

吳恩達力贊!哈佛、MIT學者用下棋證明:大型語言模型確實「理解」了世界

2021年,華盛頓大學語言學家Emily M. Bender發表了一篇論文,認為大型語言模型不過是「隨機鸚鵡」(stochastic parrots)而已,它們並不理解真實世界,只是統計某字詞出現的機率,然後像鸚鵡一樣隨機產生看起來合理的字句。
由於神經網路的不可解釋性,學術界也搞不清楚語言模型到底是不是隨機鸚鵡,各方觀點差異分歧極大。
由於缺乏廣泛認可的測試,模型是否能「理解世界」也成為了哲學問題而非科學問題。
最近,來自哈佛大學、麻省理工學院的研究人員共同發表了一項新研究Othello-GPT,在簡單的棋盤遊戲中驗證了內部表徵的有效性,他們認為語言模型的內部確實建立了一個世界模型,而不只是單純的記憶或統計,不過其能力來源還不清楚。

論文連結:https://arxiv.org/pdf/2210.13382.pdf
實驗過程非常簡單,在沒有任何奧賽羅規則先驗知識的情況下,研究人員發現模型能夠以非常高的準確率預測出合法的移動操作,捕捉棋盤的狀態。
吳恩達在「來信」專欄中對該研究表示高度認可,他認為基於該研究,有理由相信大型語言模型構建出了足夠複雜的世界模型,在某種程度上來說,確實理解了世界。
部落格連結:https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
不過吳恩達也表示,雖然哲學很重要,但這樣的爭論可能會無休無止,所以不如程式設計去吧!
棋盤世界模型
如果把棋盤想像成一個簡單的「世界」,並要求模型在對局中不斷決策,就可以初步測試出序列模型是否能夠學習到世界表徵。

研究人員選擇一個簡單的黑白棋遊戲奧賽羅(Othllo)作為實驗平台,其規則是在8*8棋盤的中心位置,先放入四個棋子,黑白各兩個;然後雙方輪流下子,在直線或斜線方向,己方兩子之間的所有敵子(不能包含空格)全部變為己子(稱為吃子) ,每次落子必須有吃子;最後棋盤全部佔滿,子多者為勝。
相比國際象棋來說,奧賽羅的規則簡單得多;同時棋類遊戲的搜尋空間足夠大,模型無法透過記憶完成序列生成,所以很適合測試模型的世界表徵學習能力。
Othello語言模型
研究人員首先訓練了一個GPT變體版語言模型(Othello-GPT),將遊戲腳本(玩家做出的一系列棋子移動操作)輸入到模型中,但模型沒有關於遊戲及相關規則的先驗知識。
模型也沒有被明確訓練以追求策略提升、贏得對局等,只是在產生合法奧賽羅移動操作時準確率比較高。
資料集
#研究人員使用了兩組訓練資料:
錦標賽(Championship)更關注數據質量,主要是從兩個奧賽羅錦標賽中專業的人類玩家採用的、更具戰略思考的移動步驟,但分別只收集到7605個和132921個遊戲樣本,兩個資料集並後以8:2的比例隨機分成訓練集(2000萬個樣本)和驗證集(379.6萬個)。
合成(Synthetic)更關注數據的規模,由隨機的、合法的移動操作組成,數據分佈不同於錦標賽數據集,而是均勻地從奧賽羅遊戲樹上採樣獲得,其中2000萬個樣本用於訓練,379.6萬個樣本用於驗證。
每場遊戲的描述由一串token組成,詞表大小為60(8*8-4)
模型和訓練
模型的架構為8層GPT模型,具有8個頭,隱藏維度為512
模型的權重完全隨機初始化,包含word embedding層,雖然表示棋盤位置的詞表內存在幾何關係(如C4低於B4),但這種歸納偏移並沒有明確表示出來,而是留給模型學習。
預測合法移動
模型的主要評估指標就是模型預測的移動操作是否符合奧賽羅的規則。
在合成資料集上訓練的Othello-GPT錯誤率為0.01%,在錦標賽資料集上的錯誤率為5.17%,相較之下,未經訓練的Othello -GPT的錯誤率為93.29%,也就是說這兩個資料集都某種程度上讓模型學會了遊戲規則。
一個可能的解釋是,模型記住了奧賽羅遊戲的所有移動操作。
為了驗證這個猜想,研究人員合成了一個新的資料集:在每場比賽開始時,奧賽羅有四個可能的開局棋位置(C5、D6、E3和F4),將所有C5開局的走法移除後作為訓練集,再將C5開局的資料作為測試,也就是移除了近1/4的博弈樹,結果發現模型錯誤率仍然只有0.02%
所以Othello-GPT的高性能並不是因為記憶,因為測試資料是訓練過程中完全沒見過的,那到底是什麼讓模型成功預測?
探索內部表徵
一個常用的神經網路內部表徵偵測工具是探針(probe),每個探針是分類器或回歸器,其輸入由網路的內部活化組成,並經過訓練以預測感興趣的特徵。
在這個任務中,為了偵測Othello-GPT的內部激活是否包含當前棋盤狀態的表徵,輸入移動序列後,用內部激活向量對下一個移動步驟進行預測。
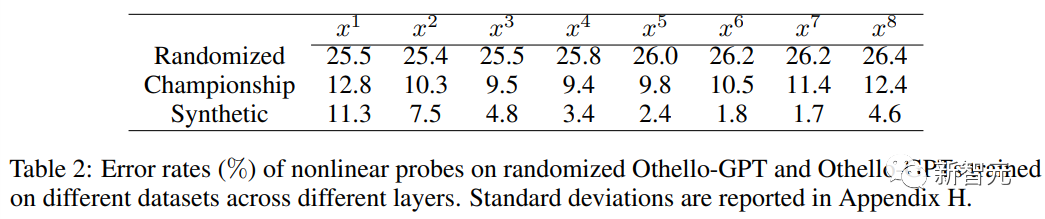
當使用線性探針時,訓練後的Othello-GPT內部表徵只比隨機猜測的準確率高了一點點。

當使用非線性探針(兩層MLP)時,錯誤率大幅下降,證明了棋盤狀態並不是以一種簡單的方式儲存在網路啟動中。
幹預實驗
為了確定模型預測和湧現世界表徵之間的因果關係,即棋盤狀態是否確實影響了網路的預測結果,研究人員進行了一組幹預(intervention)試驗,並測量由此產生的影響程度。
給定來自Othello-GPT的一組激活,用探針預測棋盤狀態,記錄相關聯的移動預測,然後修改激活,讓探針預測更新的棋盤狀態。
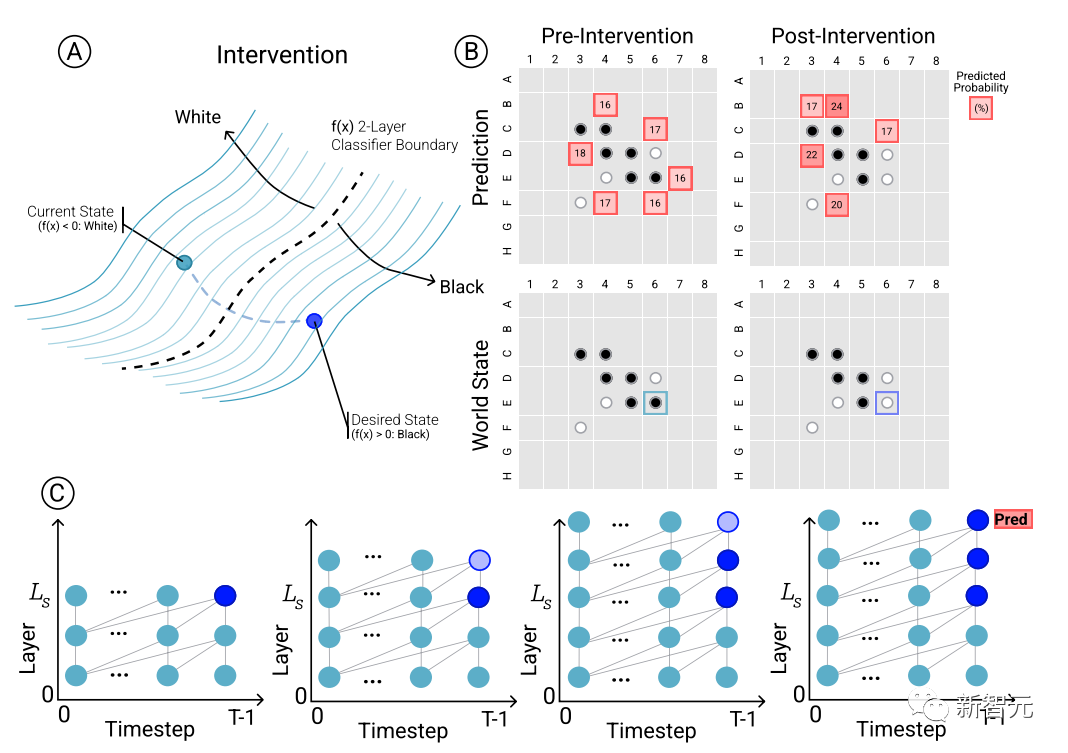
幹預操作包括將某個位置的棋子從白色變成黑色等,一個小的修改就會導致模型結果發現內部表徵能夠可靠地完成預測,即內部表徵與模型預測之間存在因果影響。
視覺化
除了介入實驗驗證內部表徵的有效性外,研究人員還將預測結果視覺化,比如說對於棋盤上的每個棋子,可以詢問模型如果用介入技術將該棋子改變,模型的預測結果會如何變化,對應預測結果的顯著性。
然後根據當前棋盤狀態的top1預測的顯著性對牌進行著色可視化,因為繪製出來的圖是基於網絡的潛空間而輸入,所以也可以叫做潛在顯著性圖(latent saliency map)。

可以看到,在合成和锦标赛数据集上训练的Othello-GPTs的top1预测的潜显著性图中都展现出了清晰的模式。
合成版Othello-GPT在合法操作位置中显示出了更高的显著性值,非法操作的显著性值明显更低,稍微有点经验的棋手都能看出模型的意图;
锦标赛版的显著图更复杂,虽然合法操作位置的显著性值比较高,但其他位置也显示出较高的显著性,可能是因为奥赛罗高手考虑更多的是全局特征。
以上是吳恩達力贊!哈佛、MIT學者用下棋證明:大型語言模型確實「理解」了世界的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通過使用 ALTER TABLE 語句為現有表添加新列。具體步驟包括:確定表名稱和列信息、編寫 ALTER TABLE 語句、執行語句。例如,為 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的語法為 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是數據類型,NOT NULL 指定是否允許空值,DEFAULT default_value 指定默認值。
 SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,釋放空間並重置標識列。禁用外鍵約束,防止級聯刪除。使用事務封裝操作,保證數據一致性。批量刪除大數據,通過 LIMIT 限制行數。清空後重建索引,提高查詢效率。
 SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
為新添加的列設置默認值,使用 ALTER TABLE 語句:指定添加列並設置默認值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默認值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 語句可用於清空 SQL 表,步驟如下:使用 DELETE 語句:DELETE FROM table_name;替換 table_name 為要清空的表的名稱。
 Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片是指分配的內存中存在無法再分配的小塊空閒區域。應對策略包括:重啟Redis:徹底清空內存,但會中斷服務。優化數據結構:使用更適合Redis的結構,減少內存分配和釋放次數。調整配置參數:使用策略淘汰最近最少使用的鍵值對。使用持久化機制:定期備份數據,重啟Redis清理碎片。監控內存使用情況:及時發現問題並採取措施。
 phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 創建數據表,以下步驟必不可少:連接到數據庫並單擊“新建”標籤。為表命名並選擇存儲引擎(推薦 InnoDB)。通過單擊“添加列”按鈕添加列詳細信息,包括列名、數據類型、是否允許空值以及其他屬性。選擇一個或多個列作為主鍵。單擊“保存”按鈕創建表和列。
 怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
創建Oracle數據庫並非易事,需理解底層機制。 1. 需了解數據庫和Oracle DBMS的概念;2. 掌握SID、CDB(容器數據庫)、PDB(可插拔數據庫)等核心概念;3. 使用SQL*Plus創建CDB,再創建PDB,需指定大小、數據文件數、路徑等參數;4. 高級應用需調整字符集、內存等參數,並進行性能調優;5. 需注意磁盤空間、權限和參數設置,並持續監控和優化數據庫性能。 熟練掌握需不斷實踐,才能真正理解Oracle數據庫的創建和管理。
