

1個token終結LLM數位程式設計難題!九大機構聯合發布xVal:訓練集沒有的數字也能預測!

雖然大型語言模型(LLM)在文字分析和生成任務上的表現非常強大,但在面對包含數字的問題時,例如多位數乘法,由於模型內部缺乏統一且完善的數字分詞機制,會導致LLM無法理解數字的語意,進而胡編亂造答案。
目前LLM還沒有廣泛應用於科學領域資料分析的一大阻礙就是數位編碼問題。
最近,熨斗研究所(Flatiron Institute)、勞倫斯伯克利國家實驗室、劍橋大學、紐約大學、普林斯頓大學等九個研究機構聯合發布了一個全新的數位編碼方案xVal,只需一個token即可對所有數字進行編碼。

論文連結:https://arxiv.org/pdf/2310.02989.pdf
xVal透過將專用token([NUM])的嵌入向量按數值縮放來表示目標真實值,再結合修改後的數字推理方法,xVal策略成功使模型在輸入字串數字到輸出數字之間映射時端到端連續,更適合科學領域的應用。
在合成和真實世界資料集上的評估結果顯示,xVal比現有的數位編碼方案不僅表現更好,而且更節省token,還表現出更好的插值泛化特性。
數位編碼新突破
標準的LLM分詞方案並沒有對數字和文字進行區分,也就無法對數值進行量化。
之前有工作依照科學計數法的形式,以10為基底,將所有數字映射到有限的原型數字(prototype numerals)集合中,或是計算數字embedding之間的餘弦距離來反映數字本身的數值差異,已成功用於解決線性代數問題,諸如矩陣乘法等。
不過對於科學領域中的連續或平滑問題,語言模型仍然無法很好地處理插值和分佈外泛化問題,因為將數字編碼為文本後,LLM在編碼和解碼階段本質上仍然是離散的,很難學習近似連續函數。
xVal的思路是對數值大小進行乘法(multiplicatively)編碼,並在嵌入空間中將其定向到可學習的方向,極大地改變了Transformer架構中處理和解釋數字的方式。
xVal使用單一token進行數位編碼,具有token效率的優勢以及最小的字典足跡(vocabulary footprint)。
結合修改後的數字推理範式,Transformer模型值在輸入數字和輸出字串的數字之間的映射時是連續的(平滑),當近似的函數是連續或平滑時,可以帶來更好的歸納偏差(inductive bias)。
xVal: 連續數字編碼
xVal並沒有對不同的數字使用不同的token,而是直接沿著嵌入空間中特定可學習方向嵌入數值。
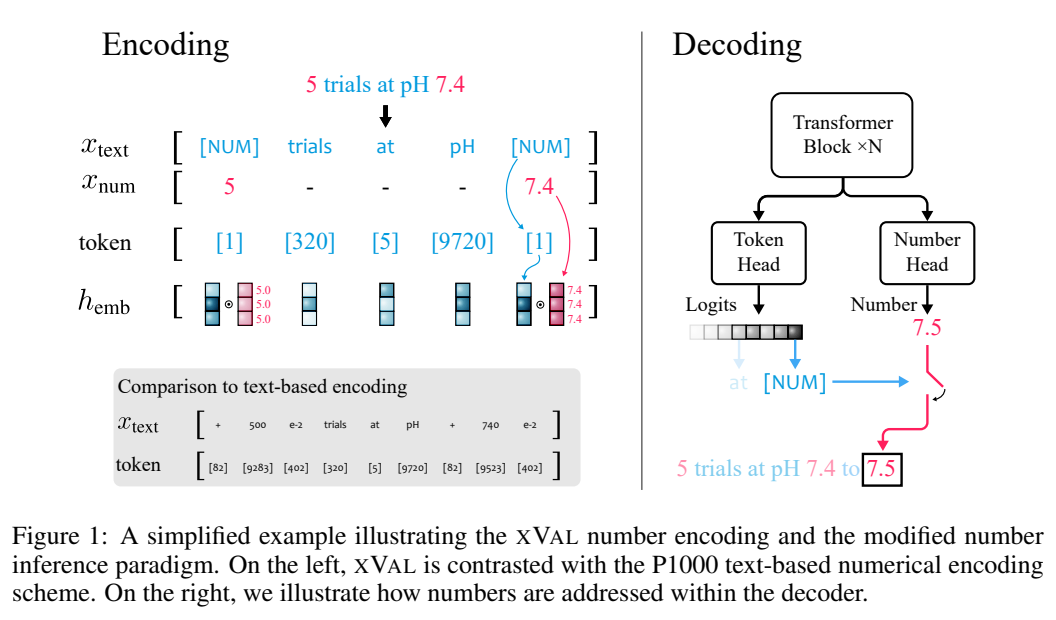
假設輸入字串中同時包含數字和文本,系統首先會對輸入進行解析,提取所有的數值,然後建構出一個新的字串,其中數字被替換為[NUM]佔位符,再將[NUM]的嵌入向量與其對應的數值相乘。
整個編碼過程可以用於遮罩語言建模(MLM)和自回歸(AR)產生。
基於層歸一化的隱式歸一化(Implicit normalization via layer-norm)
在具體實現中,第一個Transformer區塊中的xVal的乘法嵌入(multiplicative embedding)之後需要加上位置編碼向量,以及層歸一化(layer-norm),基於輸入樣本對每個token的嵌入進行歸一化。
當位置嵌入與[NUM]標記的嵌入不共線(collinear)時,標量值可以透過非線性重縮放函數(non-linear rescaling)進行傳遞。
假設u為[NUM]的嵌入,p為位置嵌入,x是被編碼的標量值,為了簡化計算可以假定u · p=0,其中∥u∥ =∥p∥ = 1,可以得到
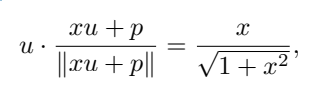
即x的值被編碼為與u同方向,並且該屬性在訓練後仍然可以保持。
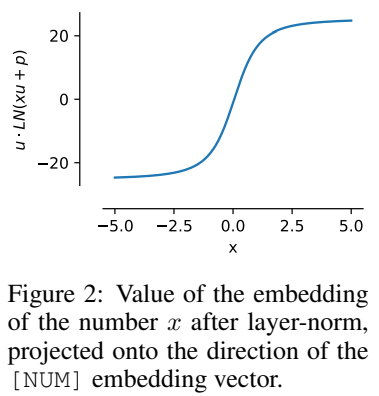
這種歸一化特性意味著xVal的動態範圍比其他基於文本的編碼方案的動態範圍更小,在實驗中設定為[-5, 5]作為訓練前的預處理步驟。
數值推理
xVal定義了在輸入數值中連續的嵌入,但如果使用多分類任務作為輸出和訓練演算法時,考慮到從輸入數值到輸出數值之間的映射,則模型作為一個整體不是端到端連續的,需要在輸出層單獨對數字進行處理。
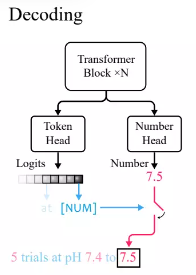
根據Transformer語言模型中的標準實踐,研究人員定義了一個token head,輸出詞彙表token的機率分佈。
因為xVal使用[NUM]對數字進行替換,所以head不攜帶任何關於數值的信息,所以需要引入了一個具有標量輸出的新number head,通過均方誤差(MSE)損失進行訓練,以恢復與[NUM]相關聯的具體數值。
給定輸入後,首先觀察token head的輸出,如果產生的token為[NUM],則查看number head來填入該token的值。
在實驗中,由於Transformer模型在推斷數值時是端對端連續的,所以當插值到未見過的數值時表現得更好。
實驗部分
比較其他數字編碼方法
研究人員將XVAL的效能與其他四種數字編碼進行了比較,這些方法都需要先將數字處理為±ddd E±d的形式,然後再根據格式調用單個或多個token來確定編碼。

不同方法對於編碼每個數字所需的token數量、詞彙表數量有很大不同,但總體來看,xVal的編碼效率是最高的,詞彙表尺寸也最小。
研究人員也在三個資料集上對xVal進行評估,包括合成的算術運算資料、全球溫度資料和行星軌道模擬資料。
學習算術
#即使對於最大的LLM來說,「多位數乘法」仍然是一個極具挑戰的任務,例如GPT-4在三位數乘法問題上僅能達到59%的zero-shot準確率,在四位數和五位數乘法問題上的準確率甚至只有4%和0%
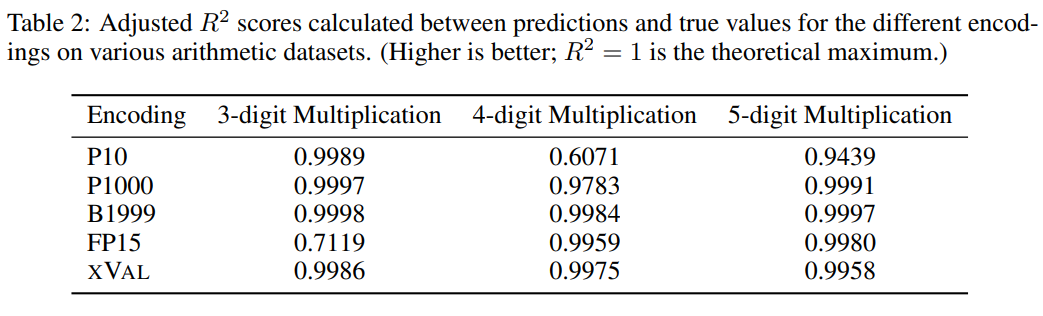
從對比實驗來看,其他數字編碼通常也能很好地解決多位數乘法問題,不過xVal的預測結果相比P10和FP15來說較穩定,不會產生異常預測值。
為了提升任務難度,研究人員使用隨機二元樹,使用加法、減法和乘法的二元運算子組合固定數量的運算元(2、3或4)建構出了一個資料集,其中每個樣本都是一個算術表達式,例如((1.32 * 32.1) (1.42-8.20)) = 35.592
#然後根據每個數字編碼方案的處理要求對樣本進行處理,任務目標是計算等式左側的表達式,即等式右側為掩碼。
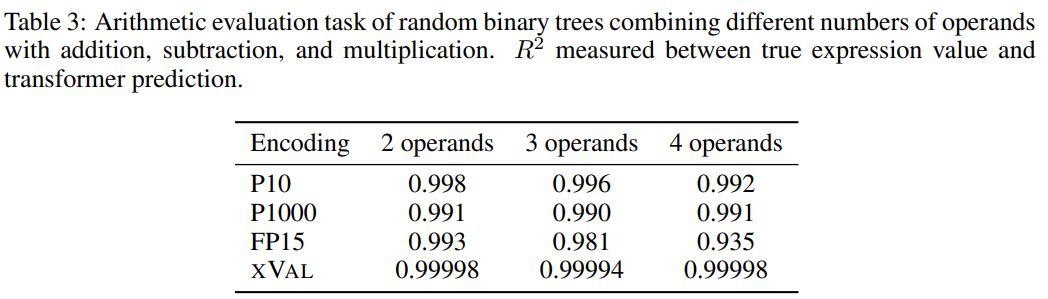
從結果來看,xVal在這個任務上表現得非常好,不過單靠算術實驗不足以完全評估語言模型的數學能力,因為算術運算中的樣本通常是短序列,底層資料流形是低維的,這些問題並沒有突破LLMs在計算上的瓶頸,而現實世界的應用更複雜。
溫度預測
#研究人員使用ERA5全球氣候資料集的子集用作評估,簡單起見,實驗中只關注地表溫度資料(ERA5中的T2m),然後對樣本進行劃分,其中每個樣本包括2-4天的地表溫度資料(一化後具有單位變異數)以及來自60 -90個隨機選擇的報告站的緯度和經度。
對座標的緯度的正弦和經度的正弦和餘弦編碼,從而保持資料的周期性,然後使用相同的操作對24小時和365天週期中位置進行編碼。

座標(coords)、起點(start)和資料(data)對應於報告站座標、第一個樣本的時間和標準化溫度數據,然後使用MLM方法來訓練語言模型。
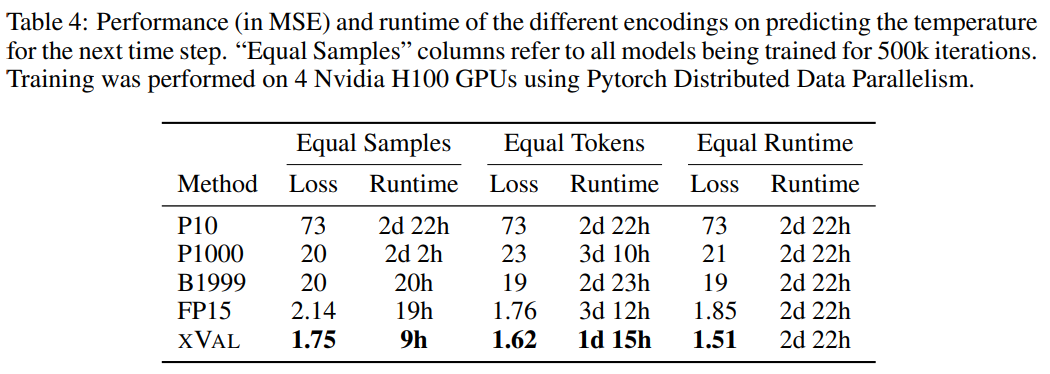
從結果來看,xVal的效能最好,同時計算所需時間也顯著降低。
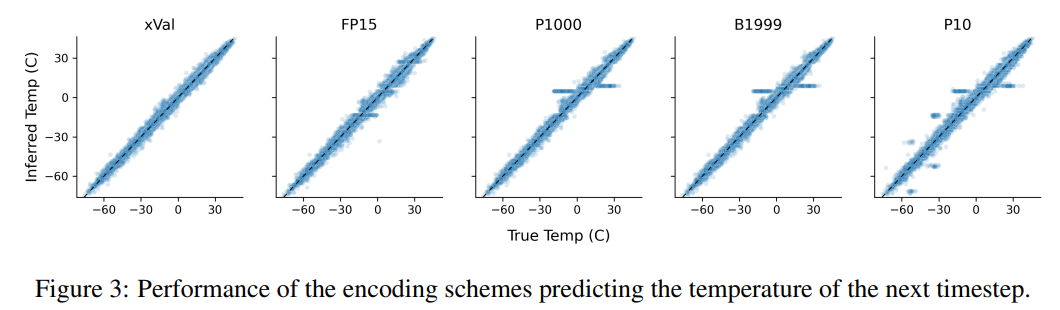
這項任務也說明了基於文字編碼方案的缺點,模型可以利用資料中的虛假相關性,即P10、P1000和B1999具有預測歸一化溫度±0.1的趨勢,主要原因是該數字在資料集中出現的頻率最高。
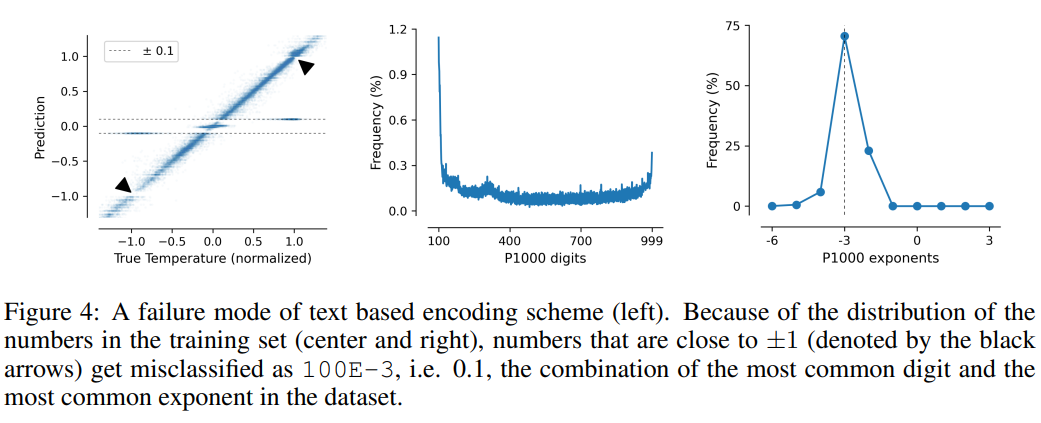
對於P1000和P10方案來說,二者的編碼輸出平均分別約為8000和5000個token(相較之下,FP15和xVal平均約1800個token),模型的不良表現可能是由於長距離建模的問題。
以上是1個token終結LLM數位程式設計難題!九大機構聯合發布xVal:訓練集沒有的數字也能預測!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通過使用 ALTER TABLE 語句為現有表添加新列。具體步驟包括:確定表名稱和列信息、編寫 ALTER TABLE 語句、執行語句。例如,為 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的語法為 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是數據類型,NOT NULL 指定是否允許空值,DEFAULT default_value 指定默認值。
 SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,釋放空間並重置標識列。禁用外鍵約束,防止級聯刪除。使用事務封裝操作,保證數據一致性。批量刪除大數據,通過 LIMIT 限制行數。清空後重建索引,提高查詢效率。
 SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
為新添加的列設置默認值,使用 ALTER TABLE 語句:指定添加列並設置默認值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默認值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 語句可用於清空 SQL 表,步驟如下:使用 DELETE 語句:DELETE FROM table_name;替換 table_name 為要清空的表的名稱。
 Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片是指分配的內存中存在無法再分配的小塊空閒區域。應對策略包括:重啟Redis:徹底清空內存,但會中斷服務。優化數據結構:使用更適合Redis的結構,減少內存分配和釋放次數。調整配置參數:使用策略淘汰最近最少使用的鍵值對。使用持久化機制:定期備份數據,重啟Redis清理碎片。監控內存使用情況:及時發現問題並採取措施。
 phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 創建數據表,以下步驟必不可少:連接到數據庫並單擊“新建”標籤。為表命名並選擇存儲引擎(推薦 InnoDB)。通過單擊“添加列”按鈕添加列詳細信息,包括列名、數據類型、是否允許空值以及其他屬性。選擇一個或多個列作為主鍵。單擊“保存”按鈕創建表和列。
 怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
創建Oracle數據庫並非易事,需理解底層機制。 1. 需了解數據庫和Oracle DBMS的概念;2. 掌握SID、CDB(容器數據庫)、PDB(可插拔數據庫)等核心概念;3. 使用SQL*Plus創建CDB,再創建PDB,需指定大小、數據文件數、路徑等參數;4. 高級應用需調整字符集、內存等參數,並進行性能調優;5. 需注意磁盤空間、權限和參數設置,並持續監控和優化數據庫性能。 熟練掌握需不斷實踐,才能真正理解Oracle數據庫的創建和管理。
