

國外GPT-3.5發布不到一年,國內文心一言發布不到半年,國內已經快轉到「百模大戰」。入局者既有大廠,也有大量新創公司。然而,大模型競爭激烈,企業用戶如果沒有練就一雙“火眼金睛”,很有可能踩坑,從而造成項目爛尾的後果。
一些大廠的大模型,例如文心大模型、通義千問、盤古大模型等,正逐漸拉開差距。 SuperCLUE最新評估清單顯示,文心一言已超越GPT-3.5turbo,GLM-130B等國產大模型也在名單前列。國內大模型從數量來看已成世界重要一極,從品質來看也迅速追上最先進的GPT-4。
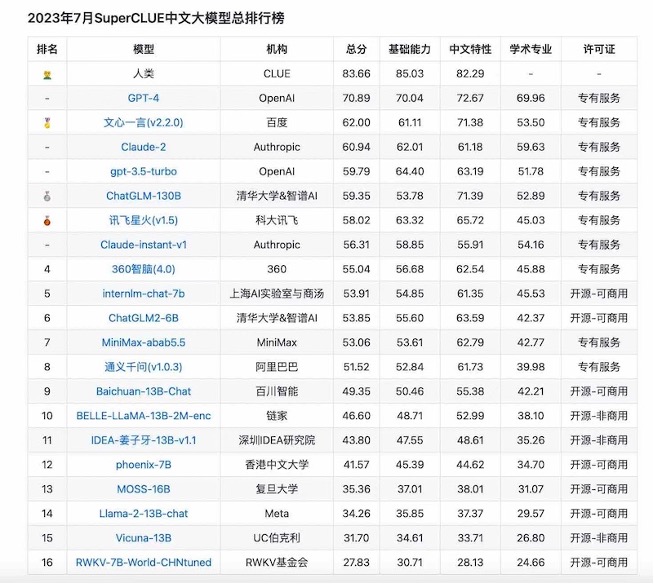
「百模大戰」的背後,業界均看好大模型技術創新推動產業數位化,創造出萬億級的市場價值。從當下來看,以文心一言、通義千問為代表的「大廠出品」大模型,在技術層面佔據優勢地位,在市場層面也透過建構產業生態,贏得了更多專案合作。
為何比起新創公司,大廠出品的大模型更強大、更受客戶青睞?在筆者看來,主要有三個原因:
首先,大模型最終要落地到產業場景應用,不是簡單的「一錘子買賣」。大廠作為更穩定、安全、可靠的象徵,普遍在AI技術底座方面有著充足的累積。企業客戶往往聚焦於應用層面,不一定具備強烈的底層AI技術累積。百度、阿里巴巴、華為等大廠已經打造了備受實戰考驗的AI底座,反觀新創公司,不乏技術創新的亮點於突破,但從全端AI技術底座積累和長期、穩定服務客戶角度來看,綜合能力於續航水平尚且存疑。
其次,大廠有更強的綜合實力投資大模型技術迭代開發。例如百度能調動全集團之力開發文心一言,最新迭代的文心大模型3.5,相較於3.0版本,推理速度提升17倍,模型效果提升超過50%。反觀風頭最勁的新創公司光年之外,不到半年就選擇了「賣身」美團。一些基於開源技術開發的大模型,缺乏足夠的底層技術累積和自主演進能力。
根據市場研究公司IDC最新發布的《AI大模型技術能力評估報告,2023》報告顯示,百度文心大模型3.5拿下12項指標的7個滿分,包括「演算法模型」、 「產業覆蓋」兩個關鍵指標,綜合評分第一;排名第二的阿里巴巴通義大模型則在11項指標中獲得6項滿分,是唯一一家「服務能力」滿分的廠商。
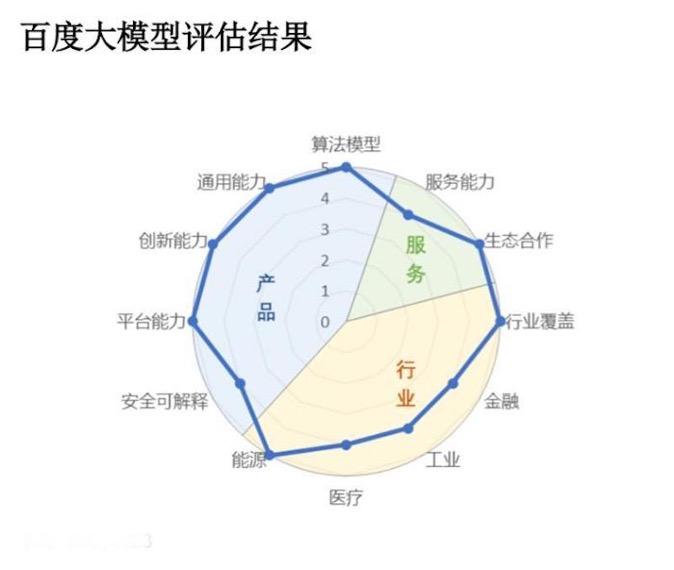
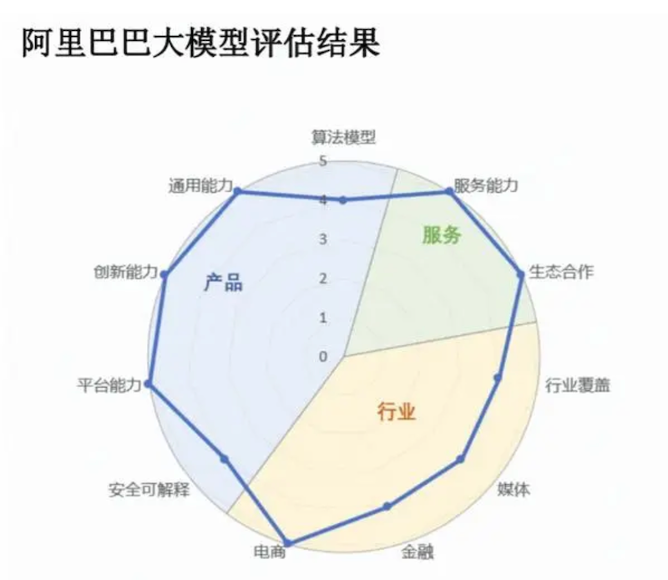
第三,大模型落地產業場景,後續的服務交付、維運等,對大廠而言是「駕輕就熟”,對新創公司則是艱難挑戰。大廠則能夠對垂直行業、重點客戶配備專屬服務團隊,免除客戶擁抱新技術的後顧之憂,而新創公司往往缺乏服務政企客戶的經驗積累,基於開源技術開發的大模型產品應用,要做好全流程服務是勉為其難。
綜上,大模型不僅看各種技術參數,更在於產業落地應用,看產業「Know-how」和成功經驗。大廠出品無論是技術開發、產業應用和服務,當下都佔有優勢。當然,「百模大戰」也許不是十多年前的「百團大戰」,最後只有2個勝利者。大模型還在發展初期,後續還有更多可能性,包括超越GPT-4以及更多歐美競品的可能性。
以上是企業「入坑」大模型,為什麼建議大廠出品?的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















