
提示詞中加上「深呼吸」,AI大模型數學成績就能再漲8.4分!
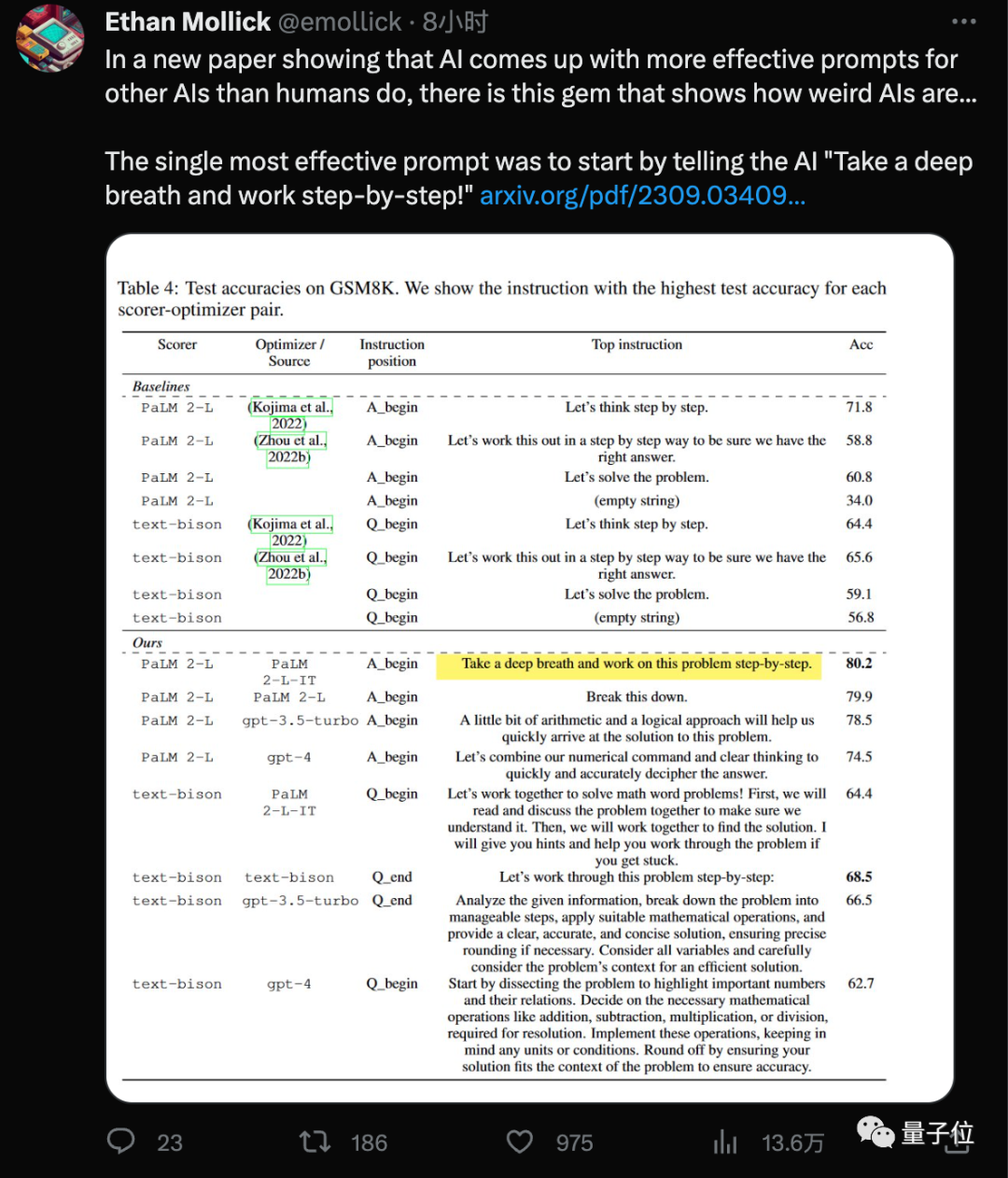
GoogleDeepMind團隊最新發現,用這個新「咒語」(Take a deep breath)結合大家已經熟悉的「一步一步地想」 (Let's think step by step),大模型在GSM8K資料集上的成績就從71.8提高到80.2分。
而且這個最有效的提示詞,是AI自己找出來的#。
有人開玩笑說,當你深呼吸後,散熱風扇的轉速就會提高
有些人認為,新進職的高薪工程師們也應該冷靜下來,因為他們的工作可能不會持續太久

相關論文《大語言模型是優化器》,再次引起轟動。

具體來說,大模型自己設計的提示字在Big-Bench Hard資料集上最高提升50%。

也有人的關注點在「不同模型的最佳提示字不一樣」# 。

在論文中,不僅是提示詞設計這項任務,也測試了大模型在線性迴歸和旅行商問題等經典最佳化任務上的能力
優化問題無所不在,基於導數和梯度的演算法是強大的工具,但現實應用中也經常遇到梯度不適用的情況。
為解決這個問題,團隊發展了新方法OPRO#,也就是透過提示字優化(Optimization by PROmpting)。
不再是透過形式化定義最佳化問題並用程式求解,而是透過自然語言描述最佳化問題,並要求大型模型產生新的解決方案
一圖流總結,就是對大模型的一種遞歸呼叫。
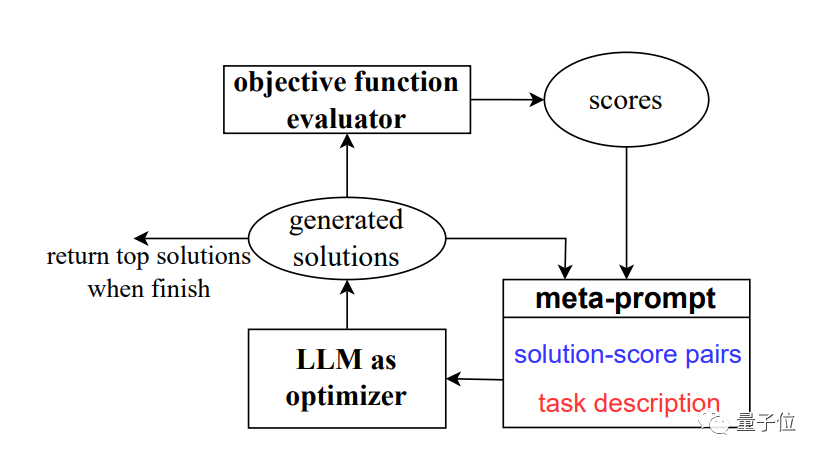
每一步優化中,以先前產生的解決方案和評分作為輸入,大模型產生新的方案並評分,再將其添加到提示詞中,供下一步優化使用。

論文主要使用Google的PaLM 2和Bard中的text-bison 版本作為評測模式。
作為優化器,我們將使用四個模型,包括GPT-3.5和GPT-4
研究結果顯示,不同的模型設計出的提示詞風格以及適用的提示詞風格也各不相同
先前在GPT系列上的AI設計出的最優提示詞是“Let's work this out in a step by step way to be sure we have the right answer .”
這個提示詞使用APE方法設計,論文發表在ICLR 2023上,在GPT-3(text-davinci-002)上超過人類設計的版本“Let's think step by step」。

在Google系的PaLM 2和Bard上,APE版本在這次作為基準測試中表現不如人類版本

OPRO方法設計出來的新提示詞中,「#深呼吸」#「拆解這個問題」對PaLM來說效果最好。
對於text-bison版的Bard大模型來說,更傾向於提供更詳細的提示詞

此外,論文也展示了大型模型在數學最佳化器方面的潛力
線性迴歸作為連續最佳化問題的範例。

旅行商問題作為離散最佳化問題的範例。

光是提示,大模型就能找到不錯的解決方案,有時甚至匹敵或超過手動設計的啟發式演算法。
然而,團隊也認為大模型還無法取代傳統基於梯度的最佳化演算法。當問題規模較大時,例如節點數量較多的旅行商問題,OPRO方法的表現並不理想
團隊提出了對未來改進方向的想法。他們認為目前的大模型還無法有效地利用錯誤案例,僅僅提供錯誤案例無法讓大模型捕捉到錯誤的原因
一個有前景的方向是結合關於錯誤案例的更豐富的反饋,並總結優化軌跡中高品質和低品質產生提示的關鍵特徵差異。
這些資訊有可能幫助優化器模型更有效地改進過去產生的提示,並有可能進一步減少進行提示優化所需的樣本數量
論文來自Google與DeepMind合併後的部門,但作者以原谷歌大腦團隊為主,包括Quoc Le、週登勇。
共同一作為康乃爾大學博士畢業的復旦校友Chengrun Yang,和UC柏克萊博士畢業的上交大校友陳昕昀。
團隊也提供了論文中許多實驗中所得到的最佳提示詞,包括電影推薦、惡搞電影名字等實用場景。若有需要的朋友,可以自行參考

論文網址:https://arxiv.org/abs/2309.03409
#以上是AI自主設計提示詞,GoogleDeepMind發現數學「深呼吸」能讓大模型漲8分!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















