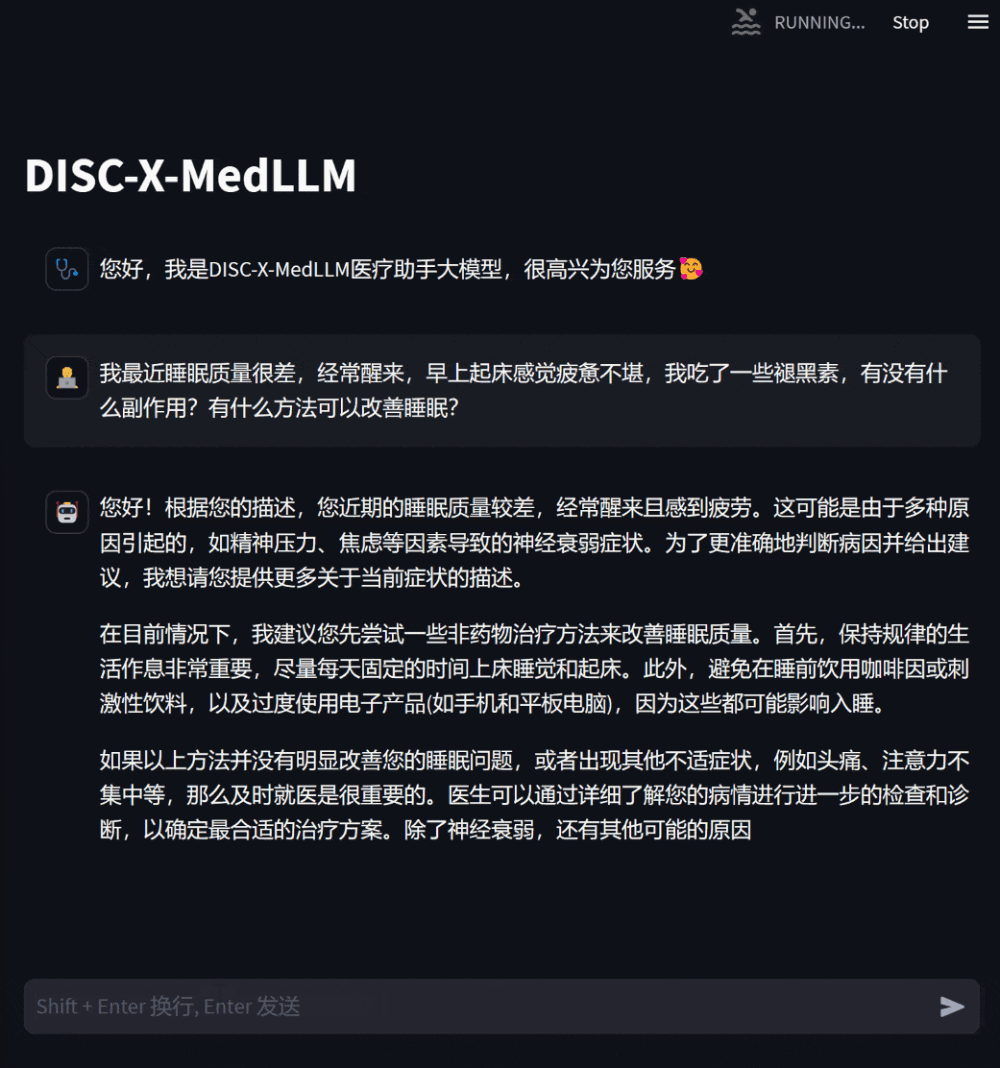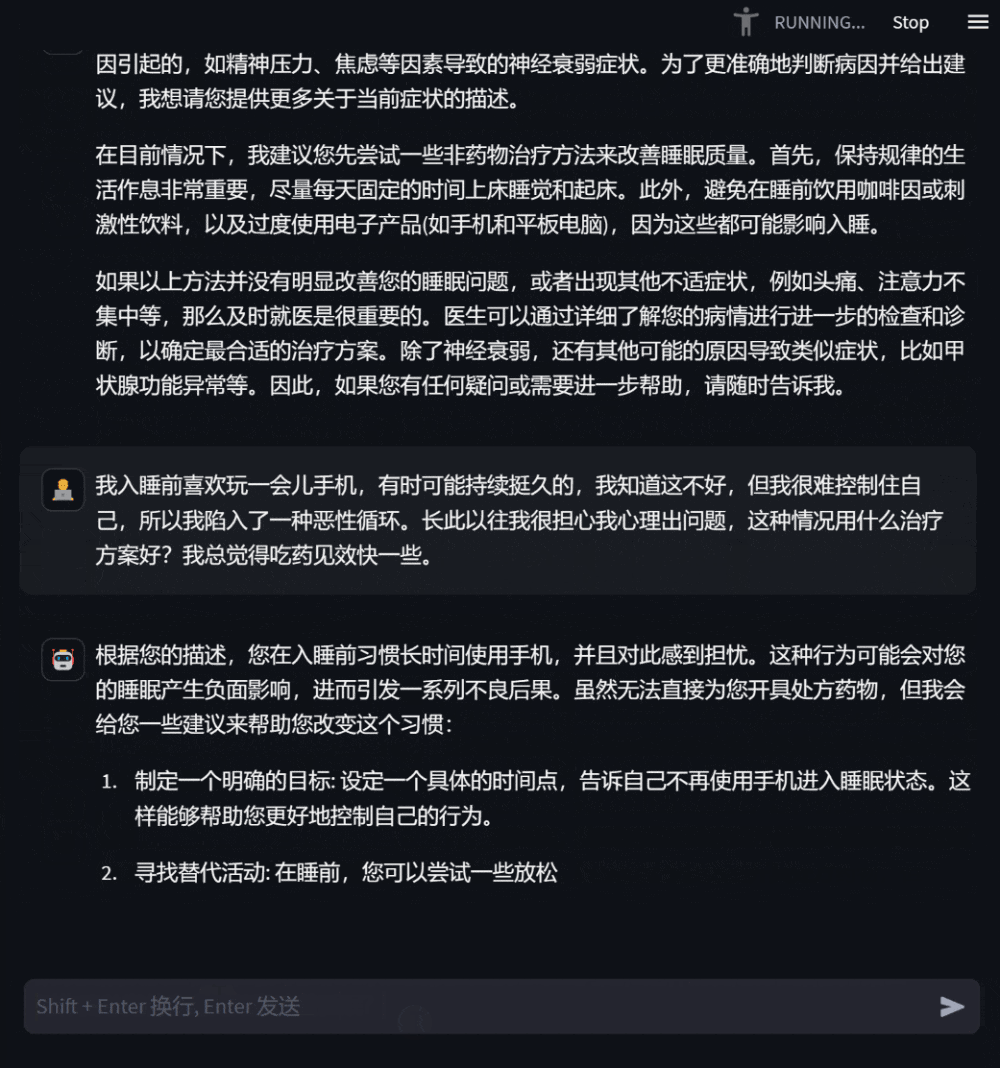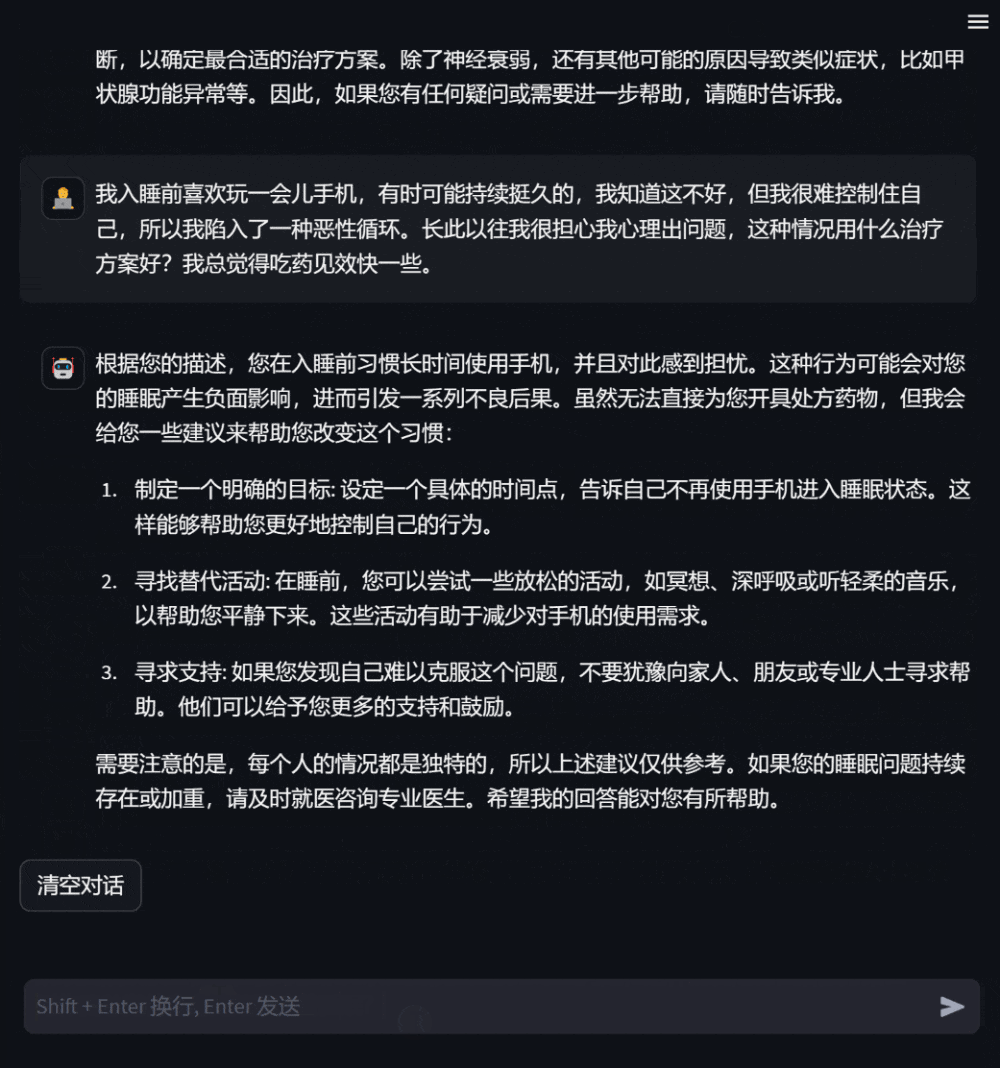
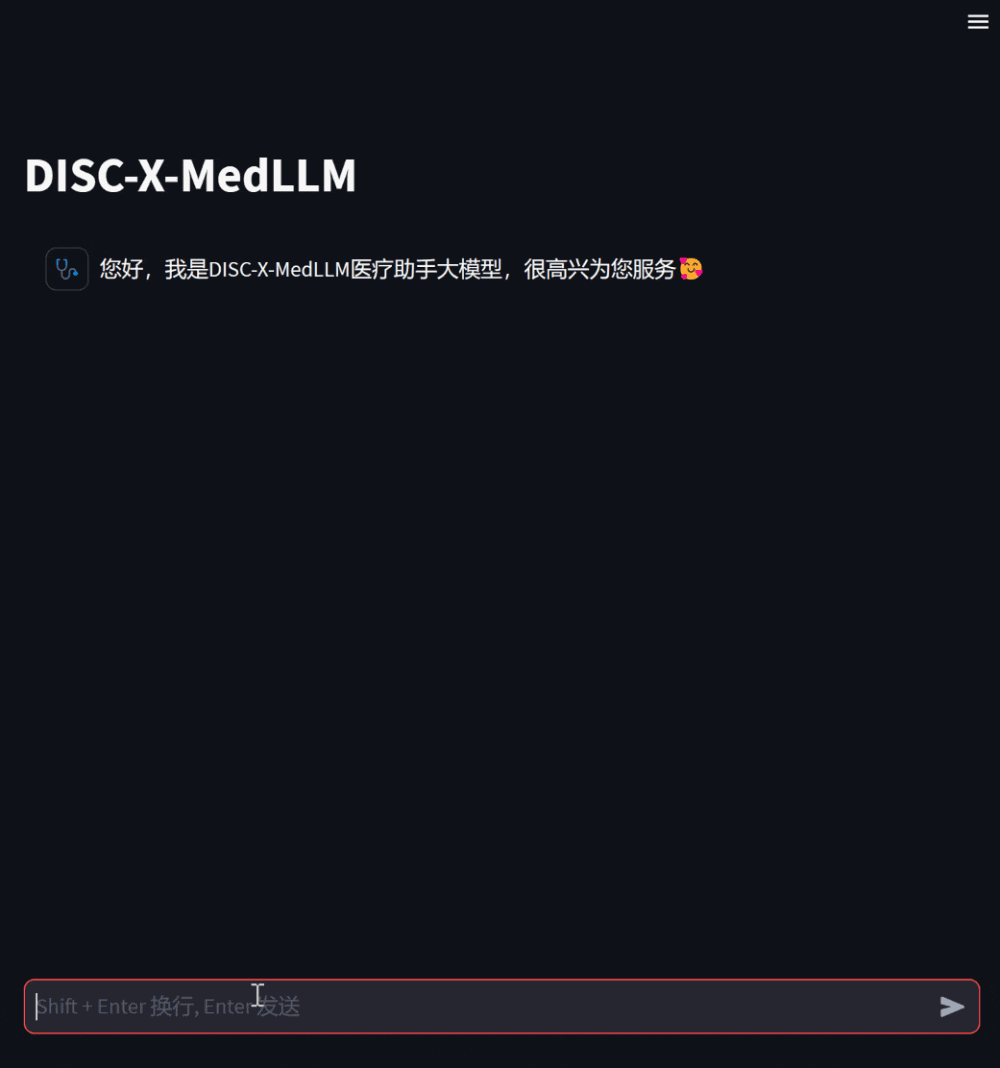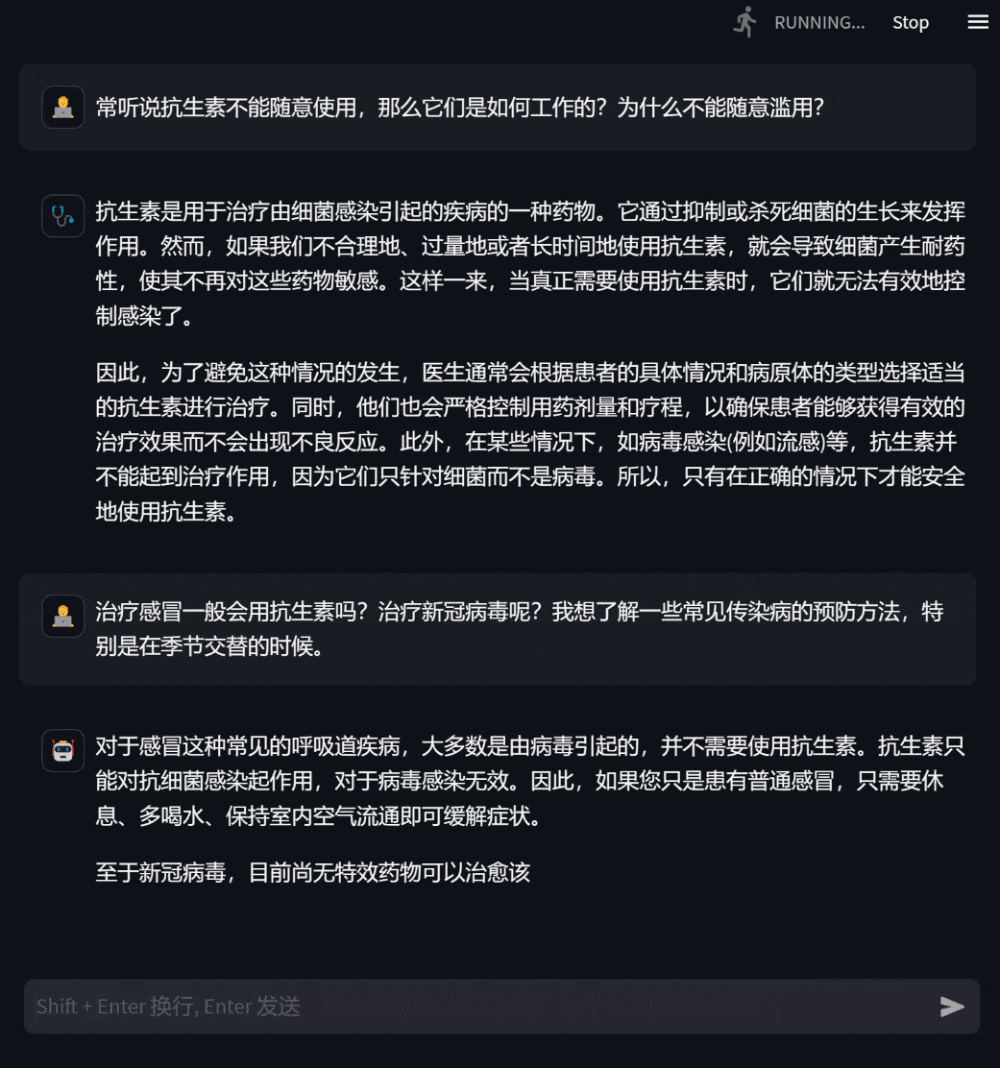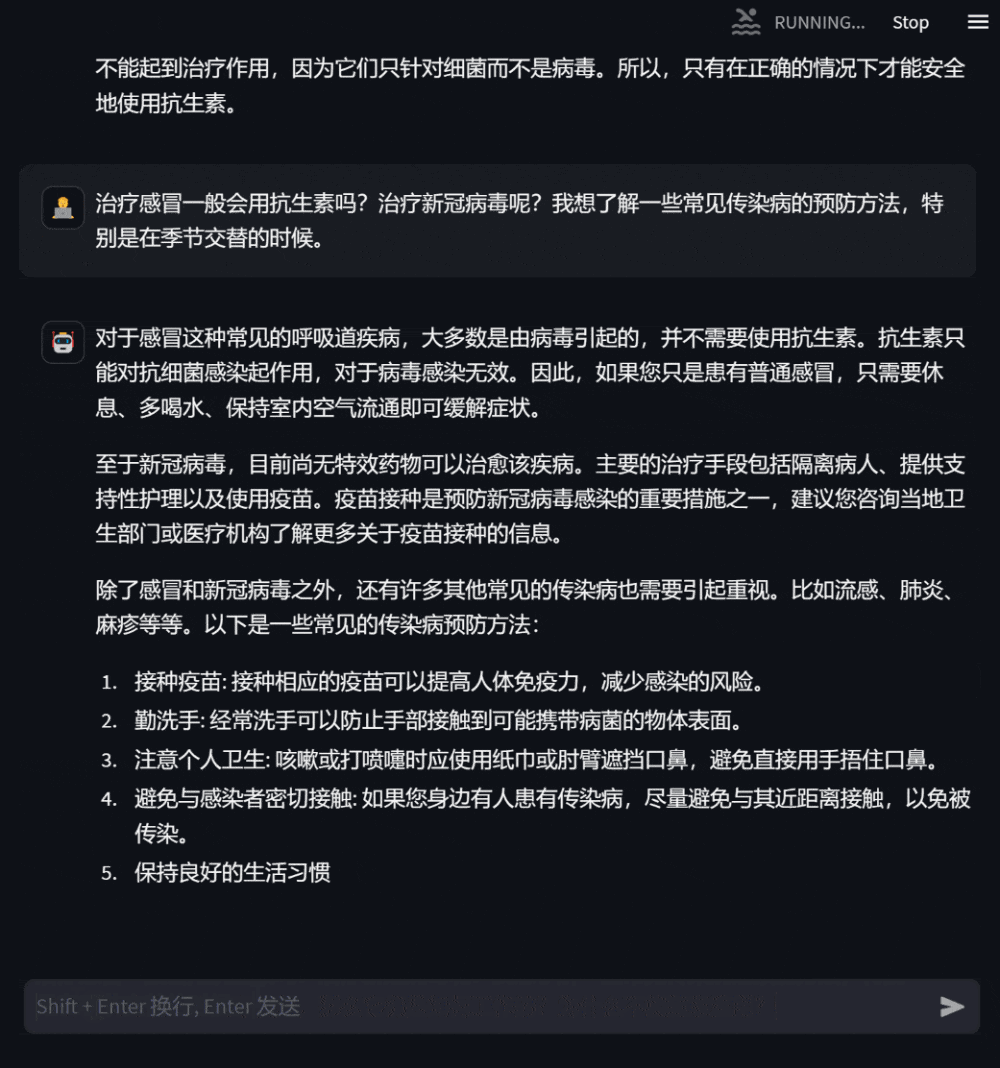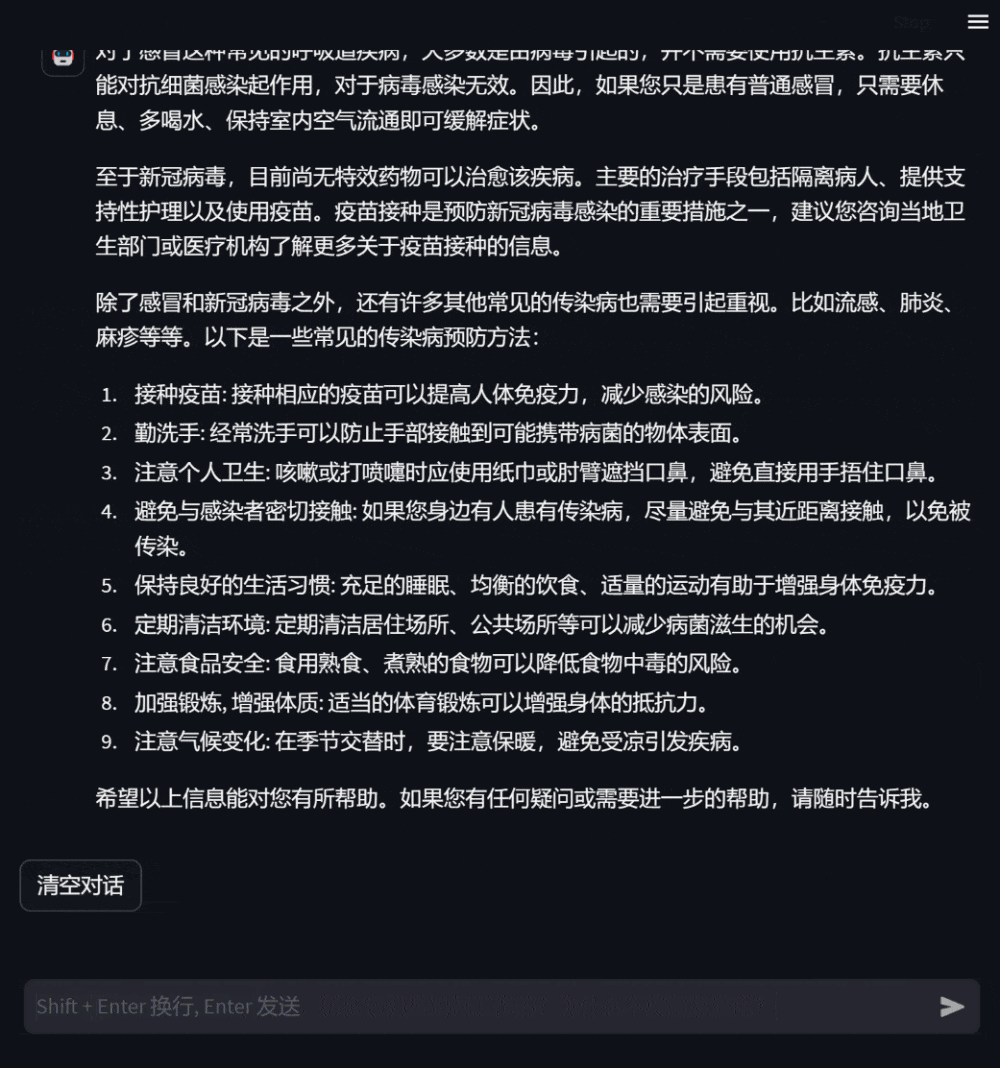
當患者感到身體不適時,可以向模型問診,描述自身症狀,模型會給予可能的原因、建議的治療方案等作為參考,在資訊缺乏時會主動追問症狀的詳細描述。
圖2:問診場景下的對話
######## ####使用者還可以基於自身健康狀況,向模型提出需求明確的諮詢問題,模型會給予詳盡有助的答复,並在信息缺乏時主動追問,以增強回复的針對性和準確性。 ###########################圖3:基於自身健康狀況諮詢的對話############# #####使用者也可以詢問與自身無關的醫學知識,此時模型會盡可能專業地作答,使用戶全面準確地理解。 #####################
DISC-MedLLM 是基於我們建構的高品質資料集DISC-Med-SFT 在通用領域中文大模型Baichuan-13B 上訓練得到的醫療大模型。值得注意的是,我們的訓練資料和訓練方法可以被適配到任何基座大模型之上。
- 可靠又豐富的專業知識。我們以醫學知識圖譜作為資訊來源,透過取樣三元組,並使用通用大模型的語言能力進行對話樣本的建構。
- 多輪對話的問詢能力。我們以真實諮詢對話紀錄作為資訊來源,使用大模型進行對話重建,建構過程中要求模型完全對齊對話中的醫學資訊。
- 對齊人類偏好的回應。病人希望在諮詢的過程中獲得更豐富的支撐資訊和背景知識,但人類醫生的回答往往簡練;我們透過人工篩選,建構高品質的小規模指令樣本,對齊病人的需求。
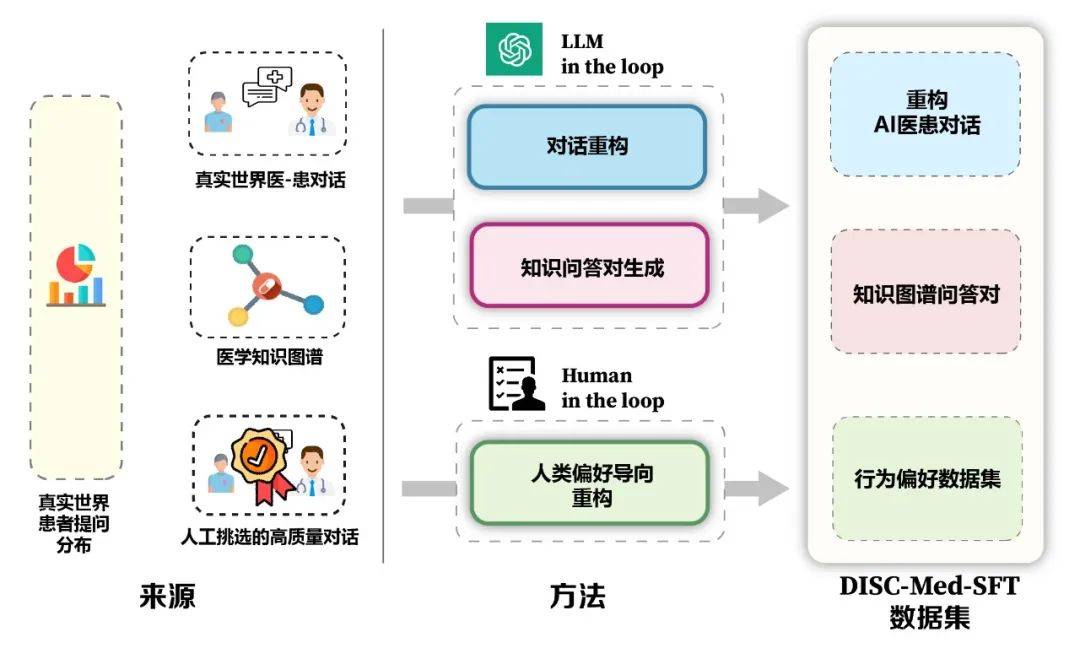
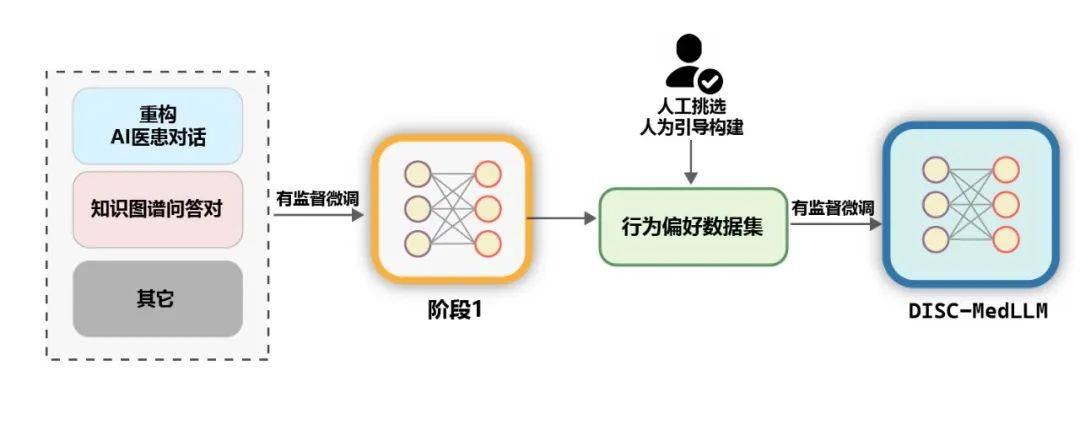
模型的優勢與資料建構架構如圖 5 所示。我們從真實諮詢場景中計算得到病人的真實分佈,以此指導數據集的樣本構造,基於醫學知識圖譜和真實諮詢數據,我們使用大模型在迴路和人在迴路兩種思路,進行數據集的構造。
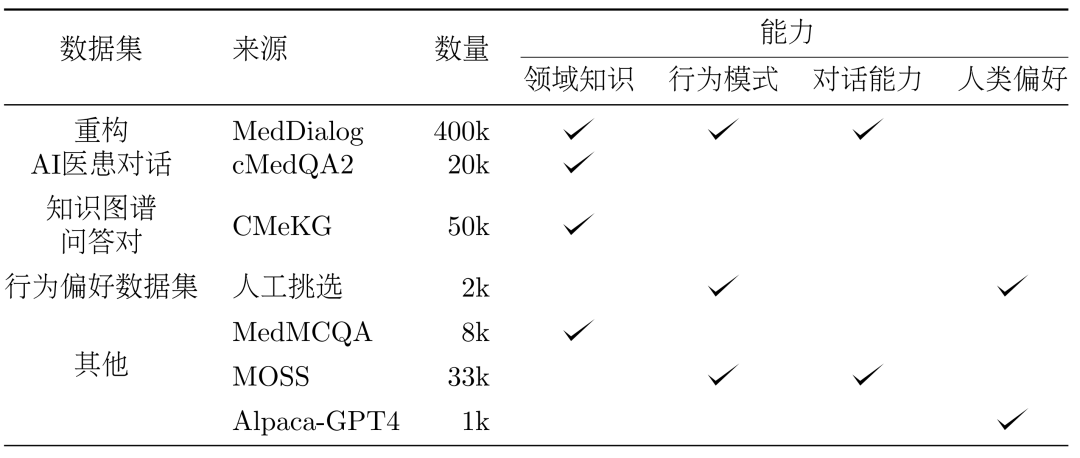
##3、方法:資料集DISC-Med-SFT 的建構#在模型訓練的過程中,我們向DISC- Med-SFT 補充了通用領域的資料集和來自現有語料的資料樣本,形成了DISC-Med-SFT-ext,詳細資料呈現在表1 中。
表1:DISC-Med-SFT-ext 資料內容介紹#資料集。分別從兩個公共資料集 MedDialog 和 cMedQA2 中隨機選擇 40 萬個和 2 萬個樣本,作為 SFT 資料集建構的來源樣本。
重構。為了將真實世界醫生回答調整為所需的高品質的統一格式的回答,我們利用 GPT-3.5 來完成這個資料集的重構過程。提示詞(Prompts)要求改寫遵循以下幾個原則:
- #去除口頭表達,提取統一表達方式,糾正醫生語言使用中的不一致之處。
- 堅持原始醫生回答中的關鍵訊息,並提供適當的解釋以更加全面、合乎邏輯。
- 重寫或刪除 AI 醫生不應該發出的回复,例如要求患者預約。
圖 6 展示了一個重構的範例。調整後醫生的回答與 AI 醫療助理的身份一致,既堅持原始醫生提供的關鍵信息,又為患者提供更豐富全面的幫助。
#醫學知識圖譜包含大量經過良好組織的醫學專業知識,基於它可以產生雜訊較低的QA 訓練樣本。我們在 CMeKG 的基礎上,根據疾病節點的科室資訊在知識圖譜中進行採樣,利用適當設計的 GPT-3.5 模型 Prompts,總共產生了超過 5 萬個多樣化的醫學場景對話樣本。 #在訓練的最終階段,為了進一步提升模型的效能,我們使用更符合人類行為偏好資料集進行次級監督微調。從MedDialog 和cMedQA2 兩個資料集中人工挑選了約2000 個高品質、多樣化的樣本,在交給GPT-4 改寫幾個範例並人工修訂後,我們使用小樣本的方法將其提供給GPT-3.5 ,產生高品質的行為偏好資料集。 #通用資料。為了豐富訓練集的多樣性,減輕模型在 SFT 訓練階段出現基礎能力降級的風險,我們從兩個通用的監督微調資料集 moss-sft-003 和 alpaca gpt4 data zh 隨機選擇了若干樣本。 MedMCQA。為增強模型的問答能力,我們選擇英文醫學領域的多項選擇題資料集MedMCQA,使用GPT-3.5 對多項選擇題中的問題和正確答案進行了優化,生成專業的中文醫學問答樣本約8000 個。 訓練。如下圖所示,DISC-MedLLM 的訓練過程分為兩個 SFT 階段。
#評測。在兩個場景中評測醫學 LLMs 的性能,即單輪 QA 和多輪對話。
- 單輪QA 評估:為了評估模型在醫學知識方面的準確性,我們從中國國家醫療執業醫師資格考試(NMLEC)和全國碩士研究生入學考試(NEEP)西醫306 專業抽取了1500 個單選題,評測模式在單輪QA 的表現。
- 多輪對話評測:為了系統性評估模型的對話能力,我們從三個公共資料集— 中文醫療基準評測(CMB-Clin)、中文醫療對話資料集(CMD)和中文醫療意圖資料集(CMID)中隨機選擇樣本並由GPT-3.5 扮演患者與模型對話,提出了四個評測指標—— 主動性、準確性、有用性和語言質量,由GPT- 4 打分。
比較模型。將我們的模型與三個通用 LLM 和兩個中文醫學對話 LLM 進行比較。包括 OpenAI 的 GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 和 HuatuoGPT-13B。
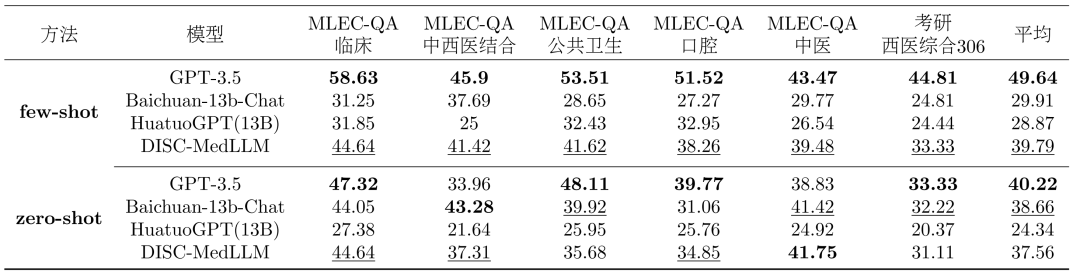
單輪 QA 結果。單項選擇題評測的整體結果顯示在表 2 中。 GPT-3.5 展現出明顯的領先優勢。 DISC-MedLLM 在小樣本設定下取得第二名,在零樣本設定中落後於 Baichuan-13B-Chat,排名第三。值得注意的是,我們的表現優於採用強化學習設定訓練的 HuatuoGPT (13B)。
表2:單項選擇題評測結果
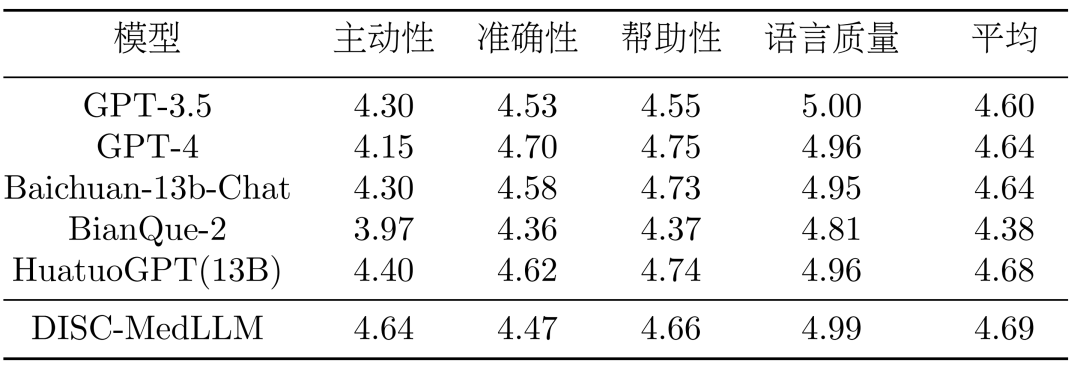
######### ###多輪對話結果。在 CMB-Clin 評估中,DISC-MedLLM 獲得了最高的綜合得分,HuatuoGPT 緊隨其後。我們的模型在積極性標準中得分最高,凸顯了我們偏向醫學行為模式的訓練方法的有效性。結果如表 3 所示。 #####################
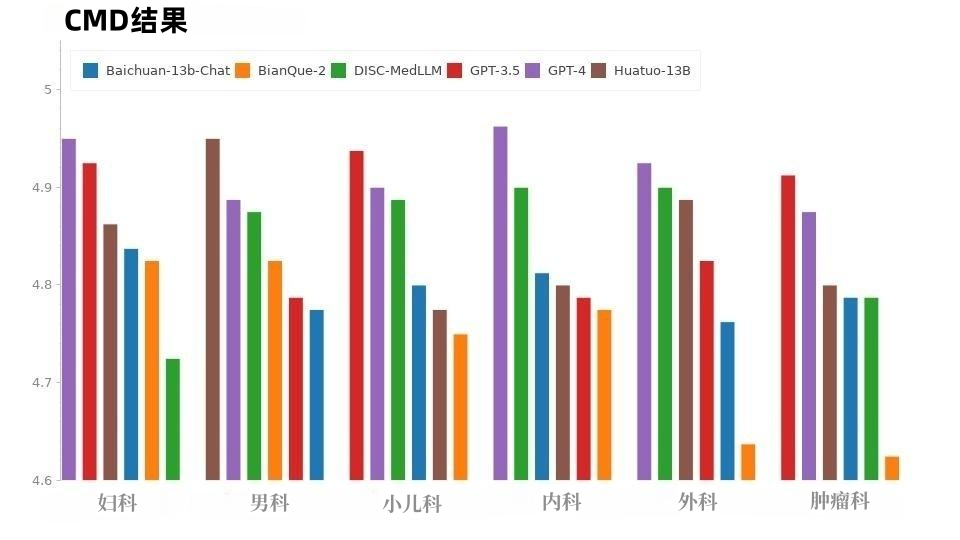
#在CMD 樣本中,如圖8 所示,GPT-4 獲得了最高分,其次是GPT-3.5。醫學領域的模式 DISC-MedLLM 和 HuatuoGPT 的整體表現分數相同,在不同科室中表現各有優異之處。
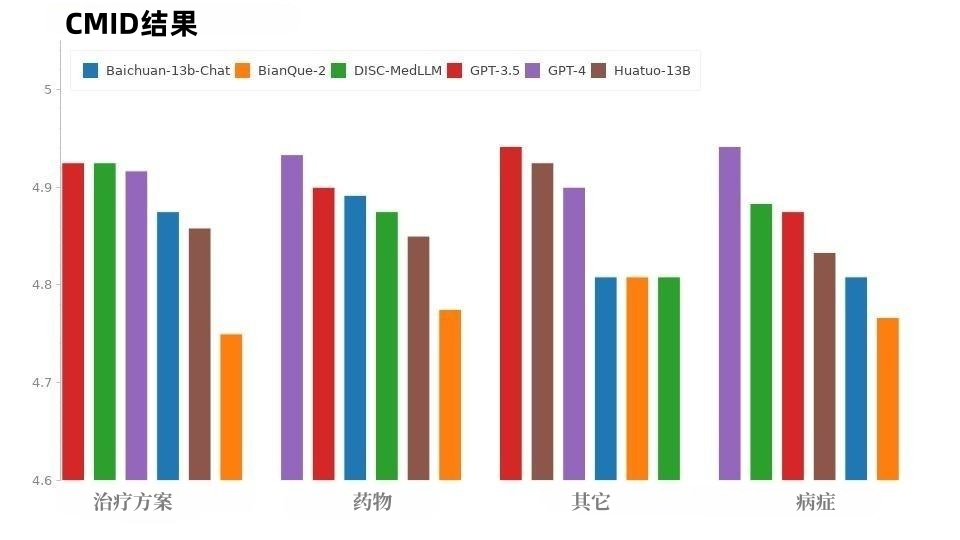
CMID 的情況與CMD 類似,如圖9 所示,GPT-4 和GPT-3.5 保持領先。除 GPT 系列外,DISC-MedLLM 表現最佳。在病症、治療方案和藥物等三個意圖中,它的表現優於 HuatuoGPT。
各模型在CMB-Clin 和CMD/CMID 之間表現不一致的情況可能是由於這三個資料集之間的資料分佈不同所造成的。 CMD 和 CMID 包含更多明確的問題樣本,患者在描述症狀時可能已經獲得了診斷並表達明確的需求,甚至患者的疑問和需求可能與個人健康狀況無關。在多個方面表現出色的通用型模型 GPT-3.5 和 GPT-4 更擅長處理這種情況。 #DISC-Med-SFT 資料集利用現實世界對話和通用領域LLM 的優勢和能力,對三個方面進行了針對性強化:領域知識、醫學對話技能和與人類偏好;高質量的數據集訓練了出色的醫療大模型DISC-MedLLM,在醫學交互方面取得了顯著的改進,表現出很高的可用性,顯示出巨大的應用潛力。 該領域的研究將為降低線上醫療成本、推廣醫療資源以及實現平衡帶來更多前景和可能性。 DISC-MedLLM 將為更多人帶來便利且個人化的醫療服務,為大健康事業發揮力量。 以上是復旦大學團隊發布中文醫療健康個人助手,同時開源47萬高品質資料集的詳細內容。更多資訊請關注PHP中文網其他相關文章!




 比較模型。將我們的模型與三個通用 LLM 和兩個中文醫學對話 LLM 進行比較。包括 OpenAI 的 GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 和 HuatuoGPT-13B。
比較模型。將我們的模型與三個通用 LLM 和兩個中文醫學對話 LLM 進行比較。包括 OpenAI 的 GPT-3.5, GPT-4, Baichuan-13B-Chat; BianQue-2 和 HuatuoGPT-13B。