
你可能聽過以下犀利的觀點:
1.跟著NVIDIA的技術路線,可能永遠追不上NVIDIA的腳步。
2. DSA或許有機會追趕上NVIDIA,但目前的狀況是DSA瀕臨消亡,看不到任何希望
#另一方面,我們都知道現在大模型正處於風口位置,業界很多人想做大模型晶片,也有很多人想投大模型晶片。
但是,大模型晶片的設計關鍵在哪,大頻寬大記憶體的重要性好像大家都知道,但做出來的晶片跟NVIDIA相比,又有何不同?
帶著問題,本文試著給大家一點啟發。
純粹以觀點為主的文章往往顯得形式主義,我們可以透過一個架構的例子來說明
SambaNova Systems被譽為美國十大獨角獸公司之一。在2021年4月,該公司由軟銀牽頭獲得了6.78億美元的D輪投資,估值達到了50億美元,成為了一家超級獨角獸公司。先前,SambaNova的投資方包括Google創投、Intel Capital、SK和Samsung催化基金等全球頂級創投基金。那麼,這家吸引了全球頂尖投資機構青睞的超級獨角獸公司到底在做什麼顛覆性的事情呢?透過觀察他們早期的宣傳資料,我們可以發現SambaNova選擇了一條與AI巨頭NVIDIA不同的發展之路
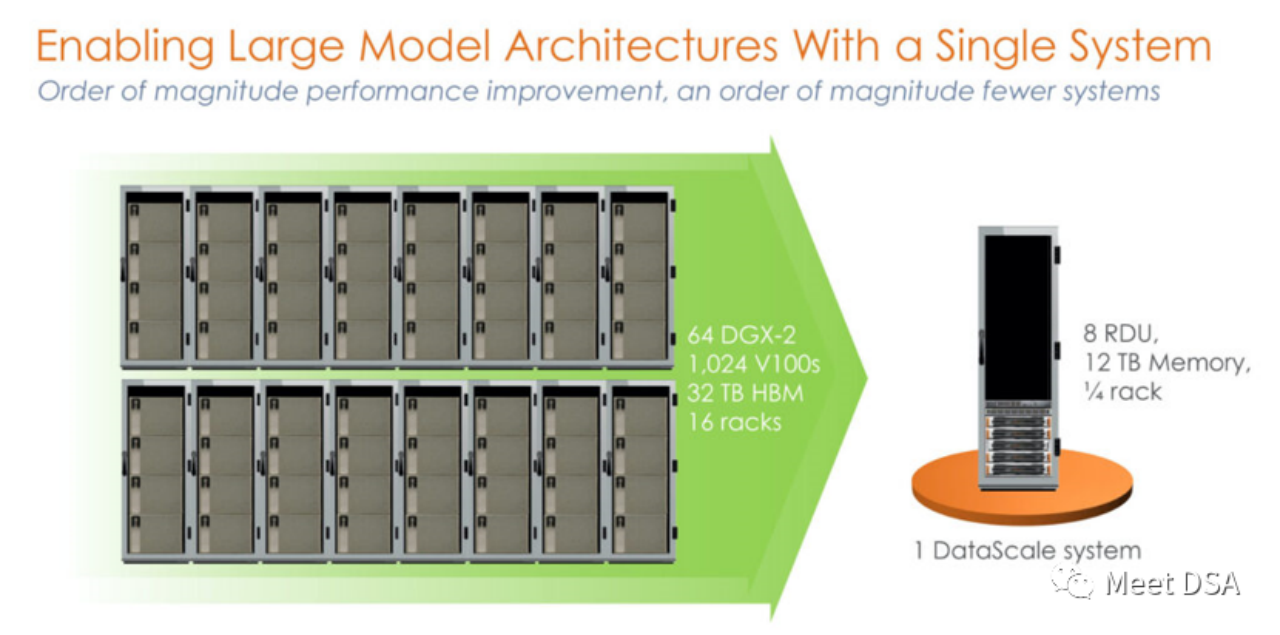
是不是有點震撼?在英偉達平台上用洪荒之力所建構的1024的V100集群,居然被SambaNova的一個單機就等價了? !這是第一代的產品,基於SN10 RDU的單機8卡機器。
可能有人會說這個對比顯得不太公平,NVIDIA不是有DGX A100嗎,可能SambaNova自己也意識到了,二代產品SN30就改成這樣了:

#DGX A100 是5 petaFLOPS的算力,SambaNova的第二代DataScale的算力也是5 petaFLOPS。 Memory比較320GB HBM vs 8TB DDR4(小編猜測可能他文章寫錯了,應該是3TB * 8)。
第二代晶片其實是SN10 RDU的Die-to-Die版本。 SN10 RDU的架構指標為:320TFLOPS@BF16,320M SRAM,1.5T DDR4。而SN30 RDU則是在此基礎上進行了雙倍的提升,正如下面所描述的那樣:
“This chip had 640 pattern compute units with more than 320 teraflops of compute at BF16 floating point precision and also had 640 pattern memory units with 320 MB of on-chip SRAM and 150 TB/sec of on-chip memory bandwidth. Each SN10 processor was also able to address 1.5 TB of DDR4 auxilia the memory Card. capacity of the RDU is doubled, and the reason it is doubled is that SambaNova designed its architecture to make use of multi-die packaging from the get-go, and in this case SambaNova is doubling up the capacity of by coo 。 memory bandwidth of the first generations of machines.”
要點提煉:大頻寬,大容量只能二選一,NVIDIA選擇了大頻寬HBM,而SambaNova選擇了大容量DDR4。從效能效果來看,SambaNova完勝。
如果換成DGX H100,即使是換成FP8這些低精度的技術,也只能縮小差距。
「And even if the DGX-H100 offers 3X the performance at 16-bit floating point calculation than the DGX-A100, it will not close the gap with the SambaNova system. However, with lower presion not close the gap with the SambaNova system. However, with lower presion not, with FP8 Nvidia might be able to close the performance gap; it is unclear how much precision will be sacrificed by shifting to lower precision data and processing.”
如果有人能夠實現這樣的效果,那不就是一個完美的大型晶片解決方案嗎?而且還能夠直接面對NVIDIA的競賽!
(可能你會說Grace CPU也可以接LPDDR,利於增大容量之類的,反觀SambaNova是怎麼看這個事情:Grace不過是一個大號的記憶體控制器,但也只能給Hopper帶來512GB的DRAM,而一個SN30就有3TB的DRAM。
我們曾經開玩笑說Nvidia的「Grace」 Arm CPU只是Hopper GPU的一個過分誇大的記憶體控制器。在很多情況下,它確實只是一個記憶體控制器,而且每個Grace-Hopper超級晶片套裝中的Hopper GPU最多只有512GB的記憶體。這仍然比SambaNova每個插槽提供的3TB記憶體少很多
歷史告訴我們,再如日中天的帝國,可能也要當心那道不起眼的裂縫!
夏核,華為大神,最近從成本的角度出發,推測了NVIDIA帝國的一個弱點可能在於每GB的成本上,他建議瘋狂堆料廉價的DDR內存來進行大規模的內部輸入/輸出,這有可能對NVIDIA產生革命性的影響
(引申:https://www.php.cn/link/617974172720b96de92525536de581fa)
#而另外一個研究DSA的知乎大神mackler給出了他的觀點,從$/GBps(數據移動)的角度看,HBM性價比更高,因為LLM雖然對內存容量有比較大的需求,但對於內存頻寬也有龐大的需求,訓練需要大量的參數需要在DRAM來交換。
(引申:https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc#)
#從SambaNova的架構範例來看,大容量廉價DDR是可以解決LLM的問題的,這印證了夏core的判斷! 但是mackler觀點中對資料移行的龐大頻寬的需求也是問題所在,那SambaNova是如何解決的?
需要進一步理解RDU架構的特點,其實也很容易理解:
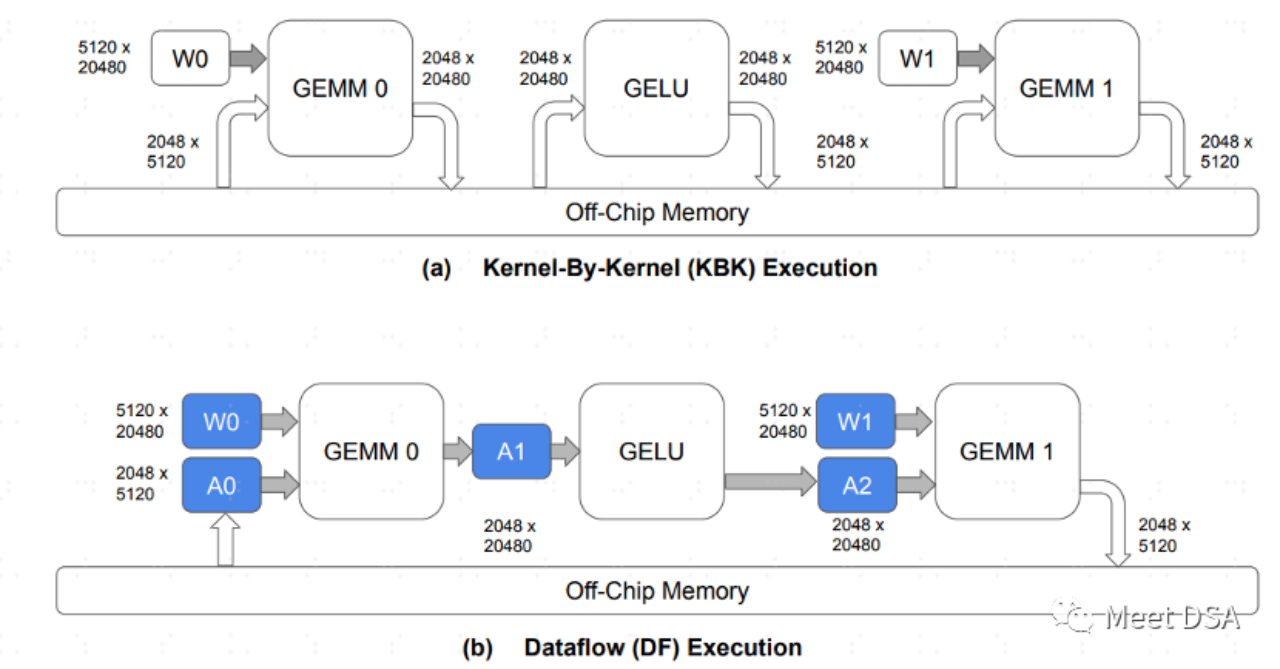
A是傳統的GPU架構資料交換的範式,每個算子都需要去片外DRAM交換數據,這種來回的交換佔據大量的DDR頻寬應該比較好理解。 B是SambaNova的架構可以做到的,模型運算過程,把很大部分的資料移都留在片內,不需要來回的去DRAM進行交換。
因此,如果能做到B這樣的效果,大頻寬,大容量二選一的問題,就可以安全的選大容量。這如以下這段話所言:
「The question we have is this: What is more important in a hybrid memory architecture supporting foundation models, memory capacity or memory bandwidth? You can'base'base both or memory bandwidth? You can'base' a single memory technology in any architecture, and even when you have a mix of fast and skinny and slow and fat memories, where Nvidia and SambaNova draw the lines are different.”
##IA#]#IA#]#IA#PIA# ,我們並非沒有希望!然而,跟隨NVIDIA進行GPGPU的策略可能並不可行。看起來,大型晶片的正確想法在於使用成本較低的DRAM,以相同的運算能力規格,效能可以達到NVIDIA的6倍以上!SambaNova的RDU/DataFlow架構是如何實現B的效果的呢?或是有其他方法可以達到類似B的效果呢?我們將在下次與大家分享,有興趣的朋友們請繼續關注我們的更新
擴展閱讀資料:[1]https:/ /sambanova.ai/blog/a-new-state-of-the-art-in-nlp-beyond-gpus/
[2]https://www.nextplatform. com/2022/09/17/sambanova-doubles-up-chips-to-chase-ai-foundation-models/
[3]https://hc33.hotchips.org /assets/program/conference/day2/SambaNova HotChips 2021 Aug 23 v1.pdf
[4]《TRAINING LARGE LANGUAGE MODELS EFFICIENTLY WITH SPARSITY AND DATAFLOW》
##[5]https://www.php.cn/link/617974172720b96de92525536de581fa
#需要改寫的內容是:[6]https://www.php .cn/link/a56ee48e5c142c26cf645b2cc23d78fc
#
以上是DSA如何彎道超車NVIDIA GPU?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















