

實戰部署:動態時序網路用於端到端偵測和追蹤

本文經自動駕駛之心公眾號授權轉載,轉載請聯絡來源。
相信除了少數自研晶片的大廠,絕大多數自動駕駛公司都會使用英偉達NVIDIA晶片,那就離不開TensorRT. TensorRT是在NVIDIA各種GPU硬體平台下運行的一個C 推理框架。我們利用Pytorch、TF或其他框架訓練好的模型,可以先轉化為onnx格式,再轉化為TensorRT的格式,然後利用TensorRT推理引擎去運行我們這個模型,從而提升這個模型在英偉達GPU上運行的速度。
一般來說,onnx和TensorRT僅支援相對比較固定的模型(包括各級的輸入輸出格式固定,單分支等),最多支援最外層動態輸入(導出onnx可以透過設定dynamic_axes參數確定允許動態變化的維度).但活躍在感知算法前沿的小伙伴們都會知道,目前一個重要發展趨勢就是端到端(End-2-End),可能涵蓋了目標檢測,目標跟踪,軌跡預測,決策規劃等全部自動駕駛環節,而且必定是前後幀緊密相關的時序模型.實現了目標檢測和目標跟踪端到端的MUTR3D模型可以作為一個典型例子(模型介紹可參考:)
#在MOTR/MUTR3D中,我們將詳細解釋Label Assignment機制的理論和實例,以實現真正的端到端多目標追蹤。請點擊連結閱讀更多:https://zhuanlan.zhihu.com/p/609123786
這種模型的轉換為TensorRT格式並實現精度對齊,甚至fp16的精度對齊,可能會面臨一系列的動態元素,例如多個if-else分支、子網路輸入形狀的動態變化以及其他需要動態處理的操作和算子等
 ##圖片
##圖片
解決這個問題受了DN-DETR[1]的啟發,那就是使用attention_mask,在nn.MultiheadAttention中對應'attn_mask'參數,作用就是屏蔽掉不需要進行信息交互的query,最初是因為在NLP中每個句子長度不一致而設定的,正好符合我現在的需求,只是需要注意True代表需要屏蔽的query,False代表有效query.
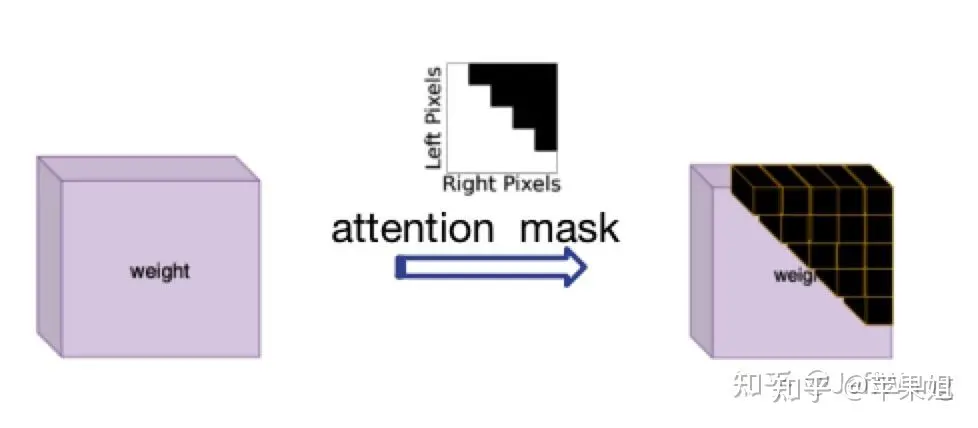 圖片
圖片
attention mask示意圖因為計算attention_mask邏輯稍微有點複雜,很多操作轉換TensorRT可能出現新問題,所以也應該在模型外計算好之後作為一個輸入變量輸入模型,再傳遞給transformer.以下是示例代碼:
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
4.padding對於QIM的影響
QIM是MUTR3D中對transformer輸出的query進行的後處理模組,主要分三步,第一步是篩選active query,即在在當前幀中檢測出目標的query,依據是obj_idxs是否>=0(在訓練階段還包括隨機drop query,和隨機加入fp query,推理階段不涉及),第二步是update query,即針對第一步中篩選的query做一個更新,包括query 輸出值的self-attention,ffn,和與query輸入值的shortcut連接,第三步是將更新的query與重新生成的初始query拼接,作為下一幀的輸入.可見第二步中仍然存在我們在第3點中提到的問題,即self-attention不做全部query之間的交互,而是只進行active query之間的信息交互.所以在這裡又要使用attention mask.
雖然QIM模組是可選的,但實驗表明對模型精度的提升是有幫助的.如果要使用QIM的話,這個attention mask必須在模型裡計算,因為模型外部無法得知當前幀的檢測結果.由於tensorRT的語法限制,很多操作要么會轉換不成功,要么不會得到想要的結果,經過多次實驗,結論是直接用索引切片賦值(類似於第3點的示例程式碼)操作一般不支援,最好用矩陣計算的方式,但涉及計算必須將attention mask的bool類型轉為float類型,最後attention mask需要轉回bool類型才能使用.以下是實例代碼:
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
5.padding對於輸出結果的影響
進行完以上四點,我們基本上可以保證模型轉換tensorRT的邏輯沒有問題,但輸出結果經過多次驗證後某些幀仍然存在問題一度讓我很不解.但一幀幀從數據上分析,就會發現竟然在某些幀padding的query雖然沒有參與transformer計算,卻可以得到一個較高的score,進而得到錯誤的結果.這種情況在資料量大的情況下確實是可能的,因為padding的query只是初始值是0,reference points也是[0,0],與其他隨機初始化的query進行了同樣的操作.但由於畢竟是padding的query ,我們並不打算使用他們的結果,所以必須要進行過濾.
如何過濾填充查詢的結果呢?填充查詢的標誌只有它們的索引位置,其他資訊都沒有特異性。而索引資訊實際上記錄在第3點使用的注意力遮罩中,這個注意力掩碼是從模型外部傳入的。這個遮罩是二維的,我們可以使用其中的一維(任一行或任一列),將填入的track_score直接置為0。請記住仍然要注意第4步的注意事項,即盡量使用矩陣計算來代替索引切片賦值,並且計算必須轉換為float類型。以下是程式碼範例:
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
6.如何動態更新track_id
除了模型主體,其實還有非常關鍵的一步,就是動態更新track_id,這也是模型能做到端到端的一個重要因素.但在原模型中更新track_id的方式是一個相對複雜的循環判斷, 即高於score thresh且是新目標的,賦一個新的obj_idx, 低於filter score thresh且是老目標的,對應的disappear time 1,如果disappear time超過miss_tolerance, 對應的obj idx置為-1,即丟棄這個目標.
我們知道tensorRT是不支援if-else多分支語句的(好吧,我一開始不知道),這是個頭痛的問題.如果將更新track_id也放到模型外部,不僅影響了模型端到端的架構,而且也會導致無法使用QIM,因為QIM篩選query的依據是更新後的track_id.所以絞盡腦汁也要把更新track_id放到模型裡面去.
再次發揮聰明才智(快用完了),if-else語句也不是不能代替的,比如使用mask並行操作.例如將條件轉換為mask(例如tensor[mask] = 0).這裡面值得慶幸的是雖然第4,第5點提到tensorRT不支援索引切片賦值操作,但是卻支援bool索引賦值,猜測可能因為切片操作隱性改變了tensor的shape吧.但經過多次實驗,也不是所有情況下的bool索引賦值都支持的,出現了以下幾種頭疼的情況:
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
以上是實戰部署:動態時序網路用於端到端偵測和追蹤的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
原文標題:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving論文連結:https://arxiv.org/pdf/2402.02519.pdf程式碼連結:https://github.com/HKUST-Aerial-Robotics/SIMPLobotics單位論文想法:本文提出了一種用於自動駕駛車輛的簡單且有效率的運動預測基線(SIMPL)。與傳統的以代理為中心(agent-cent
 DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
這篇論文探討了在自動駕駛中,從不同視角(如透視圖和鳥瞰圖)準確檢測物體的問題,特別是如何有效地從透視圖(PV)到鳥瞰圖(BEV)空間轉換特徵,這一轉換是透過視覺轉換(VT)模組實施的。現有的方法大致分為兩種策略:2D到3D和3D到2D轉換。 2D到3D的方法透過預測深度機率來提升密集的2D特徵,但深度預測的固有不確定性,尤其是在遠處區域,可能會引入不準確性。而3D到2D的方法通常使用3D查詢來採樣2D特徵,並透過Transformer學習3D和2D特徵之間對應關係的注意力權重,這增加了計算和部署的
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
