
如果你曾經與任何一款對話式 AI 機器人交流過,你一定會記得一些令人感到非常沮喪的時刻。例如,你在前一天的對話中提到的重要事項,被AI 完全忘記了…
這是因為目前的多數LLM 只能記住有限的上下文,就像為考試而臨時抱佛腳的學生,稍加盤問就會「露出馬腳」。
如果AI助理能夠在聊天中根據上下文參考幾週或幾個月前的對話,或者你可以要求AI助理總結長達數千頁的報告,那麼這樣的能力是不是令人羨慕呢?
為了讓LLM能夠更好地記住和記住更多內容,研究人員一直在不斷努力。最近,來自麻省理工學院、Meta AI和卡內基美隆大學的研究人員提出了一種名為“StreamingLLM”的方法,使得語言模型能夠流暢地處理無窮無盡的文本

StreamingLLM 的工作原理是識別並保存模型固有的「注意力池」(attention sinks)錨定其推理的初始token。結合最近 token 的滾動緩存,StreamingLLM 的推理速度提高了 22 倍,而不需要犧牲任何的準確性。短短幾天,該專案在GitHub 平台已斬獲2.5K 星:
#具體來說,StreamingLLM 是一種使語言模型能夠準確無誤地記住上一場比賽的得分、新生兒的名字、冗長的合約或辯論內容的技術。就像為 AI 助理升級了記憶體一樣,它能夠完美地處理更繁重的工作

#接下來讓我們看看技術細節。
通常,LLM 在預訓練時受到注意力視窗的限制。儘管為擴大此視窗大小、提高訓練和推理效率,先前已有很多工作,但 LLM 可接受的序列長度仍然是有限的,這對於持久部署來說並不友善。
在這篇論文中,研究者首先介紹了LLM 流應用的概念,並提出了一個問題:「能否在不犧牲效率和性能的情況下以無限長輸入部署LLM?」
將LLM 應用於無限長輸入流時,會面臨兩個主要挑戰:
1、在解碼階段,基於transformer 的LLM 會快取所有先前token 的Key 和Value 狀態(KV),如圖1 (a) 所示,這可能會導致記憶體使用過多,並增加解碼延遲;
#2、現有模型的長度外推能力有限,即當序列長度超過預訓練時設定的注意力視窗大小時,其表現就會下降。
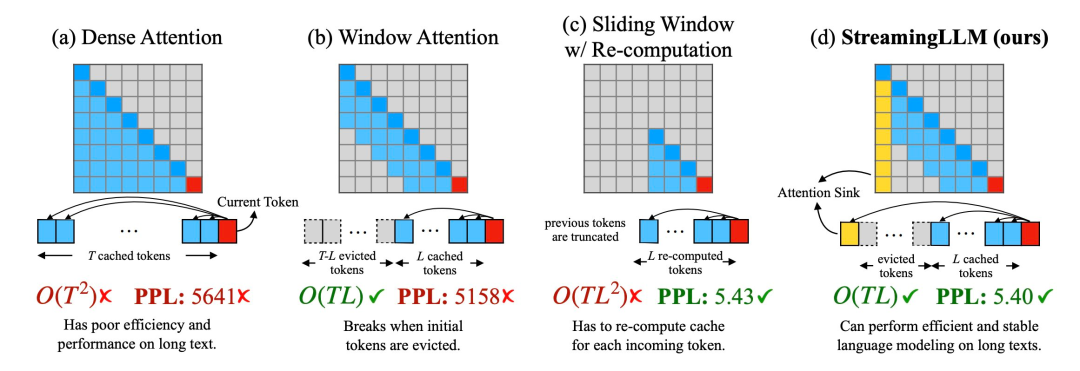
一種直覺的方法稱為視窗注意力(Window Attention)(如圖1 b),這種方法只在最近token的KV 狀態上保持一個固定大小的滑動窗口,雖然能確保在緩存填滿後仍能保持穩定的內存使用率和解碼速度,但一旦序列長度超過緩存大小,甚至只是驅逐第一個token 的KV,模型就會崩潰。另一種方法是重新計算滑動視窗(如圖1 c 所示),這種方法會為每個產生的token 重建最近token 的KV 狀態,雖然效能強大,但需要在視窗內計算二次注意力,因此速度明顯較慢,在實際的串流應用上並不理想。
在研究視窗注意力失效的過程中,研究人員發現了一個有趣的現象:根據圖2顯示,大量的注意力分數被分配給了初始的標記,而不論這些標記是否與語言建模任務相關
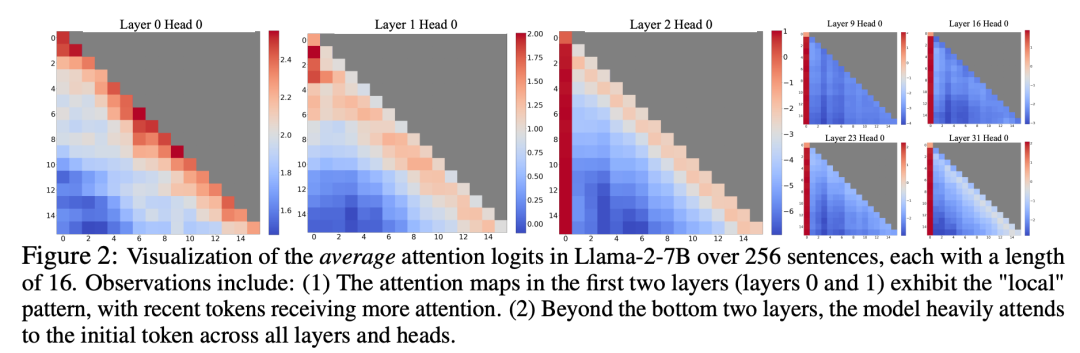
#研究者將這些token 稱為「注意力池」:儘管它們缺乏語意上的意義,但卻佔據了大量的注意力分數。研究者將這一現象歸因於Softmax(要求所有上下文token 的注意力分數總和為1),即使當前查詢在許多以前的token 中沒有很強的匹配,模型仍然需要將這些不需要的注意力值分配到某處,從而使其總和為1。初始 token 成為「池」的原因很直觀:由於自回歸語言建模的特性,初始 token 對幾乎所有後續 token 都是可見的,這使得它們更容易被訓練成註意力池。
根據上述洞察,研究者提出了StreamingLLM。這是一個簡單而高效的框架,可以讓使用有限注意力視窗訓練的注意力模型在不進行微調的情況下處理無限長的文字
StreamingLLM 利用了注意力池具有高注意力值這一事實,保留這些注意力池可以使注意力分數分佈接近常態分佈。因此,StreamingLLM 只需保留注意力池 token 的 KV 值(只需 4 個初始 token 即可)和滑動視窗的 KV 值,就能錨定注意力計算並穩定模型的效能。
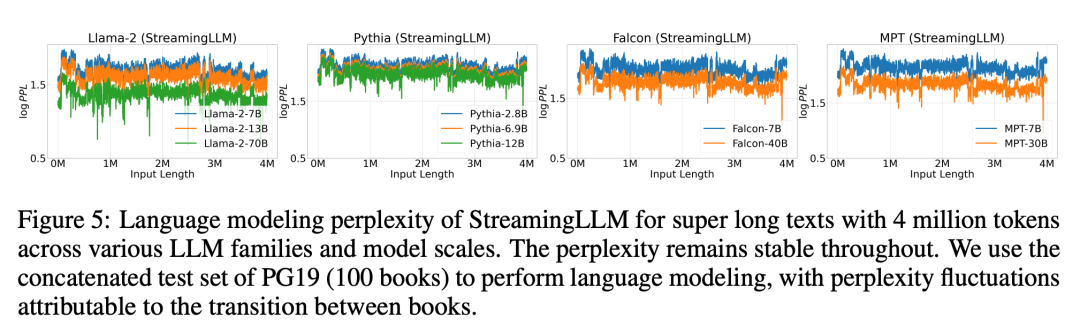
使用StreamingLLM,包括Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B 和Pythia [2.9 ,6.9,12] B 在內的模型可以可靠地模擬400 萬個token,甚至更多。
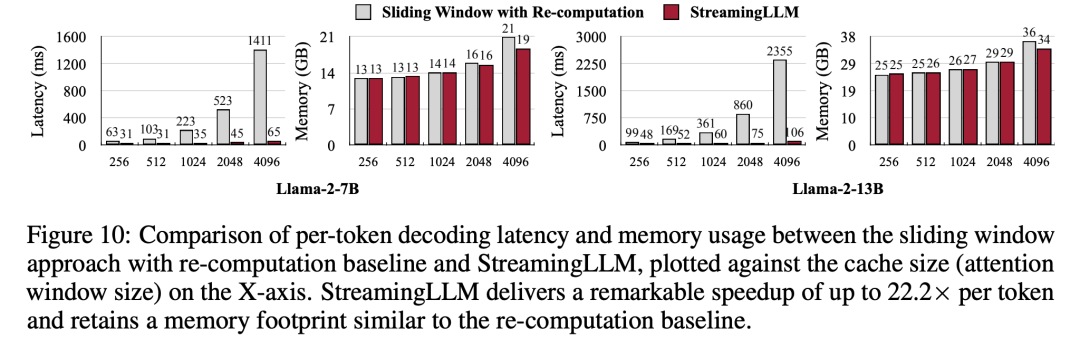
與重新計算滑動視窗相比,StreamingLLM 的速度提高了22.2倍,而沒有影響效能的損失
#在實驗中,如圖3所示,對於跨度為20K個標記的文本,StreamingLLM的困惑度與重新計算滑動視窗的Oracle基準相當。同時,當輸入長度超過預訓練視窗時,密集注意力會失效,而當輸入長度超過快取大小時,視窗注意力會陷入困境,導致初始標記被剔除
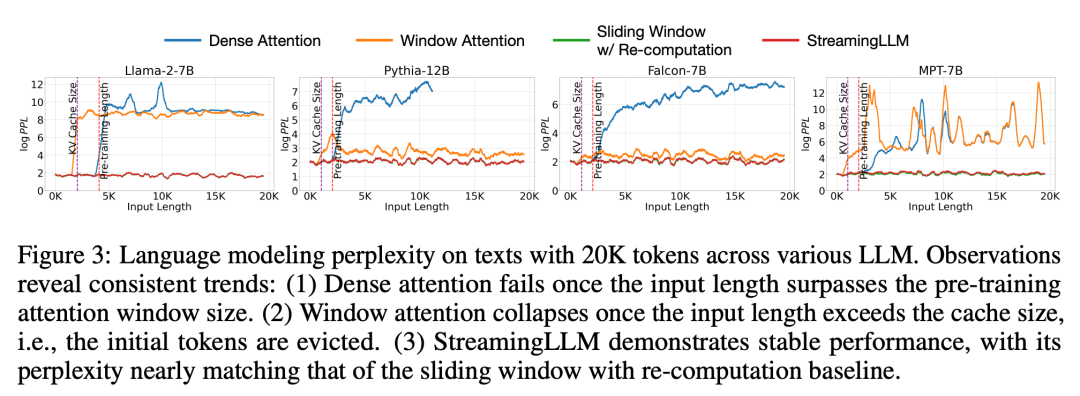
圖5 進一步證實了StreamingLLM 的可靠性,它可以處理非常規規模的文本,包括400 多萬個標記,涵蓋了各種模型系列和規模。這些模型包括Llama-2-[7,13,70] B、Falcon-[7,40] B、Pythia-[2.8,6.9,12] B 和MPT-[7,30] B
#隨後,研究者證實了「注意力池」的假設,並證明語言模型可以通過預訓練,在流式部署時只需要一個注意力池token。具體來說,他們建議在所有訓練樣本的開頭多加一個可學習的 token,作為指定的注意力池。透過從頭開始預訓練 1.6 億個參數的語言模型,研究者證明了本文方法可以維持模型的效能。這與目前的語言模型形成了鮮明對比,後者需要重新引入多個初始 token 作為注意力池才能達到相同的表現水準。
最後,研究者進行了StreamingLLM 的解碼延遲和記憶體使用率與重新計算滑動視窗的比較,並在單一英偉達A6000 GPU 上使用Llama-2-7B 和Llama- 2-13B 模型進行了測試。根據圖10的結果顯示,隨著快取大小的增加,StreamingLLM 的解碼速度呈現線性成長,而解碼延遲則呈現二次曲線上升。實驗證明,StreamingLLM 實現了令人印象深刻的提速,每個token 的速度提升高達22.2倍
##更多研究細節,可參考原論文。
以上是最多400萬token上下文、推理加速22倍,StreamingLLM火了,已獲GitHub 2.5K星的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















