

科大讯飞:华为昇腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座

本站 10 月 22 日消息,今年第三季度,科大讯飞实现净利润 2579 万元,同比下降 81.86%;前三季度净利润 9936 万元,同比下降 76.36%。
科大讯飞副总裁江涛在 Q3 业绩说明会上透露,讯飞已于 2023 年初与华为昇腾启动专项攻关,与华为联合研发高性能算子库,合力打造我国通用人工智能新底座,让国产大模型架构在自主创新的软硬件基础之上。
他指出,目前华为昇腾 910B 能力已经基本做到可对标英伟达 A100。在即将举行的科大讯飞 1024 全球开发者节上,讯飞和华为在人工智能算力底座上将有进一步联合发布。

他还提到,该公司一直致力于实现算法提升和工程技术方面的加速。自 2019 年被列入美国实体清单后,公司于 2022 年 10 月 7 日再次被美国对包括科大讯飞在内的 28 家中国人工智能、高性能芯片、超级计算机领域的头部企业和机构加码制裁。
本站查询公开资料发现,海思昇腾 910 发布于 2019 年,同时还推出了与之配套的新一代 AI 开源计算框架 MindSpore,而 MindSpore 也已经于 2020 年完成开源。
目前,华为昇腾社区已公开 Atlas 300T 产品有三个型号,分别对应昇腾 910A、910B、910 Pro B,最大 300W 功耗,前两者 AI 算力均为 256 TFLOPS,而 910 Pro B 可达 280 TFLOPS(FP16)。


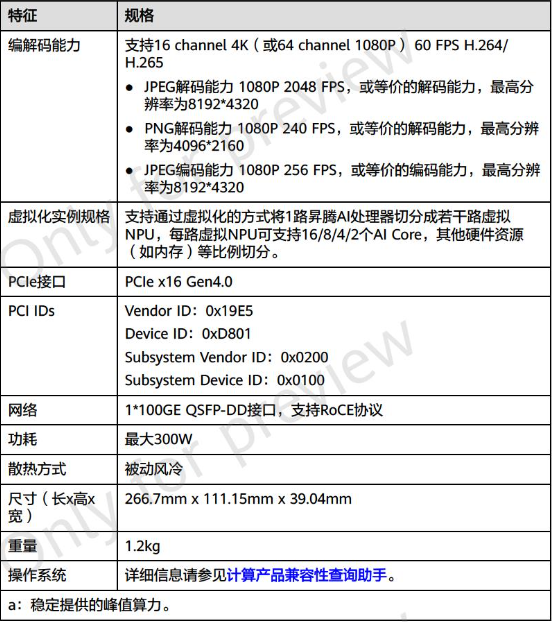



作为对比,NVIDIA A100 发布于 2020 年,采用双精度 Tensor Core,基于 Ampere 架构,功耗达到了 400W,FP32 浮点性能 19.5TFLOPS,FP16 Tensor Core 性能可达 312TFLOPS。
按照华为官方给出的规格,昇腾 910 Pro B 要比 A100 慢 18% 左右。
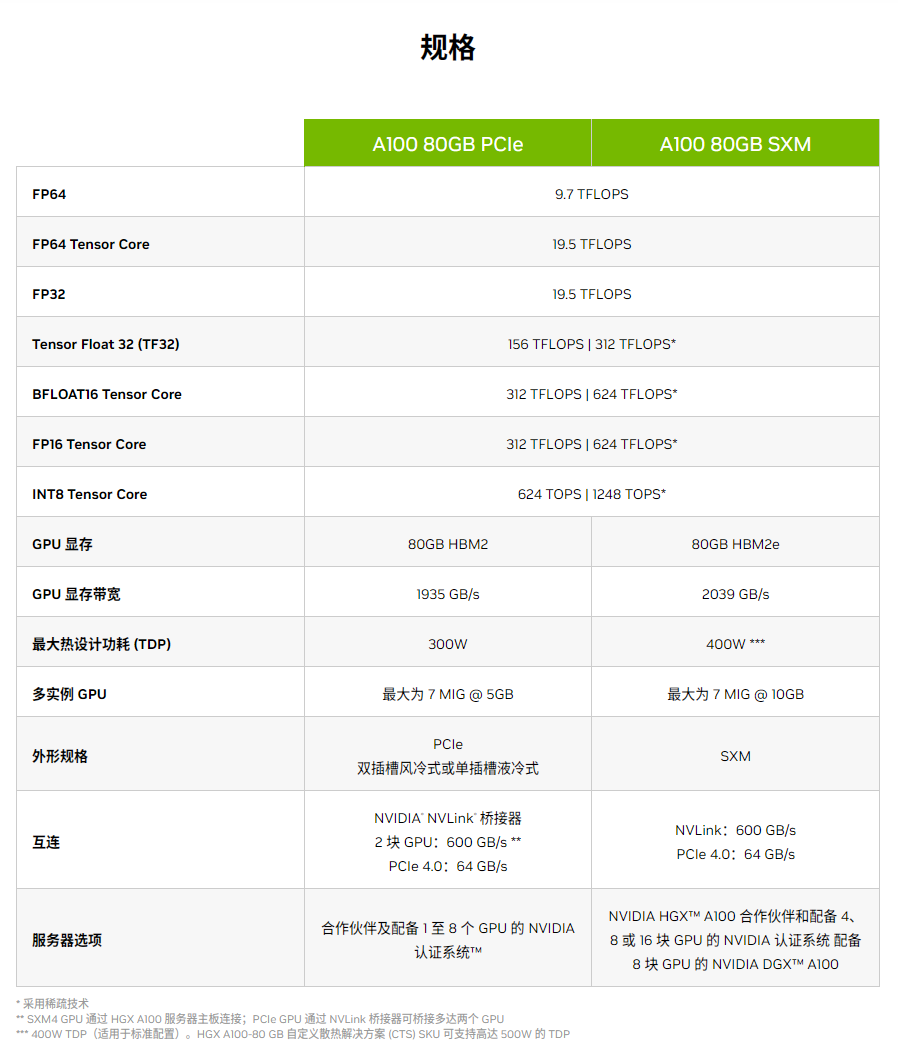
说到这里也顺便提一下 A800 芯片。这颗芯片是为了解决去年的美国商务部的半导体出口规定特意推出的一款型号,算力等参数完全不变,只是传输速率为从每秒 600GB 降至 400GB,所以美国本周发布的半导体出口新规封堵了这一漏洞。
根据知乎上 AI 从业者的反馈,哪怕昇腾 910B 目前还有不少小问题、单卡性能落后于 A800、Arm 生态有所欠缺(应该是指 CANN 对比 CUDA),但随着英伟达先进产品被禁,后续国内厂商只能被迫选择昇腾,相信昇腾产品会更加完善,并且国产厂商还可以通过堆量、增加算力集群规模的方式完成替换,至少在大模型训练领域整体差距不大。

值得一提的是,PyTorch 基金会本周三正式宣布华为作为 Premier 会员加入基金会,这也是中国首个、全球第十个 PyTorch 基金会最高级别会员。
除此之外,PyTorch 最新的 2.1 版本已同步支持昇腾 NPU,并在华为的推动下更新了更加完善的第三方设备接入机制。基于该特性,三方 AI 算力设备无需对原有框架代码进行修改就能对接 PyTorch 框架,昇腾也提供了官方认证的 Torch NPU 参考实现,可以指导三方设备便捷接入。
基于新版本,用户可以在昇腾 NPU 上直接享受原生 PyTorch 的开发体验,获得高效运行在昇腾算力设备上的模型和应用。
相关阅读:
《华为与科大讯飞启动 AI 存力底座联合创新项目》
《科大讯飞刘庆峰:华为 GPU 可对标英伟达 A100,通用大模型明年上半年对标 GPT-4》
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,本站所有文章均包含本声明。
以上是科大讯飞:华为昇腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 餘承東透露華為三折螢幕手機9月亮相:售價估計不便宜
Aug 20, 2024 am 06:36 AM
餘承東透露華為三折螢幕手機9月亮相:售價估計不便宜
Aug 20, 2024 am 06:36 AM
8月19日,鴻蒙智行在上海為享界S9舉辦了首批車主交車儀式,華為高階主管餘承東親自出席並為車主交付車輛。現場,一位已擁有問界M5、M7、M9的車主向餘承東詢問什麼時候可以買到華為三折疊屏手機,餘承東回應,下個月會有。 fenyefenye先前,網路上已流出疑似華為三折疊螢幕手機的實拍圖,引發廣泛關注。圖中,餘承東手持的新機展現了非凡的視覺衝擊力,其螢幕尺寸遠超常規折疊螢幕手機,設計獨特,非平板卻勝似平板。左側頂部鑲嵌的居中挖孔鏡頭,以及隱約可見的雙摺痕設計,手機側面疑似配備了手寫筆。這些線索無不指向,這
 華為 Mate 60 系列最佳入手時機,新增 AI 消除 + 影像升級,更可享秋日禮遇活動
Aug 29, 2024 pm 03:33 PM
華為 Mate 60 系列最佳入手時機,新增 AI 消除 + 影像升級,更可享秋日禮遇活動
Aug 29, 2024 pm 03:33 PM
自去年华为Mate60系列开售以来,我个人就一直将Mate60Pro作为主力机使用。在将近一年的时间里,华为Mate60Pro经过多次OTA升级,综合体验有了显著提升,给人一种常用常新的感觉。比如近期,华为Mate60系列就再度迎来了影像功能的重磅升级。首先是新增AI消除功能,可以智能消除路人、杂物并对空白部分进行自动补充;其次是主摄色准、长焦清晰度均有明显升级。考虑到现在是开学季,华为Mate60系列还推出了秋日礼遇活动:购机可享至高800元优惠,入手价低至4999元。常用常新的产品力加上超值
 蘋果華為都想做的無按鍵手機,被小米先做出來了?
Aug 29, 2024 pm 03:33 PM
蘋果華為都想做的無按鍵手機,被小米先做出來了?
Aug 29, 2024 pm 03:33 PM
根據Smartprix的爆料稱,小米正在研發一台代號為「朱雀」的無按鍵手機。這份爆料稱,這台代號朱雀的手機將秉承一體化的理念設計,使用屏下攝像頭,並搭載高通驍龍8gen4處理器,如果計劃沒有變動,我們很可能在2025年看到它的到來。看到這個消息,我恍惚間以為自己回到了2019年——那時小米發布了小米MIXAlpha概念機,環繞屏無按鍵設計相當驚艷。這是我第一次見識到無按鍵手機的魅力。想要一塊「魔力玻璃」,就要先把按鍵幹掉在《賈伯斯傳》中,賈伯斯曾經表達過:希望手機能夠像一塊「充滿魔力的玻璃」,
 華為將在智慧穿戴領域推出玄璣感知系統 可根據心率評估用戶情緒狀態
Aug 29, 2024 pm 03:30 PM
華為將在智慧穿戴領域推出玄璣感知系統 可根據心率評估用戶情緒狀態
Aug 29, 2024 pm 03:30 PM
近日,華為宣布將於9月推出搭載玄璣感知系統的全新智慧穿戴新品,預計為華為的最新智慧手錶。該新品將整合先進的情緒健康監測功能,玄璣感知系統以其六大特性——準確性、全面性、快速性、靈活性、開放性和延展性——為用戶提供全方位的健康評估。系統採用超感知模組,優化了多通道光路架構技術,大幅提升了心率、血氧和呼吸速率等基礎指標的監測精度。此外,玄璣感知系統也拓展了以心率資料為基礎的情緒狀態研究,不僅限於生理指標,還能評估使用者的情緒狀態和壓力水平,並支持超過60項運動健康指標監測,涵蓋心血管、呼吸、神經、內分泌、
 Mate 60降價800元、Pura 70降價1000元:就等華為發表Mate 70了!
Aug 16, 2024 pm 03:45 PM
Mate 60降價800元、Pura 70降價1000元:就等華為發表Mate 70了!
Aug 16, 2024 pm 03:45 PM
8月16日消息,對於現在的華為手機來說,已經在努力給接下來新機上市掃清道路了,所以大家看到了Mate60系列和Pura70系列陸續降價。隨著8月15日,華為官宣Mate60系列降價,華為這兩大旗艦系列的最新機種均已完成價格調整。今年7月,華為官方宣布,華為Pura70系列開啟促銷,降幅最高可達1,000元。其中,華為Pura70直降500元,到手價4999元起;華為Pura70北斗衛星消息版直降500元,到手價5099元起;華為Pura70Pro直降價800元,到手價5699元起;華為Pura70Pr
 2024Q2 全球行動程式化廣告報告:蘋果 iPhone 51% 話語權份額領銜,三星、華為和小米追趕
Aug 22, 2024 pm 02:05 PM
2024Q2 全球行動程式化廣告報告:蘋果 iPhone 51% 話語權份額領銜,三星、華為和小米追趕
Aug 22, 2024 pm 02:05 PM
本站8月22日消息,市場調查機構Pixalate昨日(8月21日)發布報告,表示在全球行動程式化廣告市場中,蘋果以51%的話語權份額(SOV)位居榜首。相關名詞解釋本站簡單介紹下專有名詞:程序化廣告(ProgrammaticAdvertising):程序化廣告是指利用廣告技術手段來購買並銷售數位廣告。程序化廣告可以在不到一秒的時間內透過自動操作步驟向受眾顯示相關的廣告。話語權份額(shareofvoice,簡稱SOV):由Pixalate測算,每個地區與特定設備類型相關的開放式程序化廣告銷售百
 華為為 Mate X5 等多款機型提供優惠 最高降價上千元
Aug 29, 2024 pm 03:32 PM
華為為 Mate X5 等多款機型提供優惠 最高降價上千元
Aug 29, 2024 pm 03:32 PM
8月29日,華為終端官方宣布,華為先鋒感恩回饋季開啟!即刻入手華為MateX5、華為Pocket2、華為novaFlip、華為Pura70系列、華為Mate60系列可享購機禮遇。不過,華為官方並未詳細說明"購機禮遇"的具體權益。 1.華為MateX5CNMO在華為商城查詢到,目前華為MateX5降價1500元,先鋒感恩回饋季購機享HUAWEICare+(一年期),諮詢客服領取;華為Pocket2購機贈價值199元Pocket2綺夢彩蝶保護殼殼殼殼殼層保護,限10點/16點/20點,每整點下單
 全球第一款三折疊螢幕!華為Mate XT螢幕供應商曝光
Sep 03, 2024 pm 06:34 PM
全球第一款三折疊螢幕!華為Mate XT螢幕供應商曝光
Sep 03, 2024 pm 06:34 PM
9月3日消息,今天,華為終端公佈了非凡大師系列新成員——MateXT。華為餘承東轉發此微博,使用的手機正是MateXT非凡大師。據悉,MateXT將是非凡大師系列首款折疊屏手機,預計為三折疊形態,在預告視頻中,數字“3”一閃而過,表明新品是一款三折疊屏旗艦。部落客數位閒聊站暗示,華為MateXT非凡大師新品的螢幕供應商為京東方,這也是業界第一家量產三折疊螢幕的屏廠。先前在今年8月份,餘承東被拍到在飛機上使用三折疊螢幕手機,從曝光圖的圖片來看,華為三折疊螢幕手機非常薄。華為三折疊螢幕手機1.
