

揭开正则表达式语法的神秘面纱_PHP

正则表达式
正则表达式(REs)通常被错误地认为是只有少数人理解的一种神秘语言。在表面上它们确实看起来杂乱无章,如果你不知道它的语法,那么它的代码在你眼里只是一堆文字垃圾而已。实际上,正则表达式是非常简单并且可以被理解。读完这篇文章后,你将会通晓正则表达式的通用语法。支持多种平台
正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group组织认定。
正则表达式并非一门专用语言,但它可用于在一个文件或字符里查找和替代文本的一种标准。它具有两种标准:基本的正则表达式(BRE),扩展的正则表达式(ERE)。ERE包括BRE功能和另外其它的概念。
许多程序中都使用了正则表达式,包括xsh,egrep,sed,vi以及在UNIX平台下的程序。它们可以被很多语言采纳,如HTML 和XML,这些采纳通常只是整个标准的一个子集。
比你想象的还要普通
随着正则表达式移植到交叉平台的程序语言的发展,这的功能也日益完整,使用也逐渐广泛。网络上的搜索引擎使用它,e-mail程序也使用它,即使你不是一个UNIX程序员,你也可以使用规则语言来简化你的程序而缩短你的开发时间。
正则表达式101
很多正则表达式的语法看起来很相似,这是因为你以前你没有研究过它们。通配符是RE的一个结构类型,即重复操作。让我们先看一看ERE标准的最通用的基本语法类型。为了能够提供具有特定用途的范例,我将使用几个不同的程序。
字符匹配
正则表达式的关键之处在于确定你要搜索匹配的东西,如果没有这一概念,Res将毫无用处。
每一个表达式都包含需要查找的指令,如表A所示。
|
Table A: Character-matching regular expressions |
|||
|
操作 |
解释 |
例子 |
结果 |
|
. |
Match any one character |
grep .ord sample.txt |
Will match “ford”, “lord”, “2ord”, etc. in the file sample.txt. |
|
[ ] |
Match any one character listed between the brackets |
grep [cng]ord sample.txt |
Will match only “cord”, “nord”, and “gord” |
|
[^ ] |
Match any one character not listed between the brackets |
grep [^cn]ord sample.txt |
Will match “lord”, “2ord”, etc. but not “cord” or “nord” |
|
|
|
grep [a-zA-Z]ord sample.txt |
Will match “aord”, “bord”, “Aord”, “Bord”, etc. |
|
|
|
grep [^0-9]ord sample.txt |
Will match “Aord”, “aord”, etc. but not “2ord”, etc. |
重复操作符
重复操作符,或数量词,都描述了查找一个特定字符的次数。它们常被用于字符匹配语法以查找多行的字符,可参见表B。
|
Table B: Regular expression repetition operators |
|||
|
操作 |
解释 |
例子 |
结果 |
|
? |
Match any character one time, if it exists |
egrep “?erd” sample.txt |
Will match “berd”, “herd”, etc. and “erd” |
|
* |
Match declared element multiple times, if it exists |
egrep “n.*rd” sample.txt |
Will match “nerd”, “nrd”, “neard”, etc. |
|
+ |
Match declared element one or more times |
egrep “[n]+erd” sample.txt |
Will match “nerd”, “nnerd”, etc., but not “erd” |
|
{n} |
Match declared element exactly n times |
egrep “[a-z]{2}erd” sample.txt |
Will match “cherd”, “blerd”, etc. but not “nerd”, “erd”, “buzzerd”, etc. |
|
{n,} |
Match declared element at least n times |
egrep “.{2,}erd” sample.txt |
Will match “cherd” and “buzzerd”, but not “nerd” |
|
{n,N} |
Match declared element at least n times, but not more than N times |
egrep “n[e]{1,2}rd” sample.txt |
Will match “nerd” and “neerd” |
锚是指它所要匹配的格式,如图C所示。使用它能方便你查找通用字符的合并。例如,我用vi行编辑器命令:s来代表substitute,这一命令的基本语法是:
s/pattern_to_match/pattern_to_substitute/
|
Table C: Regular expression anchors |
|||
|
操作 |
解释 |
例子 |
结果 |
|
^ |
Match at the beginning of a line |
s/^/blah / |
Inserts “blah “ at the beginning of the line |
|
$ |
Match at the end of a line |
s/$/ blah/ |
Inserts “ blah” at the end of the line |
|
\ |
Match at the beginning of a word |
s/\/ |
Inserts “blah” at the beginning of the word |
|
|
|
egrep “\ |
Matches “blahfield”, etc. |
|
\> |
Match at the end of a word |
s/\>/blah/ |
Inserts “blah” at the end of the word |
|
|
|
egrep “\>blah” sample.txt |
Matches “soupblah”, etc. |
|
\b |
Match at the beginning or end of a word |
egrep “\bblah” sample.txt |
Matches “blahcake” and “countblah” |
|
\B |
Match in the middle of a word |
egrep “\Bblah” sample.txt |
Matches “sublahper”, etc. |
间隔
Res中的另一可便之处是间隔(或插入)符号。实际上,这一符号相当于一个OR语句并代表|符号。下面的语句返回文件sample.txt中的“nerd” 和 “merd”的句柄:
egrep “(n|m)erd” sample.txt
间隔功能非常强大,特别是当你寻找文件不同拼写的时候,但你可以在下面的例子得到相同的结果:
egrep “[nm]erd” sample.txt
当你使用间隔功能与Res的高级特性连接在一起时,它的真正用处更能体现出来。
一些保留字符
Res的最后一个最重要特性是保留字符(也称特定字符)。例如,如果你想要查找“ne*rd”和“ni*rd”的字符,格式匹配语句“n[ei]*rd”与“neeeeerd” 和 “nieieierd”相符合,但并不是你要查找的字符。因为‘*’(星号)是个保留字符,你必须用一个反斜线符号来替代它,即:“n[ei]\*rd”。其它的保留字符包括:
- ^ (carat)
- . (period)
- [ (left bracket}
- $ (dollar sign)
- ( (left parenthesis)
- ) (right parenthesis)
- | (pipe)
- * (asterisk)
- + (plus symbol)
- ? (question mark)
- { (left curly bracket, or left brace)
- \ backslash
一旦你把以上这些字符包括在你的字符搜索中,毫无疑问Res变得非常的难读。比如说以下的PHP中的eregi搜索引擎代码就很难读了。
eregi("^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$",$sendto)
你可以看到,程序的意图很难把握。但如果你抛开保留字符,你常常会错误地理解代码的意思。
总结
在本文中,我们揭开了正则表达式的神秘面纱,并列出了ERE标准的通用语法。如果你想阅览Open Group组织的规则的完整描述,你可以参见:Regular Expressions,欢迎你在其中的讨论区发表你的问题或观点。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何快速地把你的 Python 程式碼變成 API
Apr 14, 2023 pm 06:28 PM
如何快速地把你的 Python 程式碼變成 API
Apr 14, 2023 pm 06:28 PM
提到API開發,你可能會想到DjangoRESTFramework,Flask,FastAPI,沒錯,它們完全可以用來寫API,不過,今天分享的這個框架可以讓你更快把現有的函數轉化為API,它就是Sanic 。 Sanic簡介Sanic[1],是Python3.7+Web伺服器和Web框架,旨在提高效能。它允許使用Python3.5中添加的async/await語法,這可以有效避免阻塞從而達到提升響應速度的目的。 Sanic致力於提供一種簡單且快速,集創建和啟動於一體的方法
 使用java的Character.isDigit()函數判斷字元是否為數字
Jul 27, 2023 am 09:32 AM
使用java的Character.isDigit()函數判斷字元是否為數字
Jul 27, 2023 am 09:32 AM
使用Java的Character.isDigit()函數判斷字元是否為數字字元在電腦內部以ASCII碼的形式表示,每個字元都有一個對應的ASCII碼。其中,數字字元0到9分別對應的ASCII碼值為48到57。要判斷一個字元是否為數字,可以使用Java中的Character類別提供的isDigit()方法來判斷。 isDigit()方法是Character類別的
 如何在 Word 中鍵入箭頭
Apr 16, 2023 pm 11:37 PM
如何在 Word 中鍵入箭頭
Apr 16, 2023 pm 11:37 PM
如何使用自動更正在 Word 中鍵入箭頭在 Word 中鍵入箭頭的最快方法之一是使用預先定義的自動修正捷徑。如果您鍵入特定的字元序列,Word 會自動將這些字元轉換為箭頭符號。您可以使用此方法繪製多種不同的箭頭樣式。若要使用自動更正在 Word 中鍵入箭頭:將遊標移到文件中要顯示箭頭的位置。鍵入以下字元組合之一:如果您不希望將您鍵入的內容更正為箭頭符號,請按鍵盤上的退格鍵會將
 如何在 iPhone 和 Mac 上輸入擴充字符,例如度數符號?
Apr 22, 2023 pm 02:01 PM
如何在 iPhone 和 Mac 上輸入擴充字符,例如度數符號?
Apr 22, 2023 pm 02:01 PM
您的實體或數位鍵盤在表面上提供有限數量的字元選項。但是,有幾種方法可以在iPhone、iPad和Mac上存取重音字母、特殊字元等。標準iOS鍵盤可讓您快速存取大寫和小寫字母、標準數字、標點符號和字元。當然,還有很多其他角色。您可以從帶有變音符號的字母到倒置的問號中進行選擇。您可能無意中發現了隱藏的特殊字元。如果沒有,以下是在iPhone、iPad和Mac上存取它們的方法。如何在iPhone和iPad上存取擴充字元在iPhone或iPad上取得擴充字元非常簡單。在「訊息」、「
 正確在matplotlib中顯示中文字元的方法
Jan 13, 2024 am 11:03 AM
正確在matplotlib中顯示中文字元的方法
Jan 13, 2024 am 11:03 AM
在matplotlib中正確地顯示中文字符,是許多中文使用者常常遇到的問題。預設情況下,matplotlib使用的是英文字體,無法正確顯示中文字元。為了解決這個問題,我們需要設定正確的中文字體,並將其應用到matplotlib中。以下是一些具體的程式碼範例,幫助你正確地在matplotlib中顯示中文字元。首先,我們需要導入需要的函式庫:importmatplot
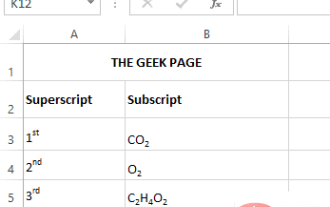 如何在 Microsoft Excel 中套用上標和下標格式選項
Apr 14, 2023 pm 12:07 PM
如何在 Microsoft Excel 中套用上標和下標格式選項
Apr 14, 2023 pm 12:07 PM
上標是一個字符或多個字符,可以是字母或數字,您需要將其設置為略高於正常文本行。例如,如果您需要寫1st,則字母st需要略高於字元1。同樣,下標是一組字符或單個字符,需要設置為略低於正常文本級別。例如,當你寫化學式時,你需要把數字放在正常字元行的下方。以下螢幕截圖顯示了上標和下標格式的一些範例。儘管這似乎是一項艱鉅的任務,但實際上將上標和下標格式應用於您的文字非常簡單。在本文中,我們將透過一些簡單的步驟說明如何輕鬆地使用上標或下標格式設定文字。希望你喜歡閱讀這篇文章。如何在 Excel 中套用上標
 lambda 表達式的語法和結構有什麼特色?
Apr 25, 2024 pm 01:12 PM
lambda 表達式的語法和結構有什麼特色?
Apr 25, 2024 pm 01:12 PM
Lambda表達式是無名稱的匿名函數,其語法為:(parameter_list)->expression。它們具有匿名性、多樣性、柯里化和閉包等特徵。在實際應用中,Lambda表達式可用於簡潔地定義函數,如求和函數sum_lambda=lambdax,y:x+y,並透過map()函數應用於列表來進行求和操作。
 如何使用Golang判斷一個字元是否為字母
Dec 23, 2023 am 11:57 AM
如何使用Golang判斷一個字元是否為字母
Dec 23, 2023 am 11:57 AM
如何使用Golang判斷一個字元是否為字母在Golang中,判斷一個字元是否為字母可以透過使用Unicode包中的IsLetter函數來實現。 IsLetter函數會檢查給定的字元是否為字母。接下來,我們將詳細介紹如何使用Golang編寫程式碼來判斷一個字元是否為字母。首先,你需要建立一個新的Go文件,用於編寫程式碼。你可以將檔案命名為"main.go"。程式碼
