

快速訓練小型專業模型:只需1句指令、5美元和20分鐘,體驗Prompt2Model!

大規模語言模型(LLM)使用戶能夠透過提示和上下文學習來建立強大的自然語言處理系統。然而,從另一個角度來看,LLM 在某些特定的自然語言處理任務上表現出一定的退步:這些模型的部署需要大量的計算資源,並且透過API 與模型進行交互可能會引發潛在的隱私問題
為了回應這些問題,來自卡內基美隆大學(CMU)和清華大學的研究人員共同推出了Prompt2Model框架。該框架的目標是將基於LLM的資料生成和檢索方法相結合,以克服上述挑戰。使用Prompt2Model框架,使用者只需提供與LLM相同的提示,即可自動收集資料並有效地訓練適用於特定任務的小型專業模型
研究人員進行了一項實驗,針對三個自然語言處理子任務進行了研究。他們使用了少量樣本提示作為輸入,並且只花了5美元來收集數據,並進行了20分鐘的訓練。透過Prompt2Model框架產生的模型在效能上比強大的LLM模型gpt-3.5-turbo提升了20%。同時,模型的大小縮小了700倍。研究人員進一步驗證了這些數據在真實場景中對模型效果的影響,使得模型開發人員能夠在部署之前預估模型的可靠性。這個框架已經以開源形式提供:

- #框架的GitHub 倉庫位址:https:/ /github.com/neulab/prompt2model
- 框架示範影片連結:youtu.be/LYYQ_EhGd-Q
- #框架相關論文連結:https ://arxiv.org/abs/2308.12261
#背景
建立特定的自然語言處理任務系統通常是相當複雜的。系統的建構者需要明確定義任務的範圍,取得特定的資料集,選擇合適的模型架構,進行模型的訓練和評估,然後將其部署以供實際應用
大規模語言模型(LLM)如GPT-3為此過程提供了更簡單的解決方案。使用者只需提供任務提示(instruction)以及一些範例(examples),LLM就能產生對應的文字輸出。然而,透過提示產生文字可能會消耗大量運算資源,並且使用提示的方式不如經過專門訓練的模型穩定。此外,LLM的可用性也受到成本、速度和隱私等方面的限制
為了解決這些問題,研究人員開發了Prompt2Model框架。該框架結合了基於LLM的資料生成和檢索技術,以克服上述限制。系統首先從提示訊息中提取關鍵訊息,然後產生並檢索訓練數據,最終產生可供部署的專業化模型
Prompt2Model 框架自動執行以下核心步驟: 1. 資料預處理:將輸入資料進行清洗和標準化,以確保其適用於模型訓練。 2. 模型選擇:根據任務的要求,選擇適當的模型架構和參數。 3. 模型訓練:使用預處理後的資料對選定的模型進行訓練,以優化模型的效能。 4. 模型評估:透過評估指標對訓練後的模型進行表現評估,以確定其在特定任務上的表現。 5. 模型調優:根據評估結果,將模型進行調優,以進一步提升其效能。 6. 模型部署:將訓練好的模型部署到實際應用環境中,以實現預測或推理功能。 透過自動化執行這些核心步驟,Prompt2Model 框架能夠幫助使用者快速建立和部署高效能的自然語言處理模型
- 資料集與模型檢索:收集相關資料集和預訓練模型。
- 資料集產生:利用 LLM 建立偽標記資料集。
- 模型微調:透過混合檢索資料和產生資料對模型進行微調。
- 模型測試:在測試資料集和使用者提供的真實資料集上對模型進行測試。
透過對多個不同任務進行實證評估,我們發現Prompt2Model的成本顯著降低,模型的體積也大幅縮小,但性能卻超越了gpt-3.5-turbo 。 Prompt2Model框架不僅可以作為高效建構自然語言處理系統的工具,還可以作為探索模型整合訓練技術的平台
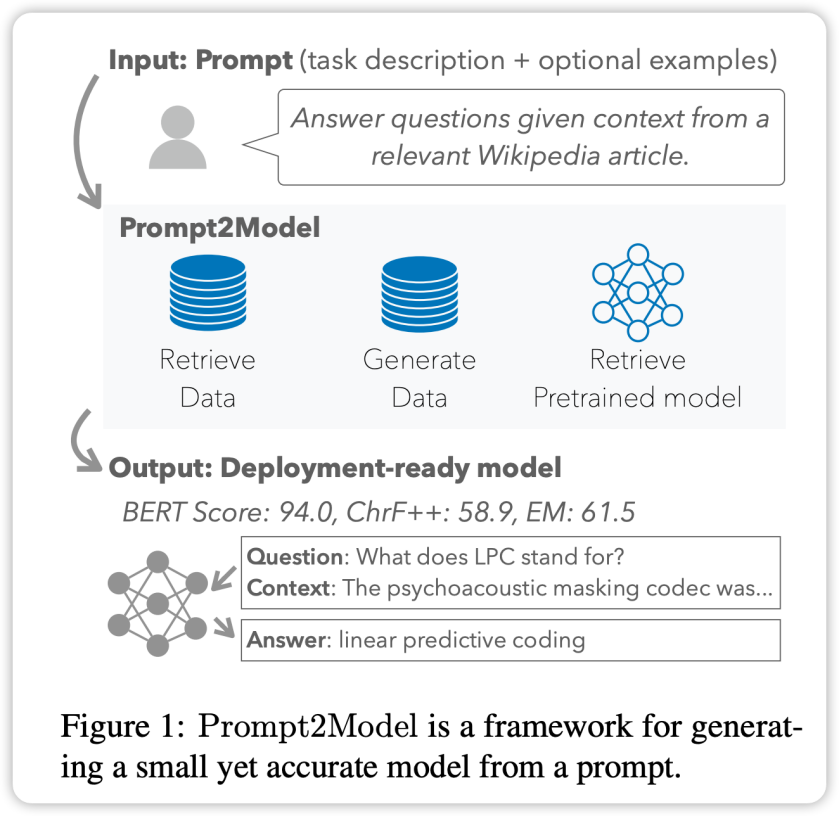
框架
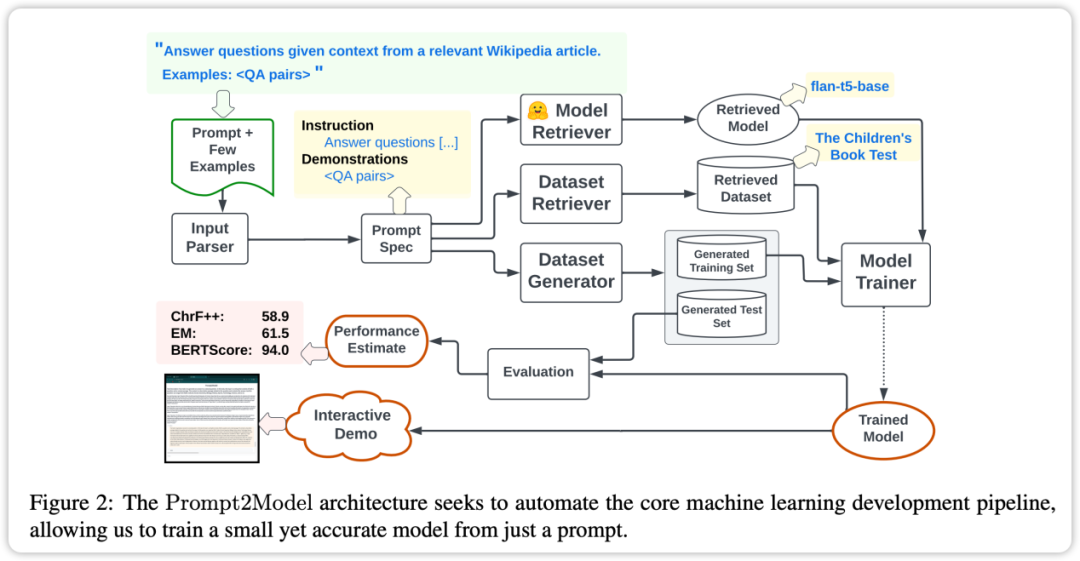
Prompt2Model 框架的核心特點是高度自動化。它的流程包括資料收集、模型訓練、評估和部署等多個環節,如上圖所示。其中,自動化資料收集系統起著關鍵作用,它透過資料集檢索和基於 LLM 的資料生成,獲取與使用者需求密切相關的資料。接下來,系統會檢索預訓練模型,並在所取得的資料集上進行微調。最後,系統會在測試集上對經過訓練的模型進行評估,並建立用於與模型互動的Web 使用者介面(UI)
Prompt2Model 框架的關鍵特點包括:
- Prompt 驅動:Prompt2Model 的核心思想在於使用prompt 作為驅動,使用者可以直接描述所需的任務,而無需深入了解機器學習的具體實作細節。
- 自動資料收集:框架透過資料集檢索和產生技術來獲取與使用者任務高度匹配的數據,從而建立訓練所需的資料集。
- 預訓練模型:框架利用預訓練模型並進行微調,從而節省大量的訓練成本和時間。
- 效果評估:Prompt2Model 支援在實際資料集上進行模型測試和評估,使得在部署模型之前就能進行初步預測和效能評估,從而提高了模型的可靠性。
Prompt2Model 框架具備以下特點,使其成為一個強大的工具,能夠高效地完成自然語言處理系統的構建過程,並且提供了先進的功能,如數據自動收集、模型評估以及使用者互動介面的建立
#實驗與結果
為了評估Prompt2Model系統的效能,在實驗設計中,研究者選擇了三個不同的任務
- 機讀問答(Machine Reading QA):使用SQuAD 作為實際評估資料集。
- 日文自然語言到程式碼轉換(Japanese NL-to-Code):使用 MCoNaLa 作為實際評估資料集。
- 時間表達式規範化(Temporal Expression Normalization):使用 Temporal 資料集作為實際評估資料集。
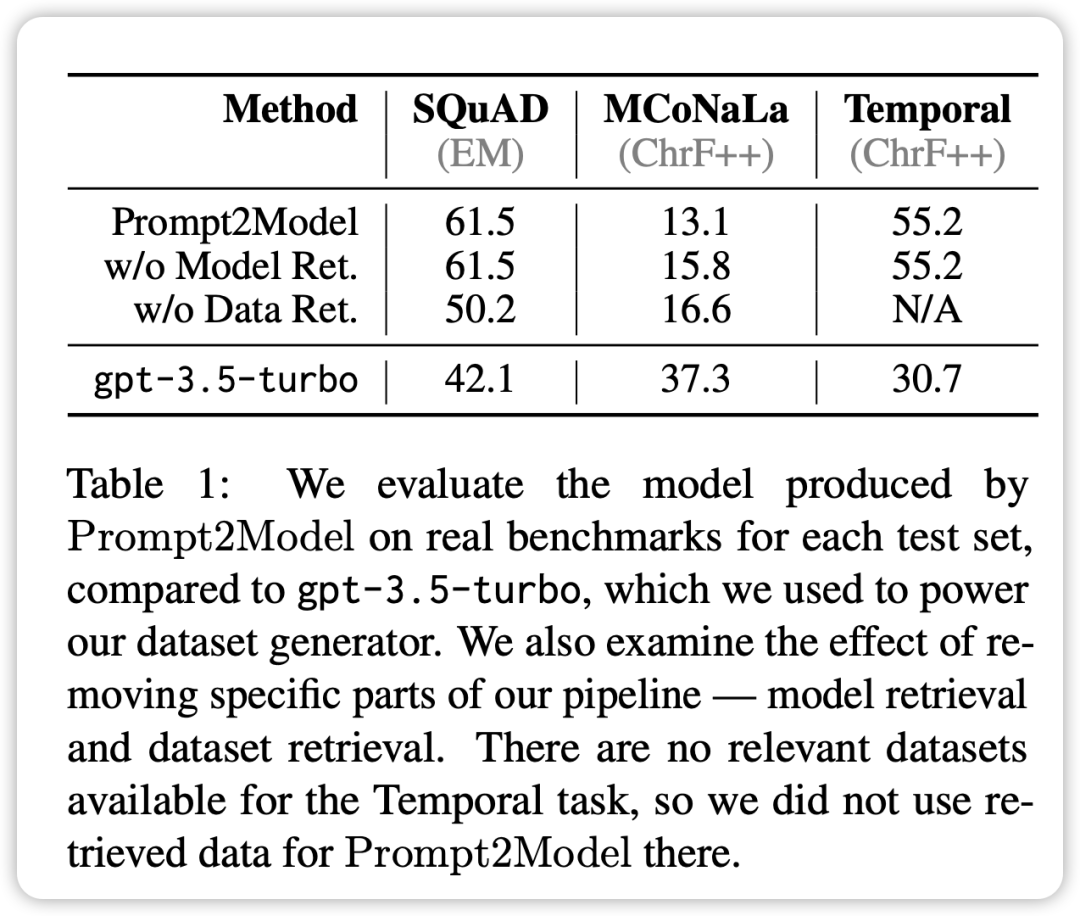
此外,研究人員也使用GPT-3.5-turbo作為基準模型進行比較。實驗結果得出以下結論:
- 在除了程式碼產生任務之外的各項任務中,Prompt2Model 系統所產生的模型明顯優於基準模型GPT-3.5- turbo,儘管產生的模型參數規模遠小於GPT-3.5-turbo。
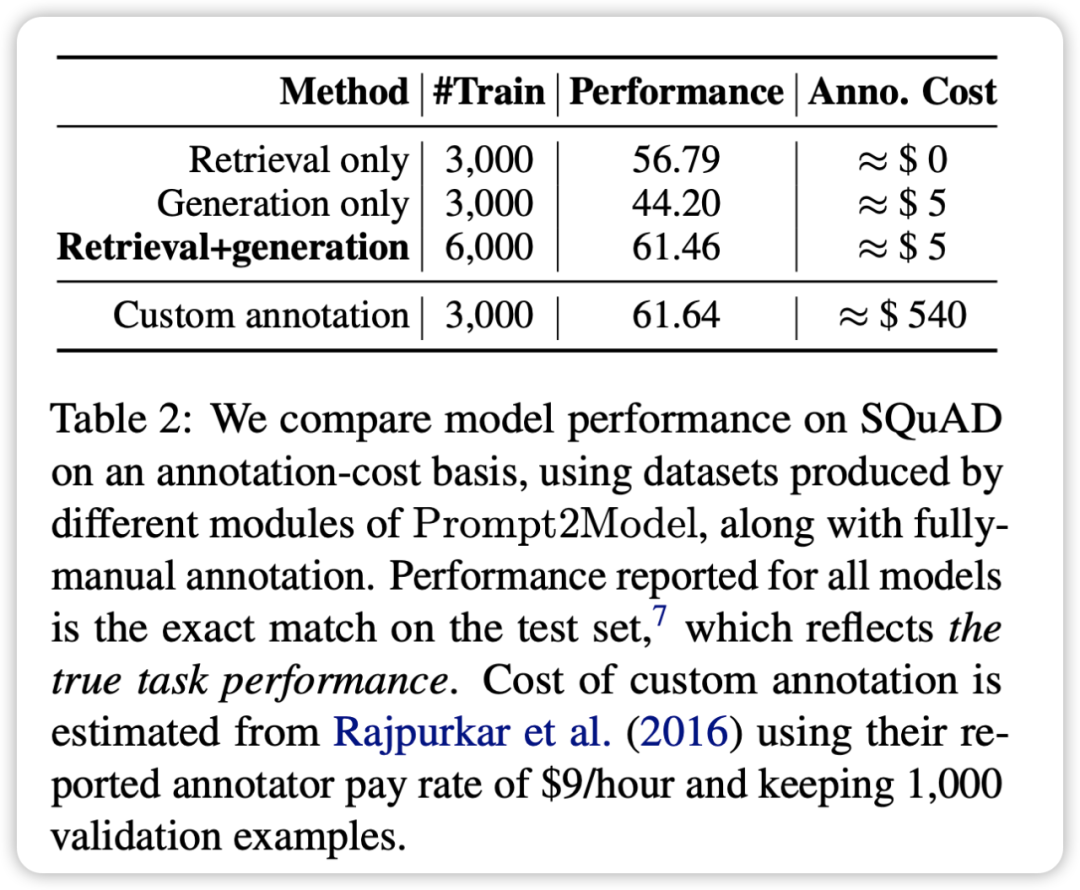
- 透過將檢索資料集與生成資料集進行混合訓練,可以達到與直接使用實際資料集訓練相媲美的效果。這驗證了 Prompt2Model 框架能夠大幅降低人工標註的成本。
- 資料產生器所產生的測試資料集能夠有效區分不同模型在實際資料集上的效能。這表明產生的數據具有較高的質量,在模型訓練方面具有充分的效果。
- 在日文到程式碼轉換任務中,Prompt2Model 系統的表現不如 GPT-3.5-turbo。
可能是由於產生的資料集品質不高,以及缺乏適當的預訓練模型等原因所導致
綜合而言,Prompt2Model 系統在多個任務上成功產生了高品質的小型模型,大大減少了對人工標註資料的需求。然而,在某些任務上仍需要進一步改進
#總結
###################################################### ####Prompt2Model 框架是由研究團隊開發的一項創新技術,它透過自然語言提示來自動建立任務特定模型。這項技術的推出大大降低了建構客製化自然語言處理模型的難度,進一步擴展了 NLP 技術的應用範圍######
验证实验结果显示,Prompt2Model框架生成的模型规模较大型语言模型显著减小,并在多个任务上表现优于GPT-3.5-turbo等模型。同时,该框架生成的评估数据集也被证实能够有效评估不同模型在真实数据集上的性能。这为指导模型最终部署提供了重要价值
Prompt2Model 框架为行业和广大用户提供了一种低成本、易于上手的方式,用于获取满足特定需求的 NLP 模型。这对于推动 NLP 技术的广泛应用具有重要意义。未来的工作将继续致力于进一步优化框架的性能
按照文章顺序,本文作者如下: 重新编写的内容:根据文章的顺序,本文的作者如下:
维贾伊·维斯瓦纳坦:http://www.cs.cmu.edu/~vijayv/
赵晨阳:https://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs.cmu.edu/~abertsch/ 阿曼达·贝尔奇: https://www.cs.cmu.edu/~abertsch/
吴同爽:https://www.cs.cmu.edu/~sherryw/
格雷厄姆·纽比格:http://www.phontron.com/
以上是快速訓練小型專業模型:只需1句指令、5美元和20分鐘,體驗Prompt2Model!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通過使用 ALTER TABLE 語句為現有表添加新列。具體步驟包括:確定表名稱和列信息、編寫 ALTER TABLE 語句、執行語句。例如,為 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的語法為 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是數據類型,NOT NULL 指定是否允許空值,DEFAULT default_value 指定默認值。
 SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,釋放空間並重置標識列。禁用外鍵約束,防止級聯刪除。使用事務封裝操作,保證數據一致性。批量刪除大數據,通過 LIMIT 限制行數。清空後重建索引,提高查詢效率。
 SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
為新添加的列設置默認值,使用 ALTER TABLE 語句:指定添加列並設置默認值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默認值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 語句可用於清空 SQL 表,步驟如下:使用 DELETE 語句:DELETE FROM table_name;替換 table_name 為要清空的表的名稱。
 Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片是指分配的內存中存在無法再分配的小塊空閒區域。應對策略包括:重啟Redis:徹底清空內存,但會中斷服務。優化數據結構:使用更適合Redis的結構,減少內存分配和釋放次數。調整配置參數:使用策略淘汰最近最少使用的鍵值對。使用持久化機制:定期備份數據,重啟Redis清理碎片。監控內存使用情況:及時發現問題並採取措施。
 phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 創建數據表,以下步驟必不可少:連接到數據庫並單擊“新建”標籤。為表命名並選擇存儲引擎(推薦 InnoDB)。通過單擊“添加列”按鈕添加列詳細信息,包括列名、數據類型、是否允許空值以及其他屬性。選擇一個或多個列作為主鍵。單擊“保存”按鈕創建表和列。
 怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
創建Oracle數據庫並非易事,需理解底層機制。 1. 需了解數據庫和Oracle DBMS的概念;2. 掌握SID、CDB(容器數據庫)、PDB(可插拔數據庫)等核心概念;3. 使用SQL*Plus創建CDB,再創建PDB,需指定大小、數據文件數、路徑等參數;4. 高級應用需調整字符集、內存等參數,並進行性能調優;5. 需注意磁盤空間、權限和參數設置,並持續監控和優化數據庫性能。 熟練掌握需不斷實踐,才能真正理解Oracle數據庫的創建和管理。
