
發燒友們已經揭開了蘋果Transformer的「秘密」
在大型模型浪潮的影響下,即使是保守的蘋果公司,在每次發布會上也必定會提及"Transformer"
例如,在今年的WWDC上,蘋果就已宣布,船新版本的iOS和macOS將內建Transformer語言模型,以提供帶有文字預測功能的輸入法。

雖然蘋果官方沒有透露更多信息,但技術愛好者們卻迫不及待
一位名叫Jack Cook的小哥,成功地翻開了macOS Sonoma beta的新篇章,意外地發現了許多新的資訊
更多細節,一起來看。
首先,讓我們回顧一下蘋果基於Transformer的語言模型在iPhone、MacBook等裝置上能夠實現的功能
#需要重寫的內容是:主要體現在輸入法方面。在語言模型的支持下,蘋果自帶的輸入法可以實現單字預測和糾錯的功能
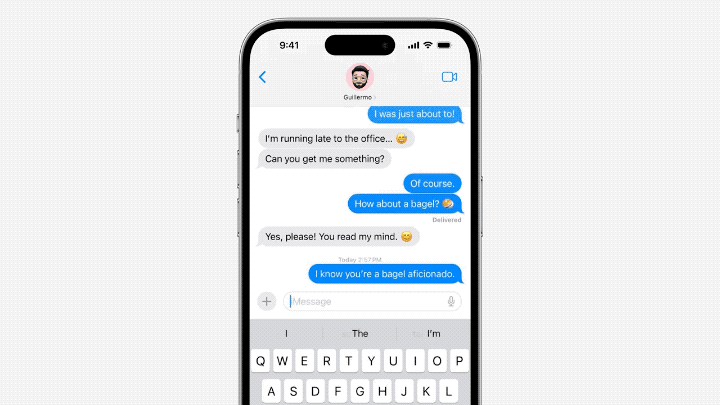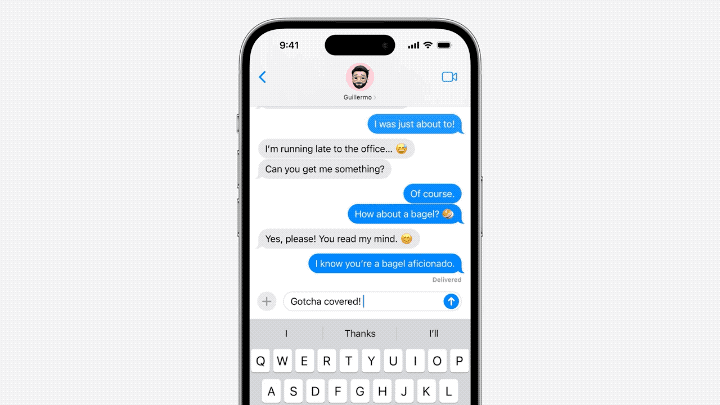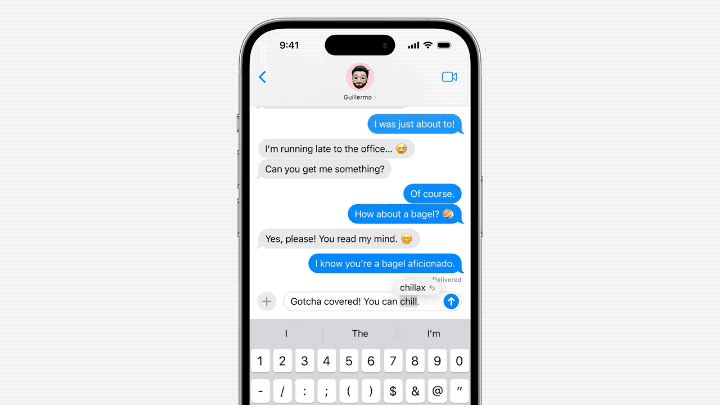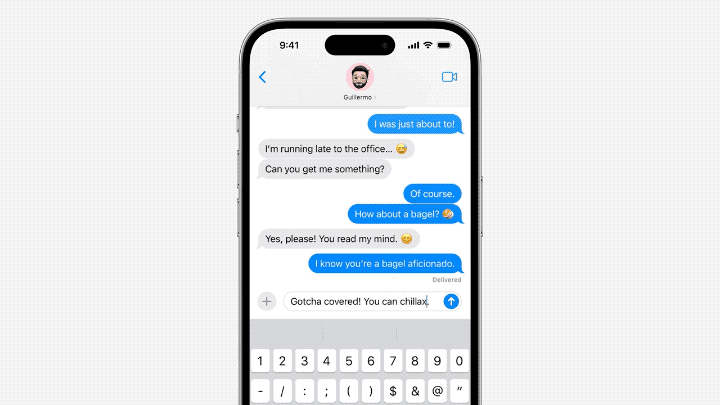
#Jack Cook小哥具體測試了一下,發現這個功能主要實現的是針對單字的預測。

模型有時也會預測即將出現的多個單字,但這僅限於句子語意十分明顯的情況,比較類似Gmail裡的自動完成功能。

那麼這個模型具體被裝在了哪裡?一通深入挖掘之後,Cook小哥確定:
我在 /System/Library/LinguisticData/RequiredAssets_en.bundle/AssetData/en.lm/unilm.bundle 中找到了預測文字模型。
原因是:
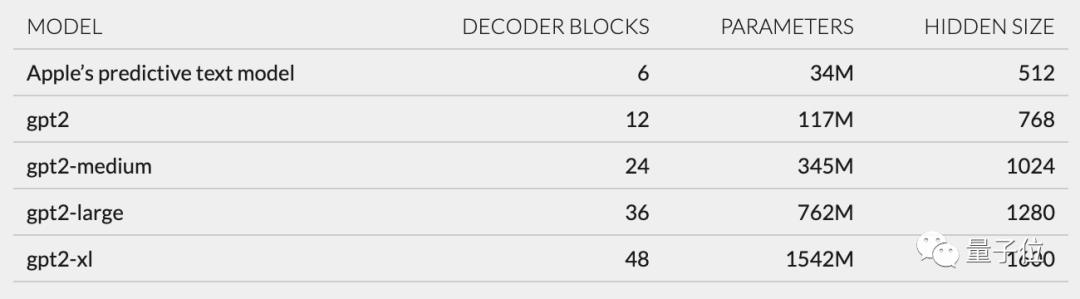
進一步推測,根據unilm_joint_cpu中所描述的網路結構,小哥認為蘋果模型是基於GPT-2架構建構的
主要的組成部分包括令牌嵌入、位置編碼、解碼器區塊和輸出層,在每個解碼器區塊中都會出現類似"gpt2_transformer_layer_3d"這樣的詞彙
需要進行改寫的內容是:△來源: Jack Cook的部落格文章
根據每層大小,小哥也推測蘋果模型約有3400萬個參數,隱藏層大小為512。換句話說,它比GPT-2最小版本還要小
小哥認為,這主要是因為蘋果想要一種不太耗電,但同時能夠快速、頻繁運行的模型。
而蘋果官方在WWDC上的說法是,「每點擊一個鍵,iPhone就會運行模型一次」。
然而,這也意味著這個文本預測模型無法很好地續寫句子或段落

#需要進行改寫的內容是:△來源: Jack Cook的部落格文章
模型架構之外,Cook小哥還挖出了分詞器(tokenizer)的相關資訊。
他在unilm.bundle/sp.dat裡發現了一組數量為15000的token,值得關注的是,其中包含100個emoji。
雖然這個Cook不是那個庫克,但小哥的部落格文章一發布,仍然吸引了很多關注

基於他的發現,網友們熱烈地討論起蘋果在使用者體驗和尖端科技應用之間的平衡大法。

回到Jack Cook本人,他本科和碩士畢業於MIT的電腦專業,目前還在攻讀牛津大學的網路社會科學碩士學位。
他之前曾在英偉達實習,專注於研究BERT等語言模式。他也擔任《紐約時報》的自然語言處理高級研發工程師
以上是iPhone中隱藏的機器人:基於GPT-2架構,附有emoji分詞器,由MIT校友開發的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















