

大數據摘要出品
家人們,繼人工智慧(AI)攻佔象棋、圍棋、Dota之後,轉筆這項技能也被AI 機器人學會了。

上面這個筆轉的賊溜的機器人,得益於名叫Eureka的智能體(Agent),是來自英偉達、賓州大學、加州理工學院和德州大學奧斯汀分校的一項研究。
得Eureka「指點」後的機器人還可以打開抽屜和櫃子、丟球和接球,或是使用剪刀。根據英偉達介紹,Eureka有10種不同的類型,可執行29種不同的任務。
要知道在之前,單就轉筆這一功能,僅靠人類專家手工編程,是無法如此順滑的實現的。

機器人盤核桃
#而Eureka 能夠自主編寫獎勵演算法來訓練機器人,且碼力強勁:自編的獎勵程式在83% 的任務中超越了人類專家,能使機器人的性能平均提升52%。
Eureka開創了一種從人類反饋中無梯度學習的新途徑,它能夠輕鬆吸收人類提供的獎勵和文字回饋,從而進一步完善自己的獎勵生成機制。
具體而言,Eureka 利用了 OpenAI 的 GPT-4 來編寫用於機器人的試誤學習的獎勵程式。這意味著該系統並不依賴人類特定任務的提示或預設的獎勵模式。
Eureka 透過在 Isaac Gym 中使用 GPU 加速的仿真,能夠快速評估大量候選獎勵的優劣,從而實現更有效率的訓練。接著,Eureka 會產生訓練結果的關鍵統計資訊摘要,並指導 LLM(Language Model,語言模型)改進獎勵函數的生成。透過這種方式,AI 智能體能夠獨立地改善對機器人的指令。
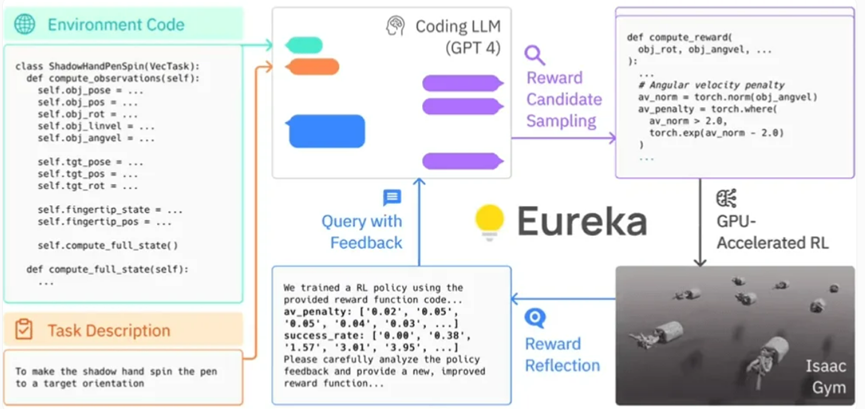
Eureka的框架
#研究人員也發現,任務越複雜,GPT- 4 的指令就越能優於所謂的"獎勵工程師"的人類指令。 參與研究的研究員甚至稱 Eureka 為「超人類獎勵工程師」。
Eureka 成功地彌補了高層推理(編碼)和低層運動控制之間的鴻溝。其採用了一種被稱為 "混合梯度架構":一個純推理的黑盒子 LLM(Language Model,語言模型)引導一個可學習的神經網路。在這個架構中,外層循環運行 GPT-4 來優化獎勵函數(無梯度),而內層循環則運行強化學習以訓練機器人的控制器(基於梯度)。
——NVIDIA的高級研究科學家Linxi "Jim" Fan
#Eureka 可以整合人類的回饋,以便更好地調整獎勵,使其更符合開發者的期望。 Nvidia 把這個過程稱為"in-context RLHF"(從人類回饋中進行上下文學習)
值得注意的是,Nvidia 的研究團隊已經開源了Eureka 的AI 演算法庫。這將使得個人和機構能夠透過 Nvidia Isaac Gym 來探索和實驗這些演算法。 Isaac Gym 是建立在 Nvidia Omniverse 平台上的,這是一個基於 Open USD 框架用於創建 3D 工具和應用程式的開發框架。

在過去的十年中,強化學習取得了巨大的成功,但我們必須承認其中仍存在持續的挑戰。之前雖然有嘗試引入類似的技術,但與使用語言模型(LLM)來輔助獎勵設計的 L2R(Learning to Reward)相比,Eureka 更為突出,因為它消除了特定任務提示的需要。 Eureka 之所以能比 L2R 更出色,是因為它能夠創建自由表達的獎勵演算法,並利用環境原始碼作為背景資訊。
英偉達的研究團隊進行了一項調查,以探索在使用人類獎勵函數啟動時,是否能提供一些優勢。實驗的目的是想看看是否你們能順利地用初始 Eureka 迭代的輸出取代原始的人類獎勵函數。
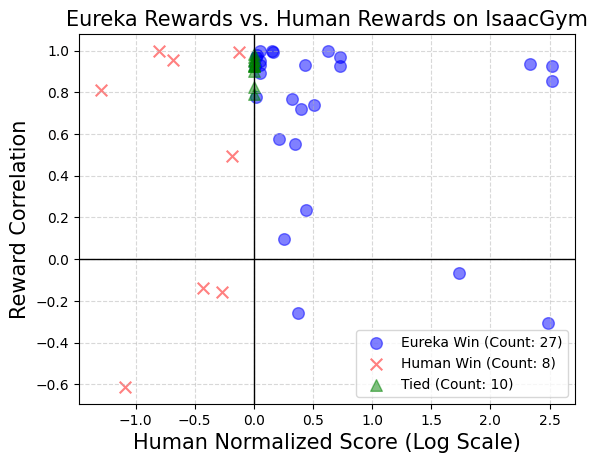
在測試中,英偉達的研究團隊在每個任務的情境下,使用相同的強化學習演算法和相同的超參數對所有最終獎勵函數進行了優化。為了測試這些特定任務的超參數是否經過良好調整以確保人工設計的獎勵的有效性,他們採用了經過充分調整的近端策略優化(PPO)實現,這個實現基於先前的工作,沒有進行任何修改。對於每個獎勵,研究人員進行了五次獨立的 PPO 訓練運行,並報告了策略檢查點達到的最大任務指標值的平均值,作為獎勵表現的測量。
結果顯示:人類設計者通常對相關狀態變數有很好的理解,但在設計有效獎勵方面可能缺乏一定的熟練度。
Nvidia 的這項開創性研究在強化學習和獎勵設計領域開闢了新的疆界。他們的通用獎勵設計演算法Eureka 利用了大型語言模型和上下文進化搜尋的力量,能夠在廣泛的機器人任務領域生成人類層級的獎勵,而無需特定任務提示或人工幹預,這在很大程度上改變了我們對AI 和機器學習的理解。
以上是機器人學會轉筆、盤核桃了! GPT-4加持,任務越複雜,表現越優秀的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















