

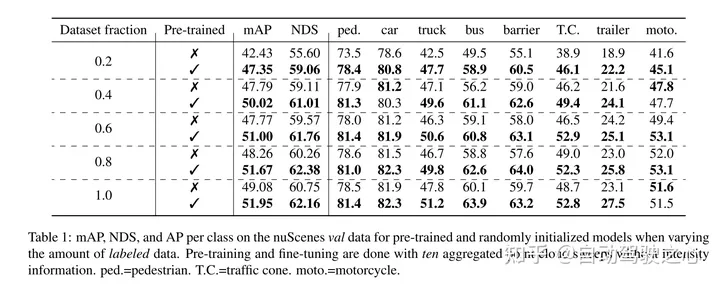
masked autoencoding已经成为文本、图像和最近的点云的transformer模型的一个成功的预训练范例。原始的汽车数据集适合进行自监督的预训练,因为与3d目标检测(od)等任务的标注相比,它们的收集成本通常较低。然而,针对点云的masked autoencoders的开发仅仅集中在合成和室内数据上。因此,现有的方法已经将它们的表示和模型定制为小而稠密的点云,具有均匀的点密度。在这项工作中,本文研究了在汽车设置中对点云进行的masked autoencoding,这些点云是稀疏的,并且在同一场景中,点云的密度在不同的物体之间可以有很大的变化。为此,本文提出了voxel-mae,这是一种为体素表示而设计的简单的masked autoencoding预训练方案。本文对基于transformer三维目标检测器的主干进行了预训练,以重建masked体素并区分空体素和非空体素。本文的方法提高了具有挑战性的nuscenes数据集上1.75 map和1.05 nds的3d od性能。此外,本文表明,通过使用voxel-mae进行预训练,本文只需要40%的带注释数据就可以超过随机初始化的等效数据。
本文提出了Voxel-MAE(一种在体素化的点云上部署MAE-style的自监督预训练的方法),并在大型汽车点云数据集nuScenes上对其进行了评估。本文的方法是第一个使用汽车点云Transformer主干的自监督预训练方案。
本文针对体素表示定制本文的方法,并使用一组独特的重建任务来捕捉体素化点云的特征。
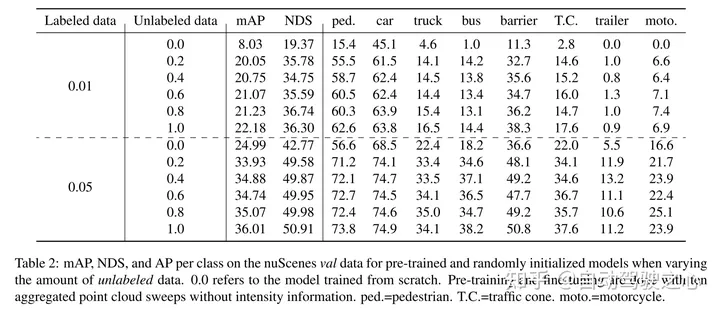
本文证明了本文的方法数据高效,并且减少了对带注释数据的需求。通过预训练,当只使用40%的带注释的数据时,本文的性能优于全监督的数据。
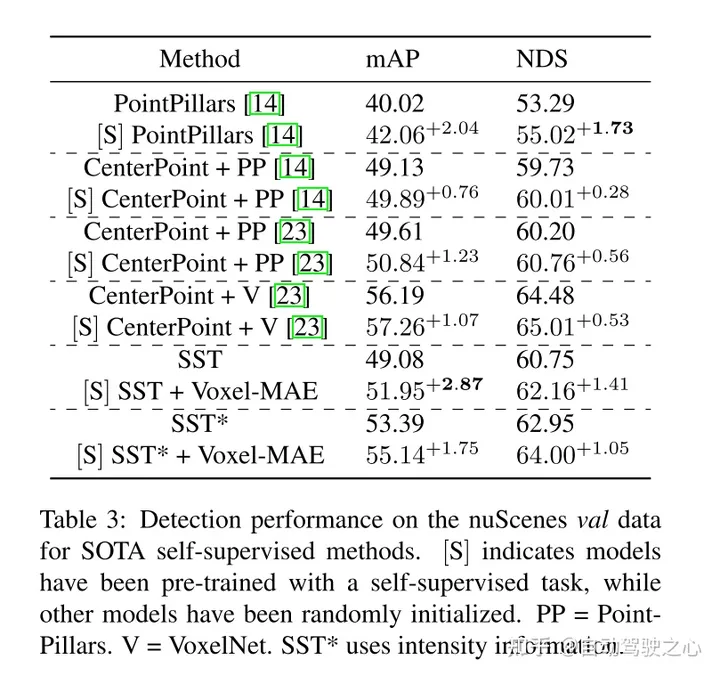
此外,本文发现Voxel-MAE在mAP中将基于Transformer检测器的性能提高了1.75个百分点,在NDS中将其性能提高了1.05个百分点,与现有的自监督方法相比,其性能提高了2倍。
这项工作的目的是将MAE-style的预训练扩展到体素化的点云。核心思想仍然是使用编码器从对输入的部分观察中创建丰富的潜在表示,然后使用解码器重构原始输入,如图2所示。经过预训练后,编码器被用作3D目标检测器的主干。但是,由于图像和点云之间的基本差异,需要对Voxel-MAE的有效训练进行一些修改。
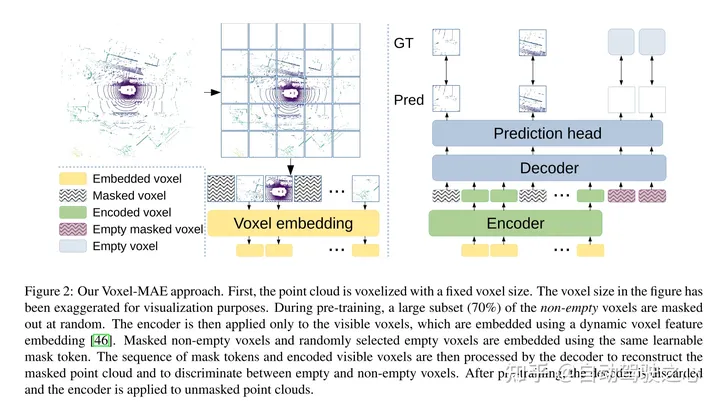
图2:本文的Voxel-MAE方法。首先,用固定的体素大小对点云进行体素化。图中的体素大小已被夸大,以实现可视化的目的。在训练前,很大一部分(70%)的非空体素被随机mask掉了。然后,编码器只应用于可见体素,使用嵌入[46]的动态体素特征嵌入这些体素。masked非空体素和随机选择的空体素使用相同的可学习mask tokens嵌入。然后,解码器对mask tokens序列和编码的可见体素序列进行处理,以重构masked点云并区分空体素和非空体素。在预训练之后,丢弃解码器,并将编码器应用于unmasked点云。

图1:MAE(左)将图像划分为固定大小的不重叠的patches。现有的masked点建模方法(中)通过使用最远点采样和k近邻创建固定数量的点云patches。本文的方法(右)使用非重叠体素和动态数量的点。
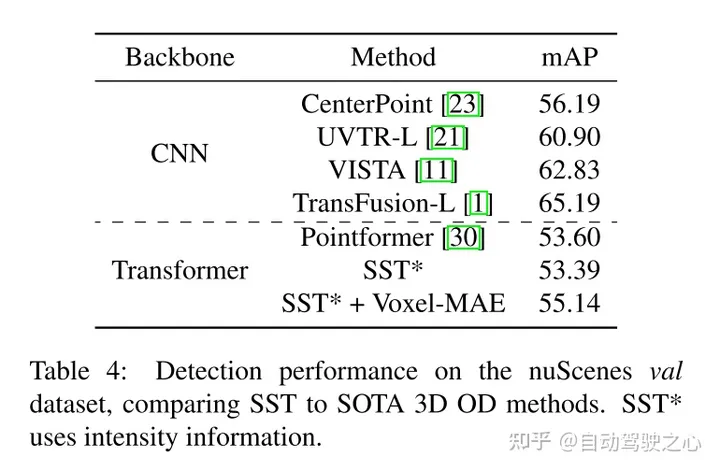
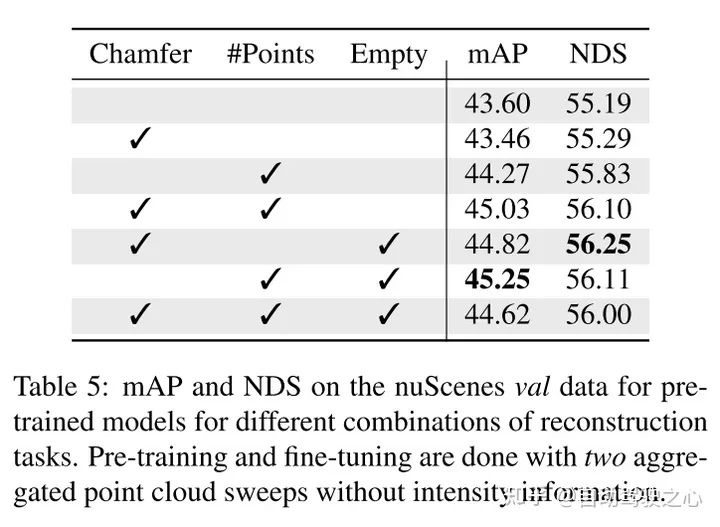
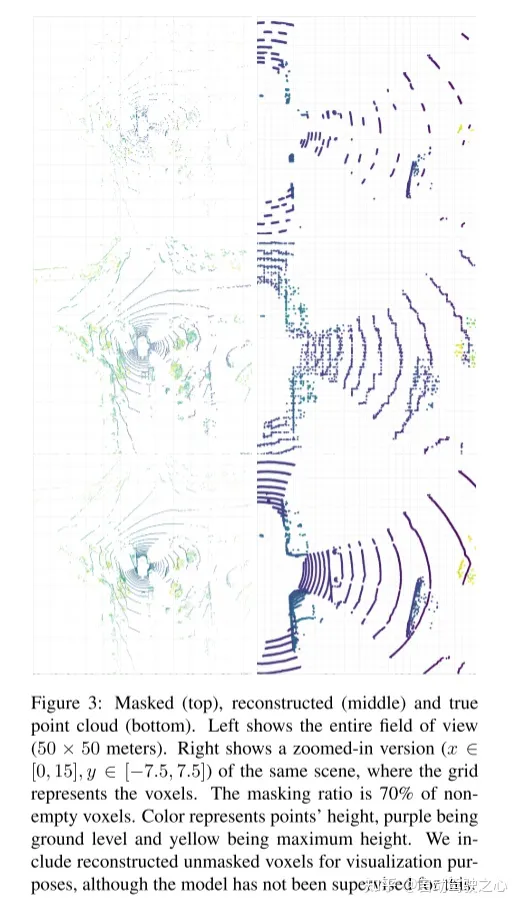
Hess G, Jaxing J, Svensson E, et al. Masked autoencoder for self-supervised pre-training on lidar point clouds[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 350-359.
以上就是用于激光雷达点云自监督预训练SOTA!的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 840
840























