
首個中英雙語的語音對話開源大模型來了!
這幾天,一篇關於語音-文本多模態大模型的論文出現在arXiv上,署名公司中出現了李開復旗下大模型公司01.ai——零一萬物的名字。
 圖片
圖片
這篇論文介紹了一個名為LLaSM的中英雙語可商用對話模型。該模型不僅支援錄音和文字輸入,而且能夠實現「混合雙打」的功能
 圖片
圖片
研究指出,「語音聊天」是AI與人之間更方便自然的互動方式,不只是透過文字輸入
用上大模型,有網友已經在想「躺著說話就能寫程式碼」的場景了。
 圖片
圖片
這項研究是由LinkSoul.AI、北京大學和零一萬物共同完成的,目前已經開源,並且可以直接在抱抱臉中進行試玩
 圖片
圖片
讓我們一起來看看它的效果如何吧
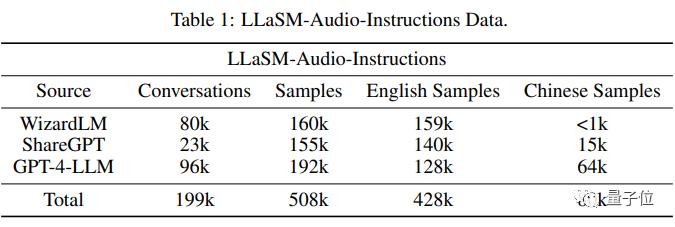
據研究人員表示,LLaSM是第一個支援中英文雙語語音-文字多模態對話的開源可商用對話模型。
那麼,就來看看它的語音文字輸入和中英雙語能力如何。
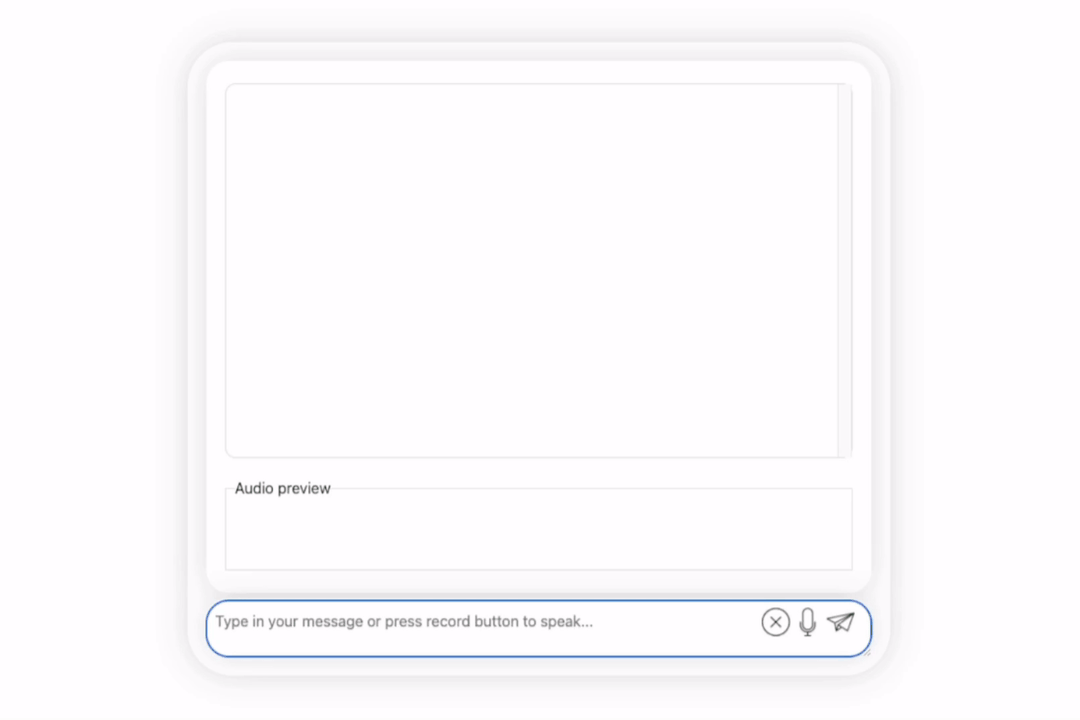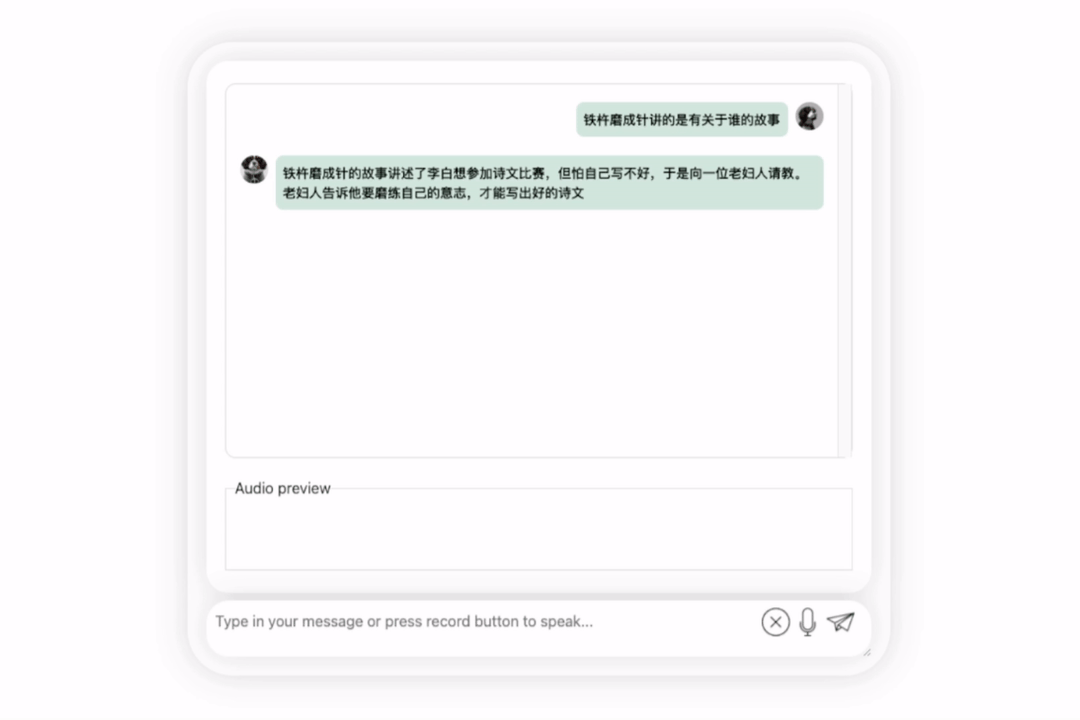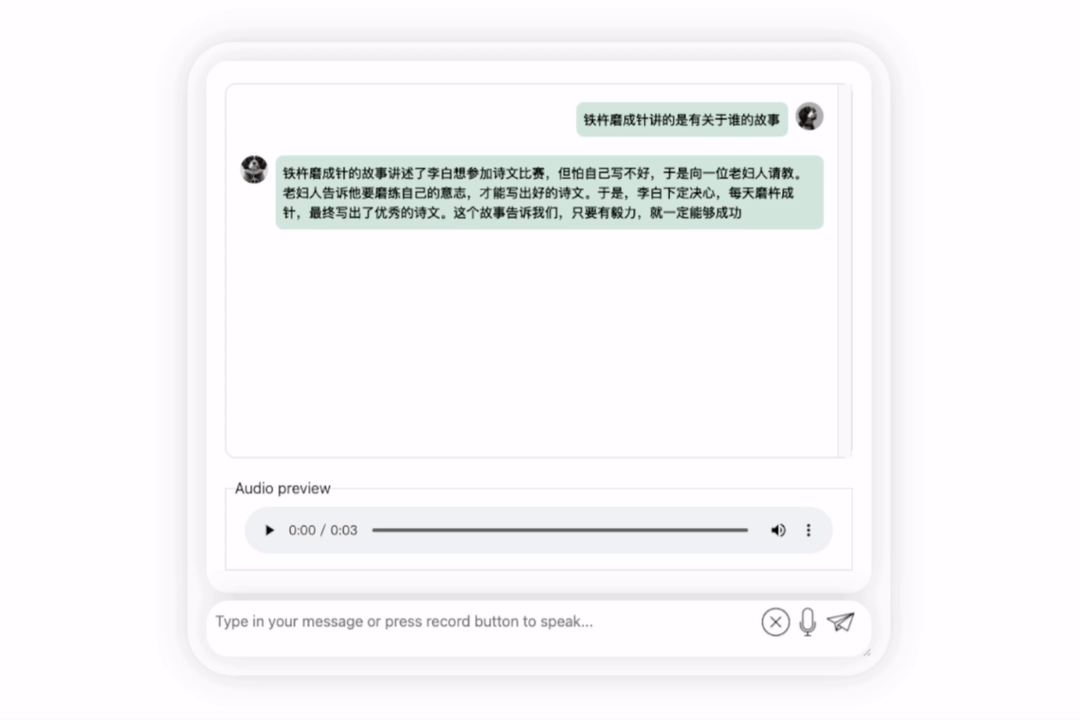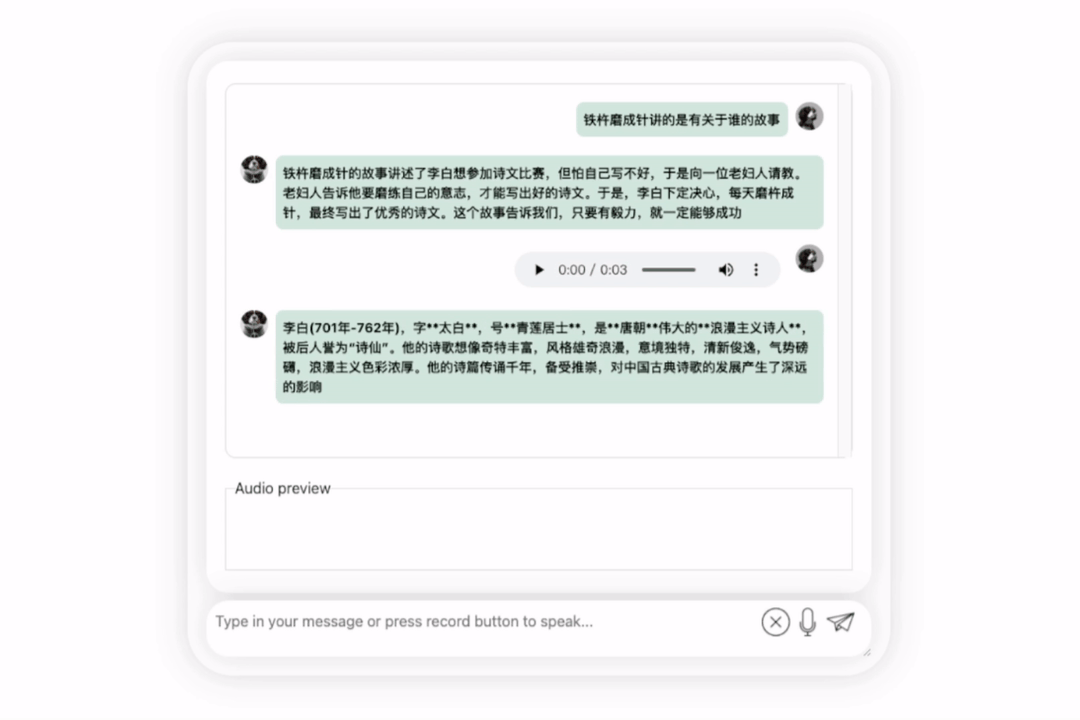
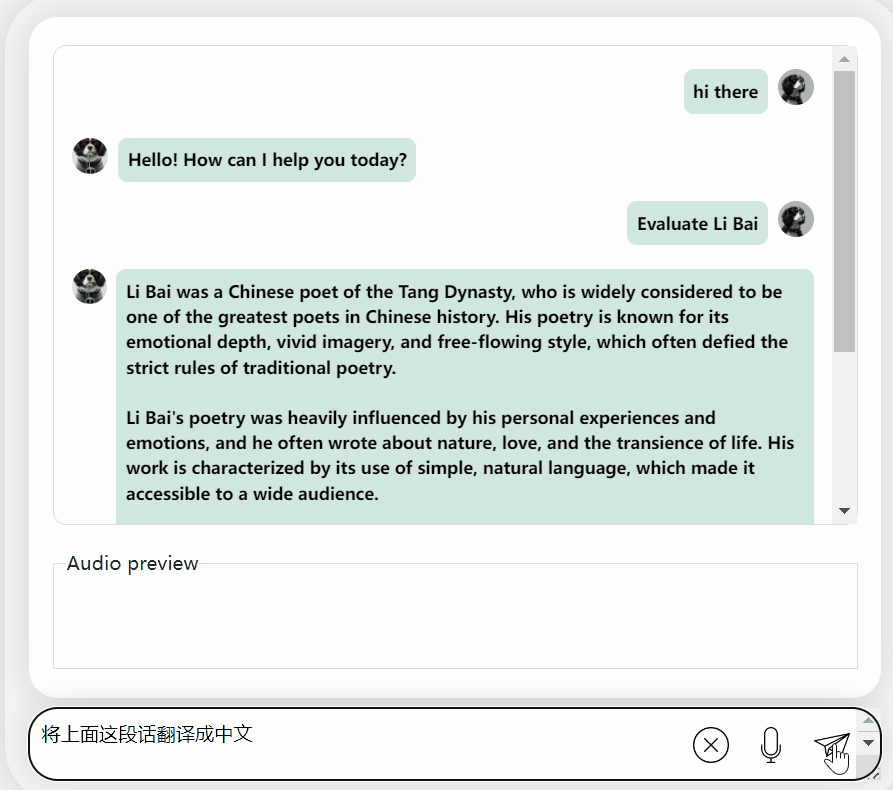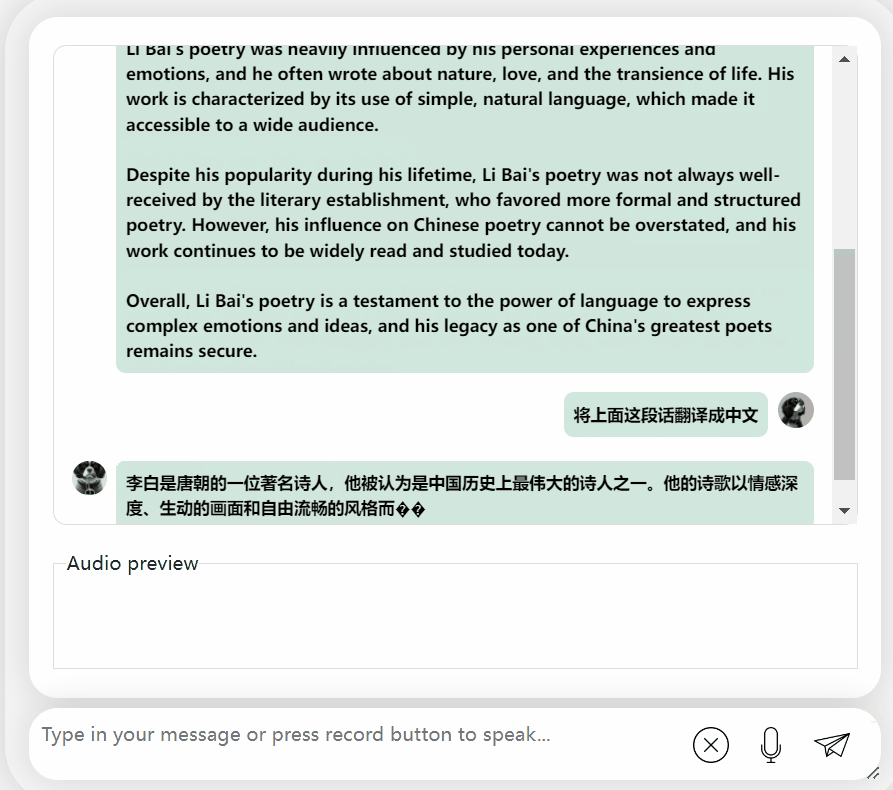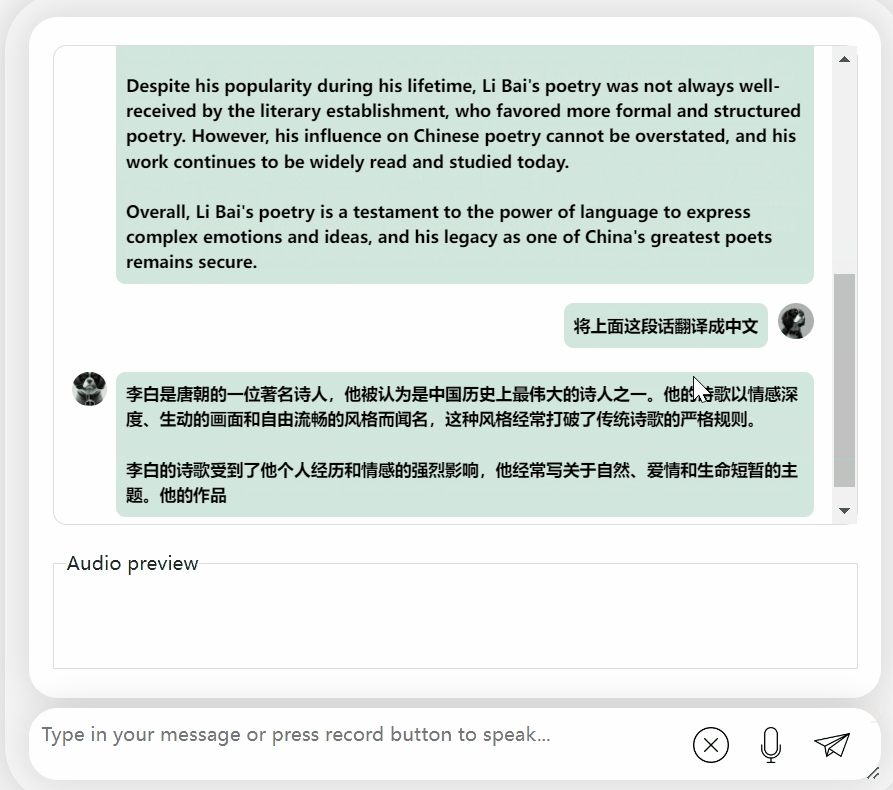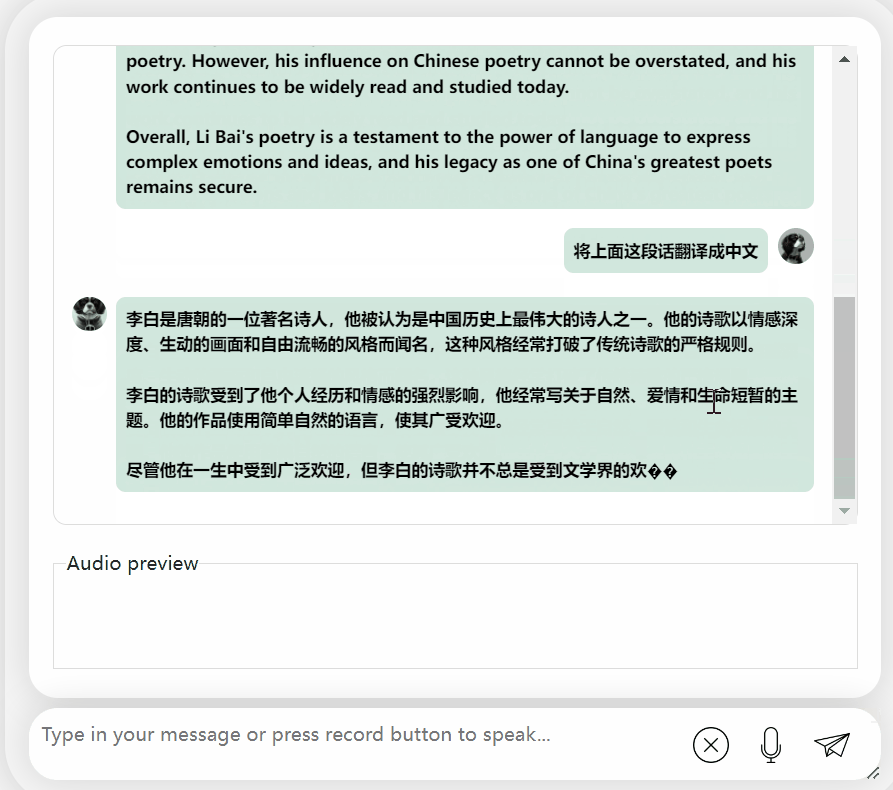
首先,讓我們進行一次中英文化碰撞,用英文來評價李白:
 #圖片
#圖片
還可以,正確地說出了李白的朝代。如果看不懂英文,讓它直接翻譯成中文也沒問題:
 圖片
圖片
#在接下來的練習中,讓我們試試看中英混合提問,將一個「炸食物」一詞加入中文句子。模型的輸出效果也相當不錯:
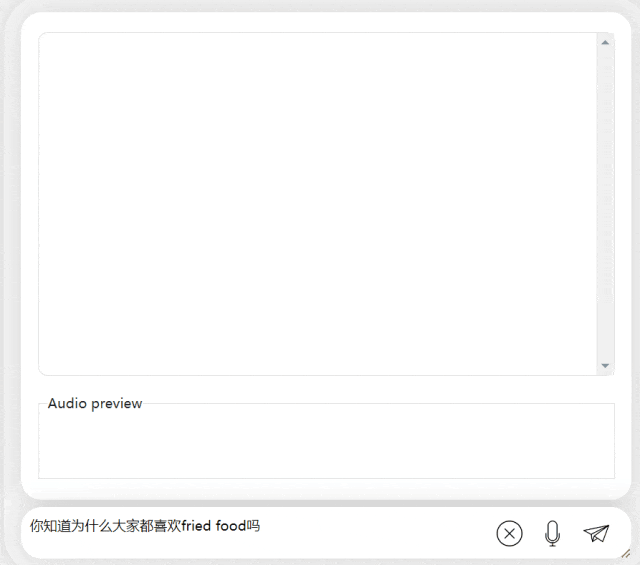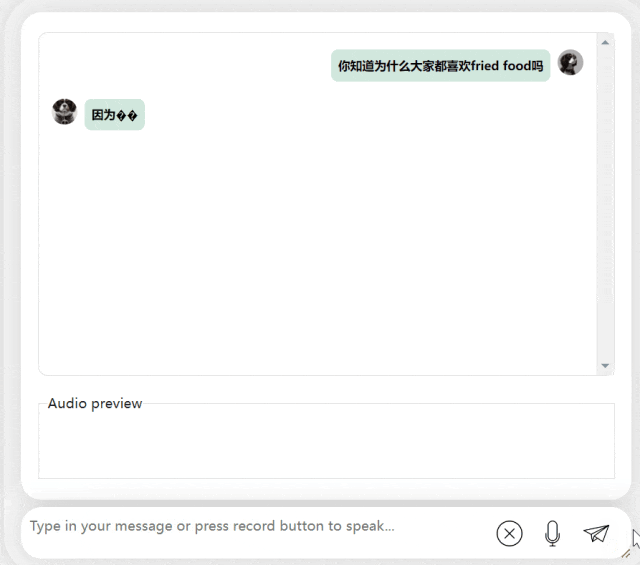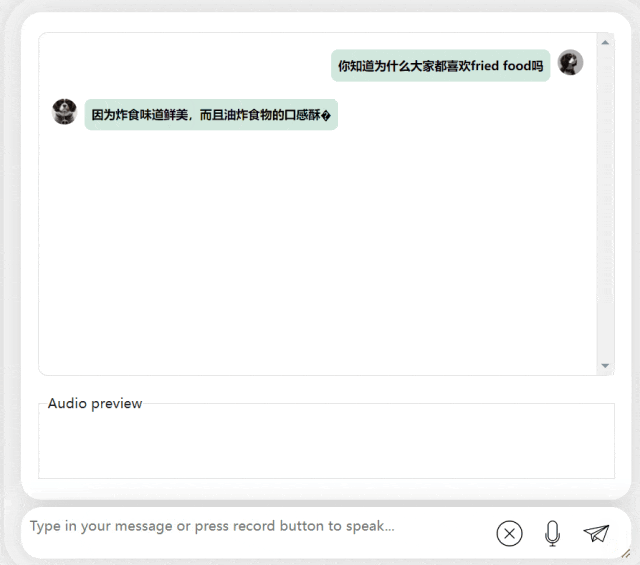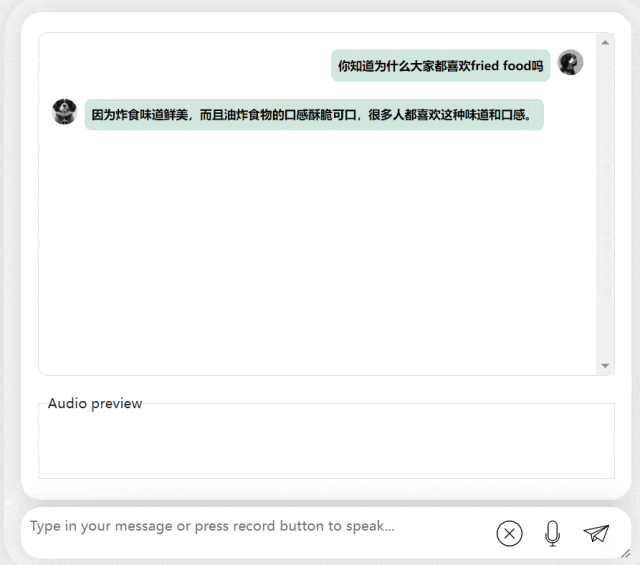 圖片
圖片
讓我們再試探模型,讓它進行一些評價,看看李白和杜甫哪個更厲害
可以觀察到,在經過一段時間的思考後,這個模型給出了非常客觀中立的評價,同時也具備了大型模型所必備的基本知識和常識(手動狗頭)
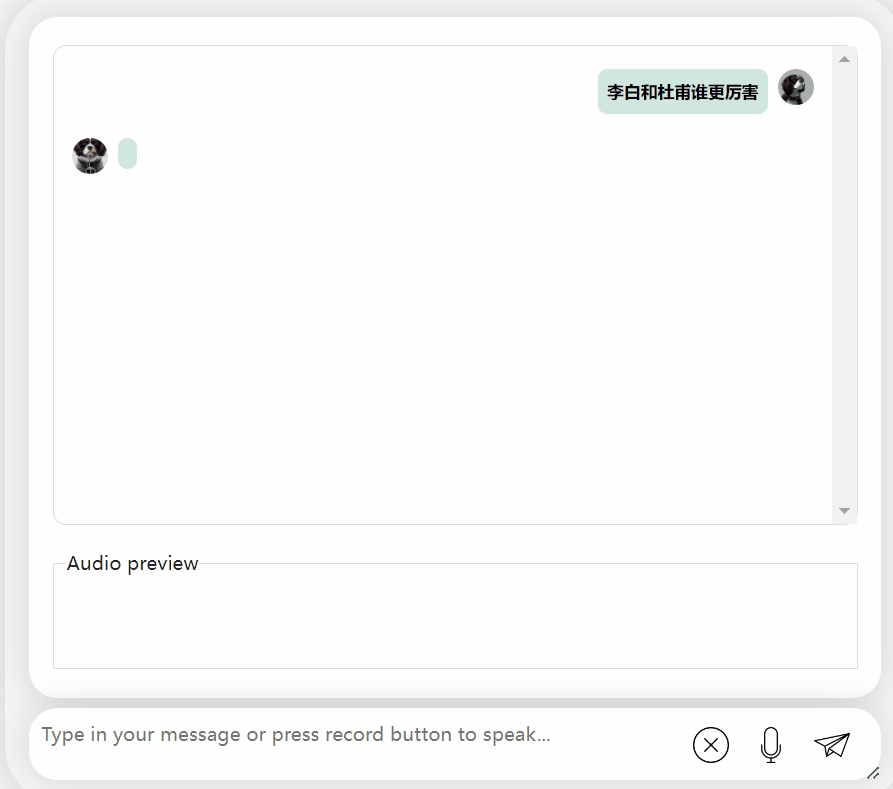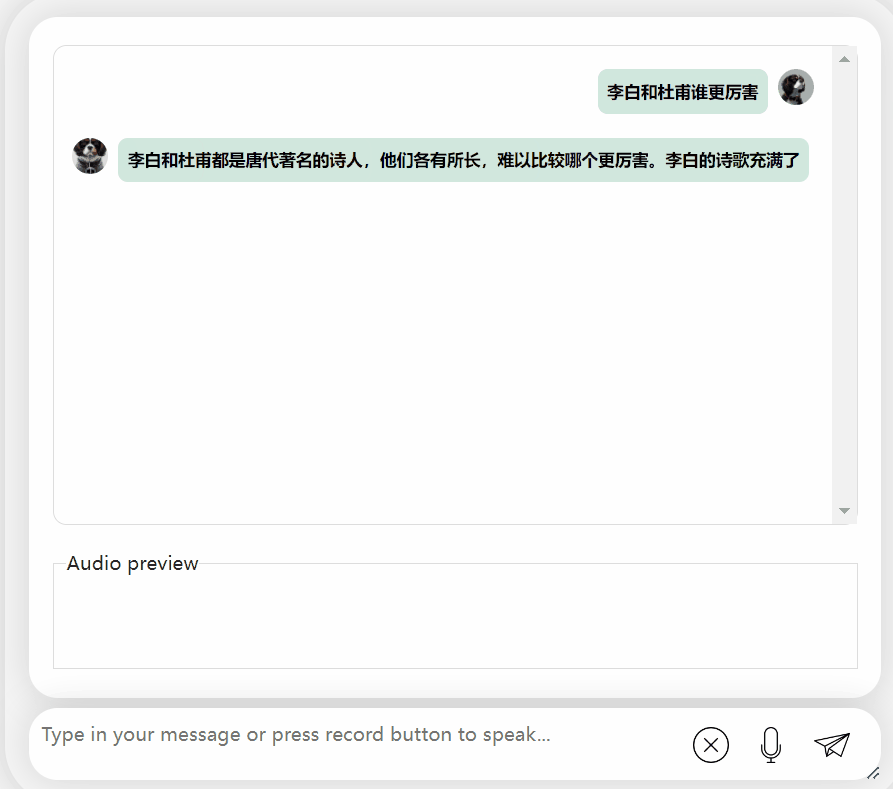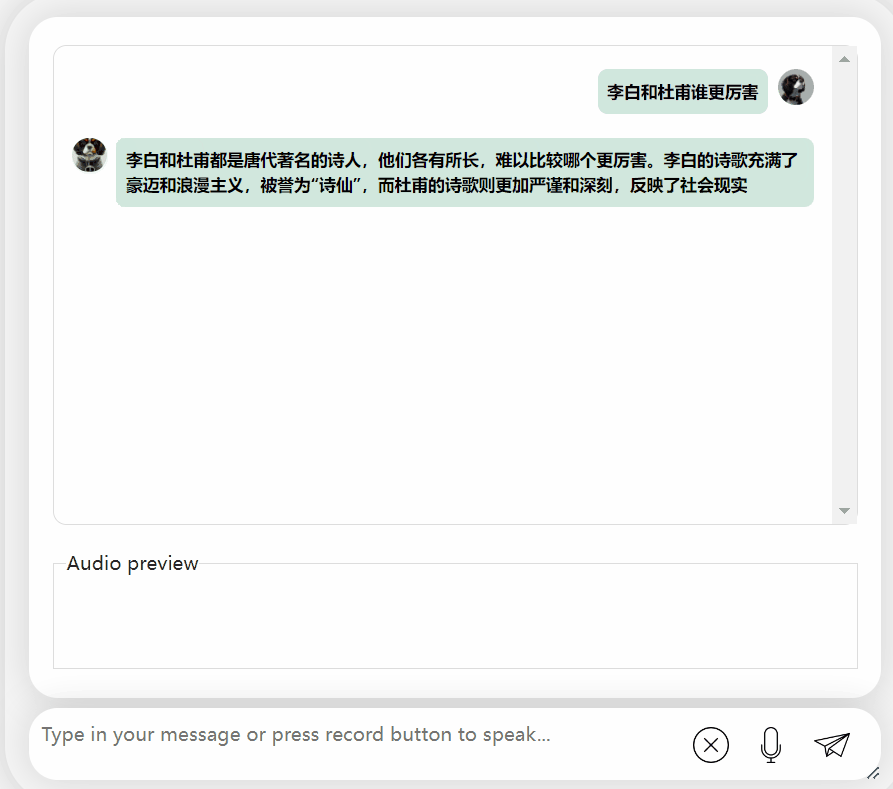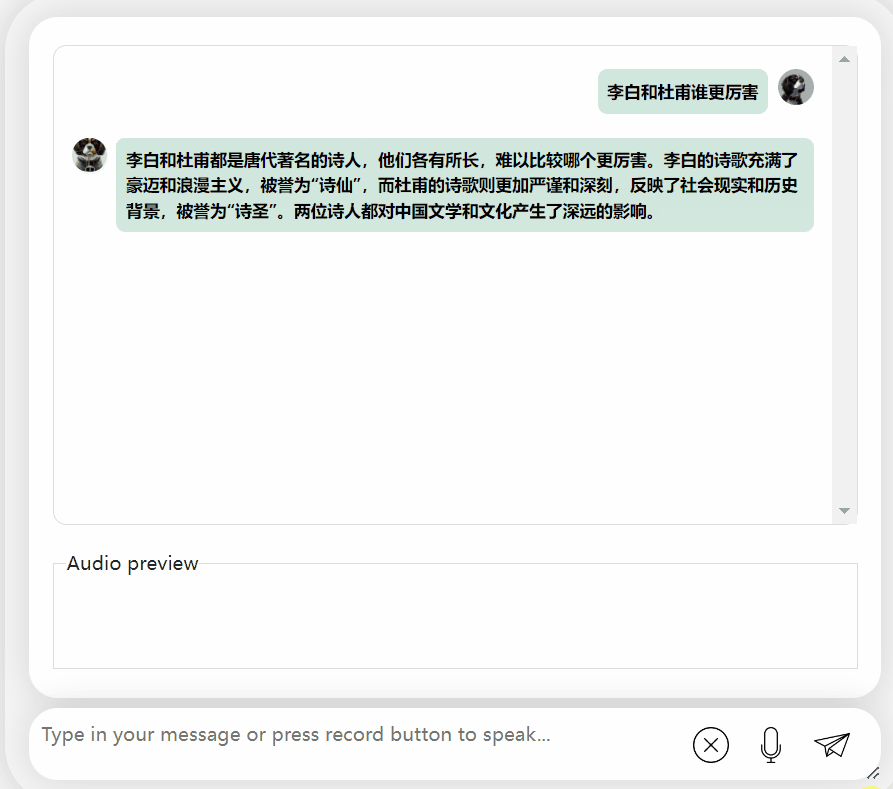 圖片
圖片
當然,不只電腦,手機也能玩。
我們試著用語音輸入「給我推薦一個食譜吧」:
可以看到模型準確地輸出了一個「茄子起司」的食譜,就是不知道好不好吃。
不過,我們在嘗試的時候也發現,這個模型有時候會出bug。
例如有時候它並不能很好地「聽懂人話」。
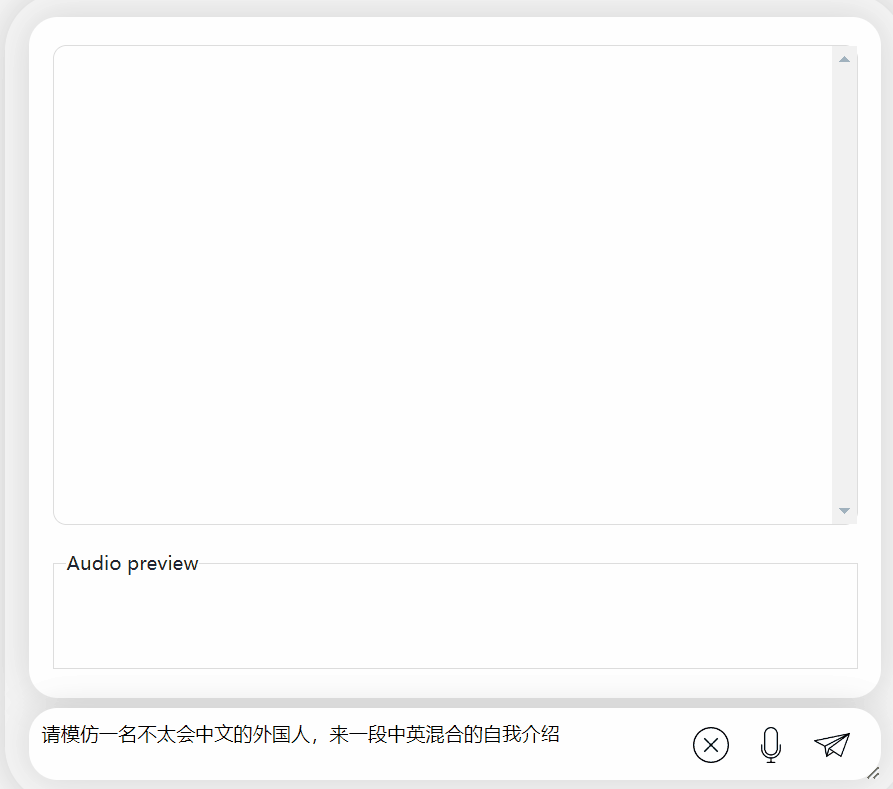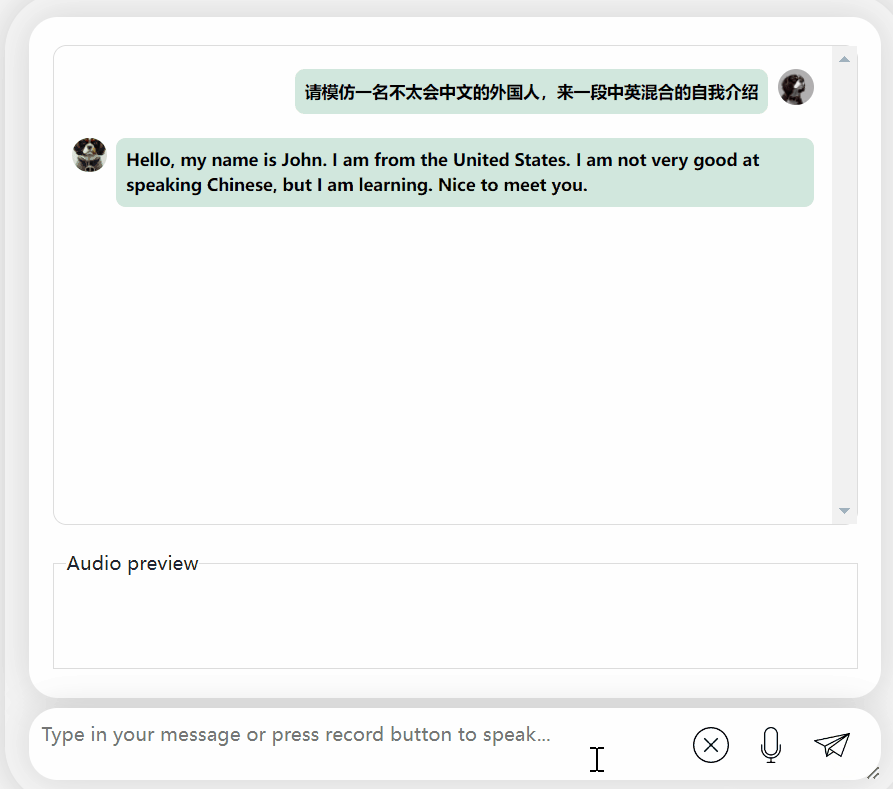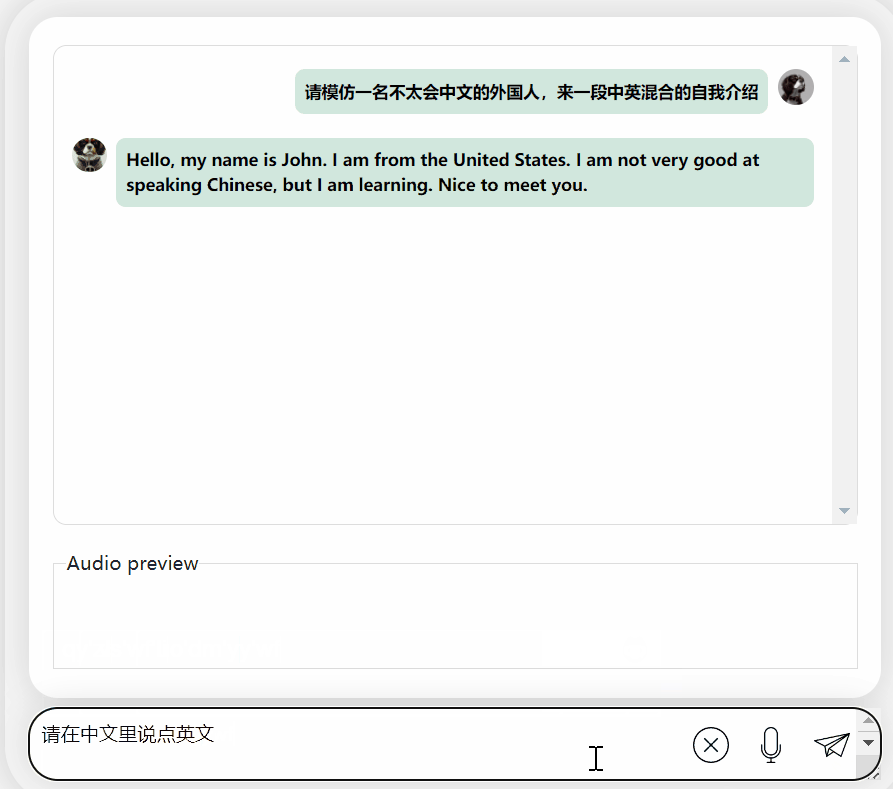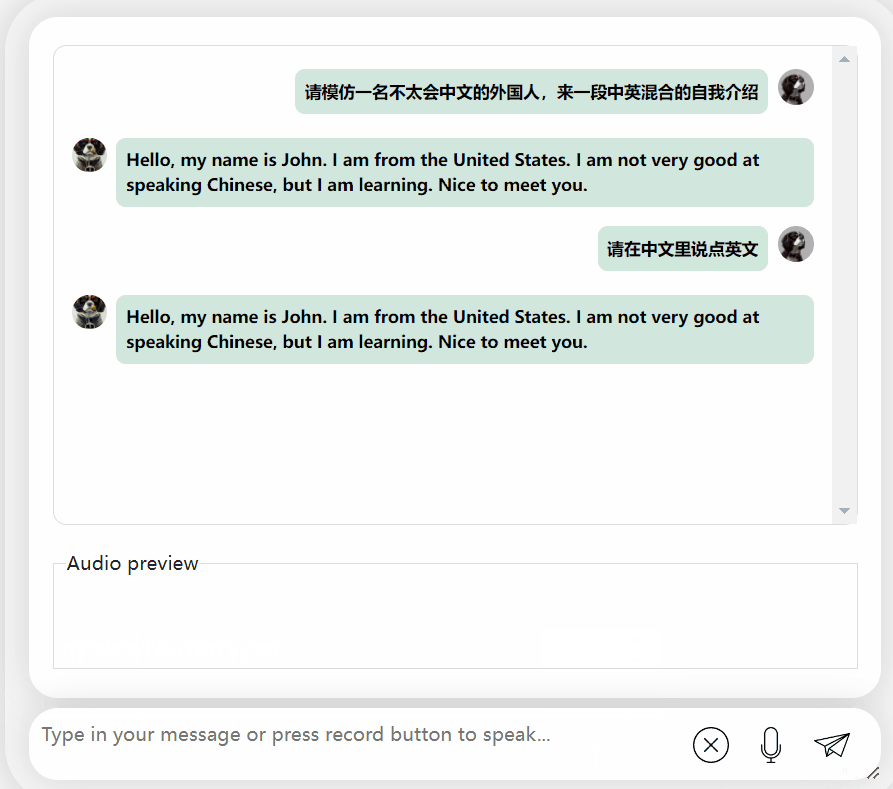
要求輸出中英混合的內容,它會假裝看不懂並輸出英文:
 #圖片
#圖片
當中英混合詢問想聽「Taylor Swift的Red」時,模型出現了嚴重的錯誤,不斷重複輸出同一句話,甚至無法停止…
 圖片
圖片
整體來看,當遇到中英混合的提問或要求時,模型輸出能力還是不太行。
不過分開的話,它的中英文表達能力還是不錯的。
那麼,這樣的模型究竟是怎麼實現的呢?
從試玩來看,LLaSM主要有兩個特點:一個是支援中英輸入,另一個是語音文字雙輸入。
要做到這兩點,分別需要在架構和訓練資料上做一些調整。
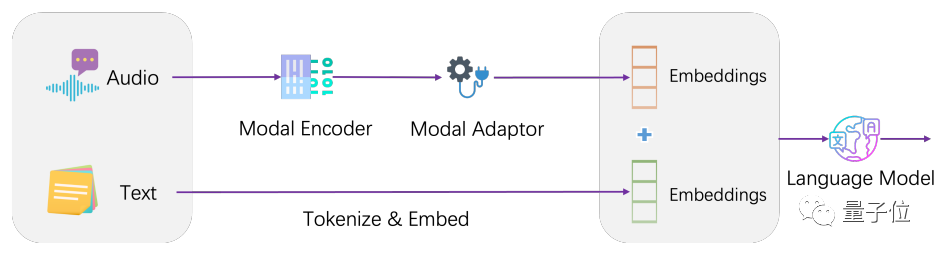
架構上,LLaSM將目前的語音辨識模型和大語言模型做了個整合。
LLaSM由三個部分構成,分別包含自動語音辨識模型Whisper、模態轉接器和大模型LLaMA。
在這個過程中,Whisper負責接收原始語音輸入並輸出語音特徵的向量表示。模態適配器的作用是對齊語音和文字嵌入。而LLaMA則負責理解語音和文字輸入的指令,並產生回應
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
#https://www.php.cn/link/47c917b09f2bc64b2916c0824c715923
https://www.php.cn/link/bcd0049c35799cdf57d06eaf2eb3cff6#
以上是國內推出全新語音對話大模型:李開復領銜,零一萬物參與,支援中英雙語與多模態,開源可商用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















