

LLaMA微調顯存需求減半,清華提出4位元優化器

大模型的訓練和微調對顯存要求很高,最佳化器狀態是顯存主要開銷之一。近日,清華大學朱軍、陳鍵飛團隊提出了用於神經網路訓練的 4 位元優化器,節省了模型訓練的記憶體開銷,同時達到與全精度優化器相當的準確率。
4 位元優化器在眾多預訓練和微調任務上進行了實驗,在保持準確率無損的情況下可將微調LLaMA-7B 的顯存開銷降低多達57% 。
論文:https://arxiv.org/abs/2309.01507
程式碼:https://github.com/thu-ml /low-bit-optimizers
模型訓練的記憶體瓶頸
從GPT-3,Gopher 到LLaMA,大模型有更好的性能已成為業界的共識。但相較之下,單一 GPU 的顯存大小卻成長緩慢,這讓顯存成為了大模型訓練的主要瓶頸,如何在有限的 GPU 記憶體下訓練大模型成為了一個重要的難題。
為此,我們首先需要明確消耗顯存的來源有哪些。事實上有三類,分別是:
1. “資料顯存”,包括輸入的資料和神經網路每層輸出的活化值,它的大小直接受到batch size 以及影像解析度/ 上下文長度的影響;
2. “模型顯存”,包括模型參數,梯度,以及最佳化器狀態(optimizer states),它的大小與模型參數數量呈正比;
3. “臨時顯存”,包括GPU kernel 計算時所用到的臨時記憶體和其他快取等。隨著模型規模的增加,模型顯存的佔比逐漸增加,成為主要瓶頸。
優化器狀態的大小由使用哪個最佳化器決定。目前,訓練 Transformer 往往使用 AdamW 優化器,它們在訓練過程中需要儲存並更新兩個優化器狀態,即一階和二階矩(first and second moments)。如果模型參數量為 N,那麼 AdamW 中最佳化器狀態的數量為 2N,這顯然是一筆極大的顯存開銷。
以LLaMA-7B 為例,模型包含的參數數量大約7B,如果使用全精度(32 位元)的AdamW 優化器對它進行微調,那麼優化器狀態所佔用的記憶體大小約為52.2GB。此外,雖然樸素的 SGD 優化器不需要額外狀態,節省了優化器狀態所佔用的內存,但是模型的性能難以保證。因此,本文主要關注如何減少模型記憶體中的優化器狀態,同時確保優化器的效能不會受損。
節省最佳化器記憶體的方法
目前在訓練演算法方面,節省最佳化器顯存開銷的方法主要有三類:
1. 透過低秩分解(Factorization)的思路對最佳化器狀態進行低秩近似(low-rank approximation);
2. 透過只訓練一小部分參數來避免保存大多數的優化器狀態,例如LoRA;
3. 基於壓縮(compression)的方法,使用低精度數值格式來表示優化器狀態。
特別的,Dettmers et al. (ICLR 2022)針對SGD with momentum 和AdamW 提出了相應的8 位元優化器,透過使用分塊量化(block-wise quantization)和動態指數數值格式(dynamic exponential numerical format)的技術,在語言建模、圖像分類、自監督學習、機器翻譯等任務上達到了與原有的全精度優化器相匹配的效果。
本文在基礎上,將優化器狀態的數值精度進一步降低至 4 位元,提出了針對不同優化器狀態的量化方法,最終提出了 4 位元 AdamW 優化器。同時,本文探討了將 壓縮和低秩分解方法結合的可能性,提出了 4 位元 Factor 優化器,這種混合式的優化器同時享有好的效能和更好的記憶體高效性。本文在眾多經典的任務上對 4 位元優化器進行了評估,包括自然語言理解、影像分類、機器翻譯和大模型的指令微調。
在所有的任務上,4 位元優化器達到了與全精度優化器可比的效果,同時能夠佔用更少的記憶體。
問題設定
基於壓縮的記憶體高效優化器的框架
首先,我們需要了解如何將壓縮操作引入到通常使用的最佳化器中,這由演算法 1 給出。其中,A 是一個基於梯度的最佳化器(例如 SGD 或 AdamW)。此最佳化器輸入現有的參數 w,梯度 g 和最佳化器狀態 s,輸出新的參數和最佳化器狀態。在演算法 1 中,全精度的 s_t 是暫時存在的,而低精度的 (s_t ) ̅ 會持久地保存在 GPU 記憶體中。這種方式能夠節省顯存的重要原因是:神經網路的參數往往由每層的參數向量拼接而成。因此,優化器更新也是逐層/ 張量進行,進而在演算法1 下,最多只有一個參數的優化器狀態以全精度的形式留在記憶體中,其他層對應的優化器狀態都處於被壓縮的狀態。

主要的壓縮方法:量化(quantization)
量化是以低精度數值來表示高精度資料的技術,本文將量化的操作解耦為兩部分:歸一化(normalization)和映射(mapping),從而能夠更加輕量級的設計並實驗新的量化方法。歸一化和映射兩個操作依次以逐元素的形式施加在全精度資料上。歸一化負責將張量中的每個元素投射到單位區間,其中張量歸一化(per-tensor normalization)和分塊歸一化(block-wise normalization)分別如下定義:
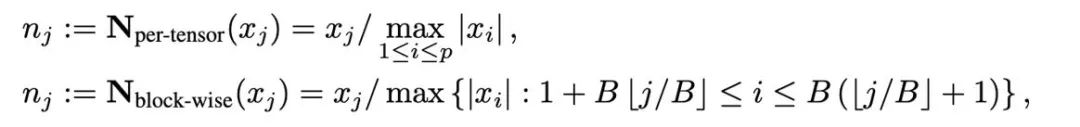
不同歸一化方法的粒度不同,處理例外值的能力會有所區別,同時帶來的額外記憶體開銷也不同。而映射(mapping)操作負責將歸一化的數值映射到低精度能夠表示的整數。正式地講,給定位寬b(即量化後每個數值使用b 位元來表示)和預先定義的函數T
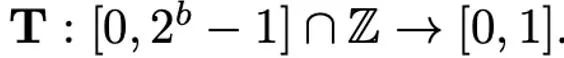
##對應操作定義為:
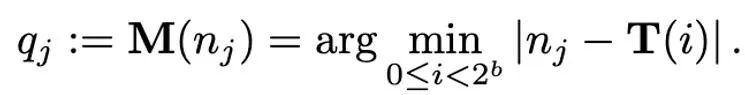
因此,如何設計恰當的T 對於減少量化誤差有很重要的作用。本文主要考慮線性映射(linear)和動態指數映射(dynamic exponent)。最後,去量化的過程就是依序施加映射(mapping)和歸一化(normalization)的逆算子。
一階矩的壓縮方法
以下主要針對AdamW 的最佳化器狀態(一階矩和二階矩)提出不同的量化方法。對於一階矩,本文的量化方法主要基於 Dettmers et al. (ICLR 2022)的方法,使用分塊歸一化(區塊大小為 2048)和動態指數映射。
在初步的實驗中,我們直接將位寬從8 位元降低至4 位元,發現一階矩對於量化十分穩健,在許多任務上已經達到匹配的效果,但也在一部分任務上出現效能上的損失。為了進一步提高性能,我們仔細研究了一階矩的模式,發現在單一張量中存在許多異常值。
先前的工作對於參數和激活值的異常值的模式已有一定的研究,參數的分佈較為平滑,而激活值則具有按照 channel 分佈的特點。本文發現,優化器狀態中異常值的分佈較為複雜,其中有些張量的異常值分佈在固定的行,而另外一些張量的異常值分佈在固定的列。
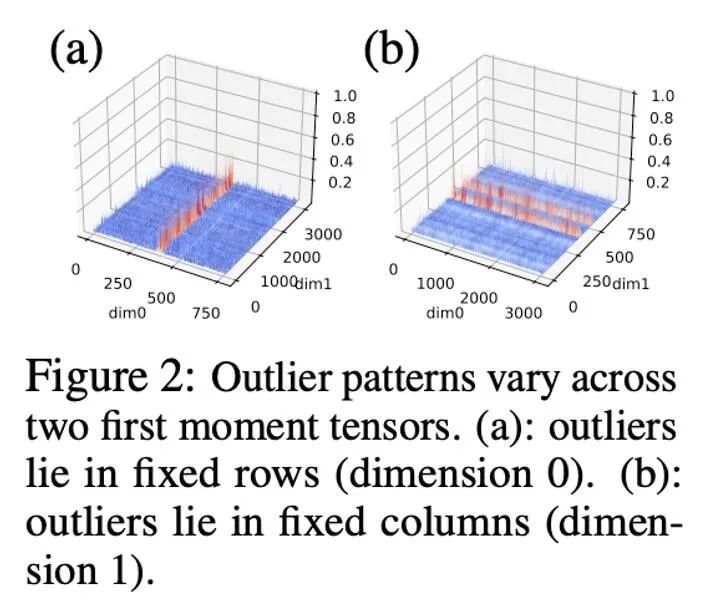
對於異常值依列分佈的張量,以行為優先的分塊歸一化可能會遇到困難。因此,本文提出採用較小的區塊,區塊大小為 128,這能夠在減少量化誤差的同時使額外的記憶體開銷保持在可控的範圍內。下圖展示了不同區塊大小的量化誤差。
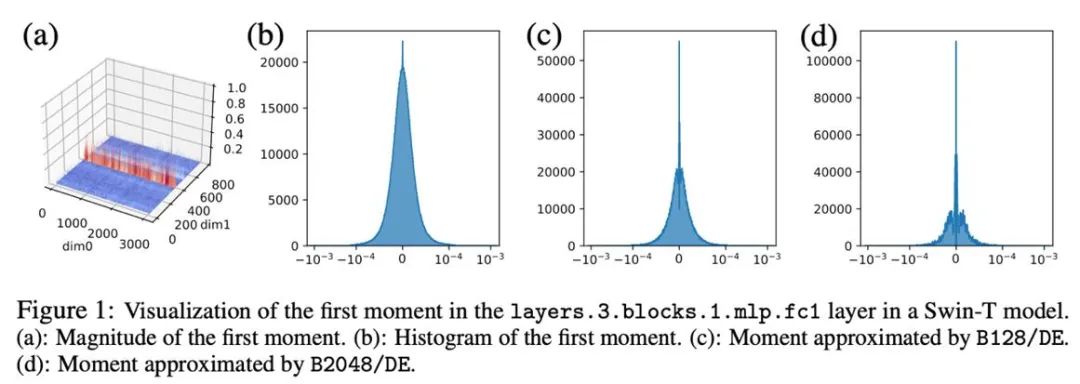 #
#
二階矩的壓縮方法
與一階矩相比,二階矩的量化更困難並且會帶來訓練的不穩定性。本文確定了零點問題是量化二階矩的主要瓶頸,此外針對病態的異常值分佈提出了改進的歸一化方法:rank-1 normalization。本文也嘗試了對二階矩的分解方法(factorization)。
零點問題
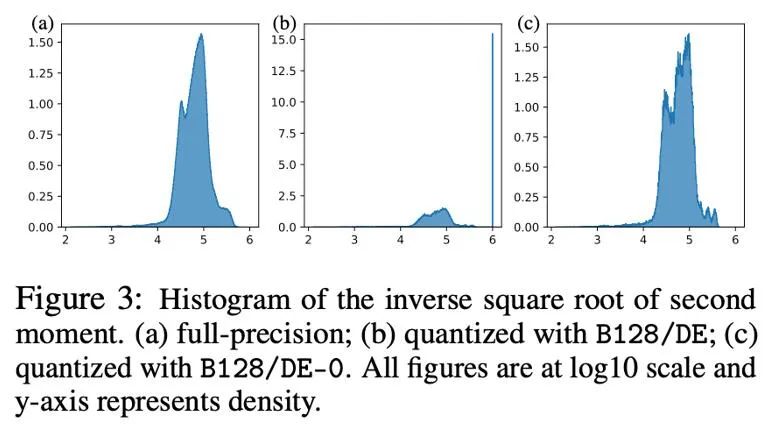
在參數、激活值、梯度的量化中,零點往往是不可缺少的,且在也是量化後頻率最高的點。但是,在 Adam 的迭代公式中,更新的大小正比於二階矩的 -1/2 次方,因此在零附近的範圍內改變會極大影響更新的大小,進而造成不穩定。
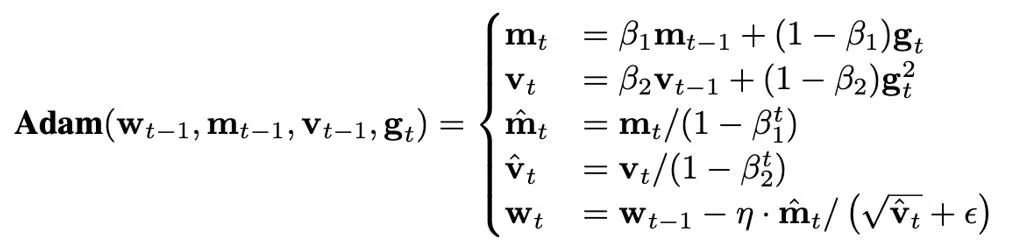
下圖以直方圖的形式展示了量化前後Adam 二階矩-1/2 次方的分佈, 即h (v) =1/(√v 10^(-6) )。如果將零點納入(圖 b),那麼大多數值都被推到了 10^6, 從而導致極大的近似誤差。一個簡單的方法是在動態指數映射中將零點移除,在這樣做之後(圖 c),對二階矩的近似變得更加精確。在實際情況中,為了有效利用低精度數值的表達能力,我們提出採用移除零點的線性映射,在實驗中取得了很好的效果。
Rank-1 歸一化
基於一階矩和二階矩複雜的異常值分佈,並受SM3 優化器所啟發,本文提出了一種新的歸一化方法,命名為rank-1 歸一化。對一個非負的矩陣張量x∈R^(n×m), 它的一維統計量定義為:
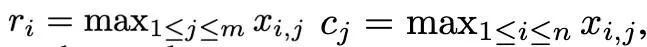
#然後rank -1 歸一化可以被定義為:
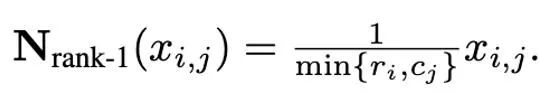
#rank-1 歸一化以更細緻的方式利用了張量的一維訊息,能夠更聰明且有效地處理按行分佈或按列分佈的異常值。此外,rank-1 歸一化能夠簡單的推廣到高維張量中,並且隨著張量規模的增加,它所產生的額外記憶體開銷要小於分塊歸一化。
此外,本文發現Adafactor 最佳化器中對於二階矩的低秩分解方法能夠有效的避免零點問題,因此也對低秩分解和量化方法的結合進行了探索。下圖展示了一系列針對二階矩的消融實驗,證實了零點問題是量化二階矩的瓶頸,同時也驗證了 rank-1 歸一化,低秩分解方法的有效性。
實驗結果
#研究根據所觀察到的現象和使用的方式,最終提出兩種低精度優化器:4 位元AdamW 和4 位元Factor,並與其他優化器進行對比,包括8 位元AdamW,Adafactor, SM3。研究選擇在廣泛的任務上進行評估,包括自然語言理解、影像分類、機器翻譯和大模型的指令微調。下表展示了各優化器在不同任務上的表現。
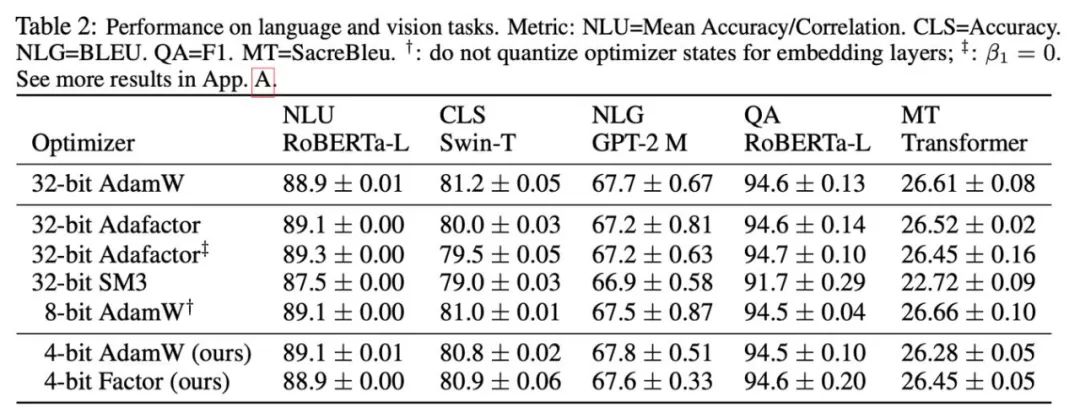
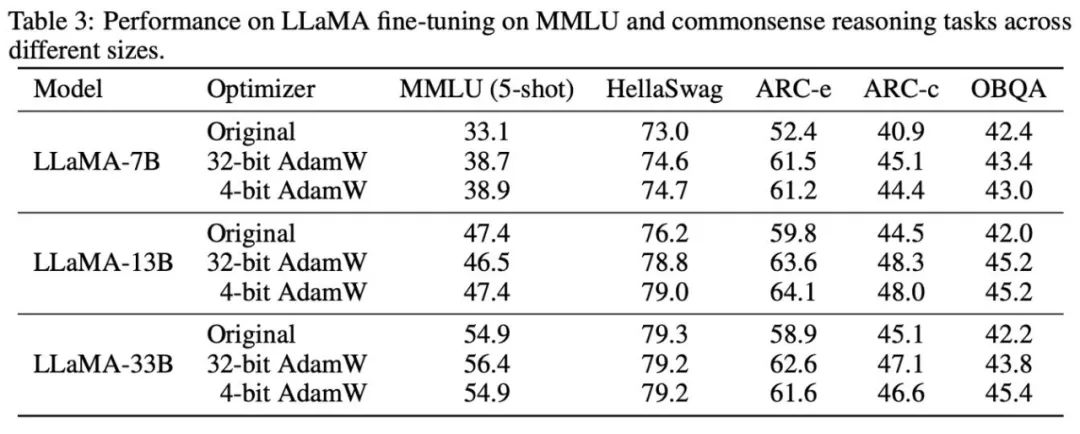
#可以看到,在所有的微調任務上,包括NLU,QA,NLG,4 位元優化器可以匹配甚至超過32 位元AdamW,同時在所有的預訓練任務上,CLS,MT,4 位元優化器達到與全精度可比的水平。從指令微調的任務中可以看到,4 位元 AdamW 並不會破壞預訓練模型的能力,同時能較好地使它們獲得遵守指令的能力。
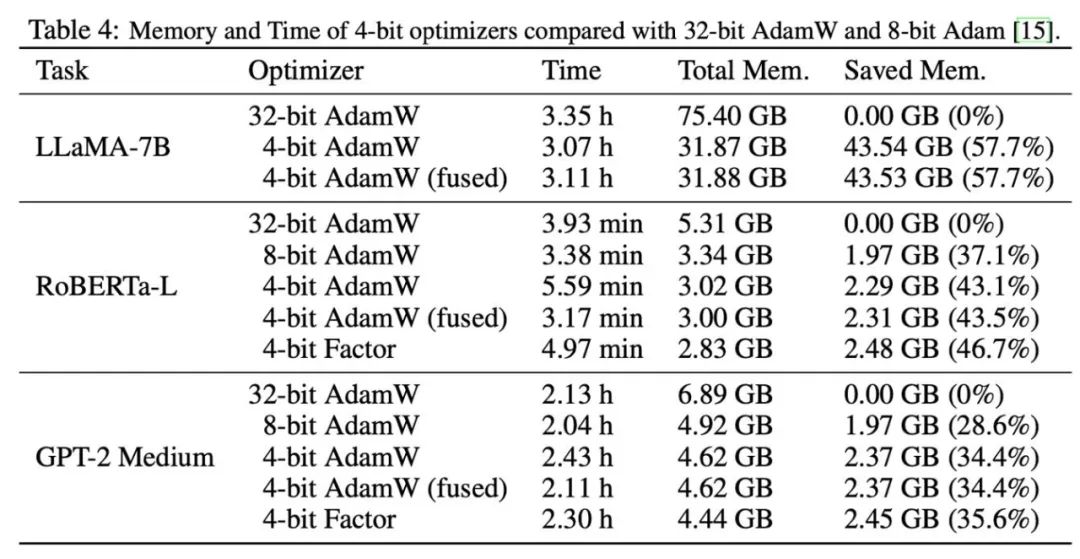
之後,我們測試了 4 位元優化器的記憶體和運算效率,結果如下表所示。相較於 8 位元優化器,本文提出的 4 位元優化器能夠節省更多內存,在 LLaMA-7B 微調的實驗中最高節省 57.7%。此外,我們提供了 4 位元 AdamW 的融合算符版本,它能夠在節省記憶體的同時不影響運算效率。對於 LLaMA-7B 的指令微調任務,由於快取壓力減小,4 位元 AdamW 也為訓練帶來了加速效果。詳細的實驗設定和結果可參考論文連結。
取代一行程式碼即可在PyTorch 中使用
import lpmmoptimizer = lpmm.optim.AdamW (model.parameters (), lr=1e-3, betas=(0.9, 0.999))
我們提供了開箱即用的4 位元優化器,只需要將原有的優化器替換為4 位元優化器即可,目前支援Adam 和SGD 的低精度版本。同時,我們也提供了修改量化參數的接口,以支援客製化的使用場景。
以上是LLaMA微調顯存需求減半,清華提出4位元優化器的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
適合新手的加密貨幣數據平台有CoinMarketCap和非小號。 1. CoinMarketCap提供全球加密貨幣實時價格、市值、交易量排名,適合新手與基礎分析需求。 2. 非小號提供中文友好界面,適合中文用戶快速篩選低風險潛力項目。
 okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
OKX 交易所的詳細介紹如下:1) 發展歷程:2017 年創辦,2022 年更名為 OKX;2) 總部位於塞舌爾;3) 業務範圍涵蓋多種交易產品,支持 350 多種加密貨幣;4) 用戶遍布 200 餘個國家,千萬級用戶量;5) 採用多重安全措施保障用戶資產;6) 交易費用基於做市商模式,費率隨交易量增加而降低;7) 曾獲多項榮譽,如“年度加密貨幣交易所”等。
 各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
機構投資者應選擇Coinbase Pro和Genesis Trading等合規平台,關注冷存儲比例與審計透明度;散戶投資者應選擇幣安和火幣等大平台,注重用戶體驗與安全;合規敏感地區的用戶可通過Circle Trade和Huobi Global進行法幣交易,中國大陸用戶需通過合規場外渠道。
 大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
選擇大宗交易平台時應考慮以下因素:1. 流動性:優先選擇日均交易量超50億美元的平台。 2. 合規性:查看平台是否持有美國FinCEN、歐盟MiCA等牌照。 3. 安全性:冷錢包存儲比例和保險機制是關鍵指標。 4. 服務能力:是否提供專屬客戶經理和定制化交易工具。
 支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
優先選擇合規平台如OKX和Coinbase,啟用多重驗證,資產自託管可減少依賴:1. 選擇有監管牌照的交易所;2. 開啟2FA和提幣白名單;3. 使用硬件錢包或支持自託管的平台。
 數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
gate.io(全球版)核心優勢是界面極簡,支持中文,法幣交易流程直觀;幣安(簡版)核心優勢是全球交易量第一,簡版模式僅保留現貨交易;OKX(香港版)核心優勢是界面簡潔,支持粵語/普通話,衍生品交易門檻低;火幣全球站(香港版)核心優勢是老牌交易所,推出元宇宙交易終端;KuCoin(中文社區版)核心優勢是支持800 幣種,界面採用微信式交互;Kraken(香港版)核心優勢是美國老牌交易所,持有香港SVF牌照,界面簡潔;HashKey Exchange(香港持牌)核心優勢是香港知名持牌交易所,支持法
 幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
國內用戶適配方案包括合規渠道和本地化工具。 1. 合規渠道:通過OTC平台如Circle Trade進行法幣兌換,境內需通過香港或海外平台。 2. 本地化工具:使用幣圈網獲取中文資訊,火幣全球站提供元宇宙交易終端。
 數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
提供各種複雜的交易工具和市場分析。覆蓋 100 多個國家,日均衍生品交易量超 300 億美元,支持 300 多個交易對與 200 倍槓桿,技術實力強大,擁有龐大的全球用戶基礎,提供專業的交易平台、安全存儲解決方案以及豐富的交易對。
