

MiniGPT-4升級到MiniGPT-v2了,不用GPT-4照樣完成多模態任務

幾個月前,來自KAUST(沙烏地阿拉伯阿卜杜拉國王科技大學)的幾位研究者提出了一個名為 MiniGPT- 4 的項目,它能提供類似GPT-4 的圖像理解與對話能力。
例如MiniGPT-4 能夠回答下圖中出現的景象:「圖片描述的是生長在冰凍湖上的一株仙人掌。仙人掌周圍有巨大的冰晶,遠處還有白雪皚皚的山峰……」假如你接著詢問這種景象能夠發生在現實世界中嗎? MiniGPT-4 給出的答案是這張圖片在現實世界中並不常見,並給出了原因。

短短幾個月過去了,近日,KAUST 團隊以及來自Meta 的研究者宣布,他們將MiniGPT-4 重磅升級到了MiniGPT-v2 版本。

論文網址:https://arxiv.org/pdf/2310.09478.pdf
論文首頁:https://minigpt-v2.github.io/
#Demo: https://minigpt-v2.github.io/
#具體而言,MiniGPT-v2 可以作為一個統一的介面來更好地處理各種視覺- 語言任務。同時,本文建議在訓練模型時對不同的任務使用唯一的辨識符號,這些符號有利於模型輕鬆的區分每個任務指令,並提高每個任務模型的學習效率。
為了評估 MiniGPT-v2 模型的性能,研究者對不同的視覺 - 語言任務進行了廣泛的實驗。結果表明,與先前的視覺 - 語言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各種基準上實現了 SOTA 或相當的性能。例如 MiniGPT-v2 在 VSR 基準上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。
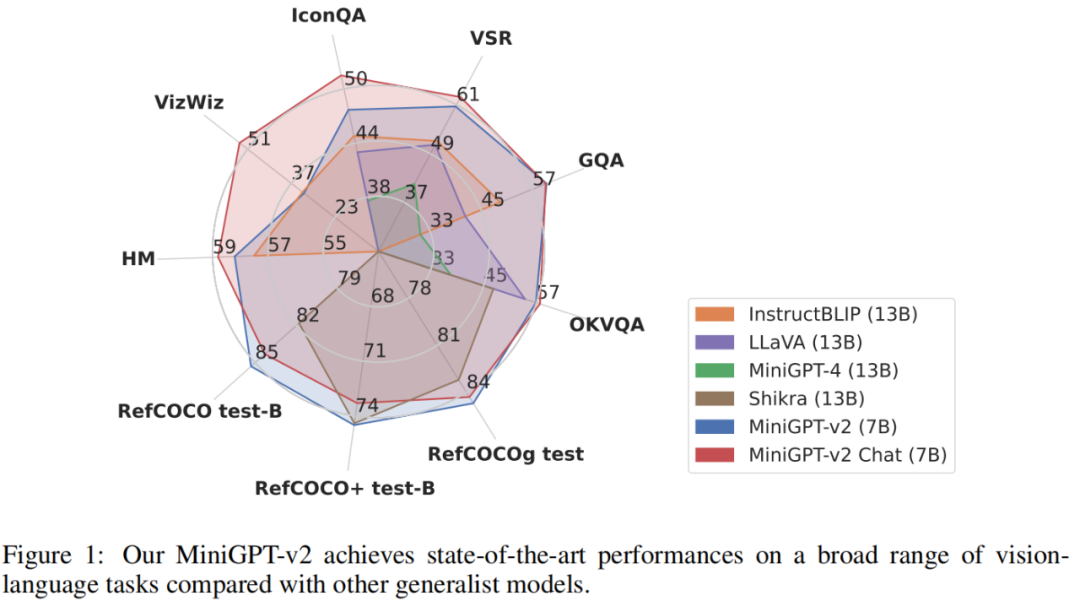
下面我們透過特定的範例來說明 MiniGPT-v2 辨識符號的作用。
例如,透過加上[grounding] 識別符號,模型可以很容易產生一個帶有空間位置感知的圖片描述:

透過新增[detection] 辨識符號,模型可以直接擷取輸入文字裡面的物件並且找到它們在圖片中的空間位置:

##框出圖中的一個物體,透過加上[identify] ,可以讓模型直接辨識出來物體的名字:
 透過加上[refer]和一個物體的描述,模型可以直接幫你找到物體對應的空間位置:
透過加上[refer]和一個物體的描述,模型可以直接幫你找到物體對應的空間位置:

#你也可以不加任何任務辨識符合,和圖片進行對話:

模型的空間感知也變得更強,可以直接問模型誰出現在圖片的左面,中間和右面:

方法介紹
#MiniGPT-v2 模型架構如下圖所示,它由三個部分組成:視覺主幹、線性投影層和大型語言模型。

視覺主幹:MiniGPT-v2 採用 EVA 作為主幹模型,並且在訓練期間會凍結視覺主幹。訓練模型的影像解析度為 448x448 ,並插入位置編碼以擴展更高的影像解析度。
線性投影層:本文旨在將所有的視覺 token 從凍結的視覺主幹投影到語言模型空間。然而,對於更高解析度的圖像(例如 448x448),投影所有的圖像 token 會導致非常長的序列輸入(例如 1024 個 token),顯著降低了訓練和推理效率。因此,本文簡單地將嵌入空間中相鄰的 4 個視覺 token 連接起來,並將它們一起投影到大型語言模型的同一特徵空間中的單一嵌入中,從而將視覺輸入 token 的數量減少了 4 倍。
大型語言模型:MiniGPT-v2 採用開源的 LLaMA2-chat (7B) 作為語言模型主幹。在該研究中,語言模型被視為各種視覺語言輸入的統一介面。本文直接借助 LLaMA-2 語言 token 來執行各種視覺語言任務。對於需要產生空間位置的視覺基礎任務,本文直接要求語言模型產生邊界框的文字表示以表示其空間位置。
多任務指令訓練
#本文使用任務辨識符號指令來訓練模型,分為三個階段。各階段訓練所使用的資料集如表 2 所示。

階段 1:預訓練。本文對弱標記資料集給出了高取樣率,以獲得更多樣化的知識。
階段 2:多任務訓練。為了提高 MiniGPT-v2 在每個任務上的效能,現階段只專注於使用細粒度資料集來訓練模型。研究者從 stage-1 中排除 GRIT-20M 和 LAION 等弱監督資料集,並根據每個任務的頻率更新資料採樣比。該策略使本文模型能夠優先考慮高品質對齊的圖像文字數據,從而在各種任務中獲得卓越的性能。
階段 3:多模態指令調優。隨後,本文專注於使用更多多模態指令資料集來微調模型,並增強其作為聊天機器人的對話能力。
最後,官方也提供了Demo 供讀者測試,例如,下圖中左邊我們上傳一張照片,然後選擇[Detection] ,接著輸入“red balloon”,模型就能辨識出圖中紅色的氣球:

#有興趣的讀者,可以查看論文首頁以了解更多內容。
以上是MiniGPT-4升級到MiniGPT-v2了,不用GPT-4照樣完成多模態任務的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何設置、獲取和刪除 WordPress Cookie(像專業人士一樣)
May 12, 2025 pm 08:57 PM
如何設置、獲取和刪除 WordPress Cookie(像專業人士一樣)
May 12, 2025 pm 08:57 PM
您想了解如何在WordPress網站上使用cookie嗎? Cookie是在用戶瀏覽器中存儲臨時信息的有用工具。您可以使用此信息通過個性化和行為定位來增強用戶體驗。在本終極指南中,我們將向您展示如何像專業人士一樣設置、獲取和刪除WordPresscookie。注意:這是一個高級教程。它要求您精通HTML、CSS、WordPress網站和PHP。什麼是Cookie? Cookie是用戶訪問網站時創建並存儲在用戶瀏覽
 2025年火幣APKV10.50.0下載指南 怎麼下載
May 12, 2025 pm 08:48 PM
2025年火幣APKV10.50.0下載指南 怎麼下載
May 12, 2025 pm 08:48 PM
火幣APKV10.50.0下載指南:1、點擊文中直達鏈接;2、選擇正確的下載包;3、填寫註冊信息;4、開始火幣交易流程。
 2025年火幣APKV10.50.0下載地址
May 12, 2025 pm 08:42 PM
2025年火幣APKV10.50.0下載地址
May 12, 2025 pm 08:42 PM
火幣APKV10.50.0下載指南:1、點擊文中直達鏈接;2、選擇正確的下載包;3、填寫註冊信息;4、開始火幣交易流程。
 2025年火幣APKV10.50.0安裝方法 APK指南
May 12, 2025 pm 08:27 PM
2025年火幣APKV10.50.0安裝方法 APK指南
May 12, 2025 pm 08:27 PM
火幣APKV10.50.0下載指南:1、點擊文中直達鏈接;2、選擇正確的下載包;3、填寫註冊信息;4、開始火幣交易流程。
 2025年火幣APKV10.50.0下載網址
May 12, 2025 pm 08:39 PM
2025年火幣APKV10.50.0下載網址
May 12, 2025 pm 08:39 PM
火幣APKV10.50.0下載指南:1、點擊文中直達鏈接;2、選擇正確的下載包;3、填寫註冊信息;4、開始火幣交易流程。
 十大數字幣交易所app最新排名 數字貨幣十大交易所app推薦
May 12, 2025 pm 08:15 PM
十大數字幣交易所app最新排名 數字貨幣十大交易所app推薦
May 12, 2025 pm 08:15 PM
十大數字幣交易所app最新排名依次為:1. OKX,2. Binance,3. Huobi,4. Coinbase,5. Kraken,6. KuCoin,7. Bitfinex,8. Gemini,9. Bitstamp,10. Poloniex。使用這些app的步驟包括:下載並安裝app,註冊賬戶,完成KYC認證,充值並開始交易。
 2025十大虛擬幣交易所app排名 數字貨幣交易APP最新排行榜前十名
May 12, 2025 pm 08:18 PM
2025十大虛擬幣交易所app排名 數字貨幣交易APP最新排行榜前十名
May 12, 2025 pm 08:18 PM
2025年十大虛擬幣交易所APP排名如下:1. OKX,2. Binance,3. Huobi,4. Coinbase,5. Kraken,6. KuCoin,7. Bybit,8. FTX,9. Bitfinex,10. Gate.io。這些交易所根據用戶體驗、安全性和交易量等維度進行評選,每個平台都提供了獨特的功能和服務,以滿足不同用戶的需求。
 火幣APKV10.50.0版本安裝教程
May 12, 2025 pm 08:33 PM
火幣APKV10.50.0版本安裝教程
May 12, 2025 pm 08:33 PM
火幣APKV10.50.0下載指南:1、點擊文中直達鏈接;2、選擇正確的下載包;3、填寫註冊信息;4、開始火幣交易流程。
