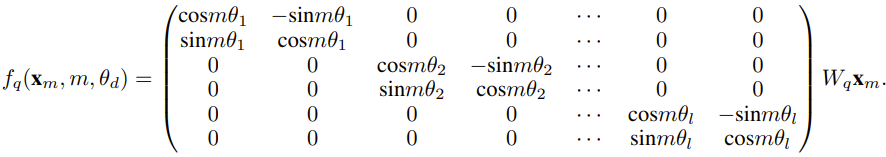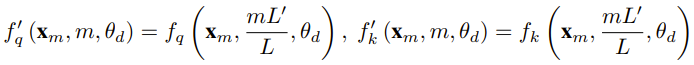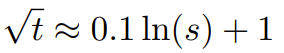基於 Transformer 的大型語言模型(LLM)已經展現出執行上下文學習(ICL)的強大能力,並且幾乎已經成為許多自然語言處理(NLP)任務的不二選擇。 Transformer 的自註意力機制可讓訓練高度並行化,從而能以分散式的方式處理長序列。 LLM 訓練所使用的序列的長度稱為其上下文視窗。
Transformer 的上下文視窗直接決定了可以提供範例的空間量,從而限制了其 ICL 能力。 如果模型的上下文視窗有限,那麼為模型提供穩健範例的空間就更少,而這些穩健範例正是執行 ICL 所用的。此外,當模型的上下文視窗特別短時,摘要等其它任務也會受到嚴重妨礙。 就語言本身的性質來說,token 的位置對有效建模來說至關重要,而自註意力由於其並行性,並不會直接編碼位置資訊。 Transformer 架構引入了位置編碼來解決這個問題。 原始的 Transformer 架構使用了絕對正弦波位置編碼,之後其被改進成了可學習的絕對位置編碼。自那以後,相對位置編碼方案又進一步提升了 Transformer 的效能。目前,最受歡迎的相對位置編碼是 T5 Relative Bias、RoPE、XPos 和 ALiBi。 位置編碼有一個重複的限制:無法泛化在訓練期間看到的上下文視窗。儘管 ALiBi 等一些方法有能力做一些有限的泛化,但還沒有方法能泛化用於顯著長於其預訓練長度的序列。 已經出現了一些試圖克服這些限制的研究結果。例如,有研究提出透過位置插值(PI)來稍微修改 RoPE 並在少量資料上微調來擴展上下文長度。 兩個月前,Nous Research 的 Bowen Peng 在 Reddit 上分享了一種解決思路,即透過納入高頻損失來實現「NTK 感知型插值」。這裡的 NTK 是指 Neural Tangent Kernel(神經正切核)。 其聲稱經過NTK 感知型擴展的RoPE 能讓LLaMA 模型的上下文視窗大幅擴展(超過8k),同時還無需任何微調,對困惑度造成的影響也極小。
- 論文:https://arxiv.org/abs/2309.00071
- 模式:https: //github.com/jquesnelle/yarn
#在這篇論文中,他們對NTK 感知型插值做出了兩點改進,它們分別著重於不同的面向:
- 部分 NTK 插值法,當使用少量較長上下文的資料微調後,模型能取得最佳表現。
研究者表示,在這篇論文誕生前,就已經有研究者將NTK 感知型插值和動態NTK 插值用於一些開源模型。例如 Code Llama(使用 NTK 感知型插值)和 Qwen 7B(使用動態 NTK 插值)。 在這篇論文中,基於先前有關NTK 感知型內插、動態NTK 插值和部分NTK 插值的研究成果,研究者提出了YaRN(Yet another RoPE extensioN method),一種可以高效擴展使用旋轉位置嵌入(Rotary Position Embeddings / RoPE)的模型的上下文視窗的方法,可用於LLaMA、GPT-NeoX 和PaLM 系列模型。研究發現,只需使用原模型預訓練資料規模約 0.1% 量的代表性樣本進行微調,YaRN 就能實現目前最佳的上下文視窗擴展效能。 旋轉位置嵌入(Rotary Position Embeddings / RoPE)最早由論文《RoFormer: Enhanced transformer with rotary position embedding》引入,也是YaRN 的基礎。對於使用固定上下文長度預先訓練的LLM,如果使用位置內插(PI)來擴展上下文長度,則可以表示為:#可以看出PI 對所有RoPE 維度都會做同等延展。研究者發現 PI 論文中所描述的理論插值界限不足以預測 RoPE 和 LLM 內部嵌入之間的複雜動態。以下將描述研究者發現並解決的 PI 的主要問題,以便讀者了解 YaRN 中各種新方法的背景、起因和解決理由。 若只從訊息編碼的角度看RoPE,根據神經正切核(NTK)理論,如果輸入維度較低且對應的嵌入缺乏高頻分量,那麼深度神經網路難以學習高頻資訊。
為了解決在對 RoPE 嵌入插值時丟失高頻訊息的問題,Bowen Peng 在上述 Reddit 帖子中提出了 NTK 感知型插值。這種方法不會對 RoPE 的每個維度進行同等擴展,而是透過更少地擴展高頻和更多地擴展低頻來將插值壓力分散到多個維度。
在測試中,研究者發現在擴展未經微調的模型的上下文大小方面,這種方法優於 PI。但是,這種方法有一個重大缺點:由於它不只是一種插值方案,某些維度會被外推入一些「界外」值,因此使用 NTK 感知型插值進行微調的效果不如 PI。
更進一步說,由於有「界外」值,理論上的擴展因子就無法準確地描述真實的上下文擴展程度。在實踐中,對於給定的上下文長度擴展,必須將擴展值 s 設定得比期望的擴展值高一點。
對於RoPE 嵌入,有一個有趣的觀察:給定一個上下文大小L,存在某些維度d,其中的波長λ 長於預訓練階段見過的最大上下文長度(λ > L),這說明某些維度的嵌入可能在旋轉域中的分佈不均勻。
PI 和 NTK 感知型插值會平等地對待所有 RoPE 隱藏維度(就好像它們對網路有相同的效果)。但研究者透過實驗發現,網路會給某些維度不同於其它維度的待遇。如前所述,給定上下文長度 L,某些維度的波長 λ 大於或等於 L。由於當一個隱藏維度的波長大於或等於L 時,所有的位置配對會編碼一個特定的距離,因此研究者猜想其中的絕對位置資訊得到了保留;而當波長較短時,網路僅可獲得相對位置資訊.
當使用擴展比例s 或基礎變化值b' 來拉伸所有RoPE 維度時,所有token 都會變得彼此更接近,因為被一個較小量旋轉過的兩個向量的點積會更大。這種擴展會嚴重損害 LLM 理解其內部嵌入之間小的局部關係的能力。研究者猜測這種壓縮會導致模型對附近 token 的位置順序感到困惑,從而損害模型的能力。
為了解決這個問題,基於研究者觀察到的現象,他們選擇完全不對更高頻率的維度進行插值。
他們也提出,對於所有維度 d,r
使用這一小節所描述的技術,一種名為部分 NTK 插值的方法誕生了。這種改良版方法優於先前的 PI 和 NTK 感知型插值方法,其適用於無微調和已微調模型。因為此方法避免了對旋轉域分佈不均勻的維度進行外推,因此就避免了先前方法的所有微調問題。
當使用RoPE 插值方法無微調地擴展上下文大小時,我們希望模型在更長的上下文大小上慢慢地劣化,而不是在擴展度s 超過所需值時在整個上下文大小上完全劣化。
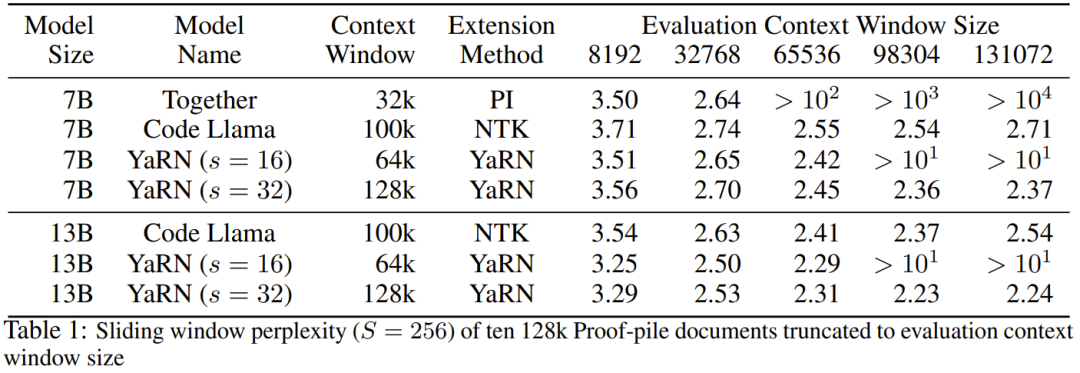
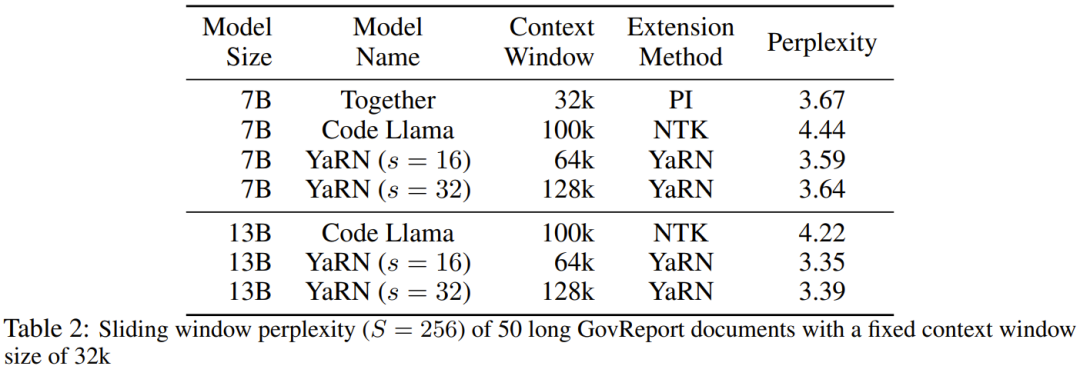
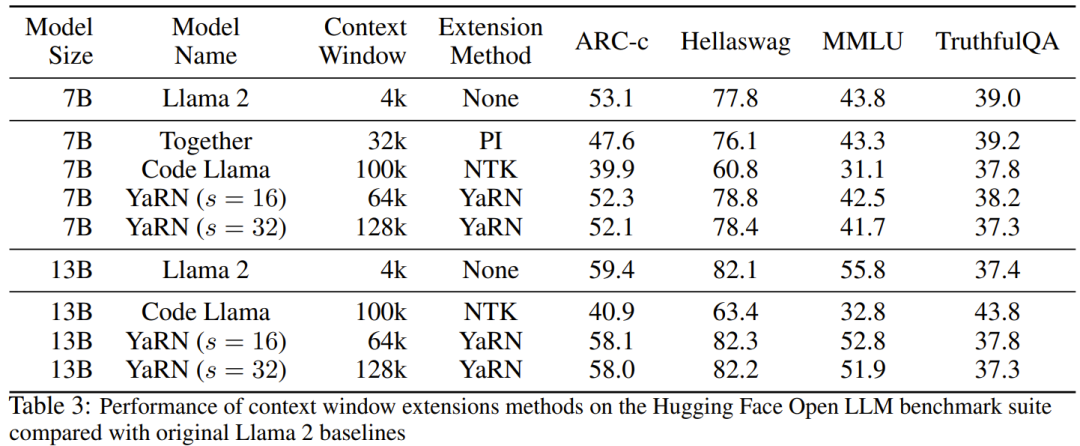
在動態 NTK 方法中,擴展度 s 是動態計算的。 在推理過程中,當上下文大小被超過時,就動態地更改擴展度s,這樣可讓所有模型在達到訓練的上下文限制L 時緩慢地劣化而不是突然崩潰式劣化。 即便解決了前面描述的局部距離問題,為了避免外推,也必須在閾值α 處插值更大的距離。直覺來看,這似乎不應該是個問題,因為全局距離無需高精度也能區分 token 位置(即網絡只需大概知道 token 是在序列的開頭、中間或末尾即可)。 但是,研究者發現:由於平均最小距離隨著token 數量的增加而變得更近,因此它會使注意力softmax 分佈變得更尖(即減少了注意力softmax 的平均熵)。換句話說,隨著長距離衰減的影響因插值而減弱,網路會「更關注」更多 token。這種分佈的轉變會導致 LLM 輸出品質下降,這是與先前問題無關的另一個問題。 由於當RoPE 嵌入插值到更長的上下文大小時,注意力Softmax 分佈中的熵會減少,因此研究者的目標是逆轉這種熵減(即增加註意力logit 的「溫度」)。這可以透過在應用 softmax 之前將中間注意力矩陣乘以溫度 t > 1 來完成,但由於 RoPE 嵌入被編碼為一個旋轉矩陣,就可以簡單地按常數因子 √t 來擴展 RoPE 嵌入的長度。這種「長度擴展」技巧讓研究可以不必修改注意力代碼,這能大幅簡化與現有訓練和推理流程的集成,並且時間複雜度僅有 O (1)。 由於這種 RoPE 插值方案對 RoPE 維度的內插法不均勻,因此很難計算相對於擴展度 s 所需的溫度比例 t 的解析解。幸運的是,研究者透過實驗發現:透過最小化困惑度,所有LLaMA 模型都遵循大致相同的擬合曲線:研究者是在LLaMA 7B、 13B、33B 和65B 上發現這個公式的。他們發現這個公式也能很好地適用於 LLaMA 2 模型(7B、13B 和 70B),差異很細微。這顯示這種熵增特性很常見,可以泛化到不同的模型和訓練資料。 這種最終修改方案產出了 YaRN 方法。新方法在已微調和未微調場景中都勝過之前所有方法,而且完全不需要修改推理程式碼。只需要修改一開始用於產生 RoPE 嵌入的演算法。 YaRN 如此簡單,使其可以在所有推理和訓練庫中輕鬆實現,包括與 Flash Attention 2 的兼容性。 #實驗顯示 YaRN 能成功擴充 LLM 的脈絡視窗。此外,他們僅訓練了 400 步就得到了這一結果,這差不多只有模型的原始預訓練語料庫的 0.1%,與先前的研究成果相比有大幅下降。這說明新方法具有很高的計算效率,沒有額外的推理成本。 為了評估所得到的模型,研究者計算了長文檔的困惑度,並在已有基準上進行了評分,結果發現新方法勝過所有其它上下文視窗擴充方法。 首先,研究者評估了上下文視窗增大時模型的表現表現。表 1 總結了實驗結果。 表 2 展示了在 50 個未截斷的 GovReport 文件(長度至少為 16k token)上的最終困惑度。 為了測試使用上下文擴展時模型性能的劣化情況,研究者使用Hugging Face Open LLM Leaderboard 套件評估了模型,並將其與LLaMA 2 基準模型以及公開可用的PI 和NTK 感知型模型的已有分數進行了比較。表 3 總結了實驗結果。 以上是想讓大模型在prompt中學習更多範例,這個方法能讓你輸入更多字符的詳細內容。更多資訊請關注PHP中文網其他相關文章!