

紙投Nature先問GPT-4!史丹佛實測5000篇,一半意見跟人類評審沒差別

GPT-4有能力做論文評審嗎?
來自史丹佛等大學的研究人員還真測試了一把。
他們丟給GPT-4數千篇來自Nature、ICLR等頂會的文章,讓它產生評審意見(包括修改建議啥的),然後與人類給的意見進行比較。
經過調查,我們發現:
GPT-4提出的超50%觀點與至少一名人類評審員一致;
並且有超過82.4%的作者發現GPT-4提供的意見非常有幫助
這項研究能為我們帶來哪些啟示呢?
結論是:
高品質的人類回饋仍然不可替代;但GPT-4可以幫助作者在正式同儕審查前改進初稿。

具體來看。
實測GPT-4論文評審水準
為了證明GPT-4的潛力,研究人員先用GPT-4創造了一個自動pipeline
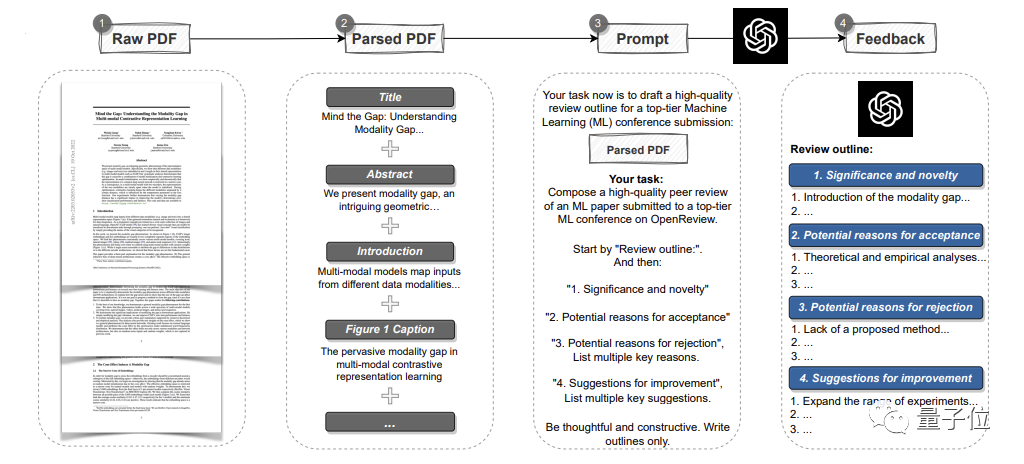 # #。
# #。
它能夠分析整篇PDF格式的論文,提取標題、摘要、圖表、表格標題等內容,以建立提示語然後讓GPT-4提供評審意見。 其中,意見和各頂會的標準一樣,共包含四個部分:
研究的重要性和新穎性,以及可能被接受或拒絕的原因和改進建議
具體實驗從兩方面展開。
首先是量化實驗: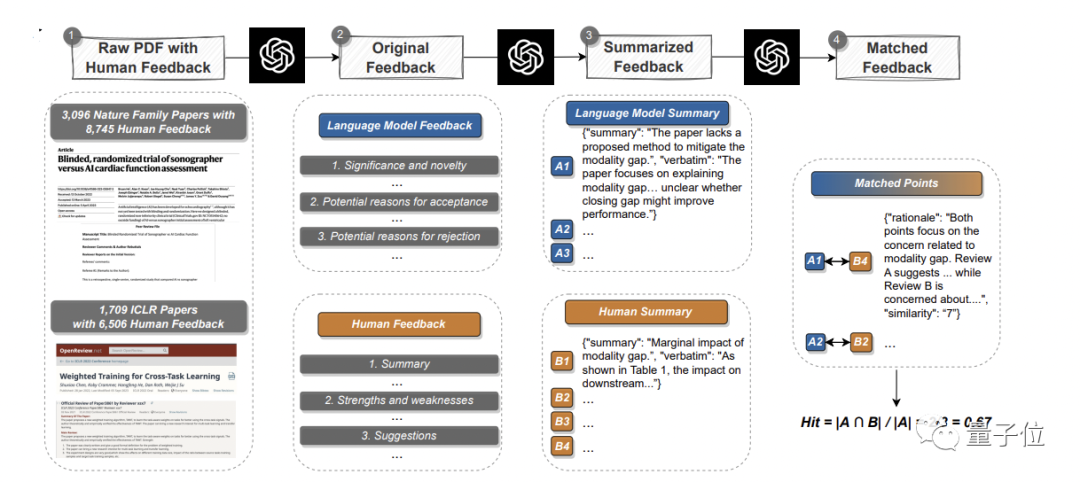
閱讀現有論文,產生回饋,並與真實人類觀點進行系統比較,以找出重疊部分
在此,團隊從Nature正刊和各大子刊挑選了3096篇文章,從ICLR機器學習會議
(包含去年和今年)挑選了1709篇,共計4805篇。 其中,Nature論文共涉及8745條人類評審意見;ICLR會議涉及6506條。
 GPT-4給出意見之後,pipeline就在match環節分別提取人類和GPT-4的論點,然後進行語義文本匹配,找到重疊的論點,以此來衡量GPT-4意見的有效性和可靠性。
GPT-4給出意見之後,pipeline就在match環節分別提取人類和GPT-4的論點,然後進行語義文本匹配,找到重疊的論點,以此來衡量GPT-4意見的有效性和可靠性。
結果是:
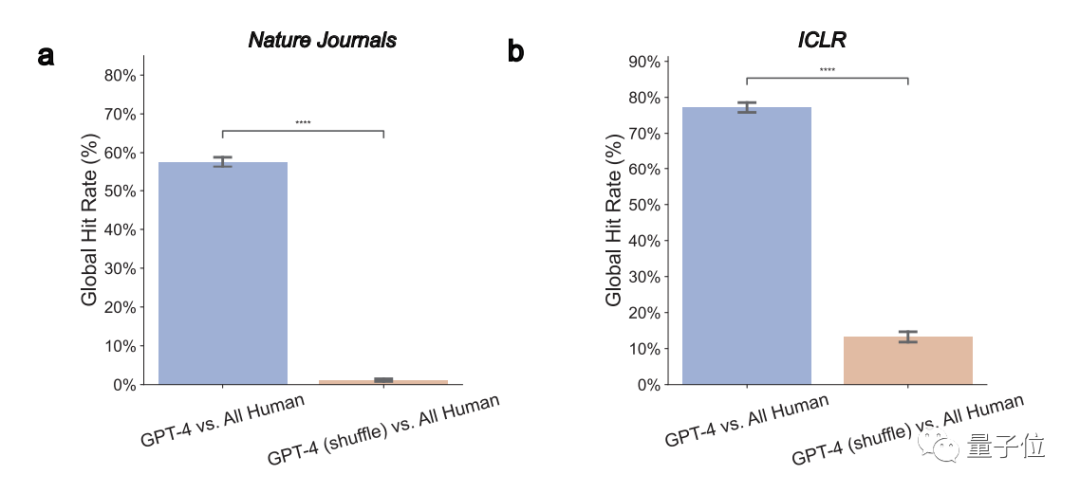
1、GPT-4意見與人類評審員真實意見顯著重疊整體來看,在Nature論文中, GPT-4有57.55%的意見與至少一位人類評審員一致;在ICLR中,這個數字則高達77.18%。
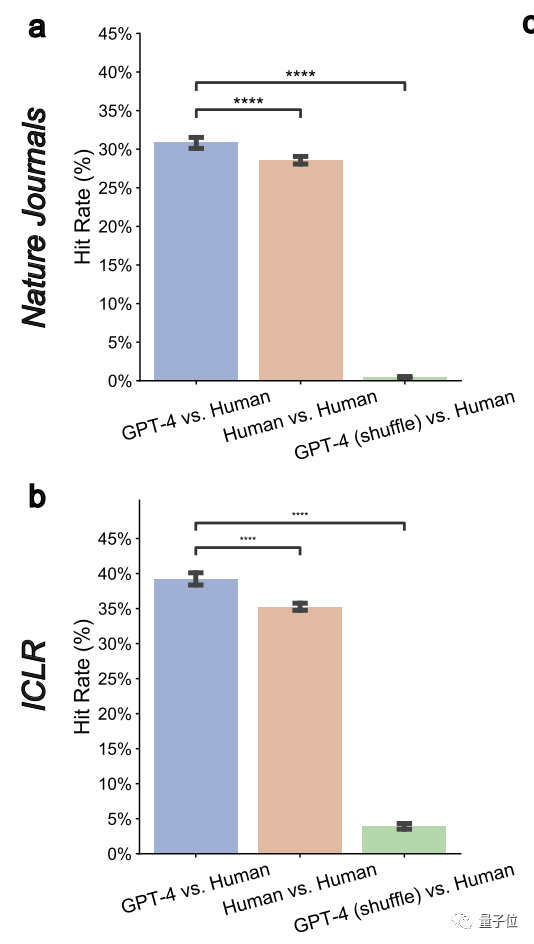
再進一步仔細比較GPT-4與每位評審員的意見之後,團隊又發現:GPT-4在Nature論文上和人類評審員的重疊率下降為30.85%,在ICLR上降至39.23%。
然而,這與兩位人類審查者之間的重疊率相當
在Nature論文中,人類的平均重疊率為28.58%;而在ICLR上則為35.25%
此外,他們也透過分析論文的等級等級(oral、spotlight、或直接被拒絕的)
發現:對於程度較弱的論文而言,GPT-4和人類審查者之間的重疊率有望提高。從目前的30%多,可以增加到接近50%這表明,GPT-4具有很高的辨別能力,可以辨別出水平較差的論文#作者也因此表示,那些需要更實質修改才能被接收的論文有福了,大夥兒可以在正式提交前多試試GPT-4給出的修改意見。2、GPT-4能夠提供非通用的回饋
######所謂非一般回饋,即GPT-4不會給予一個適用於多篇論文的通用評審意見。 ######在此,作者們衡量了一個「成對重疊率」的指標,結果發現它在Nature和ICLR上都顯著降低到了0.43%和3.91%。 ######這顯示GPT-4具有特定目標#########3、能夠與人類觀點在重大、普遍問題上達成一致######一般而言,那些最早出現並且被多個評審員提及的意見,往往代表著重要且普遍存在的問題
#在這裡,團隊還發現LLM更有可能識別出多個評審員一致認可的常見問題或缺陷
GPT-4在整體上表現尚可
4、GPT-4給的意見更強調一些與人類不同的面向
研究發現,GPT-4評論研究本身意義的頻率是人類的7.27倍,而評論研究新穎性的可能性是人類的10.69倍。
以及GPT-4和人類都經常建議進行額外的實驗,但人類更關註消融實驗,GPT-4更建議在更多資料集上嘗試。
作者表示,這些發現表明,GPT-4和人類評審員在各方面的重視程度各不相同,兩者合作可能帶來潛在優勢。
定量實驗之外是使用者研究#。
本研究共有308名來自不同機構的AI和計算生物學領域的研究員參與,他們將各自的論文上傳給GPT-4進行評審
研究團隊收集了他們對GPT-4評審意見的真實回饋。
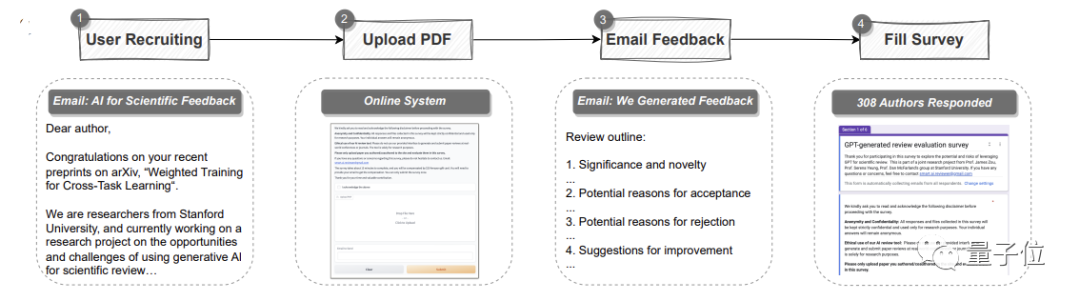
總體而言,超過一半(57.4%)的參與者認為GPT-4產生的回饋很有幫助,包括給到一些人類想不到的點。
以及82.4%的調查者認為它比至少一些人類評審員的回饋更有益。
此外,有超過一半的人(50.5%)表示,願意進一步使用GPT-4等大模型來改進論文。
其中一人表示,只需要5分鐘GPT-4就給了結果,這個回饋速度真的非常快,對研究人員改善論文很有幫助。
當然,作者強調:
GPT-4的能力也有一些限制
最明顯的是它更關注於“整體佈局”,缺少特定技術領域(例如模型架構)的深度建議。
因此,正如作者最後的結論所述:
在正式評審之前,人類評審員的高品質回饋是非常重要的,但我們可以先試水一下,以彌補實驗和建構等方面的細節可能被遺漏的情況
當然,他們也提醒:
正式評審中,審稿人應該還是獨立參與,不依賴任何LLM。
一作都是華人
本研究一作共三位,都是華人,都來自史丹佛大學電腦科學學院。

他們分別是:
- 梁偉欣,該校博士生,也是斯坦福AI實驗室(SAIL)成員。他碩士畢業於史丹佛電機工程專業,本科畢業於浙江大學計算機科學。
- Yuhui Zhang,同博士生在讀,研究方向為多模態AI系統。清華本科畢業,史丹佛碩士畢業。
- 曹瀚成,該校五年級博士在讀,輔修管理科學與工程,同時加入了史丹佛大學NLP和HCI小組。此前畢業於清華大學電子工程學系大學部。
論文連結:https://arxiv.org/abs/2310.01783
#以上是紙投Nature先問GPT-4!史丹佛實測5000篇,一半意見跟人類評審沒差別的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 比特幣成品結構分析圖是啥?怎麼畫?
Apr 21, 2025 pm 07:42 PM
比特幣成品結構分析圖是啥?怎麼畫?
Apr 21, 2025 pm 07:42 PM
繪製比特幣結構分析圖的步驟包括:1. 確定繪圖目的與受眾,2. 選擇合適的工具,3. 設計框架並填充核心組件,4. 參考現有模板。完整的步驟確保圖表準確且易於理解。
 跨鏈交易什麼意思?跨鏈交易所有哪些?
Apr 21, 2025 pm 11:39 PM
跨鏈交易什麼意思?跨鏈交易所有哪些?
Apr 21, 2025 pm 11:39 PM
支持跨鏈交易的交易所有:1. Binance,2. Uniswap,3. SushiSwap,4. Curve Finance,5. Thorchain,6. 1inch Exchange,7. DLN Trade,這些平台通過各種技術支持多鏈資產交易。
 幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
適合新手的加密貨幣數據平台有CoinMarketCap和非小號。 1. CoinMarketCap提供全球加密貨幣實時價格、市值、交易量排名,適合新手與基礎分析需求。 2. 非小號提供中文友好界面,適合中文用戶快速篩選低風險潛力項目。
 Aavenomics是修改AAVE協議令牌並介紹令牌回購的建議,已達到法定人數
Apr 21, 2025 pm 06:24 PM
Aavenomics是修改AAVE協議令牌並介紹令牌回購的建議,已達到法定人數
Apr 21, 2025 pm 06:24 PM
Aavenomics是修改AAVE協議令牌並引入令牌回購的提議,已為AAVEDAO實現了一個法定人數。 AAVE連鎖計劃(ACI)創始人馬克·澤勒(MarcZeller)在X上宣布了這一點,並指出它標誌著該協議的新時代。 AAVE連鎖倡議(ACI)創始人MarcZeller在X上宣布,Aavenomics提案包括修改AAVE協議令牌和引入令牌回購,已為AAVEDAO實現了法定人數。根據Zeller的說法,這標誌著該協議的新時代。 AaveDao成員以壓倒性的投票支持該提議,即在周三以每週100
 幣圈槓桿交易所排名 幣圈十大槓桿交易所APP最新推薦
Apr 21, 2025 pm 11:24 PM
幣圈槓桿交易所排名 幣圈十大槓桿交易所APP最新推薦
Apr 21, 2025 pm 11:24 PM
2025年在槓桿交易、安全性和用戶體驗方面表現突出的平台有:1. OKX,適合高頻交易者,提供最高100倍槓桿;2. Binance,適用於全球多幣種交易者,提供125倍高槓桿;3. Gate.io,適合衍生品專業玩家,提供100倍槓桿;4. Bitget,適用於新手及社交化交易者,提供最高100倍槓桿;5. Kraken,適合穩健型投資者,提供5倍槓桿;6. Bybit,適用於山寨幣探索者,提供20倍槓桿;7. KuCoin,適合低成本交易者,提供10倍槓桿;8. Bitfinex,適合資深玩
 混合型區塊鏈交易平台有哪些
Apr 21, 2025 pm 11:36 PM
混合型區塊鏈交易平台有哪些
Apr 21, 2025 pm 11:36 PM
選擇加密貨幣交易所的建議:1. 流動性需求,優先選擇幣安、Gate.io或OKX,因其訂單深度與抗波動能力強。 2. 合規與安全,Coinbase、Kraken、Gemini具備嚴格監管背書。 3. 創新功能,KuCoin的軟質押和Bybit的衍生品設計適合進階用戶。
 各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
機構投資者應選擇Coinbase Pro和Genesis Trading等合規平台,關注冷存儲比例與審計透明度;散戶投資者應選擇幣安和火幣等大平台,注重用戶體驗與安全;合規敏感地區的用戶可通過Circle Trade和Huobi Global進行法幣交易,中國大陸用戶需通過合規場外渠道。
 十大加密貨幣交易所平台 世界最大的數字貨幣交易所榜單
Apr 21, 2025 pm 07:15 PM
十大加密貨幣交易所平台 世界最大的數字貨幣交易所榜單
Apr 21, 2025 pm 07:15 PM
在當今的加密貨幣市場中,交易所扮演著至關重要的角色,它們不僅是投資者進行買賣交易的平台,更是市場流動性和價格發現的重要來源。全球最大的虛擬貨幣交易所排行前十,這些交易所不僅在交易量上遙遙領先,而且在用戶體驗、安全性和創新服務方面也各有千秋。排行榜首的交易所通常擁有龐大的用戶基礎和廣泛的市場影響力,它們的交易量和資產種類往往是其他交易所難以企及的。
