

Interspeech 2023 | 火山引擎串流音訊技術之語音增強與AI音訊編碼


背景介紹
為了回應處理各類複雜音視訊通訊場景,如多設備、多人、多噪音場景,串流通訊技術漸漸成為人們生活中不可或缺的技術。為達到更好的主觀體驗,使用戶聽得清、聽得真,串流音頻技術方案融合了傳統機器學習和基於AI的語音增強方案,利用深度神經網路技術方案,在語音降噪、迴聲消除、幹擾人聲消除和音訊編解碼等方向,為即時通訊中的音訊品質保駕護航。
作為語音訊號處理研究領域的旗艦國際會議,Interspeech一直代表著聲學領域技術最前沿的研究方向,Interspeech 2023 收錄了多篇和音訊訊號語音增強演算法相關的文章,其中,火山引擎串流音訊團隊共有4 篇研究論文被大會接收,論文方向包括語音增強、基於AI編解碼 、迴聲消除、無監督自適應語音增強。
值得一提的是,在無監督自適應語音增強領域,位元組跳動與西工大聯合團隊在今年的CHiME (Computational Hearing in Multisource Environments) 挑戰賽子任務無監督域自適應對話語音增強(Unsupervised domain adaptation for conversational speech enhancement, UDASE) 贏得了冠軍(https://www.chimechallenge.org/current/task2/results)。 CHiME挑戰賽是由法國電腦科學與自動化研究所、英國雪菲爾大學、美國三菱電子研究實驗室等知名研究機構所於2011年發起的一項重要國際賽事,聚焦於語音研究領域極具挑戰的遠場語音處理相關任務,今年已舉辦到第七屆。歷屆CHiME比賽的參賽隊伍包括英國劍橋大學、美國卡內基美隆大學、約翰霍普金斯大學、日本NTT、日立中央研究院等國際知名大學和研究機構,以及清華大學、中國科學院大學、中科院聲學所、西工大、科大訊飛等國內頂尖院校及研究所。
本文將介紹這4 篇論文解決的核心場景問題和技術方案,分享火山引擎串流音訊團隊在語音增強,基於AI編碼器,迴聲消除和無監督自適應語音增強領域的思考與實踐。
基於可學習梳狀濾波器的輕量級語音諧波增強方法
論文網址:https://www.isca-speech.org/archive/interspeech_2023/ le23_interspeech.html
背景
受限於延遲和運算資源,即時音視訊通訊場景下的語音增強,通常使用基於濾波器組的輸入特徵。透過梅爾和ERB等濾波器組,原始頻譜被壓縮至維度較低的子帶域。在子帶域上,基於深度學習的語音增強模型的輸出是子帶的語音增益,該增益代表了目標語音能量的佔比。然而,由於頻譜細節遺失,在壓縮的子帶域上增強的音訊是模糊的,通常需要後處理以增強諧波。 RNNoise和PercepNet等使用梳狀濾波器增強諧波,但由於基頻估計以及梳狀濾波增益計算和模型解耦,它們無法被端到端優化;DeepFilterNet使用時頻域濾波器抑制諧波間噪聲,但並沒有明確利用語音的基頻訊息。針對上述問題,團隊提出了一種基於可學習梳狀濾波器的語音諧波增強方法,該方法融合了基頻估計和梳狀濾波,且梳狀濾波的增益可以被端到端優化。實驗顯示,該方法可以在和現有方法相當的計算量下實現更好的諧波增強。
模型框架結構
基頻估計器(F0 Estimator)
為了降低基頻估計難度並使得整個鏈路可以端到端運行,將待估計的目標基頻範圍離散化為N個離散基頻,並使用分類器估計。增加了1維代表非濁音幀,最終模型輸出為N 1維的機率。和CREPE一致,團隊使用高斯平滑的特徵作為訓練目標,並使用Binary Cross Entropy作為損失函數:
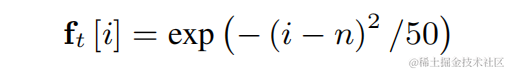
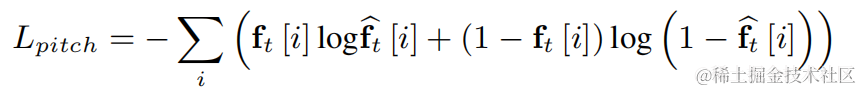
可學習梳狀濾波器(Learnable Comb Filter)
對上述每一個離散基頻,團隊均使用類似PercepNet的FIR濾波器進行梳狀濾波,其可表示為一個受調製的脈衝串:
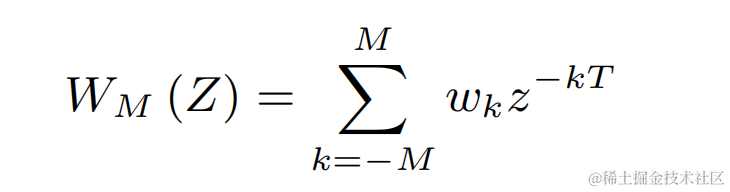
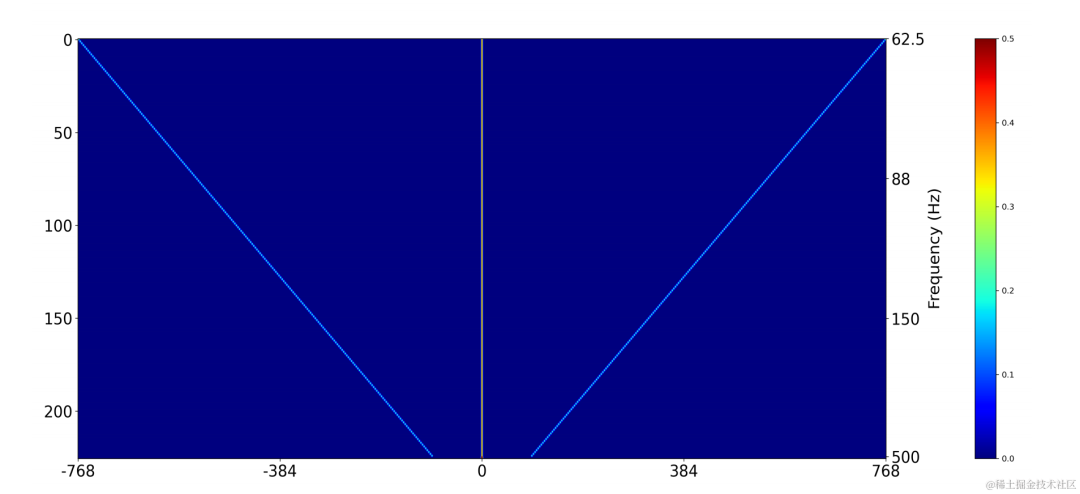
在訓練時使用二維卷積層(Conv2D)同時計算所有離散基頻的濾波結果,該二維卷積的權重可以表示為下圖矩陣,該矩陣有N 1維,每維均使用上述濾波器初始化:
透過目標基頻的獨熱標籤和二維卷積的輸出相乘得到每一幀基頻對應的濾波結果:

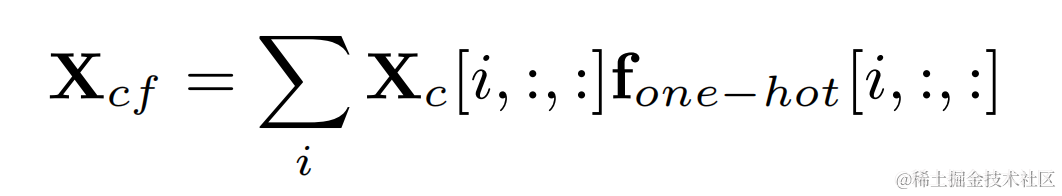
諧波增強後的音訊將和原始音訊加權相加,並和子頻帶增益相乘得到最後的輸出:
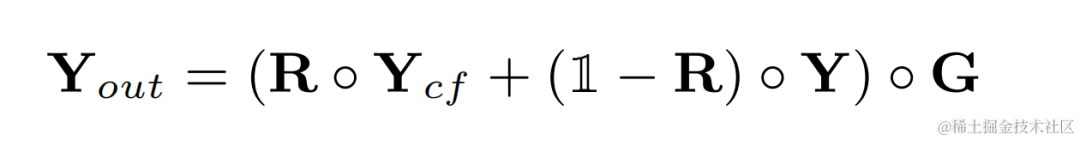
在推斷時,每一幀只需要計算一個基頻的濾波結果,因此此方法的計算消耗量較低。
模型結構
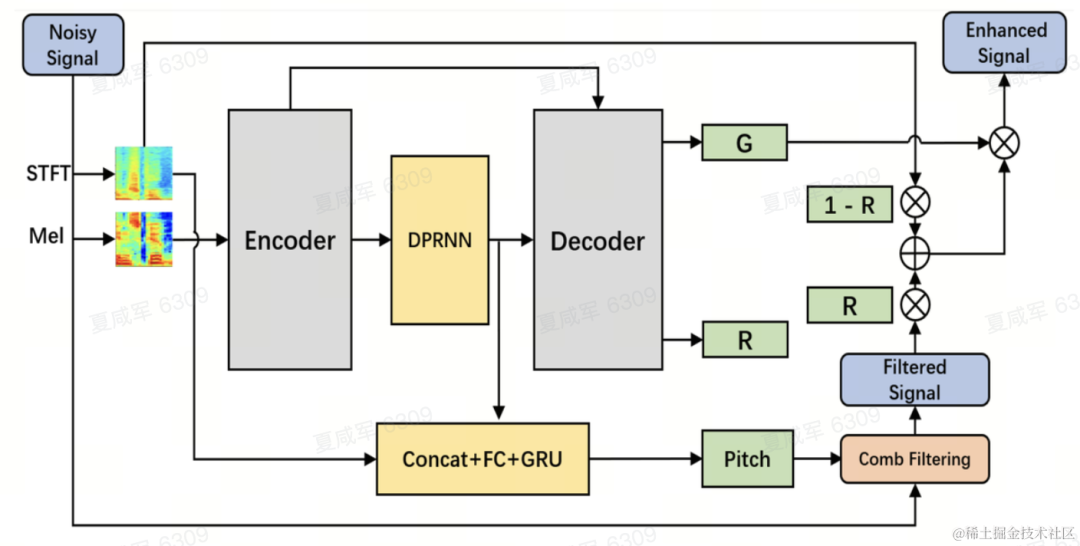
團隊使用雙路卷積循環神經網路(Dual-Path Convolutional Recurrent Network, DPCRN)作為語音增強模型主幹,並添加了基頻估計器。其中Encoder和Decoder使用深度可分離卷積組成對稱結構,Decoder有兩個平行支路分別輸出子帶增益G和加權係數R。基頻估計器的輸入是DPRNN模組的輸出和線性頻譜。此模型的計算量約為300 M MACs,其中梳狀濾波計算量約為0.53M MACs。
模型訓練
在實驗中,使用VCTK-DEMAND和DNS4挑戰賽資料集進行訓練,並使用語音增強和基頻估計的損失函數進行多任務學習。
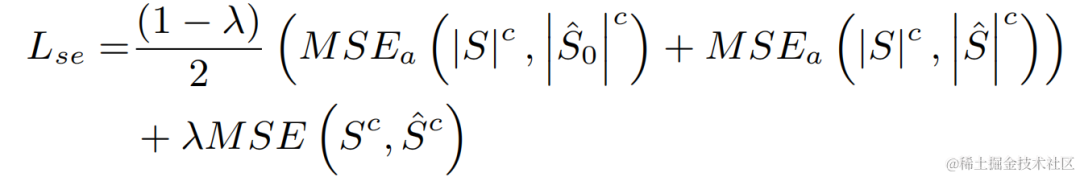
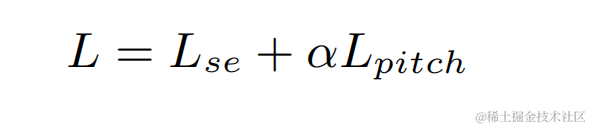
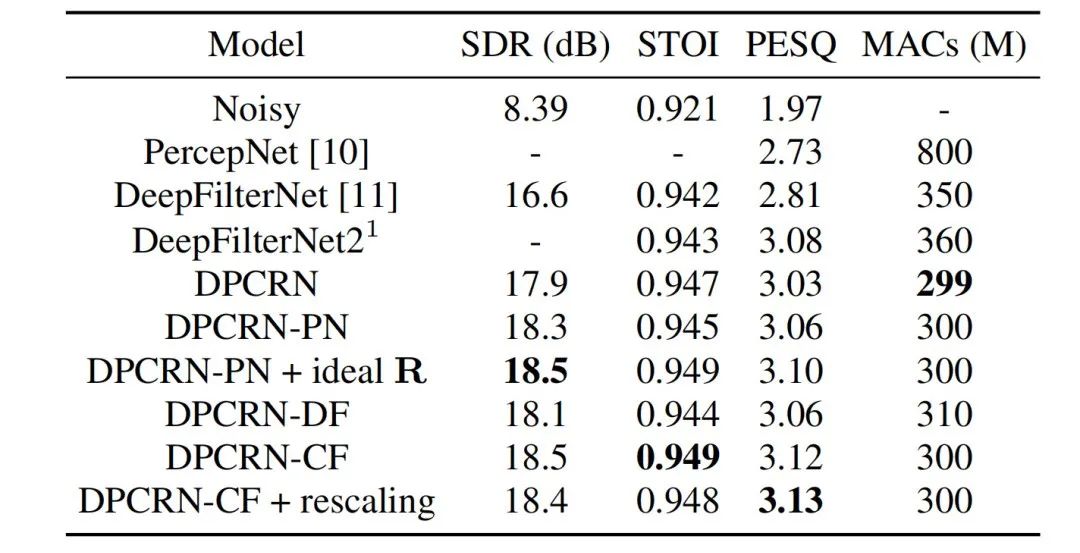
實驗結果
串流音訊團隊將所提出的可學習梳狀濾波模型和使用PercepNet的梳狀濾波以及DeepFilterNet的濾波演算法的模型進行對比,它們分別被稱為DPCRN-CF、DPCRN-PN和DPCRN-DF。在VCTK測試集上,本文提出的方法相對現有方法都顯示出優勢。
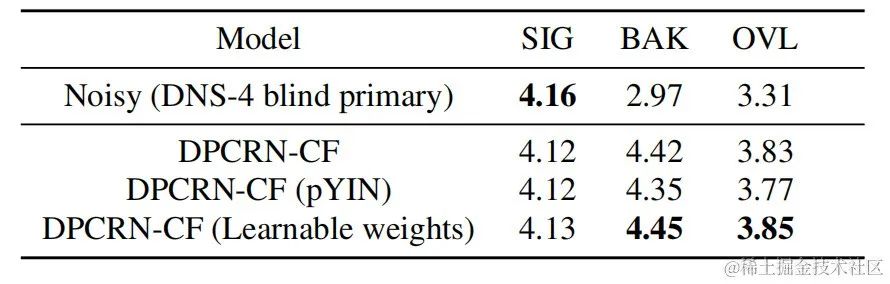
同時團隊對基頻估計和可學習的濾波器進行了消融實驗。實驗結果顯示,相對於使用基於訊號處理的基頻估計演算法和濾波器權重,端到端學習得到的結果更優。
基於Intra-BRNN 和GB-RVQ 的端對端神經網路音訊編碼器
論文位址:https://www.isca-speech .org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
背景
近年來,許多神經網路模型被用於低碼率語音編碼任務,然而一些端到端模型未能充分利用幀內相關訊息,且引入的量化器有較大量化誤差導致編碼後音訊品質偏低。為了提高端對端神經網路音訊編碼器質量,串流音訊團隊提出了一個端到端的神經語音編解碼器,即CBRC(Convolutional and Bidirectional Recurrent neural Codec)。 CBRC使用1D-CNN(一維卷積) 和Intra-BRNN(幀內雙向循環神經網路) 的交錯結構以更有效地利用幀內相關性。此外,團隊在CBRC中使用分組和集束搜尋策略的殘差向量量化器(Group-wise and Beam-search Residual Vector Quantizer,GB-RVQ)來減少量化雜訊。 CBRC以20ms幀長編碼16kHz音頻,沒有額外的系統延遲,適用於即時通訊場景。實驗結果表明,碼率為3kbps的 CBRC編碼語音品質優於12kbps的Opus。
模型框架結構
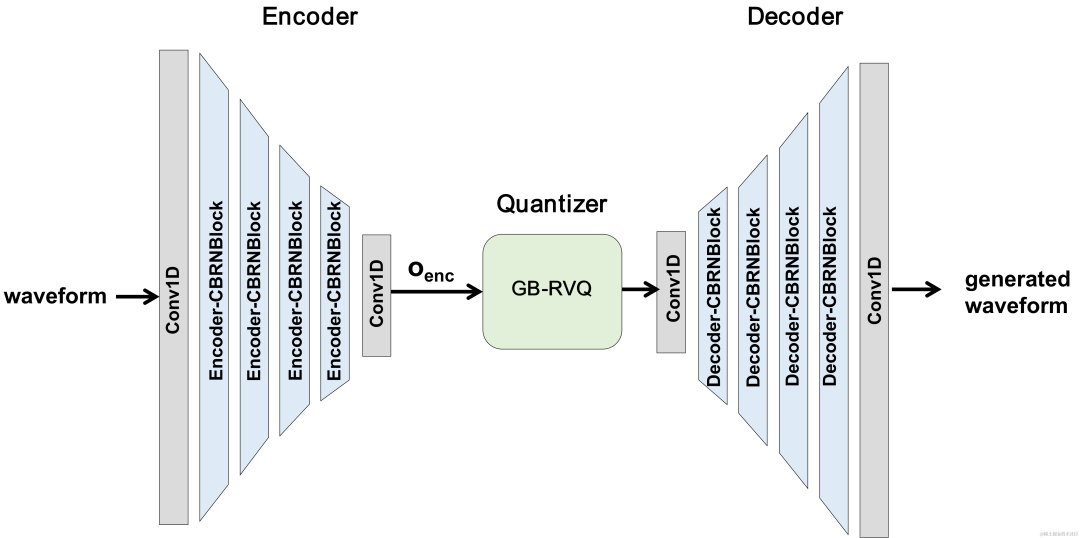
CBRC整體結構
Encoder和Decoder网络结构
Encoder采用4个级联的CBRNBlocks来提取音频特征,每个CBRNBlock由三个提取特征的ResidualUnit和控制下采样率的一维卷积构成。Encoder中特征每经过一次下采样则特征通道数翻倍。在ResidualUnit中由残差卷积模块和残差双向循环网络构成,其中卷积层采用因果卷积,而Intra-BRNN中双向GRU结构只处理20ms帧内音频特征。Decoder网络为Encoder的镜像结构,使用一维转置卷积进行上采样。1D-CNN和Intra-BRNN的交错结构使Encoder和Decoder充分利用20ms音频帧内相关性而不引入额外的延时。
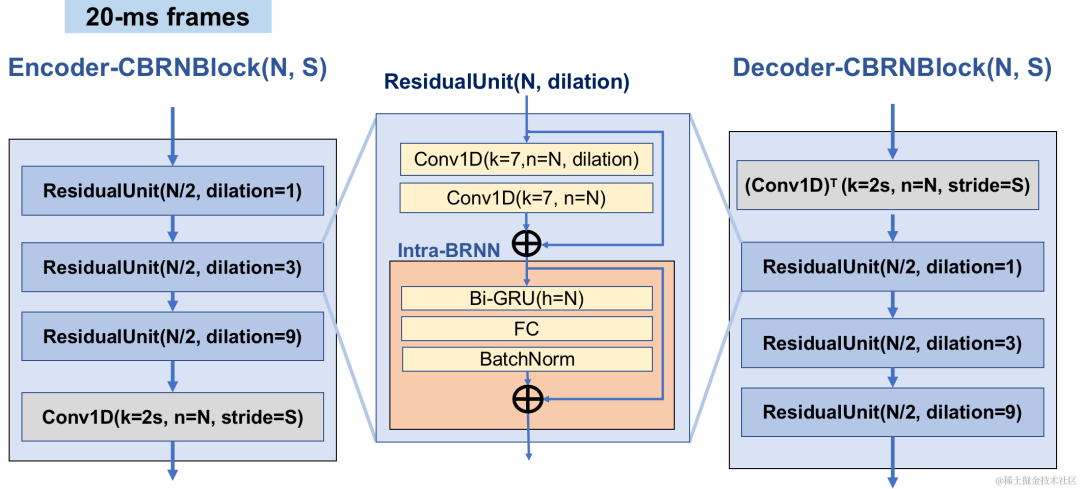
CBRNBlock结构
分组和集束搜索残差矢量量化器 GB-RVQ
CBRC使用残差矢量量化器(Residual Vector Quantizer,RVQ)将编码网络输出特征量化压缩到指定比特率。RVQ以多层矢量量化器(Vector Quantizer,VQ)级联来压缩特征,每层VQ对前一层VQ量化残差进行量化,可显著降低同等比特率下单层VQ的码本参数量。团队在CBRC中提出了两种更优的量化器结构,即分组残差矢量量化器 (Group-wise RVQ) 和集束搜索残差矢量量化器(Beam-search RVQ)。
分组残差矢量量化器 Group-wise RVQ |
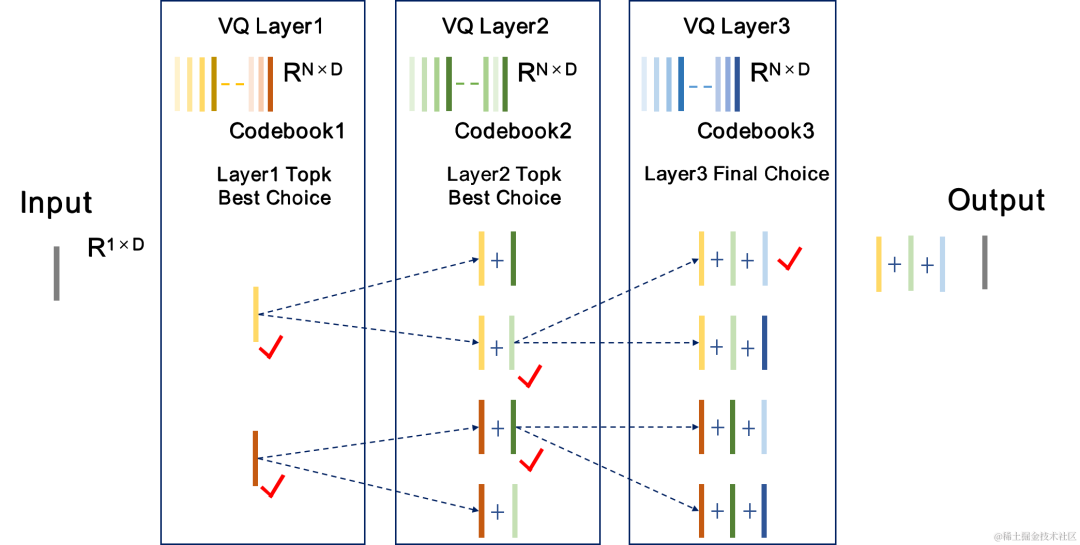
集束搜索残差矢量量化器 Beam-search RVQ |
|
|
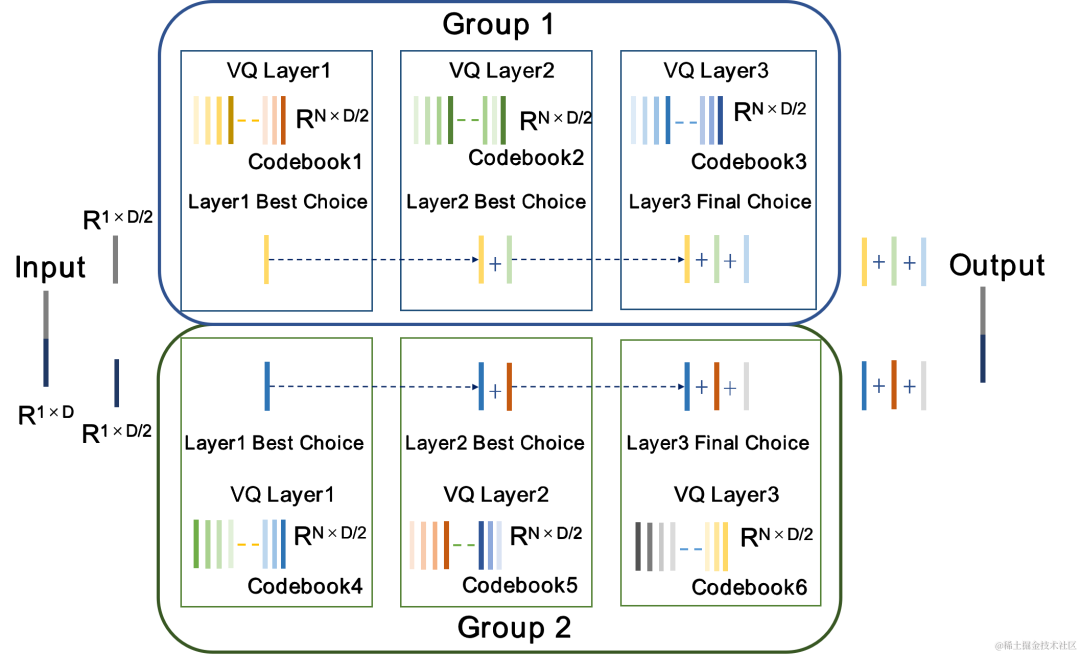
Group-wise RVQ將Encoder輸出分組,同時使用分組的RVQ對分組後特徵進行獨立量化,隨後分組量化輸出拼接輸入Decoder。 Group-wise RVQ以分組量化方式降低了量化器的碼本參數量和計算複雜度,同時降低了CBRC端到端訓練難度進而提升了CBRC編碼音頻品質。
團隊將Beam-search RVQ引入神經音頻編碼器端對端訓練中,使用Beam-search演算法選擇RVQ中量化路徑誤差最小的碼本組合,以降低量化器的量化誤差。原RVQ演算法在每層VQ量化中選擇誤差最小的碼本為輸出,但每層VQ量化最優的碼本組合後不一定是全域最優碼本組合。團隊使用Beam-search RVQ,在每層VQ中以量化路徑誤差最小準則保留k個最優的量化路徑,實現在更大的量化搜尋空間中選擇更優的碼本組合,降低量化誤差。
|
Beam-search RVQ演算法簡短過程: 1、每層VQ輸入前層VQ的個候選量化路徑,得到個候選量化路徑。 2、從個候選量化路徑中選擇個量化路徑誤差最小的個量化路徑作為目前VQ層輸出。 | 3、在最後一層VQ中選擇量化路徑誤差最小的路徑作為量化器的輸出。
|

模型訓練
在實驗中,使用LibriTTS資料集中245小時的16kHz語音進行訓練,將語音幅度乘以隨機增益後輸入模型。訓練中損失函數由頻譜重建多尺度損失,判別器對抗損失和特徵損失,VQ量化損失和感知損失構成。
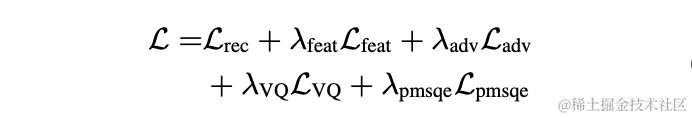
實驗結果
主客觀分數
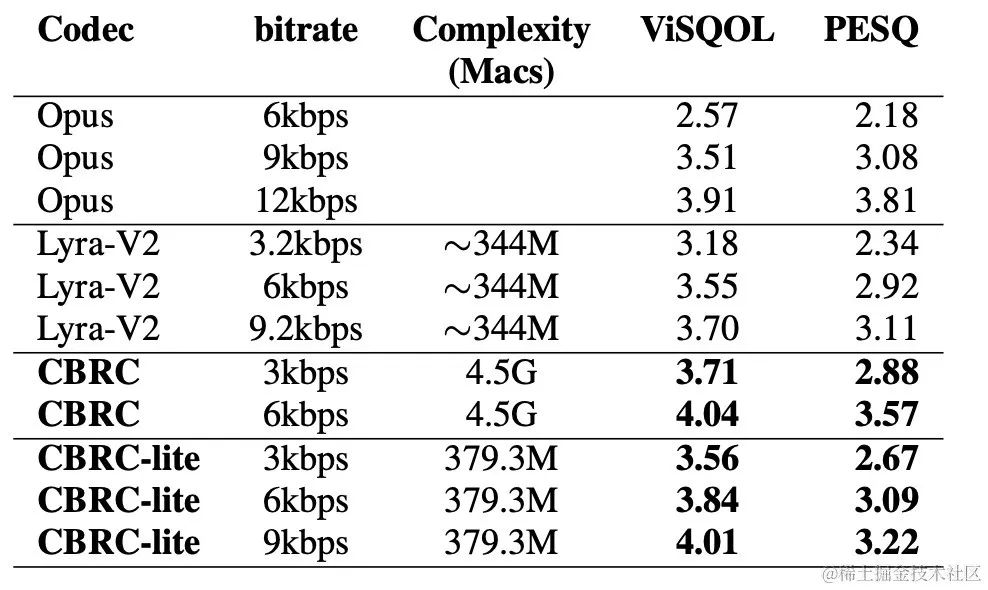
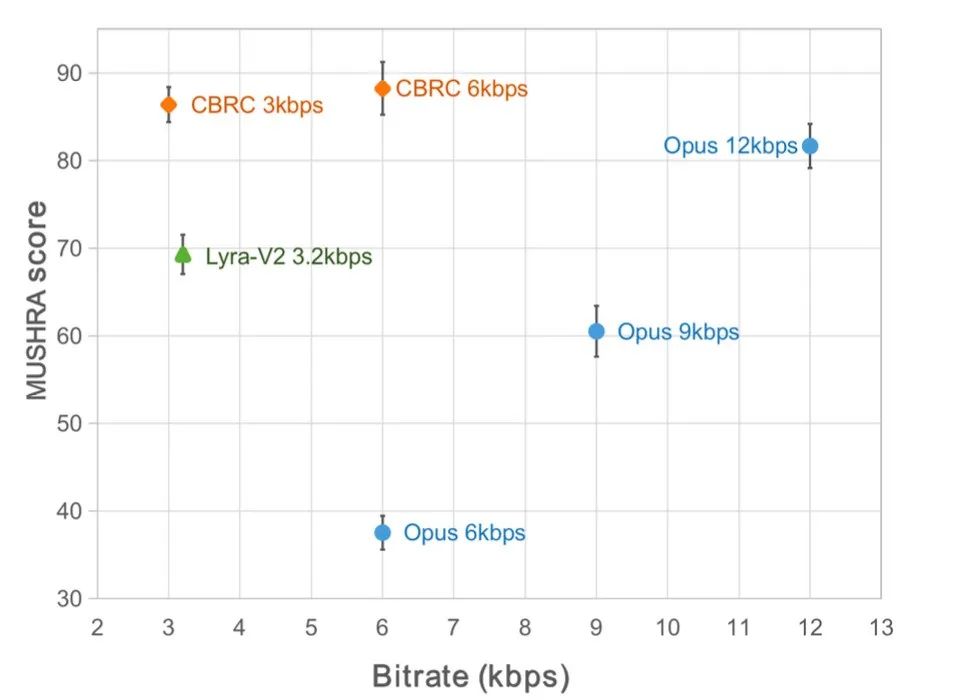
#為了評估CBRC編碼語音質量,建構了10個多語種音頻對比集,在此對比集上與其他音訊編解碼器進行了比較。為了降低計算複雜的影響,團隊設計了輕量化的CBRC-lite,其計算複雜度略高於Lyra-V2。由主觀聽感比較結果可知,CBRC在3kbps上語音品質超過了12kbps的Opus,同樣超過了3.2kbps的Lyra-V2,這顯示所提出方法的有效性。 https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb中提供了CBRC編碼後音頻樣音。
「客觀分數 |
|
主觀聽感得分 |
|
消融实验
团队设计了针对Intra-BRNN、Group-wise RVQ 和 Beam-search RVQ的消融实验。实验结果表明在Encoder和Decoder使用Intra-BRNN均可明显提升语音质量。此外,团队统计了RVQ中码本使用频次并计算熵解码以对比不同网络结构下码本使用率。相比于全卷积结构,使用Intra-BRNN的CBRC将潜在编码比特率从4.94kbps提升到5.13kbps。同样,在 CBRC中使用Group-wise RVQ 和 Beam-search RVQ均能显著提升编码语音质量,且相比于神经网络本身的计算复杂度, GB-RVQ带来的复杂度增加几乎可忽略。


样音
原始音频
arctic_a0023_16k,字节跳动技术团队,5秒
es01_l_16k,字节跳动技术团队,10秒
CBRC 3kbps
arctic_a0023_16k_CBRC_3kbps,字节跳动技术团队,5秒
es01_l_16k_CBRC_3kbps,字节跳动技术团队,10秒
CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps,字节跳动技术团队,5秒
es01_l_16k_CBRC_lite_3kbps,字节跳动技术团队,10秒
基于两阶段渐进式神经网络的回声消除方法
论文地址:https://www.isca-speech.org/archive/pdfs/interspeech_2023/chen23e_interspeech.pdf
背景
在免提通信系统中,声学回声是令人烦恼的背景干扰。当远端信号从扬声器播放出来,然后由近端麦克风记录时,就会出现回声。回声消除 (AEC) 旨在抑制麦克风拾取的不需要的回声。在现实世界中,有很多非常需要消除回声的应用,例如实时通信、智能教室 、车载免提系统等等。
最近,采用深度学习 (DL) 方法的数据驱动 AEC 模型已被证明更加稳健和强大 。这些方法将 AEC 表述为一个监督学习问题,其中输入信号和近端目标信号之间的映射函数通过深度神经网络 (DNN) 进行学习。然而,真实的回声路径极其复杂,这对 DNN 的建模能力提出了更高的要求。为了减轻网络的建模负担,大多数现有的基于 DL 的 AEC 方法采用一个前置的线性回声消除(LAEC) 模块来抑制大部分回声的线性分量。但是,LAEC 模块有两个缺点:1)不合适的 LAEC 可能会导致近端语音的一些失真,以及 2)LAEC 收敛过程使线性回声抑制性能不稳定。由于 LAEC 是自优化的,因此 LAEC 的缺点会给后续的神经网络带来额外的学习负担。
为了避免 LAEC 的影响并保持更好的近端语音质量,本文探索了一种新的基于端到端 DL 的两阶段处理模式,并提出了一种由粗粒度 (coarse-stage) 和细粒度 (fine-stage) 组成的两阶段级联神经网络(TSPNN) 用于回声消除任务。大量的实验结果表明,所提出的两阶段回声消除方法能够达到优于其他主流方法的性能。
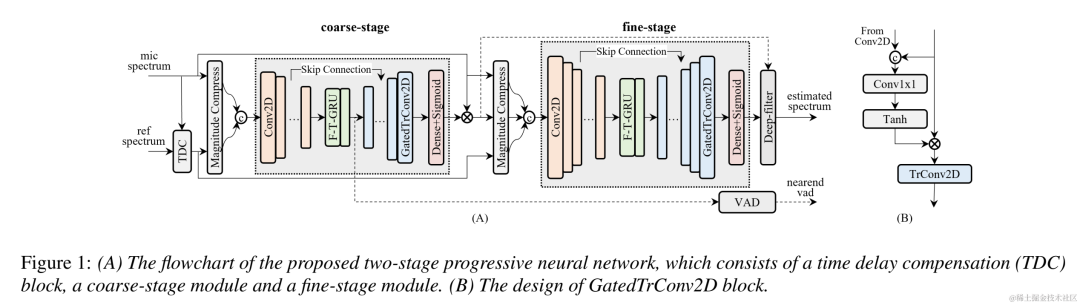
模型框架结构
如下图所示,TSPNN 主要由三个部分组成:时延补偿模块 (TDC)、粗粒度处理模块 (coarse-stage) 和细粒度处理模块 (fine-stage)。TDC 负责对输入的远端参考信号 (ref) 和近端麦克风信号 (mic) 进行对齐,有利于后续模型收敛。coarse-stage 负责将大部分的回声 (echo) 和噪声 (noise) 从 mic 中去除,极大减轻后续 fine-stage 阶段模型学习负担。同时,coarse-stage 结合了语音活跃度检测 (VAD) 任务进行多任务学习,强化模型对近端语音的感知能力,减轻对近端语音的损伤。fine-stage 负责进一步消除残余回声和噪声,并结合邻居频点信息来较好地重构出近端目标信号。
為了避免獨立優化每個階段的模型而導致的次優解,本文採用級聯優化的形式來同時優化coarse-stage 和fine-stage,同時鬆弛對coarse-stage 的約束,避免對近端語音造成損傷。此外,為了讓模型能夠具有感知近端語音的能力,本發明引入了 VAD 任務進行多任務學習,在損失函數中加入 VAD 的 Loss。最終損失函數為:
其中 分別表示目標近端訊號複數譜、coarse-stage 和fine-stage 估計的近端訊號複數譜;分別表示coarse-stage估計的近端語音活躍狀態、近端語音活躍偵測標籤; 為一個控制標量,主要用於調節訓練階段對不同階段的關注程度。本發明限制 來鬆弛對 coarse-stage 的約束,有效避免 coarse-stage 對近端的傷害。
實驗結果
實驗數據
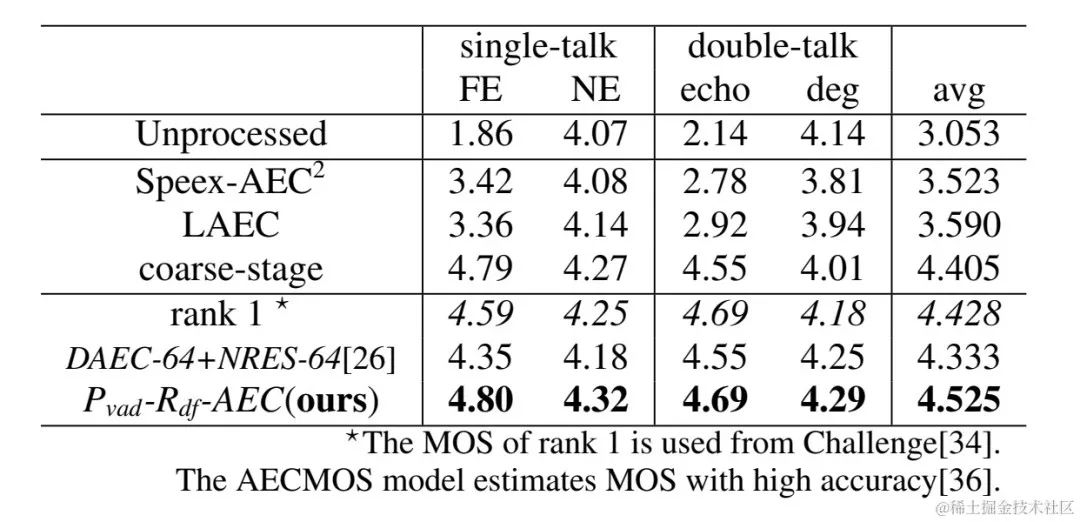
火山引擎串流音訊團隊所提兩階段迴聲消除系統也與其他方法做了比較,實驗結果表明,所提能夠達到優於其他主流方法的效果。
具體範例
- 實驗結果Github 連結:https://github.com/enhancer12/TSPNN
- 雙講場景效果表現:
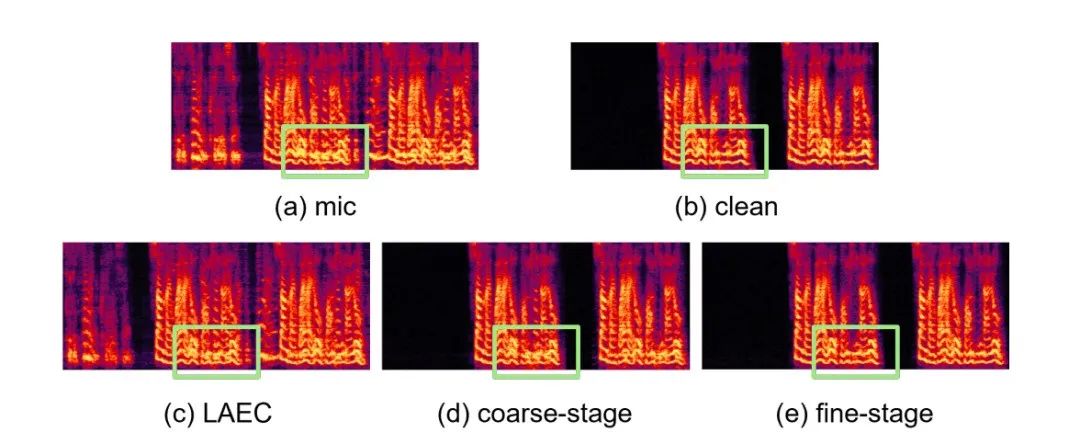
CHiME-7 無監督域自適應語音增強(UDASE)挑戰賽冠軍方案
論文地址:https: //www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf
背景:
#近年來,隨著神經網路和資料驅動的深度學習技術的發展,語音增強技術的研究逐漸轉向基於深度學習的方法,越來越多基於深度神經網路的語音增強模型被提出。然而這些模型大多是基於有監督學習,都需要大量的配對資料進行訓練。然而在實際場景中,無法同時收錄到嘈雜場景的語音和與之配對的不受干擾的乾淨語音標籤,通常採用數據模擬的形式,單獨採集乾淨語音與各種各樣的噪聲,將其按照一定信噪比混合得到帶噪音頻。這導致了訓練場景與實際應用場景的不匹配,模型效能在實際應用中有所下降。
為了更好的解決以上域不匹配問題,利用真實場景中大量無標籤數據,無監督、自監督語音增強技術被提出。 CHiME挑戰賽賽道2旨在利用未標記的數據來克服在人工生成的標記數據上訓練的語音增強模型因訓練數據與實際應用場景的不匹配導致的性能下降問題,研究的重點在於如何借助目標域的無標籤資料和集外的標籤資料來提升目標域的增強結果。
模型框架結構:
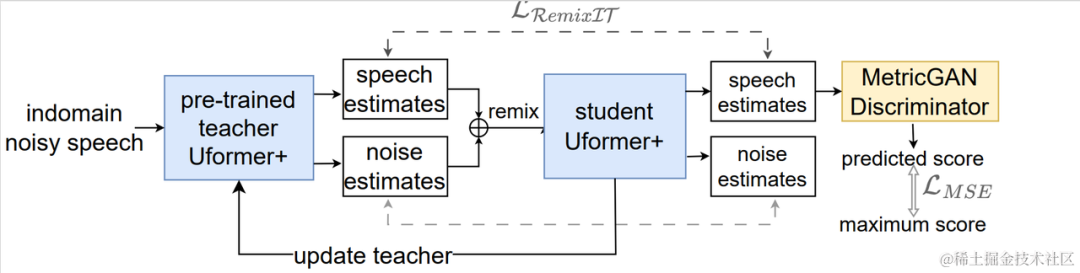
無監督域自適應語音增強系統流程圖
#如上圖所示,所提框架是一個教師學生網路。首先在域內資料上使用語音活動偵測、UNA-GAN、模擬房間衝擊響應、動態加噪等技術產生最接近目標域的標籤資料集,在該域外有標籤資料集上預訓練教師降噪網路Uformer 。接著在域內無標籤數據上藉助該框架更新學生網絡,即利用預訓練的教師網絡從帶噪聲頻中估計乾淨語音和噪聲作為偽標籤,將他們打亂順序重新混合作為學生網絡輸入的訓練數據,利用偽標籤有監督的訓練學生網路。使用預先訓練的MetricGAN判別器估計學生網路產生的乾淨語音品質評分,並與最高分計算損失,以指導學生網路產生更高品質的乾淨音訊。每訓練一定步長後以一定權重將學生網路的參數更新到教師網路中,以獲取更高品質的監督學習偽標籤,如此重複。
Ufomer 網路
Uformer 是在Uformer網路基礎上加入MetricGAN改進得到的。 Uformer是基於 Unet 結構的複數實數雙路徑conformer網絡,它具有兩個並行的分支,幅度譜分支和複數譜分支,網絡結構如下圖所示。幅度分支用於進行主要的噪音抑制功能,能夠有效抑制大部分噪音。複數分支作為輔助,用於補償語譜細節和相位偏差等損失。 MetricGAN的主要想法是使用神經網路模擬不可微的語音品質評估指標,使其可用於網路訓練中,以減少訓練和實際應用時評估指標不一致帶來的誤差。這裡團隊使用感知語音品質評價(PESQ)作為MetricGAN網路估計的目標。
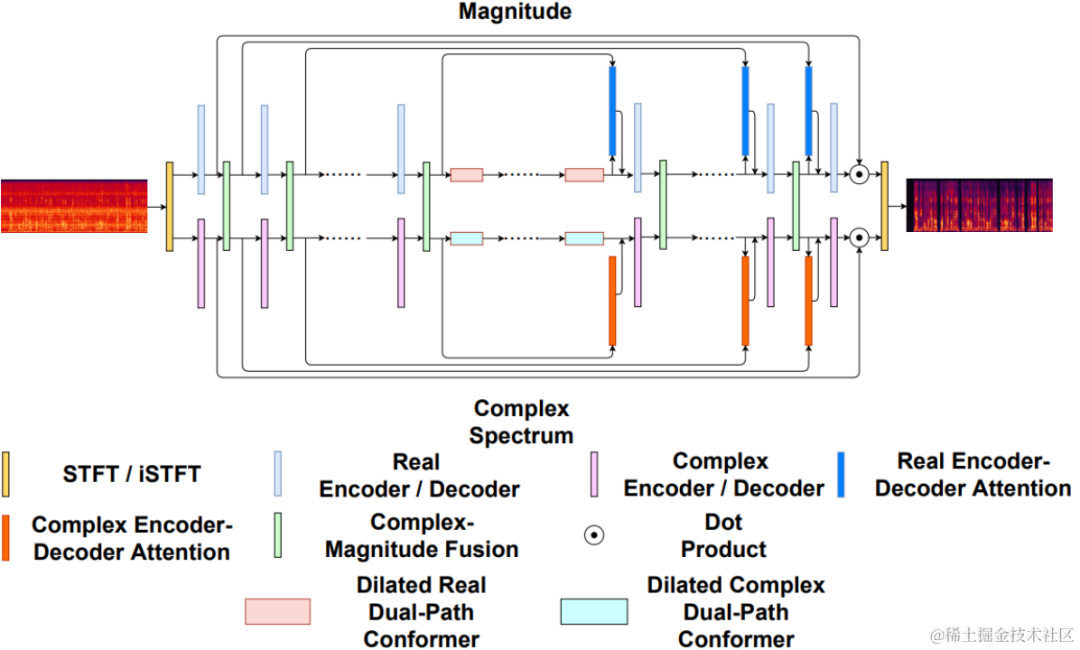
Uformer網路結構圖
RemixIT-G框架
RemixIT-G是一個教師學生網絡,首先在域外有標籤資料上預訓練教師Uformer 模型,使用此預訓練教師模型解碼域內帶噪音頻,估計噪音和語音。接下來在同一批次內打亂估計的噪音和語音的順序,重新將噪音和語音按打亂後的順序混合成為帶噪音頻,作為訓練學生網路的輸入。教師網路估計的噪音和語音作為偽標籤。學生網路解碼重混合的帶噪音頻,估計噪音和語音,與偽標籤計算損失,更新學生網路參數。學生網路估計的語音被送入預訓練的MetricGAN判別器中預測PESQ,並與PESQ最大值計算損失,更新學生網路參數。
所有訓練資料完成一輪迭代後依下列公式更新教師網路的參數:,其中為訓練第K輪教師網路的參數, 為第K輪學生網路的參數。即將學生網路的參數以一定權重與教師網絡相加。
資料擴充方法UNA-GAN
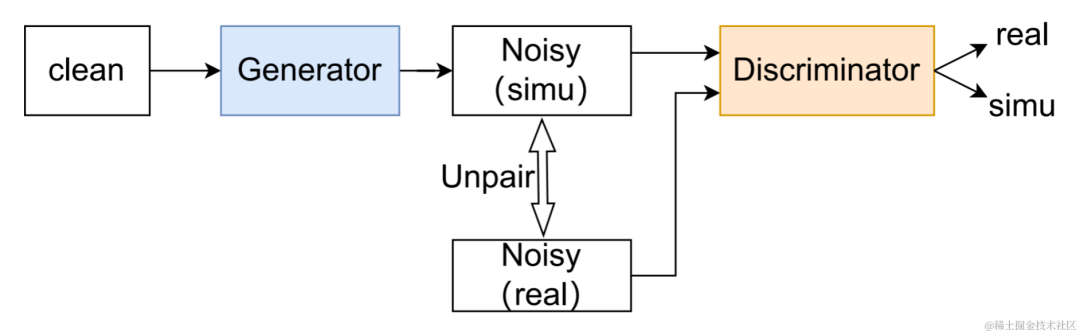
#UNA-GAN結構圖
##無監督雜訊自適應數據擴充網路UNA-GAN是一種基於生成對抗網路的雜訊頻生成模型。其目的是在無法取得獨立的雜訊資料的情況下,只使用域內帶雜訊頻,直接將乾淨語音轉換為具有域內雜訊的雜訊頻。生成器輸入乾淨語音,輸出模擬的帶噪音頻。判別器輸入產生的雜訊頻或真實的域內帶雜訊頻,判斷輸入的音訊來自真實場景還是模擬產生。判別器主要根據背景噪音的分佈來區分來源,在這個過程中,人類語音被視為無效訊息。透過執行以上對抗訓練的過程,生成器試圖將域內雜訊直接添加在輸入的乾淨音訊上,以迷惑判別器;判別器試圖盡力區分帶雜訊頻的來源。為了避免生成器添加過多噪聲,覆蓋掉輸入音訊中的人類語音,使用了對比學習。在生成的帶噪音頻、和輸入的乾淨語音對應位置採樣256個區塊。相同位置的區塊的配對被視為正範例,不同位置的區塊的配對被視為負樣例。使用正負樣例計算交叉熵損失。 實驗結果結果顯示所提出的Uformer 相比基線Sudo rm-rf具有更強的效能,資料擴充方法UNA-GAN也具有產生域內帶雜訊頻的能力。域適應框架RemixIT基線在SI-SDR上取得了較大提升,但在DNS-MOS上指標較差。團隊提出的改進RemixIT-G同時在兩個指標上都取得了有效提升,並在競賽盲測集上取得了最高的主觀測聽MOS打分。最終測聽結果如下圖所示。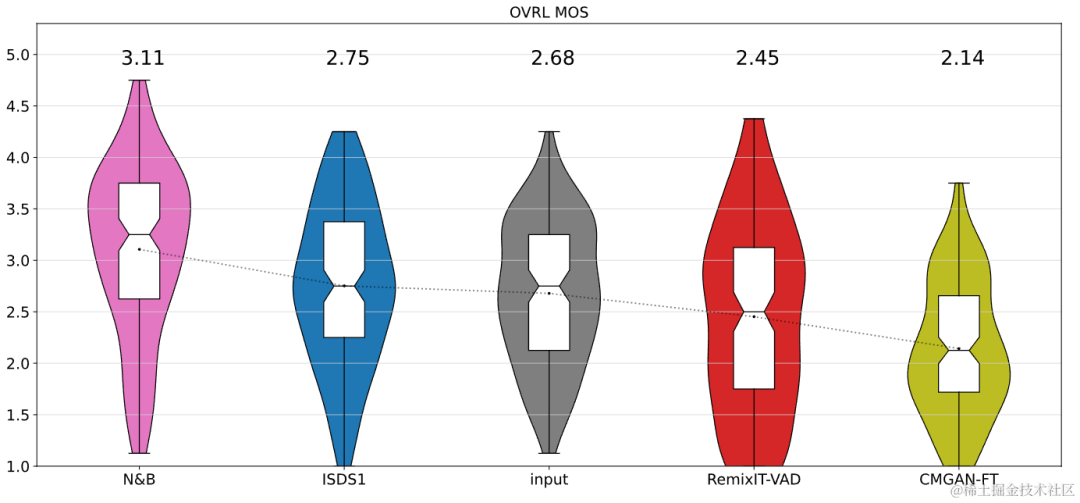
以上是Interspeech 2023 | 火山引擎串流音訊技術之語音增強與AI音訊編碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
嘿,編碼忍者!您當天計劃哪些與編碼有關的任務?在您進一步研究此博客之前,我希望您考慮所有與編碼相關的困境,這是將其列出的。 完畢? - 讓&#8217
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
介紹 Openai已根據備受期待的“草莓”建築發布了其新模型。這種稱為O1的創新模型增強了推理能力,使其可以通過問題進行思考
 視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表語句:動態地將列添加到數據庫 在數據管理中,SQL的適應性至關重要。 需要即時調整數據庫結構嗎? Alter表語句是您的解決方案。本指南的詳細信息添加了Colu
 pixtral -12b:Mistral AI'第一個多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一個多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
介紹 Mistral發布了其第一個多模式模型,即Pixtral-12b-2409。該模型建立在Mistral的120億參數Nemo 12B之上。是什麼設置了該模型?現在可以拍攝圖像和Tex
 如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在從事代理AI時,開發人員經常發現自己在速度,靈活性和資源效率之間進行權衡。我一直在探索代理AI框架,並遇到了Agno(以前是Phi-
 超越駱駝戲:大型語言模型的4個新基準
Apr 14, 2025 am 11:09 AM
超越駱駝戲:大型語言模型的4個新基準
Apr 14, 2025 am 11:09 AM
陷入困境的基準:駱駝案例研究 2025年4月上旬,梅塔(Meta)揭開了其Llama 4套件的模特,擁有令人印象深刻的性能指標,使他們對GPT-4O和Claude 3.5 Sonnet等競爭對手的良好定位。倫斯的中心
 多動症遊戲,健康工具和AI聊天機器人如何改變全球健康
Apr 14, 2025 am 11:27 AM
多動症遊戲,健康工具和AI聊天機器人如何改變全球健康
Apr 14, 2025 am 11:27 AM
視頻遊戲可以緩解焦慮,建立焦點或支持多動症的孩子嗎? 隨著醫療保健在全球範圍內挑戰,尤其是在青年中的挑戰,創新者正在轉向一種不太可能的工具:視頻遊戲。現在是世界上最大的娛樂印度河之一
