

世界模型大放異彩!這20多種自動駕駛場景數據的逼真程度令人難以置信...
Oct 09, 2023 pm 03:01 PM你認為這是一個普通無趣的自動駕駛影片嗎?

這段內容不需要改變原意,需要將其改寫為中文
沒有一幀是「真的」。

不同路況、各種天氣,20多種情境都能模擬,效果以假亂真。

世界模型再次展現出其強大的作用!這次,LeCun看到後都激動地轉發了

如上效果,由GAIA-1的最新版本帶來。
它規模達90億參數,用4700小時駕駛影片訓練,實現了輸入影片、文字或操作生成自動駕駛影片的效果。
帶來的最直接好處就是,更能預測未來事件。它可以模擬超過20種場景,從而進一步提高自動駕駛的安全性,並降低成本

#主創團隊表示,這將改變自動駕駛的遊戲規則!
GAIA-1是如何實現的?其實之前我們已經在自動駕駛的Daily中詳細介紹了Wayve團隊開發的GAIA-1:一種用於自動駕駛的生成式世界模型。如果你對此有興趣,可以去我們的公眾號閱讀相關內容!
規模越大效果越好
GAIA-1是一個多模態生成式世界模型,它能夠透過整合視覺、聽覺和語言等多種感知方式來理解和生成世界的表達。這個模型透過深度學習演算法,能夠從大量的資料中學習並推理出世界的結構和規律。 GAIA-1的目標是模擬人類的感知和認知能力,以便更好地理解和互動世界。它在許多領域都有廣泛的應用,包括自動駕駛、機器人技術和虛擬實境等。透過不斷地訓練和優化,GAIA-1將不斷進化和提升,成為一個更加智能和全面的世界模型
它使用視頻、文本和動作作為輸入,並生成逼真的駕駛場景視頻,同時可以對自動駕駛車輛的行為和場景特徵進行精細控制
而且可以僅透過文字提示來產生影片。

其模型原理類似於大型語言模型的原理,即預測下一個令牌
模型可以利用向量量化表示將視訊幀離散,然後預測未來場景,就轉換成了預測序列中的下一個token。然後再利用擴散模型從世界模型的語言空間產生高品質視訊。
具體步驟如下:
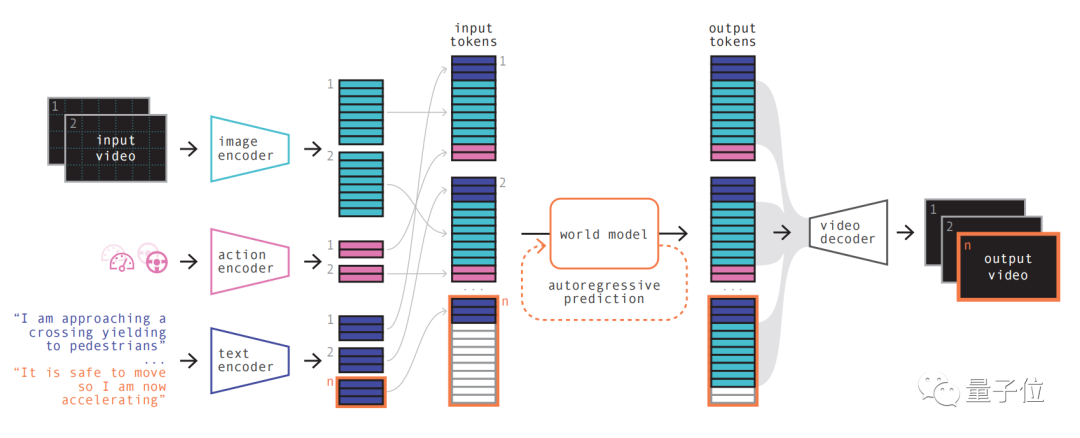
第一步簡單理解,就是對各種輸入進行重新編碼與排列組合。
透過使用專門的編碼器對各種輸入進行編碼,可以將不同的輸入投射到共享表示中。文字和視訊編碼器將輸入分離、嵌入,而操作表示則被單獨投射到共享表示中
這些編碼的表示具有時間的一致性
在進行排列之後,關鍵部分世界模型登場。
作為一個自回歸Transformer,它有能力預測序列中的下一組影像令牌。它不僅考慮了先前的圖像令牌,還要同時考慮文字和操作的上下文資訊
模型生成的內容不僅保持了圖像的一致性,還能與預測的文字和動作保持一致
團隊介紹,GAIA-1中的世界模型規模為65億參數,在64塊A100上訓練15天而成。
透過使用視訊解碼器和視訊擴散模型,最後將這些令牌轉換回視訊
這一步關乎視訊的語義品質、圖像準確性和時間一致性。
GAIA-1的視訊解碼器規模達26億參數規模,利用32台A100訓練15天而來。
值得一提的是,GAIA-1不僅和大語言模型原理相似,同時也呈現出了隨著模型規模擴大、產生品質提升的特點。

團隊對先前的6月份發布的早期版本和最新效果進行了對比
後者規模為前者的480倍。
可以直觀看影片在細節、解析度等方面都有明顯提升。

而從實際應用方面出發,GAIA-1也帶來了影響,其主創團隊表示,這會改變自動駕駛的規則。

原因來自三個面向:
- 安全
- 綜合訓練資料 ##長尾場景
Wayve。
Wayve成立於2017年,投資方有微軟等,估值已經達到了獨角獸。
創辦人為現任執行長亞歷克斯·肯德爾和艾瑪爾·沙(公司官網領導層頁已無其資訊),兩人均畢業於劍橋大學,擁有機器學習博士學位
LINGO-1也引發轟動。
這個自動駕駛模型在行車過程中能夠即時生成解說,從而進一步提高了模型的可解釋性今年3月,比爾·蓋茨還曾試乘過Wayve的自動駕駛汽車。
#論文網址:https://arxiv.org/abs/2309.17080

以上是世界模型大放異彩!這20多種自動駕駛場景數據的逼真程度令人難以置信...的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱門文章


熱門文章

熱門文章標籤

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)




 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一


 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇

 nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!

