
手工小作坊,終究敵不過工廠流水線。
如果說,當下的生成式AI,是一個正在茁壯成長的孩子,那麼源源不斷的數據,就是其餵養其生長的食物。
數據標註是製作這「食物」的過程
然而,這過程真的很卷,很累人。
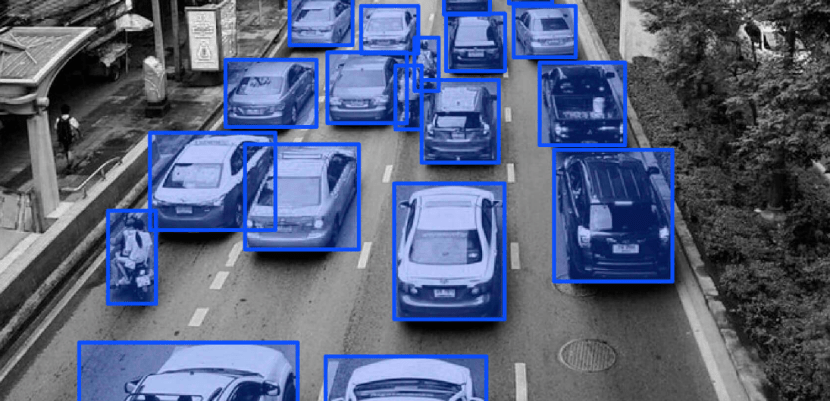
進行標註的「標註師」不僅需要反覆地辨識出影像中的各種物體、顏色、形狀等,有時甚至需要對資料進行清洗和預處理。
隨著人工智慧技術的不斷進步,人工資料標註的限制也越來越明顯。人工資料標註不僅耗費時間和精力,有時難以保證品質

為了解決這些問題,Google最近提出了一種名為AI反饋強化學習(RLAIF)的方法,透過使用大型模型取代人類進行偏好標註
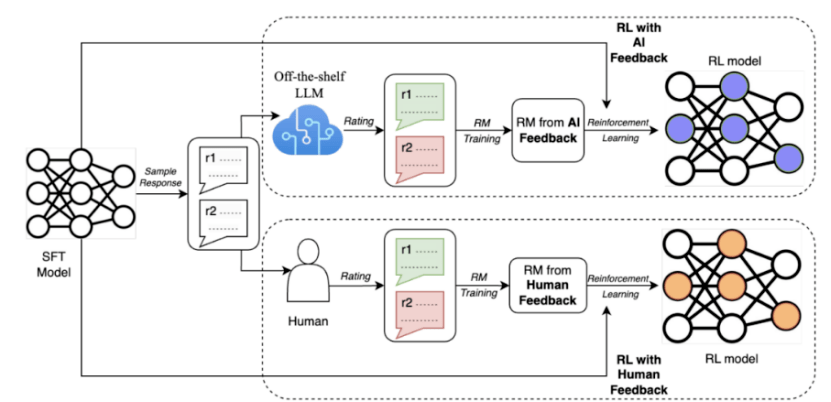
#研究結果顯示,RLAIF能夠在沒有依賴人類標註的情況下,達到與人類回饋強化學習(RLHF)相當的改進效果,兩者的勝率都是50%。此外,研究也發現,RLAIF和RLHF相比於監督微調(SFT)的基線策略都更優越
這些結果表明,RLAIF不需要依賴人工標註,是RLHF的可行替代方案。
如果這項技術將來真的被廣泛推廣和普及,那麼依賴人工「拉框」進行資料標註的許多企業是否將面臨絕境?
01 資料標註現況
如果要簡單地總結目前國內標註產業的現狀,那就是:勞動量大,但效率卻不太高,屬於費力不討好的狀態。
標註企業稱為AI領域的資料工廠,通常集中在東南亞、非洲或是中國的河南、山西、山東等人力資源豐富的地區。
為了降低成本,標註公司的老闆們會在縣城租一塊場地,放置電腦設備。一旦有訂單,他們就會在附近招募兼職人員來處理,如果沒有訂單,就會解散休息
簡單來說,這個工種有點類似馬路邊上的臨時裝潢工。

在工位上,系統會隨機給「標註師」一組數據,一般包含幾個問題和幾個答案。
之後,「標註師」需要先標註出這個問題屬於什麼類型,隨後給這些答案分別打分數並排序。
先前,人們在談論國產大模型與GPT-4等先進大模型的差距時,總結出了國內數據品質不高的原因。
為什麼資料品質不高?其中一部分原因在於資料標註的「管線」
目前,中文大模型的資料來源是兩類,一類是開源的資料集;一類是透過爬蟲爬來的中文網路資料。
中文大模型表現不夠好的主要原因之一就是網路資料質量,例如,專業人士在尋找資料的時候一般不會用百度。
因此,在面對一些較為專業、垂直的數據問題,例如醫療、金融等,就要與專業團隊合作。
可這時,問題又來了:對於專業團隊來說,在數據方面不僅回報週期長,而且先行者很有可能會吃虧。
例如,某家標註團隊花了很多錢和時間,做了很多數據,別人可能花很少的錢就可以直接打包買走。
面對這種“搭便車困境”,國內許多大型模型都陷入了數據雖然眾多,但質量卻不高的奇怪境地
既然如此,那目前國外一些較為領先的AI企業,如OpenAI,他們是怎麼解決這一問題的?

OpenAI在資料標註方面並沒有放棄使用廉價的密集勞動來降低成本
例如,先前就曝出其曾以2美元/小時的價格,僱用了大量肯亞勞工進行有毒資訊的標註工作。
然而,重要的區別在於如何解決資料品質和標註效率的問題
具體來說,OpenAI在這方面,與國內企業最大的不同,就在於如何降低人工標註的「主觀性」、「不穩定性」的影響。
02 OpenAI的方法 重新撰寫內容時,需要將語言改寫為中文,不需要出現原始句子
#為了降低這樣人類標註員的“主觀性”和“不穩定性”,OpenAI大致採用了兩個主要的策略:
1、人工回饋與強化學習結合;
#在重新寫作時,需要將原始內容轉換為中文。以下是重新寫作後的內容: 首先,讓我們來談談標註方式。 OpenAI的人工回饋與國內最大的區別在於,它主要是對智慧系統的行為進行排序或評分,而不是對其輸出進行修改或標註
智慧系統的行為是指在複雜環境中,根據自身目標和策略,智慧系統所採取的一系列動作或決策
例如玩遊戲、操控機器人、與人對話等
智慧型系統的輸出,則是指在一個簡單的任務中,根據輸入的數據,產生一個結果或回答,例如寫一篇文章、畫一幅畫。
普遍而言,智慧系統的行為往往難以用「正確」或「錯誤」來判斷,而更需要用偏好或滿意度來評價
這種以「偏好」或「滿意度」為標準的評估體系,不需要修改或標註具體的內容,因此減少了人類主觀性、知識水平等因素對數據標註品質和準確性的影響
誠然,國內企業在進行標註時,也會使用類似「排序」、「評分」的體系,但由於缺乏像OpenAI那樣的「獎勵模型」作為獎勵函數來優化智慧系統的策略,這樣的「排序”和“打分”,本質上仍然是一種對輸出進行修改或標註的方法。
2、多樣化、大規模的資料來源管道;
#國內的數據標註來源主要是第三方標註公司或科技公司自建團隊,這些團隊多為本科生組成,缺乏足夠的專業性和經驗,難以提供高品質和高效率的回饋。

相較之下,OpenAI的人工回饋是透過多個管道和團隊獲得的
OpenAI與多家數據公司和機構合作,例如Scale AI、Appen、Lionbridge AI等,不僅使用開源數據集和互聯網爬蟲來獲取數據,還致力於獲取更多樣化和高質量的數據
這些數據公司和機構的標註手段與國內的同行相比,更加「自動化」和「智慧化」

例如,Scale AI使用了一種稱為 Snorkel的技術,它是一種基於弱監督學習的資料標註方法,可以從多個不精確的資料來源產生高品質的標籤。
同時,Snorkel還可以利用規則、模型、知識庫等多種訊號為資料添加標籤,而不需要手動直接標註每個資料點。這樣可以大幅減少人工標註的成本和時間。

在資料標註成本降低、週期縮短的情況下,這些具備競爭優勢的資料公司可以選擇高價值、高難度、高門檻的細分領域,如自動駕駛、大語言模型、合成資料等,以不斷提升自身的核心競爭力與差異化優勢
如此一來,「先行者會吃虧」的搭便車困境,也被強大的技術和產業壁壘給消弭了。
標準化與小作坊的比較
由此可見,AI自動標註技術,真正淘汰的只是那些還在使用純人工的標註公司。
儘管數據標註聽起來是一個「勞力密集」產業,但是一旦深入細節,便會發現,追求高品質的數據並不是一件容易的事。
以海外數據標註的獨角獸Scale AI為代表,Scale AI不僅在使用非洲等地的廉價人力資源,同樣還招聘了數十名博士,來應對各行業的專業數據。

Scale AI為OpenAI等大型模式企業提供的最大價值在於資料標註的品質
而要想最大程度地保障資料質量,除了前面提到的使用AI輔助標註外,Scale AI的另一大創新,就是了一個統一的資料平台。
這些平台,包括了Scale Audit、Scale Analytics、ScaleData Quality 等。透過這些平台,客戶可以監控和分析標註過程中的各種指標,並對標註資料進行校驗和最佳化,評估標註的準確性、一致性和完整性。
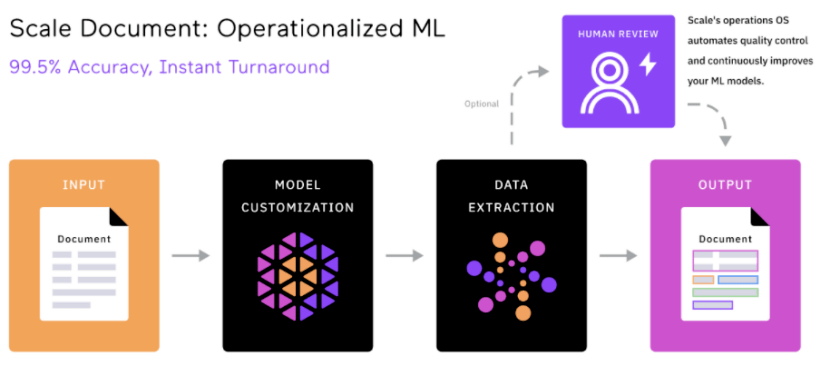
可以說,這樣標準化、統一化的工具與流程,成為了區分標註企業中「流水線工廠」與「手工小作坊」的關鍵因素。
在這方面,目前國內大部分的標註企業,都仍在使用「人工審核」的方式來審核資料標註的質量,只有百度等少數巨頭引入了較為先進的管理和評估工具,如EasyData智能數據服務平台。
如果沒有專門的工具來監控和分析標註結果和指標,那麼在關鍵的數據審核方面,對數據質量的把關就只能依賴於人工的經驗,這種方式仍然只能達到作坊式水準

因此,越來越多的中國企業,如百度、龍貓數據等,開始使用機器學習和人工智慧技術,以提高數據標註的效率和質量,實現人機協作的模式
從這個角度來看,人工智慧標註的出現並不意味著國內標註企業的末日,而只是傳統的低效、廉價、缺乏技術含量的勞動密集型標註方式的末日
以上是谷歌這一'大招”,要逼死多少AI標註公司?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















