
Code Llama一出,大家都期待有人能繼續進行量化瘦身,幸好它可以在本地運行
果然是llama.cpp作者Georgi Gerganov出手了,但他這回不按套路出牌:
在不進行量化的情況下,即使使用FP16精度,Code LLama的34B程式碼也能在蘋果電腦上運行,並且推理速度超過每秒20個token
 #圖片
#圖片
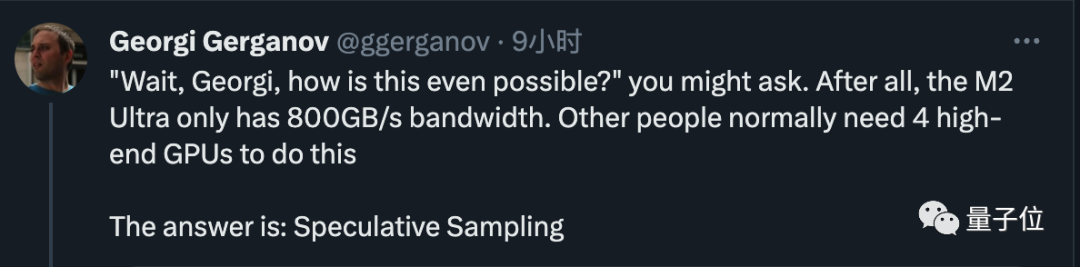
現在只要使用具有800GB/s頻寬的M2 Ultra,就可以完成原本需要4個高階GPU才能完成的任務,而且寫程式碼的速度也非常快
老哥隨後揭示了秘訣,答案非常簡單,就是進行投機採樣(speculative sampling/decoding)
 圖片
圖片
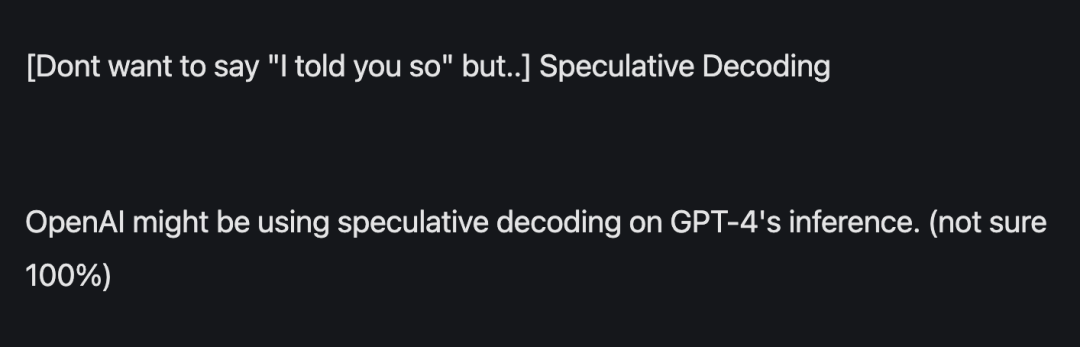
觸發了許多業界大咖的關注
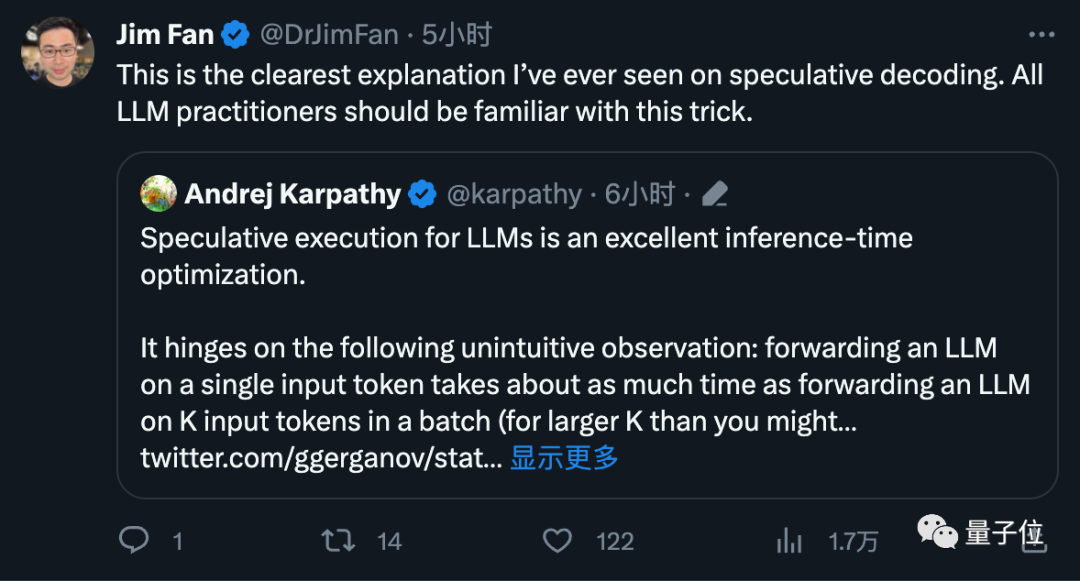
OpenAI創始成員Andrej Karpathy評價這是一種非常出色的推理時優化,並給出了更多技術解讀。
範麟熙,一位英偉達科學家,也認為這是每個從事大模型工作的人都應該熟悉的技巧
 圖片
圖片
 圖片
圖片
 圖片
圖片

方法很簡單,先訓練一個與大模型近似、更便宜的小模型,讓小模型先生成K個token,然後讓大模型去做評判。
大模型可以直接使用已接受的部分,並由大模型修改不接受的部分
在原始的研究中,使用了T5-XXL模型進行演示,並且在保持生成在結果不變的情況下,得到了2-3倍的推理加速
#Andjrey Karpathy把這個方法比喻成「先讓小模型打草稿」。
他解釋了這個方法有效的關鍵之處在於,將大型模型分別輸入一個token和一批token,預測下一個token所需的時間幾乎相同
每個token都依賴前一個token,因此在正常情況下無法同時對多個token進行採樣
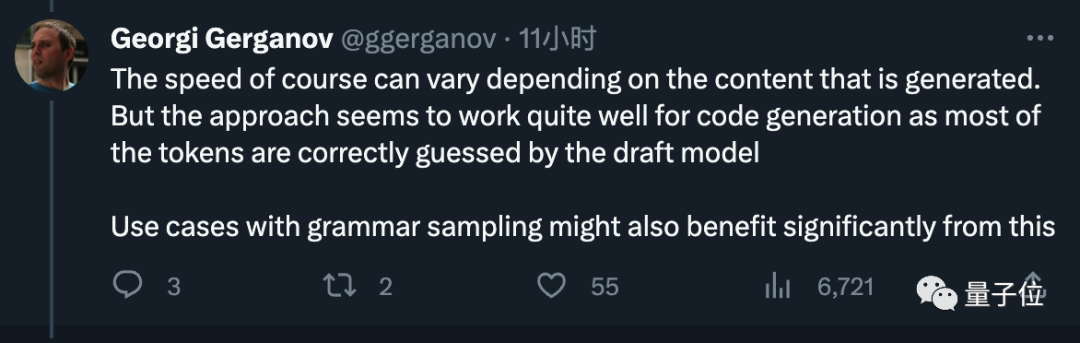
小模型雖然能力較差,但實際生成一個句子時有很多部分是非常簡單的,小模型也能勝任,只有遇到困難的部分再讓大模型上就好了。  原文指出,可以直接加速現有的成熟模型,而無需改變其結構或重新進行訓練
原文指出,可以直接加速現有的成熟模型,而無需改變其結構或重新進行訓練
 圖片
圖片
最後,他也建議Meta以後在發布模型時直接把小的草稿模型附帶上吧,受到大夥好評。
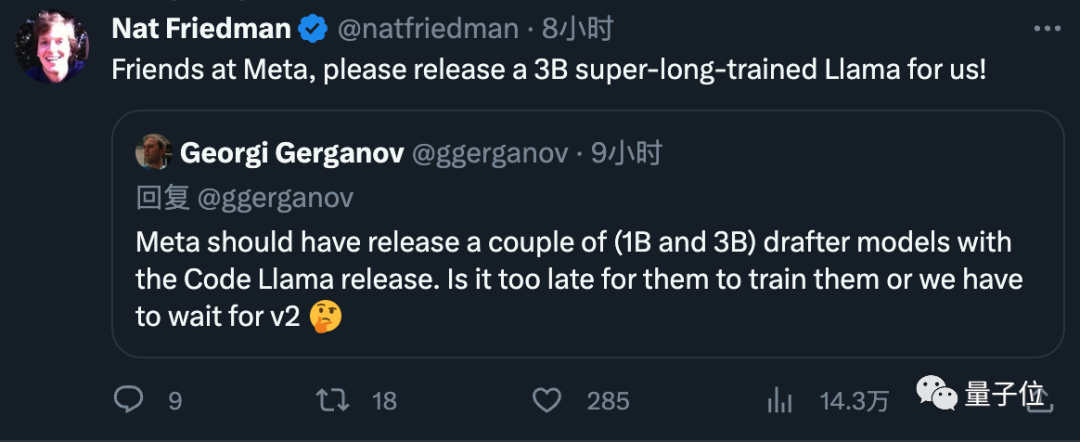 圖片
圖片
Georgi Gerganov是作者,他在今年三月將LlaMA的第一代移植到了C上。他的開源專案llama.cpp已經獲得了接近4萬顆星星
 圖片
圖片
他最初只是把這個當作一個業餘興趣,但由於反應熱烈,他在6月宣布創業
新公司ggml.ai致力於在邊緣設備上運行AI。該公司的主打產品是llama.cpp背後的C語言機器學習框架
 圖片
圖片
在創業初期,我們成功獲得了來自GitHub前首席執行長Nat Friedman和Y Combinator合夥人Daniel Gross的種子前投資
LlaMA2發布後他也很活躍,最狠的一次直接把大模型塞進了瀏覽器裡。
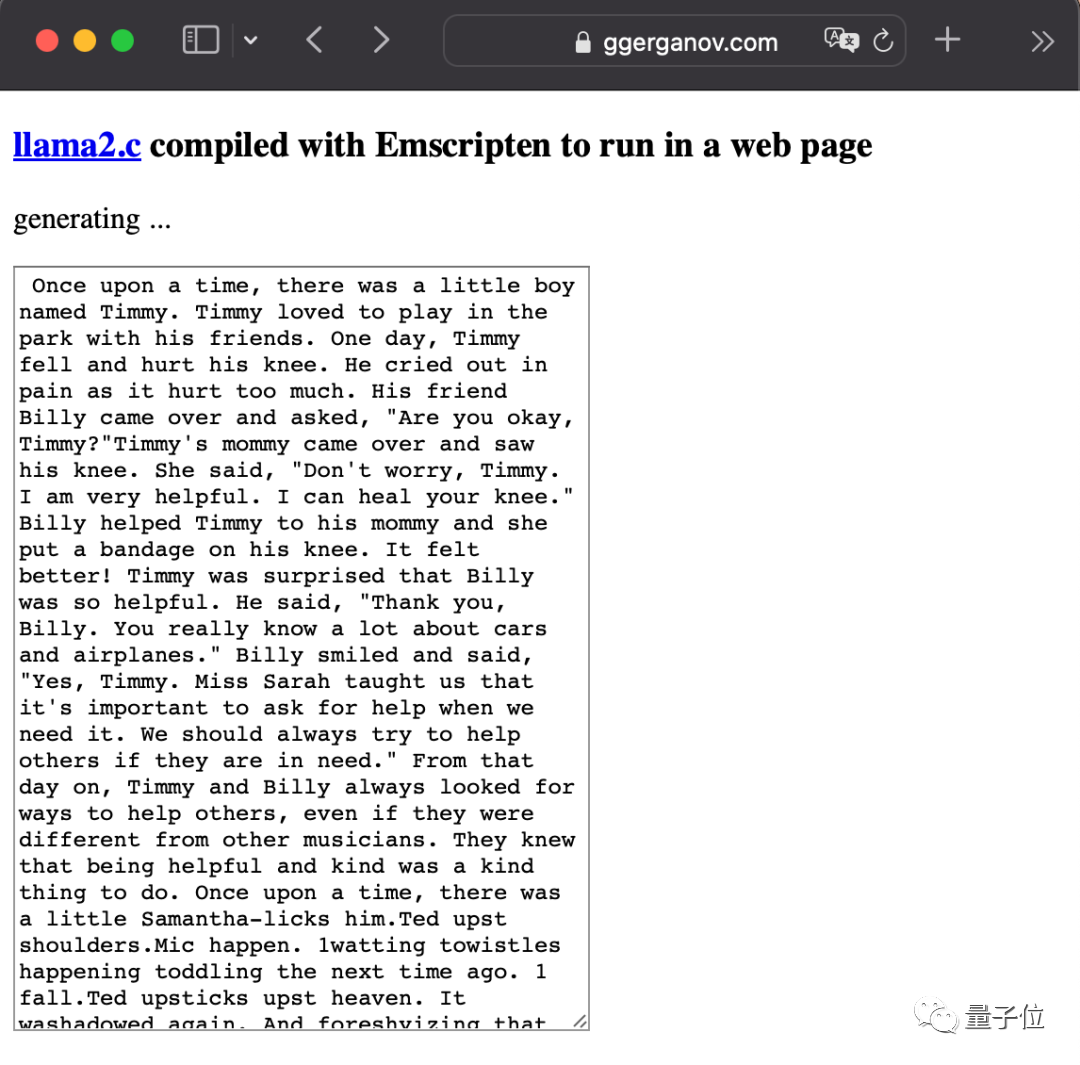 圖片
圖片
請查看Google的投機採樣論文:https://arxiv.org/abs/2211.17192
#參考連結: [1]https://x.com/ggerganov/status/1697262700165013689 [2]https://x.com/karpathy/status/1697318534555336961
以上是蘋果芯跑大模型不用降計算精度,投機採樣殺瘋了,GPT-4也在用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















