

「人與場景交互生成」新突破!天大、清華發布Narrator:文字驅動,自然可控|ICCV 2023

自然可控的人與場景互動(Human Scene Interaction, HSI)生成在虛擬實境/擴增實境(VR/AR)內容創作和以人為中心的人工智慧等多個領域發揮著重要作用。
然而,現有方法的可控能力有限、互動種類有限、生成結果不自然,嚴重限制了它在現實中的應用場景
在ICCV 2023的研究中,天津大學和清華大學的團隊提出了一個名為Narrator的解決方案,針對這個問題進行了探索。這個解決方案的重點是在從文字描述中自然可控地生成逼真且多樣的人與場景交互這一具有挑戰性的任務上
 ##圖片
##圖片
##方法動機
#現有的人與場景互動生成方法大多關注在互動的物理幾何關係,但缺乏對生成的語意控制,也侷限於單人生成。
因此,作者著眼於一項具有挑戰性的任務,即從自然語言描述中可控生成真實且多樣的人與場景互動。作者觀察到人類通常會透過空間感知和動作辨識來自然地描述在不同地點進行各種互動的人。
圖片 重寫內容如下:根據圖1,Narrator可以自然而可控地產生語意一致且物理合理的人與場景交互,適用於以下各種情況:(a)由空間關係引導的交互,(b)由多個動作引導的交互,(c)多人場景交互,以及(d)結合上述交互類型的人與場景互動
重寫內容如下:根據圖1,Narrator可以自然而可控地產生語意一致且物理合理的人與場景交互,適用於以下各種情況:(a)由空間關係引導的交互,(b)由多個動作引導的交互,(c)多人場景交互,以及(d)結合上述交互類型的人與場景互動
具體來說,空間關係可以用來描述場景或局部區域中不同物件之間的相互關係。而互動動作則由原子身體部位的狀態來指定,例如人的腳踩地、軀幹靠著、右手輕拍和低著頭等
以此為出發點,作者採用場景圖來表示空間關係,提出了聯合全局和局部場景圖(Joint Global and Local Scene Graph, JGLSG) 機制,為隨後的生成提供了全局位置感知。
同時,考慮到身體部位狀態是模擬符合文字的逼真互動的關鍵,作者引入了部位層級動作(Part-Level Action, PLA)機制來建立人體部位與動作之間的對應關係。
受益於有效的觀察認知以及所提出的關係推理的靈活性和復用性,作者進一步提出一種簡單而有效的多人生成策略,這是當時第一個自然可控且使用者友好的多人場景互動(Multi-Human Scene Interaction, MHSI)生成方案。
方法思維
Narrator框架總覽
Narrator的目標是以自然可控的方式產生人物與場景之間的互動,這種互動在語義上與文字描述一致,並且在物理上與三維場景相匹配
##圖片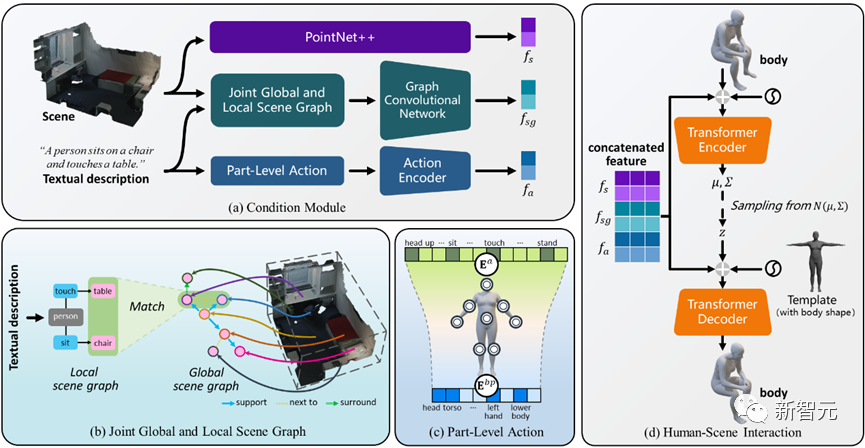 圖2 Narrator框架總覽
圖2 Narrator框架總覽
2)針對人們會同時透過不同的身體部位完成互動動作的觀察,引入了部件層級動作機制,以實現逼真和多樣化的互動;
#在場景感知最佳化過程中,我們額外引入了交互二分面損失,以期獲得更優秀的生成結果
4)進一步擴展到多人互動生成,並最終促進了多人場景互動的第一步。
聯合全域和局部場景圖機制
#空間關係的推理可以為模型提供特定場景的線索,對於實現人與場景交互的自然可控性具有重要作用。
為了實現這一目標,作者提出了一種全局和局部場景圖聯合機制,該機制透過以下三個步驟來實施:
##1. 全域場景圖產生:給定場景,用預先訓練好的場景圖模型產生全域場景圖,即 ,其中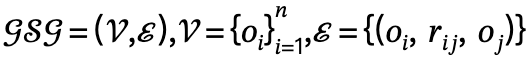 ,
,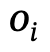 是帶有類別標籤的對象,
是帶有類別標籤的對象,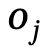 是
是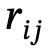 和
和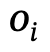 之間的關係,n是物體數量,m是關係數量;
之間的關係,n是物體數量,m是關係數量;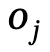
,其中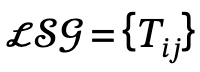 定義了主詞-謂語-物件的三元組;
定義了主詞-謂語-物件的三元組;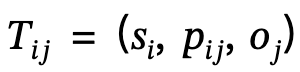
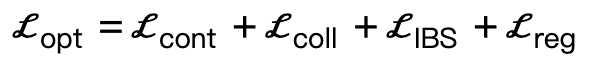
其中,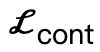 鼓勵身體頂點與場景接觸;
鼓勵身體頂點與場景接觸;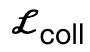 是基於符號距離的碰撞項;
是基於符號距離的碰撞項;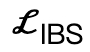 是相比現有工作額外引入的交互二分面(IBS)損失,其為取樣於場景和人體之間的等距點集合;
是相比現有工作額外引入的交互二分面(IBS)損失,其為取樣於場景和人體之間的等距點集合;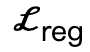 是一個正規因子,用於懲罰偏離初始化的參數。
是一個正規因子,用於懲罰偏離初始化的參數。
多人場景交互(MHSI)
在現實世界的場景中,很多情況下並非只有一個人與場景交互,而是多人以獨立或關聯的方式進行互動。
然而,由於缺乏MHSI資料集,現有方法通常需要額外的人工努力,無法以可控和自動的方式處理這項任務。
為此,作者僅利用現有的單人資料集,為多人生成方向提出了簡單而有效的策略。
給定多人相關的文本描述後,作者首先將其解析為多個局部場景圖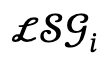 和交互動作
和交互動作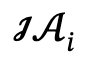 ,並定義候選集為
,並定義候選集為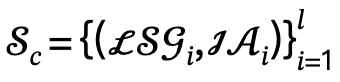 ,其中l為人數。
,其中l為人數。
對於候選集中的每一項,首先將其與場景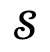 和對應全域場景圖
和對應全域場景圖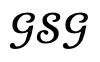 一起輸入Narrator,然後執行最佳化過程。
一起輸入Narrator,然後執行最佳化過程。
為了處理人與人之間的碰撞,在最佳化過程中額外引入了損失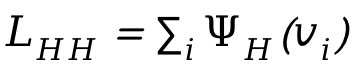 ,其中
,其中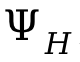 為人與人符號距離。
為人與人符號距離。
然後,當優化損失低於根據實驗經驗確定的閾值時,接受這一生成結果,同時透過添加人類節點來更新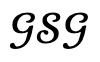 ;否則認為生成結果不可信,並透過屏蔽對應的物體節點來更新
;否則認為生成結果不可信,並透過屏蔽對應的物體節點來更新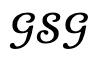 。
。
值得注意的是,這種更新方式建立了每一代結果與前一代結果之間的關係,避免了一定程度的擁擠,並且與簡單的多次生成相比空間分佈更合理和互動更逼真。
以上過程可以表達為:
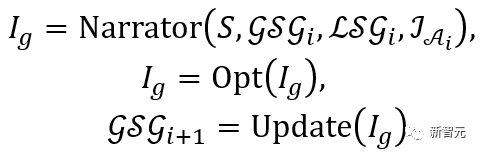
實驗結果
鑑於目前現有的方法無法直接從文字描述中自然可控地產生人與場景的交互,我們將PiGraph [1]、POSA [2]、COINS [3] 進行合理擴展,使其適用於文字描述,並使用相同的資料集對它們的官方模型進行訓練。經過修改後,我們將這些方法命名為PiGraph-Text、POSA-Text和COINS-Text
# 圖片
圖片
圖3 不同方法的定性對比結果
在圖3中展示了Narrator與三種基線的定性比較結果。由於PiGraph-Text的表現形式限制,它有更嚴重的穿透問題
POSA-Text在最佳化過程中往往會陷入局部最小值,從而產生不良的交互接觸。 COINS-Text將動作綁定到特定物體上,缺乏對場景的全局感知,導致與未指定物體的穿透,並且難以處理複雜的空間關係。
相較之下,Narrator可以根據不同層次的文字描述,正確推理空間關係,剖析多動作下的身體狀態,從而獲得更好的生成效果。
在定量比較方面,如表1所示,Narrator在五個指標上都優於其他方法,顯示出該方法產生的結果具有更準確的文本一致性和更優秀的物理合理性。
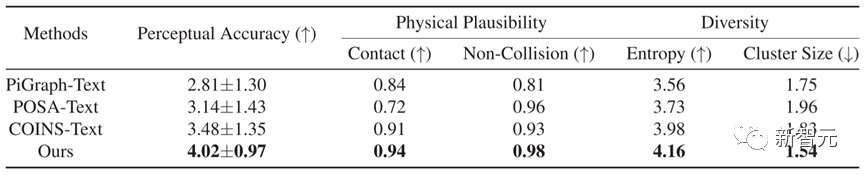 表1 不同方法的量化比較結果
表1 不同方法的量化比較結果
除此之外,作者也提供了詳細的比較與分析來更好地了解所提出的MHSI策略的有效性。
考慮到目前還沒有針對MHSI的工作,他們選擇了一種直接的方法作為基線,即與用COINS按順序生成和優化的方法。
為了進行公平比較,同樣為其引入了人為碰撞損失。圖4和表2分別展示了定性和定量結果,都有力證明了作者所提出的策略在MHSI上語義一致和物理合理的優勢。
 圖4 與用COINS 依序產生和最佳化的方法進行的MHSI定性比較
圖4 與用COINS 依序產生和最佳化的方法進行的MHSI定性比較

作者簡介

#研究的主要方向包括三維視覺、電腦視覺以及人與場景互動生成

#主要研究方向:三維視覺、電腦視覺、人體與衣物重建

研究方向主要包括三維視覺、電腦視覺和圖像生成

研究方向主要集中在以人為中心的電腦視覺和圖形學

主要研究方向:電腦圖形學,三維視覺與計算攝影
個人主頁連結:https://liuyebin.com/
#
研究的主要方向:三維視覺、智慧重建與生成
個人主頁:http://cic .tju.edu.cn/faculty/likun
參考文獻:
[1] Savva M, Chang A X, Hanrahan P, 等. Pigraphs: 從觀察中學習互動快照[J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 1-12.
[2] Hassan M, Ghosh P, Tesch J, et al. Populating 3D scenes by learning human-scene interaction[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 14708-14718.
[3] Zhao K, Wang S, Zhang Y, et al . Compositional human-scene interaction synthesis with semantic control[C]. European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 311-327.
以上是「人與場景交互生成」新突破!天大、清華發布Narrator:文字驅動,自然可控|ICCV 2023的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 清華鏡像來源完美指南:讓你的軟體安裝更流暢
Jan 16, 2024 am 10:08 AM
清華鏡像來源完美指南:讓你的軟體安裝更流暢
Jan 16, 2024 am 10:08 AM
清華鏡像來源使用攻略:讓你的軟體安裝更暢快,需要具體程式碼範例在日常使用電腦的過程中,我們經常需要安裝各種軟體來滿足不同的需求。不過,在安裝軟體時,我們常常會遇到下載速度慢、無法連線等問題,尤其是在使用國外鏡像來源的時候。為了解決這個問題,清華大學提供了一個鏡像來源,它提供了豐富的軟體資源,而且下載速度非常快。下面,就讓我們一起來了解清華鏡像來源的使用攻略。首先,
 Java中的ClassCastException異常在什麼場景下出現?
Jun 25, 2023 pm 09:19 PM
Java中的ClassCastException異常在什麼場景下出現?
Jun 25, 2023 pm 09:19 PM
Java是一種強型別語言,執行時要求資料型別匹配。由於Java的類型轉換機制嚴格,如果程式碼中出現資料類型不符的情況,就會出現ClassCastException異常。 ClassCastException異常是Java語言中非常常見的異常之一,本文將介紹ClassCastException異常的產生原因以及如何避免它。什麼是ClassCastExcepti
 Linux系統這些壓測工具,你有用過嗎?
Mar 21, 2024 pm 04:12 PM
Linux系統這些壓測工具,你有用過嗎?
Mar 21, 2024 pm 04:12 PM
身為維運人員,你是否遇過這種場景?需要用工具測試系統cpu或記憶體佔用高來觸發告警,或透過壓測測試服務的同時能力。身為維運工程師,也可以透過這些指令復現故障場景。那麼透過本文可以讓你掌握常用的測試指令和工具。一、前言在某些情況下,為了定位和復現專案中的問題,必須使用工具進行系統性壓力測試,以模擬和還原故障場景。這時測試或壓測工具就變得特別重要。接下來,我們將根據不同的場景來探討這些工具的使用。二、測試工具2.1網路限速工具tctc是Linux中用來調整網路參數的命令列工具,可用來模擬各種網
 兩句話,讓AI生成VR場景!還是3D、HDR全景圖的那種
Apr 12, 2023 am 09:46 AM
兩句話,讓AI生成VR場景!還是3D、HDR全景圖的那種
Apr 12, 2023 am 09:46 AM
大數據摘要出品作者:Caleb最近,ChatGPT可以說是火得不要不要的。 11月30日,OpenAI發布聊天機器人ChatGPT,並免費向公眾開放進行測試以來,在國內已經被玩出了花。和機器人對話,就是讓機器人去執行某個指令,比如說輸入關鍵字讓AI產生對應的畫面。這好像也不是什麼稀奇的事了,OpenAI在4月不是還更新了DALL-E的新版本嗎? OpenAI,how old are you? (怎麼老是你?)如果文摘菌說生成的是3D畫面,還是HDR全景圖那種,或是基於VR的影像內容呢?最近,新加坡
 清華光學 AI 登 Nature!物理神經網絡,反向傳播不需要了
Aug 10, 2024 pm 10:15 PM
清華光學 AI 登 Nature!物理神經網絡,反向傳播不需要了
Aug 10, 2024 pm 10:15 PM
用光訓練神經網絡,清華成果最新登上了Nature!無法應用反向傳播演算法怎麼辦?他們提出了一種全前向模式(FullyForwardMode,FFM)的訓練方法,在實體光學系統中直接執行訓練過程,克服了傳統基於數位電腦模擬的限制。簡單點說,以前需要對物理系統進行詳細建模,然後在電腦上模擬這些模型來訓練網路。而FFM方法省去了建模過程,讓系統直接使用實驗數據進行學習和最佳化。這也意味著,訓練不需要再從後向前檢查每一層(反向傳播),而是可以直接從前向後更新網路的參數。打個比方,就像拼圖一樣,反向傳播
 學會使用Kafka常用指令,靈活應對各種場景的學習必備
Jan 31, 2024 pm 09:22 PM
學會使用Kafka常用指令,靈活應對各種場景的學習必備
Jan 31, 2024 pm 09:22 PM
學習Kafka必備:掌握常用指令,輕鬆應付各種場景1.建立Topicbin/kafka-topics.sh--create--topicmy-topic--partitions3--replication-factor22.列出Topicbin/kafka-topics.sh --list3.查看Topic詳細資料bin/kafka-to
 我們一起聊聊大模型的模型融合方法
Mar 11, 2024 pm 01:10 PM
我們一起聊聊大模型的模型融合方法
Mar 11, 2024 pm 01:10 PM
在先前的實務中,模型融合被廣泛運用,尤其在判別模型中,它被認為是一種能夠穩定提升效能的方法。然而,對於生成語言模型而言,由於其涉及解碼過程,其運作方式並不像判別模型那樣直截了當。另外,由於大模型的參數量增大,在參數規模更大的場景,簡單的集成學習可以考慮的方法相比低參數的機器學習更受限制,比如經典的stacking,boosting等方法,因為堆疊模型的參數問題,無法簡單拓展。因此針對大模型的整合學習需要仔細考慮。以下我們來講解五種基本的整合方法,分別是模型整合、機率整合、嫁接學習、眾包投票、MOE
