
軌跡預測近兩年風頭正猛,但大都聚焦於車輛軌跡預測方向,自動駕駛之心今天就為大家分享頂會NeurIPS上關於行人軌跡預測的演算法—SHENet,在受限場景中人類的移動模式通常在一定程度上符合有限的規律。基於這個假設,SHENet透過學習隱含的場景規律來預測一個人的未來軌跡。文章已經授權自動駕駛之心原創!
由於人類運動的隨機性和主觀性,當前預測一個人的未來軌跡仍然是一個具有挑戰性的問題。然而,由於場景限制(例如平面圖、道路和障礙物)以及人與人或人與物體的互動性,在受限場景中人類的移動模式通常在一定程度上符合有限的規律。因此,在這種情況下,個人的軌跡也應該遵循其中一個規律。換句話說,一個人後來的軌跡很可能已經被其他人走過了。基於這個假設,本文的演算法(SHENet)透過學習隱含的場景規律來預測一個人的未來軌跡。具體來說我們將場景中人和環境的過去動態所固有的規律性稱為場景史。進而將場景歷史資訊分為兩類:歷史群體軌跡與個體與環境的交互作用。為了利用這兩種類型的信息進行軌跡預測,本文提出了一種新穎的框架場景歷史挖掘網路(SHENet),其中以簡單而有效的方法利用場景歷史。特別是設計的兩個組件:群體軌跡庫模組,用於提取代表性群體軌跡作為未來路徑的候選者;交叉模態交互模組,用於對個體過去軌跡與其周圍環境之間的交互進行建模,以進行軌跡細化。另外為了減輕上述人體運動的隨機性和主觀性所引起的真值軌跡的不確定性,SHENet將平滑度納入訓練過程和評估指標中。最終我們在不同實驗數據集上進行了驗證,與SOTA方法相比,展示了卓越的性能。
人類軌跡預測(HTP)旨在從影片片段中預測目標人的未來路徑。這對於智慧交通至關重要,因為它使車輛能夠提前感知行人的狀態,從而避免潛在的碰撞。具有HTP功能的監控系統可以協助安全人員預測嫌疑人可能的逃跑路徑。儘管近年來已經做了很多工作,但很少有足夠可靠和可推廣到現實世界場景中的應用,這主要是由於任務的兩個挑戰:隨機性和人體運動的主觀性。然而,在受限的現實世界場景中,挑戰並非絕對棘手。如圖1 所示,給定該場景中先前捕獲的視頻,目標人的未來軌跡(紅色框)變得更加可預測,因為人類的移動模式通常符合該場景中目標人將遵循的幾個基本規律。因此,要預測軌跡,我們首先需要了解這些規律。我們認為,這些規律性隱含地編碼在歷史人類軌跡(圖 1 左)、個體過去的軌跡、周圍環境以及它們之間的相互作用(圖 1 右)中,我們稱之為場景歷史。

圖 1:利用場景歷史的示意圖:歷史群體軌跡和個體環境交互,用於人類軌跡預測。
我們將歷史資訊分為兩類:歷史群體軌跡(HGT)和個體與環境互動(ISI)。 HGT是指一個場景中所有歷史軌跡的群體代表。使用HGT的原因是,鑑於場景中的新目標人,由於上述隨機性,他/她的路徑更有可能與其中一個群體軌跡比歷史軌蹟的任何單一實例具有更多相似性、主觀性、規律性。然而,群體軌跡與個體過去的狀態和對應環境的相關性較小,也會影響個體未來的軌跡。 ISI 需要透過提取上下文資訊來更全面地利用歷史資訊。現有的方法很少考慮個體過去軌跡和歷史軌跡之間的相似性。大多數嘗試僅探索個體與環境的交互,其中花費了大量精力對個體軌跡、環境的語義訊息以及它們之間的關係進行建模。儘管MANTRA使用以重構方式訓練的編碼器來對相似性進行建模,而MemoNet透過儲存歷史軌蹟的意圖來簡化相似性,但它們都在實例層級而不是群組層級上執行相似性計算,從而使其對受過訓練的編碼器的能力敏感。基於上述分析,我們提出了一個簡單而有效的框架,場景歷史挖掘網絡(SHENet),共同利用 HGT 和 ISI 進行 HTP。特別是,該框架由兩個主要組成部分組成:(i)群體軌跡庫(GTB)模組,以及(ii)跨模式互動(CMI)模組。 GTB從所有歷史個體軌跡中建立代表性群體軌跡,並為未來軌跡預測提供候選路徑。 CMI 對觀察到的個體軌跡和周圍環境分別進行編碼,並使用跨模態轉換器對它們的交互作用進行建模,以細化搜尋到的候選軌跡。
此外,為了減輕上述兩個特徵(即隨機性和主觀性)的不確定性,我們在訓練過程和當前評估指標,平均和最終位移誤差(即ADE 和FDE)中引入曲線平滑(CS),從而得到兩個新指標CS-ADE 和CS-FDE。此外,為了促進 HTP 研究的發展,我們收集了一個具有不同運動模式的新的具有挑戰性的資料集,名為 PAV。該資料集是透過從 MOT15 資料集中選擇具有固定攝影機視圖和複雜人體運動的影片來獲得的。
這項工作的貢獻可以總結如下:1)我們引入群體歷史來搜尋 HTP 的個體軌跡。 2)我們提出了一個簡單而有效的框架,SHENet,共同利用兩種類型的場景歷史(即歷史群體軌跡和個體與環境的互動)進行HTP。 3)我們建構了一個新的具有挑戰性的資料集PAV; 此外,考慮到人類移動模式的隨機性和主觀性,提出了一種新穎的損失函數和兩種新的指標,以實現更好的基準HTP 性能。 4)我們對ETH、UCY和PAV進行了全面的實驗,以證明SHENet的優越性能以及每個組件的功效。
單一模態方法 單一模態方法依賴於從過去的軌跡中學習個體運動的規律性來預測未來的軌跡。例如,Social LSTM透過social pooling模組對個體軌跡之間的交互作用進行建模。 STGAT使用注意力模組來學習空間互動並為鄰居分配合理的重要性。 PIE 使用時間注意力模組來計算每個時間步觀察到的軌蹟的重要性。
多模態方法 此外,多模態方法也檢視了環境資訊對 HTP 的影響。 SS-LSTM提出了一個場景互動模組來捕捉場景的全局資訊。 Trajectron 使用圖結構對軌跡進行建模,並與環境資訊和其他個體互動。 MANTRA利用外部記憶體來建模長期依賴關係。它將歷史單智能體軌跡儲存在記憶體中,並對環境資訊進行編碼,以從該記憶體中細化搜尋到的軌跡。
與先前工作的差異 單一模態和多模態方法都使用場景歷史的單一或部分方面,而忽略歷史組軌跡。在我們的工作中,我們以更全面的方式整合場景歷史信息,並提出專用模組來分別處理不同類型的信息。我們的方法與先前的工作,特別是基於記憶體的方法和基於聚類的方法之間的主要區別如下:i)MANTRA 和MemoNet 考慮歷史個體軌跡,而我們提出的SHENet關注歷史群體軌跡,這在不同場景下更具有普遍性。 ii) 還有一部分工作將人-鄰居分組以進行軌跡預測;將軌跡聚類為固定數量的類別以進行軌跡分類; 我們的 SHENet 產生代表性軌跡作為個人軌跡預測的參考。
所提出的場景歷史挖掘網路(SHENet)的架構如圖2 所示,它由兩個主要元件組成:群組軌跡庫模組(GTB)和交叉模態交互模組(CMI)。形式上,給定該場景的觀察影片中的所有軌跡 、 場景影像以及目標人 在最後時間步中的過去軌跡,其中表示第p 個人在時間步t 的位置, SHENet 要求預測行人在接下來的幀中的未來位置,使得盡可能接近真值軌跡。提出的 GTB 首先將 壓縮為代表群體軌跡。然後,將觀測到的軌跡作為key,在中搜尋最接近的代表群體軌跡,作為候選未來軌跡 。同時,將過去的軌跡和場景影像分別傳到軌跡編碼器和場景編碼器,以分別產生軌跡特徵和場景特徵。編碼後的特徵被輸入到交叉模態transformer中,以學習和真值軌跡之間的偏移 。透過將 加入 #,我們得到最終的預測 。在訓練階段,如果到的距離高於閾值,則人的軌跡(即和)將被添加到軌跡庫中。訓練完成後,bank被固定用於推理。
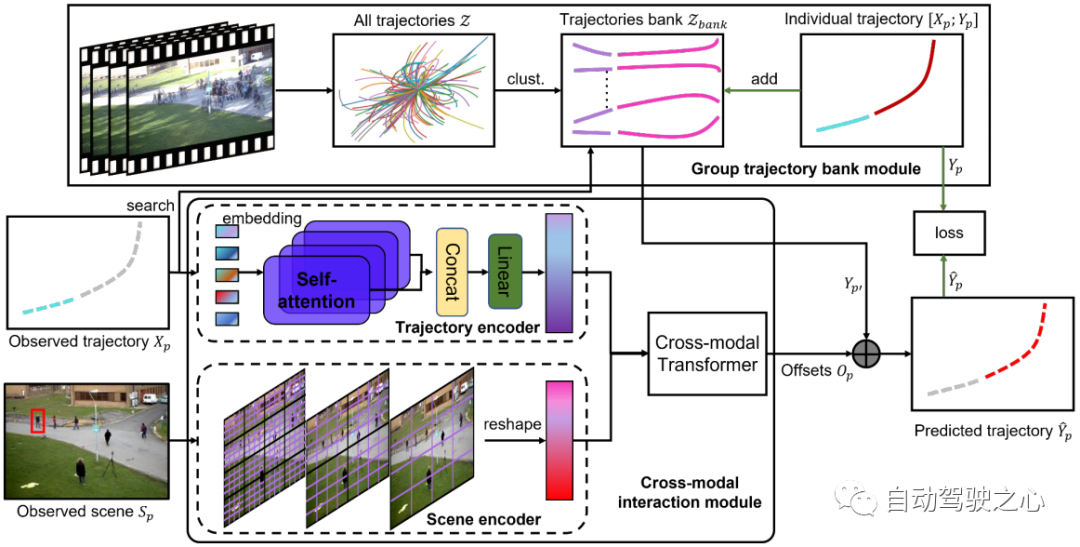
圖 2:SHENet 的架構由兩個元件組成:群組軌跡庫模組 (GTB) 和跨模態互動模組 (CMI)。 GTB將所有歷史軌跡聚類成一組代表性組軌跡,並為最終軌跡預測提供候選。在訓練階段,GTB可以根據預測軌跡的誤差,將目標人的軌跡納入群體軌跡庫中,以擴展表達能力。 CMI將目標人的過去軌跡和觀察到的場景分別作為軌跡編碼器和場景編碼器的輸入進行特徵提取,然後透過跨模態轉換器有效地對過去軌跡與其周圍環境之間的交互進行建模並進行細化提供候選軌跡。
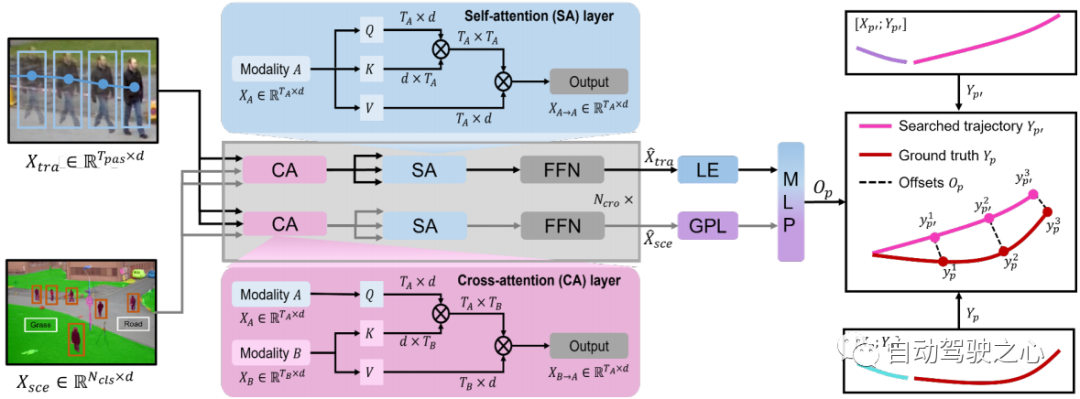
圖 3:交叉模數transformer圖示。軌跡特徵和場景特徵被輸入到交叉模態transformer中,以學習搜尋軌跡和真值軌跡之間的偏移。
群體軌跡庫模組(GTB)用於建構場景中具有代表性的群體軌跡。 GTB的核心功能是bank初始化、軌跡搜尋和軌跡更新。
軌跡庫初始化 由於大量記錄的軌跡存在冗餘,我們不是簡單地使用它們,而是產生一組稀疏且有代表性的軌跡作為軌跡庫的初始值。具體來說,我們將訓練資料中的軌跡表示為 並將每個 分成一對觀測軌跡 與未來軌跡 ,從而將 分成觀測集 以及對應的未來集合 。然後,我們計算,中每對軌跡之間的歐氏距離,並透過K-medoids聚類演算法獲得軌跡簇。 的初始成員是屬於同一群集的軌跡的平均值(參見演算法 1,步驟 1)。中的每條軌跡都代表了一群人的移動模式。
軌跡搜尋和更新 在群組軌跡庫中,每個軌跡都可以被視為過去-未來對。在數值上, ,其中 代表過去軌跡和未來軌跡的組合, 是 中過去未來對的數量。給定軌跡 ,我們使用觀察到的 作為關鍵來計算其與 中過去軌跡 的相似度得分,並找到代表性軌跡 根據最大相似度得分(參見演算法1,步驟2)。相似度函數可以表示為:
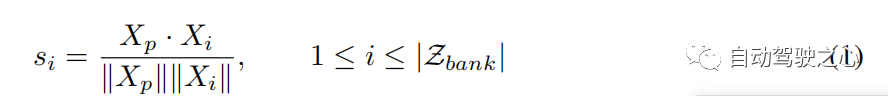
透過將偏移量 (參見公式2)加入代表性軌跡 中,我們獲得了被觀察者的預測軌跡 (參見圖2)。雖然初始軌跡庫在大多數情況下效果很好,但為了提高庫 的泛化性(參見演算法1,步驟3),我們根據距離閾值θ 決定是否更新 。
此模組重點在於個體過去軌跡與環境訊息之間的交互作用。它由兩個單模態編碼器組成,分別用於學習人體運動和場景訊息,以及一個跨模態轉換器來建模它們的交互作用。
軌跡編碼器 軌跡編碼器採用來自 Transformer 網路 的多頭注意力結構,其具有 自註意力(SA)層。 SA 層以 的大小捕捉不同時間步長的人體運動,並將運動特徵從維度 投影到 ,其中 是軌跡編碼器的嵌入維度。因此,我們使用軌跡編碼器來獲得人體運動表示:。
場景編碼器 由於預先訓練的 Swin Transformer在特徵表示方面具有引人注目的性能,我們採用它作為場景編碼器。它提取大小為 的場景語義特徵,其中 (預訓練場景編碼器中的 )是語義類別的數量,例如人和道路, 和 是空間解析度。為了使後續模組能夠方便地融合運動表示和環境訊息,我們將語義特徵從大小()重改為(),並透過多層感知層將它們從維度()投影到() 。結果,我們使用場景編碼器 來獲得場景表示 。
交叉模態Transformer 單模態編碼器從其自身模態中提取特徵,忽略人體運動和環境訊息之間的相互作用。具有 層的交叉模態transformer旨在透過學習這種交互作用來細化候選軌跡 (請參閱第 3.2 節)。我們採用雙流結構:一個用於捕捉受環境資訊約束的重要人體運動,另一個用於挑選與人體運動相關的環境資訊。交叉注意 (CA) 層和自註意 (SA) 層是跨模態轉換器的主要組成部分(見圖 3)。為了捕捉受環境影響的重要人體運動並獲取與運動相關的環境訊息,CA層將一種模態視為query,將另一種模態視為與兩種模態交互作用的key和value。 SA 層用於促進更好的內部連接,計算場景約束運動或運動相關環境資訊中元素(query)與其他元素(key)之間的相似性。因此,我們透過交叉模態transformer 來獲得多式聯運表示()。為了預測搜尋軌跡 與真實軌跡 之間的偏移量 ,我們採用 的最後一個元素(LE) 和全域池化層(GPL) 之後的輸出 的 。偏移量 可以表述如下:
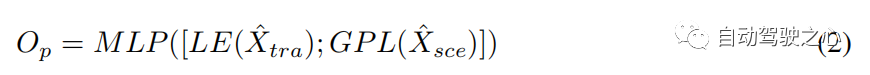
#其中 [; ] 表示向量串聯,MLP 為多層感知層。
我們端到端地訓練 SHENet 的整體框架,以最小化目標函數。在訓練過程中,由於場景編碼器已經在ADE20K 上進行了預訓練,因此我們凍結其分割部分並更新MLP頭的參數(請參閱第3.3節)。遵循現有的工作,我們計算了 ETH/UCY 資料集上的預測軌跡與真值軌跡之間的均方誤差(MSE): 。
在更具挑戰性的 PAV 資料集中,我們使用曲線平滑(CS)回歸損失,這有助於減少個體偏差的影響。它計算軌跡平滑後的 MSE。 CS損失可以表述如下:
其中CS代表曲線平滑的函數[2]。

資料集 我們在ETH、UCY 、PAV 和史丹佛無人機資料集(SDD)資料集上評估我們的方法。單模態方法僅關注軌跡數據,然而,多模態方法需要考慮場景資訊。
與ETH/UCY 資料集相比,PAV 更具挑戰性,具有多種運動模式,包括PETS09-S2L1 (PETS) 、ADL-Rundle-6 (ADL) 和Venice-2 (VENICE) ,這些資料被捕獲來自靜態攝影機並為HTP 任務提供足夠的軌跡。我們將影片分為訓練集(80%)和測試集(20%),PETS/ADL/VENICE 分別包含 2,370/2,935/4,200 個訓練序列和 664/306/650 個測試序列。我們使用 個觀察幀來預測未來 幀,這樣我們就可以比較不同方法的長時預測結果。
與 ETH/UCY 和 PAV 資料集不同,SDD 是在大學校園中鳥瞰捕獲的大規模資料集。它由多個互動主體(例如行人、騎自行車的人和汽車)和不同的場景(例如人行道和十字路口)組成。按照先前的工作,我們使用過去的 8 幀來預測未來的 12 幀。
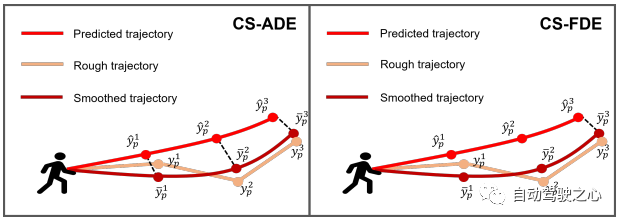
圖 4:我們提出的指標 CS-ADE 和 CS-FDE 的圖示。

圖 5:曲線平滑後一些樣本的視覺化。
評估指標 對於ETH和UCY資料集,我們採用HTP的標準指標:平均位移誤差(ADE)和最終位移誤差(FDE)。 ADE 是所有時間步上預測軌跡與真值軌跡之間的平均 誤差,FDE 是最終時間步預測軌跡與真值軌跡之間的 誤差。 PAV 中的軌跡存在一些抖動現象(例如急轉彎)。因此,合理的預測可能會產生與使用傳統指標 ADE 和 FDE 進行不切實際的預測大致相同的誤差(見圖 7(a))。為了關注軌跡本身的模式和形狀,並減少隨機性和主觀性的影響,我們提出了CS-Metric:CS-ADE和CS-FDE(如圖4)。 CS-ADE 計算如下:
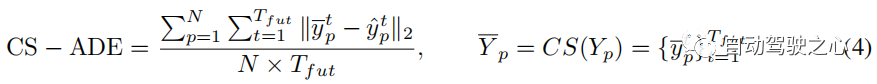
其中CS是曲線平滑函數,定義與3.4節的Lcs相同。與CS-ADE類似,CS-FDE計算軌跡平滑後的最終位移誤差:
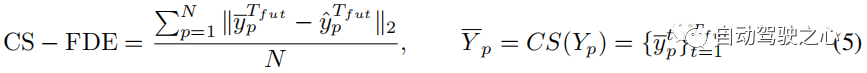
圖5 顯示了訓練資料中的一些樣本,將粗糙的真值軌跡轉換為平滑的軌跡。
實作細部 在SHENet中,群組軌跡庫的初始大小設定為。軌跡編碼器和場景編碼器都有 4 個自註意力(SA)層。跨模態 Transformer 有 6 個 SA 層和交叉注意(CA)層。我們將所有嵌入維度設定為 512。對於軌跡編碼器,它學習大小為 的人體運動資訊(ETH/UCY 中 ,PAV 中 )。對於場景編碼器,它輸出大小為 150 × 56 × 56 的語意特徵。我們將大小從 150 × 56 × 56 改為 150 × 3136,並將它們從維度 150 × 3136 投影到 150 × 512。我們訓練 在 4 個 NVIDIA Quadro RTX 6000 GPU 上建立 100 個週期的模型,並使用固定學習率 1e − 5 的 Adam 優化器。
在表1 中,我們評估了SHENet 的每個組件,包括群組軌跡庫(GTB)模組和跨模態交互作用(CMI)模組,該模組包含軌跡編碼器(TE)、場景編碼器(SE)和跨模態交互作用(CMI)模組。
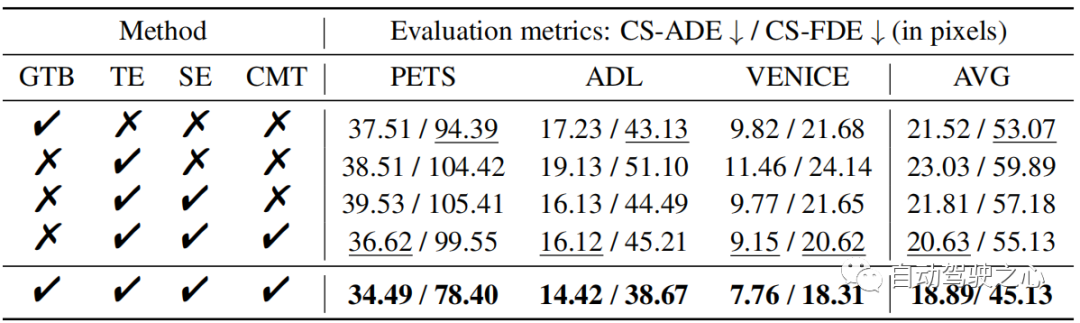
GTB 的影響 我們先研究 GTB 的表現。與 CMI(即 TE、SE 和 CMT)相比,GTB 在 PETS 上的 FDE 提高了 21.2%,這是一個顯著的改進,說明了 GTB 的重要性。然而,僅靠 GTB(表 1 第 1 行)是不夠的,甚至比 CMI 的表現還要差一些。因此,我們探討了CMI模組中各個部分的作用。 TE 和SE 的影響 為了評估TE 和SE 的效能,我們將從TE 中提取的軌跡特徵和從SE 中提取的場景特徵連接在一起(表1 中的第3 行),並以較小的運動提高ADL 和VENICE 的性能(與單獨使用TE。這表明將環境資訊納入軌跡預測可以提高結果的準確性。CMT 的效果 與表1 的第三行相比,CMT(表1 的第4 行)可以顯著提高模型性能。值得注意的是,它的性能優於PETS 上串聯的TE 和SE,ADE 提高了7.4%。與單獨的GTB 相比,完整的CMI 比ADE 平均提高了12.2%。
在 ETH/UCY 資料集上,將我們的模型與最先進的方法進行比較:SS-LSTM、Social-STGCN、MANTRA、AgentFormer、YNet。結果總結在表 2 中。我們的模型將平均 FDE 從 0.39 降低到 0.36,與最先進的方法 YNet 相比,提高了 7.7%。特別是,當軌跡發生較大移動時,我們的模型在 ETH 上顯著優於先前的方法,其 ADE 和 FDE 分別提高了 12.8% 和 15.3%。
表 2:ETH/UCY 資料集上最先進 (SOTA) 方法的比較。 * 表示我們使用比單模態方法更小的集合。採用前20最好的方式進行評估。
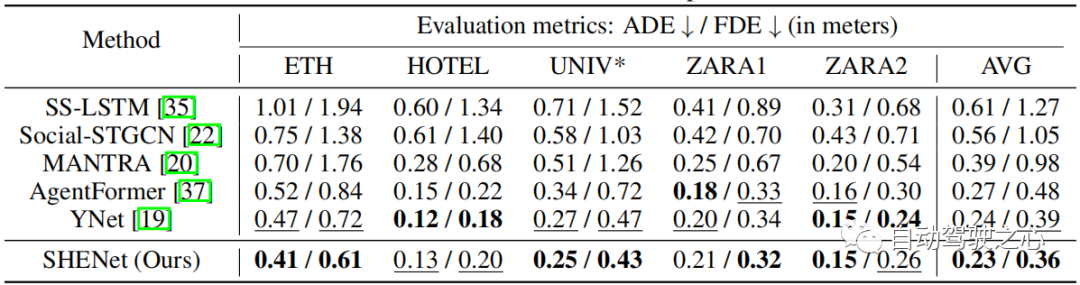
表 3:在 PAV 資料集上與 SOTA 方法的比較。
為了評估我們的模型在長期預測中的表現,我們在PAV 上進行了實驗,其中每個軌跡 個觀察幀, 個未來影格。表 3 顯示了與先前的 HTP 方法的效能比較:SS-LSTM、Social-STGCN、Next、MANTRA、YNet。與 YNet 的最新結果相比,所提出的 SHENet CS-ADE 和 CS-FDE 平均分別提高了 3.3% 和 10.5%。由於 YNet 預測軌蹟的熱圖,因此當軌跡有小幅運動時(例如 VENICE),它的表現會更好一些。儘管如此,我們的方法在 VENICE 中仍然具有競爭力,並且在具有較大運動和交叉點的 PETS 上比其他方法要好得多。特別是,與 YNet 相比,我們的方法在 PETS 上將 CS-FDE 提高了 16.2%。我們也在傳統的 ADE/FDE 指標取得了巨大的進步。
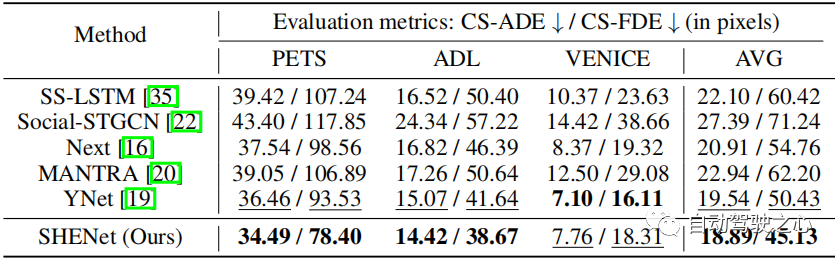
距離閾值 θ θ用於決定軌跡庫的更新。 θ的典型值是根據軌跡長度設定。當真值軌跡以像素計越長時,預測誤差的絕對值通常越大。然而,它們的相對誤差是可比的。因此,當誤差收斂時,θ被設定為訓練誤差的75%。實驗中,我們在 PETS 中設定 θ = 25,在 ADL 中設定 θ = 6。由實驗結果得到“75%的訓練誤差”,如表4所示。
表 4:PAV 資料集上不同參數 θ 的比較。結果是三種情況的平均值。
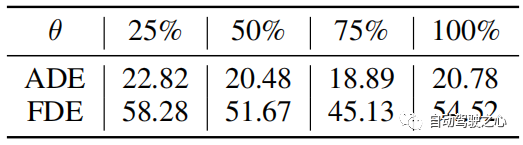
表 5:PAV 資料集上初始簇數 K 的比較。

K 中心點中的簇數 我們研究了設定不同數量的初始簇K的效果,如表5所示。我們可以注意到,初始簇數對預測結果並不敏感,尤其是初始簇數為 24-36 時。因此,我們在實驗中可以將K設定為32。
Bank複雜度分析 搜尋和更新的時間複雜度分別為O(N)和O(1)。它們的空間複雜度是O(N)。群體軌跡數N≤1000。聚類過程的時間複雜度為ββ,空間複雜度為ββ。 β 是聚類軌蹟的數量。 是聚類的數量, 是聚類方法的迭代次數。

圖 6:我們的方法和最先進方法的定性視覺化。藍線是觀察到的軌跡。紅線和綠線顯示預測軌跡和真實軌跡。

圖 7:不使用/使用 CS 的定性視覺化。
圖 6 展示了 SHENet 和其他方法的定性結果。相較之下,我們驚訝地註意到,在一個人走到路邊然後折返(綠色曲線)的極具挑戰性的情況下,所有其他方法都不能很好地處理,而我們提出的SHENet 仍然可以處理它。這應該歸功於我們專門設計的歷史群體軌跡庫模組的作用。此外,與基於記憶的方法 MANTRA [20] 相比,我們搜尋群體的軌跡,而不僅僅是個體。這更加通用,可以應用於更具挑戰性的場景。圖 7 包括 YNet 和我們的 SHENet 的定性結果,不含/帶曲線平滑 (CS)。第一行顯示使用 MSE 損失 的結果。受過去帶有一些噪音的軌跡(例如突然和急轉彎)的影響,YNet的預測軌跡點聚集在一起,不能呈現明確的方向,而我們的方法可以根據歷史群體軌跡提供潛在的路徑。這兩個預測在視覺上是不同的,但數值誤差 (ADE/FDE) 大致相同。相較之下,我們提出的 CS 損失 的定性結果如圖 7 的第二行。可以看到,提出的 CS 顯著降低了隨機性和主觀性的影響,並透過YNet 和我們的方法產生了合理的預測。
本文提出了 SHENet,這是一種充分利用 HTP 場景歷史的新穎方法。 SHENet 包括一個GTB 模組,用於根據所有歷史軌跡建立一個群體軌跡庫,並從該庫中檢索被觀察者的代表性軌跡;還包括一個CMI 模組(在人體運動和環境資訊之間相互作用)來細化該代表性軌跡。我們在 HTP 基準上實現了 SOTA 效能,並且我們的方法在具有挑戰性的場景中展示了顯著的改進和通用性。然而,目前框架中仍存在一些尚未探索的方面,例如bank建造過程目前僅關注人體運動。未來的工作包括使用互動資訊(人體運動和場景資訊)進一步探索軌跡庫。

原文連結:https://mp.weixin.qq.com/s/GE-t4LarwXJu2MC9njBInQ
以上是行人軌跡預測有哪些有效的方法和普遍的Base方法?頂會論文分享!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















