

FMCW雷達位置辨識如何優雅的實現(IROS2023)

大家好,我叫袁健豪,很開心來自動駕駛之心平台分享我們在IROS2023上關於雷達位置識別的工作。
由於其對挑戰性環境的固有抗性,使用調頻連續波 (FMCW) 雷達的定位越來越受到關注。然而,雷達測量過程的複雜偽影需要適當的不確定性估計 - 以確保這種有前景的感測器模式的安全和可靠應用。在這項工作中,我們提出了一個多會話地圖管理系統,該系統基於嵌入空間中學到的變異屬性來建立「最佳」地圖以進行進一步的定位。使用相同的變異數屬性,我們也提出了一種新的方法,內省地拒絕可能是不正確的定位查詢。為此,我們應用了穩健的噪音感知度量學習,既利用沿驅動路徑的雷達資料的短時間尺度變化(用於資料增強),又預測基於度量空間的位置識別中的下游不確定性。我們透過 Oxford Radar RobotCar 和 MulRan 資料集的廣泛交叉驗證測試證明了我們方法的有效性。在此,我們僅使用單一最近鄰查詢就超越了雷達位置識別的當前最新技術和其他不確定性感知方法。當基於不確定性拒絕查詢時,我們也顯示了在一個困難的測試環境中的效能增加,這是我們沒有觀察到的與競爭的不確定性感知位置識別系統。
Off the Radar的出發點
位置識別和定位是機器人技術和自主系統領域的重要任務,因為它們使系統能夠理解和導航其環境。傳統的基於視覺的位置識別方法經常容易受到環境條件變化的影響,如光照、天氣和遮擋,導致表現下降。為了解決這個問題,人們越來越關注使用FMCW雷達作為這種對抗性環境的穩健感測器替代品。
現有的工作已經證明了手工製作的和基於學習的特徵提取方法的FMCW雷達位置識別的有效性。儘管現有的工作取得了成功,但這些方法在自動駕駛等安全關鍵應用中的部署仍受到校準不確定性估計的限制。在這個領域,需要考慮以下幾點:
- 安全性要求不確定性估計與誤報率良好校準,以便啟用內省拒絕;
- 即時部署需要快速的基於單次掃描不確定性的推理能力;
- 長期自主性中的重複路線遍歷需要在線連續地圖維護。
雖然VAE通常用於產生任務,但其機率潛在空間可以作為位置識別的有效度量空間表示,並允許對資料雜訊分佈進行先驗假設,這也提供了一個標準化的偶然不確定性估計。因此,在本文中,為了實現FMCW雷達在自動駕駛中的可靠和安全部署,我們利用了一個變分對比學習框架,並提出了一個統一的基於不確定性的雷達位置識別方法。
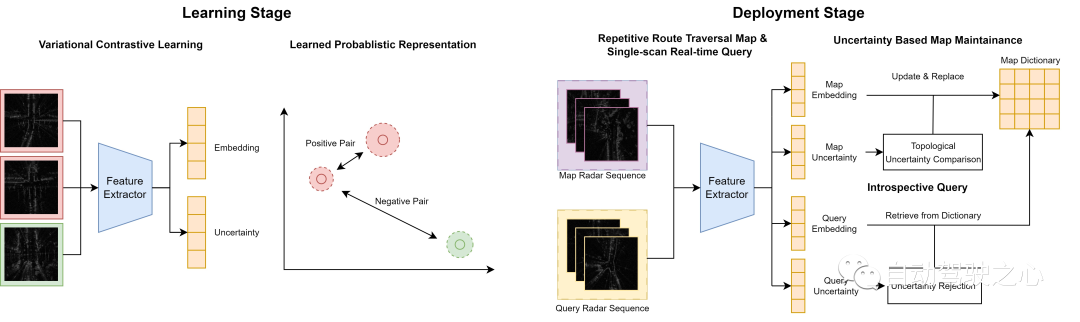 系統流程概覽
系統流程概覽
在離線階段,我們使用變分對比學習框架來學習一個具有估計不確定性的隱藏嵌入空間,使得來自相似拓撲位置的雷達掃描彼此接近,反之亦然。在線上階段,我們開發了兩種基於不確定性的機制來處理連續收集的雷達掃描,用於推理和地圖建構。對於重複遍歷相同的路線,我們透過用更確定的掃描替換高度不確定的掃描來積極維護一個整合的地圖字典。對於不確定性低的查詢掃描,我們基於度量空間距離從字典中檢索匹配的地圖掃描。相反,我們拒絕對高不確定性的掃描進行預測。
Off the Radar的方法介紹
本文介紹了一個用於雷達位置辨識的變分對比學習框架,來描述位置辨識中的不確定性。主要貢獻包括:
- 不確定性知覺的對比學習架構。
- 基於校準不確定性估計的內省查詢機制。
- 線上遞歸地圖維護用於變更的環境。
變分比較學習
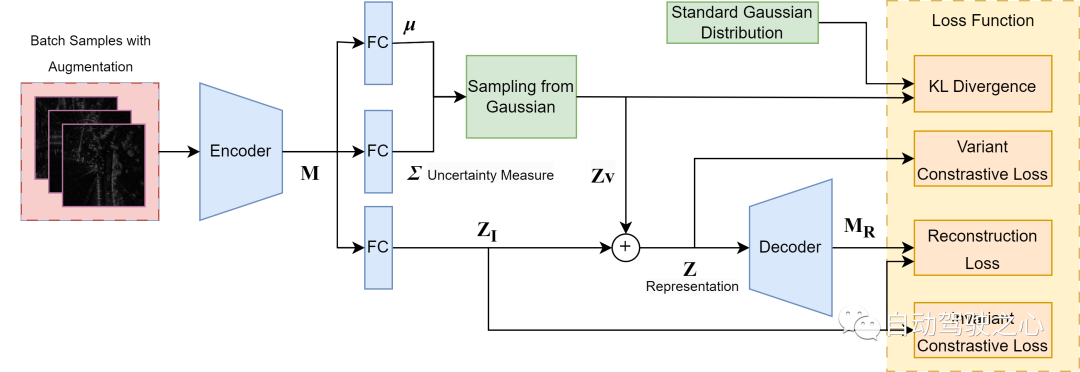
變分對比學習框架概覽,基於[^Lin2018dvml]. 透過編碼器-解碼器結構學習一個度量空間,其中有兩個重新參數化的部分:一個用於識別的確定性嵌入和一組參數建模多變量高斯分佈,其方差作為不確定性度量。整體學習由重構和對比損失共同驅動,以確保雷達掃描的資訊性和區分性的隱藏表示。
這一部分的工作既是我們核心貢獻的關鍵推動者,也是深度變分度量學習與雷達位置識別的新穎整合,以及在位置識別中表徵不確定性的新方法。如圖所示,我們採用了一個結構來將雷達掃描嵌入分解為一個噪聲誘導的變數部分,它捕獲了與預測無關的不確定性來源的方差,以及一個語義不變的部分,用於場景表示的基本特徵。變數部分後來從一個先驗的多元等方高斯分佈中取樣,並添加到不變性部分,形成整體表示。變數輸出直接用作不確定性測量。我們假設我們只考慮由數據中的固有模糊性和隨機性引起的模型預測的偶然不確定性作為不確定性的主要來源。特別是對於雷達掃描,這可能是由於斑點雜訊、飽和和臨時遮擋。標準的度量學習方法,不考慮所選的損失函數,都傾向於在正樣本對之間強制相同的嵌入,同時忽略了它們之間的潛在變異數。然而,這可能導致模型對微小特徵不敏感,並過度擬合訓練分佈。因此,為了模擬雜訊方差,我們使用結構中的額外機率方差輸出來估計偶然不確定性。為了建立這樣一個噪音感知的雷達感知表示,我們使用四個損失函數來指導整體訓練。
1) 不變對比損失在確定性表示( Z_I ) 上,以從雷達語義中分離任務無關的噪聲,使得不變嵌入包含足夠的因果信息;以及
2) 變數對比損失在整體表示( Z ) 上,建立有意義的度量空間。兩種對比損失均採取以下形式。
其中一個批次由m個樣本和使用「旋轉」策略,合成旋轉的時間近似幀增強 組成,這只是旋轉增強,用於旋轉不變性。我們的目標是最大化增強樣本被識別為原始實例的機率,同時最小化反轉情況的機率。
其中嵌入 ( Z ) 是 ( Z_I ) 或 ( Z ) ,如公式1)和2)所述。
3)Kullback–Leibler (KL) 散度在學到的高斯分佈和標準各向同性多變量高斯分佈之間,這是我們對資料雜訊的先驗假設。這確保了所有樣本雜訊的相同分佈,並為變數輸出的絕對值提供了一個靜態參考。
4) 重建損失在提取特徵圖( M ) 和解碼器輸出( M_R ) 之間,這迫使整體表示( Z ) 包含原始雷達掃描中的足夠資訊以進行重建。但是,我們只重建一個較低維度的特徵圖,而不是像素級雷達掃描重建,以減少解碼過程中的計算成本。
雖然僅由KL散度和重建損失驅動的普通VAE結構也提供了潛在方差,但由於其眾所周知的後驗崩潰和消失方差問題,它被認為不可靠地用於不確定性估計。這種無效性主要是由於訓練過程中兩個損失的不平衡:當KL散度占主導地位時,潛在空間後驗被迫等於先驗,而當重建損失占主導地位時,潛在方差被推到零。然而,在我們的方法中,我們透過引入變數對比損失作為額外的正則化器,實現了更穩定的訓練,其中方差被驅使在度量空間中保持聚類中心之間的穩健邊界。因此,我們獲得了更可靠的潛在空間方差,反映了雷達感知的基礎偶然不確定性。我們選擇在特徵增加的損失設定中展示我們特定的學習不確定性方法的好處。在這個領域,雷達位置識別的最新技術已經使用了許多(即超過2個)負樣本的損失,所以,我們在這個基礎上進行了擴展。
持續地圖維護
持續地圖維護是線上系統的重要功能,因為我們的目標是充分利用在自動駕駛車輛操作期間獲得的掃描數據,並以遞歸的方式改進地圖。合併新的雷達掃描到由先前遍歷的掃描組成的父地圖的過程如下所示。每個雷達掃描都由一個隱藏表示和一個不確定性度量表示。在合併過程中,我們為每個新掃描搜尋匹配的正樣本,拓撲距離在閾值以下。如果新掃描的不確定性較低,那麼它將被整合到父地圖中並取代匹配的掃描,否則它將被丟棄。
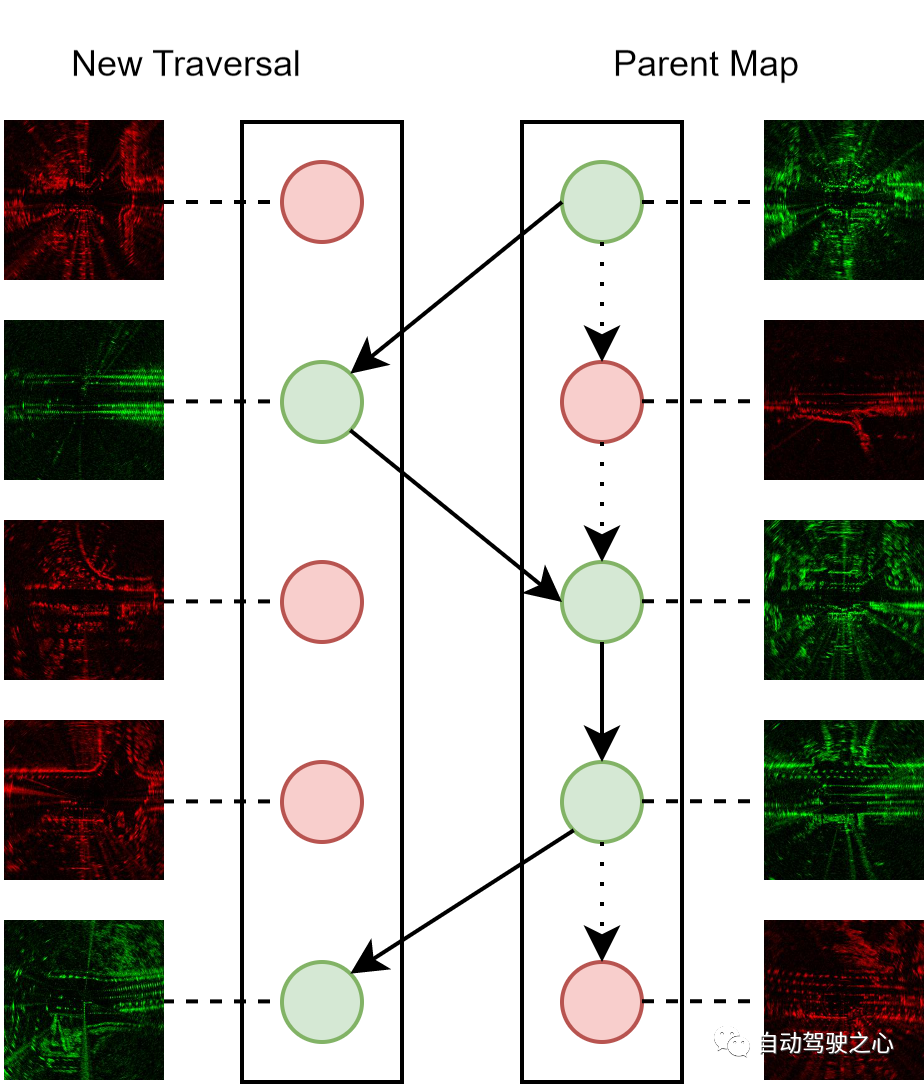
地圖維護示意圖:紅色和綠色節點分別代表具有較高和較低不確定性的雷達掃描。我們始終維護一個作為每個位置的定位參考的父地圖,該地圖僅由具有最低不確定性的掃描組成。請注意,虛線邊表示父地圖的初始狀態,實線邊表示父地圖的更新版本。
透過迭代地執行維護過程,我們可以逐漸提高整合父地圖的品質。因此,維護演算法可以作為一種有效的線上部署策略,因為它不斷地利用同一路線遍歷的多次經驗來提高識別效能,同時保持一個恆定的父地圖大小,從而導致有預算的計算和儲存成本。
內省查詢
由於與標準高斯分佈的測量的模型不確定性,所有維度的估計變異數接近1。因此,我們可以使用兩個超參數 \Delta 和 N 來完全定義不確定性拒絕的規模和解析度。得到的閾值T定義如下:
給定一個具有m 維潛在方差的掃描,我們將所有維度求平均,得到一個標量不確定性度量
預測拒絕
在推理時,我們執行內省查詢拒絕,其中方差高於定義閾值的查詢掃描將被拒絕識別。現有的方法,如 STUN 和 MC Dropout,動態地將批量樣本的不確定性範圍劃分為閾值層級。然而,這需要在推理過程中有多個樣本,並可能導致不穩定的拒絕性能,特別是當只有少量樣本時。相較之下,我們的靜態閾值策略提供了與樣本無關的閾值級別,並提供了一致的單掃描不確定性估計和拒絕。這項特性對於即時部署地點識別系統至關重要,因為在駕駛過程中,雷達掃描是逐幀獲得的。
實驗細節
本文使用兩個資料集:1) Oxford Radar RobotCar 和 2) MulRan。這兩個資料集都使用CTS350-X Navtech FMCW 掃描雷達。雷達系統在76 GHz到77 GHz的範圍內運行,可產生多達3768個範圍讀數,解析度為4.38公分。
基準測試 的識別效能是透過與幾種現有方法進行比較來完成的,包括原始的VAE,Gadd et al 提出的最先進的雷達地點辨識方法(稱為BCRadar),以及非學習基礎的方法RingKey(ScanContext 的一部分,沒有旋轉細化)。此外,性能還與 MC Dropout 和 STUN進行了比較,這兩種方法作為具有不確定性意識的地點識別基線。
消融研究為了評估我們提出的內省查詢(Q)和地圖維護(M)模組的有效性,我們透過比較我們方法的不同變體進行了消融研究,分別表示為OURS(O/M/Q/QM),具體如下:
- O: 沒有地圖維護,沒有內省查詢
- M: 僅地圖維護
- Q: 僅內省查詢
- QM: 地圖維護和內省查詢都有具體來說,我們比較了O 和M 之間的識別性能,以及Q 和QM 之間的不確定性估計性能。
通用設定為了確保公平的比較,我們為所有基於對比學習的方法採用了一個通用的批次對比損失,從而在基準測試中實現了一致的損失函數。
實作細節
掃描設定
對於所有方法,我們將具有A = 400方位和B = 3768 格的極座標雷達掃描轉換為笛卡爾掃描,每個箱子的大小為4.38 cm,具有W = 256的邊長和0.5 m 的箱子大小。
訓練超參數
我們使用VGG-19 [^simonyan2014very^] 作為背景特徵提取器,並使用一個線性層將提取的特徵投影到較低的嵌入維度d=128。我們在 Oxford Radar RobotCar 中為所有基準訓練了10 個時代,在 MulRan #中為15 個迭代,學習率為1e{-5},批次大小為8。
評估指標
為了評估地點辨識效能,我們使用 Recall@N (R@N) 指標,這是透過確定在N 個候選人中是否至少有一個候選者接近GPS/INS 所指示的地面真實值來確定的本地化的準確性。這對於自動駕駛應用中的安全保證尤其重要,因為它反映了系統對假陰性率的校準。我們也使用 Average Precision (AP) 來測量所有召回等級的平均精確度。最後,我們使用 F-scores 與 \beta=2/1/0.5# 來分配召回對精確度的重要性級別,作為評估整體識別性能的綜合指標。
此外,為了評估不確定性估計性能。我們使用 Recall@RR,在這裡我們執行內省查詢拒絕,並在不同的不確定性閾值層級上評估 Recall@N =1 -- 拒絕所有查詢的掃描的不確定性大於閾值的。我們因此拒絕了 0-100% 的查詢。
結果總結
地點辨識效能
#如Oxford Radar RobotCar實驗中表格1所示,我們的方法僅使用度量學習模組,在所有指標上都取得了最高的效能。具體來說,在 Recall@1 方面,我們的方法OURS(O) 展示了透過變分對比學習框架學習的方差解耦表示的有效性,實現了超過90.46% 的識別性能。這進一步得到了 MulRan 實驗結果的支持,如表2所示,我們的方法在 Recall@1、總體 F-scores 和 AP 上皆優於其他所有方法。儘管在 MulRan 實驗中,VAE 在 Recall@5/10 #上優於我們的方法,但我們的方法在兩個設定中的最佳 F-1/0.5/2 #和 AP 表明,我們的方法具有更高的精確度和召回率,從而實現了更準確和穩健的識別性能。
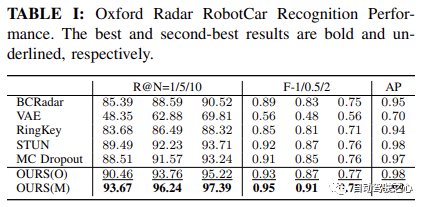
Oxford Radar RobotCar辨識效能。最佳和次佳的結果分別為粗體和__下劃線__。
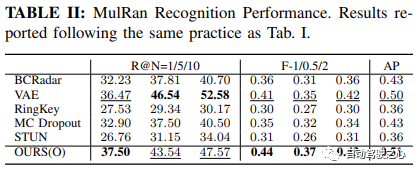
Mulran辨識效能。格式同上。
此外,透過進一步利用Oxford Radar RobotCar中的持續地圖維護,我們能夠將 Recall@1 進一步提高到93.67%,超過了當前最先進的方法STUN,超出了4.18%。這進一步證明了學習變異數作為一個有效的不確定性度量,以及基於不確定性的地圖整合策略在提高地點識別表現方面的有效性。
不確定性估計效能
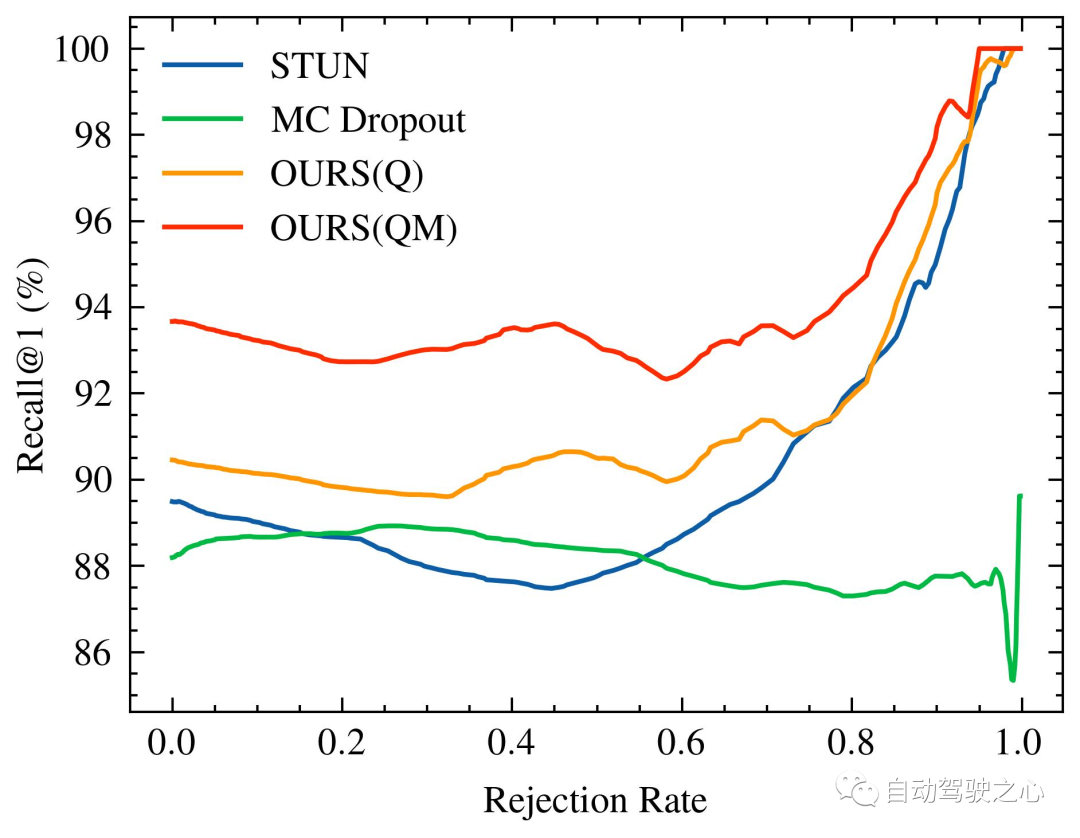
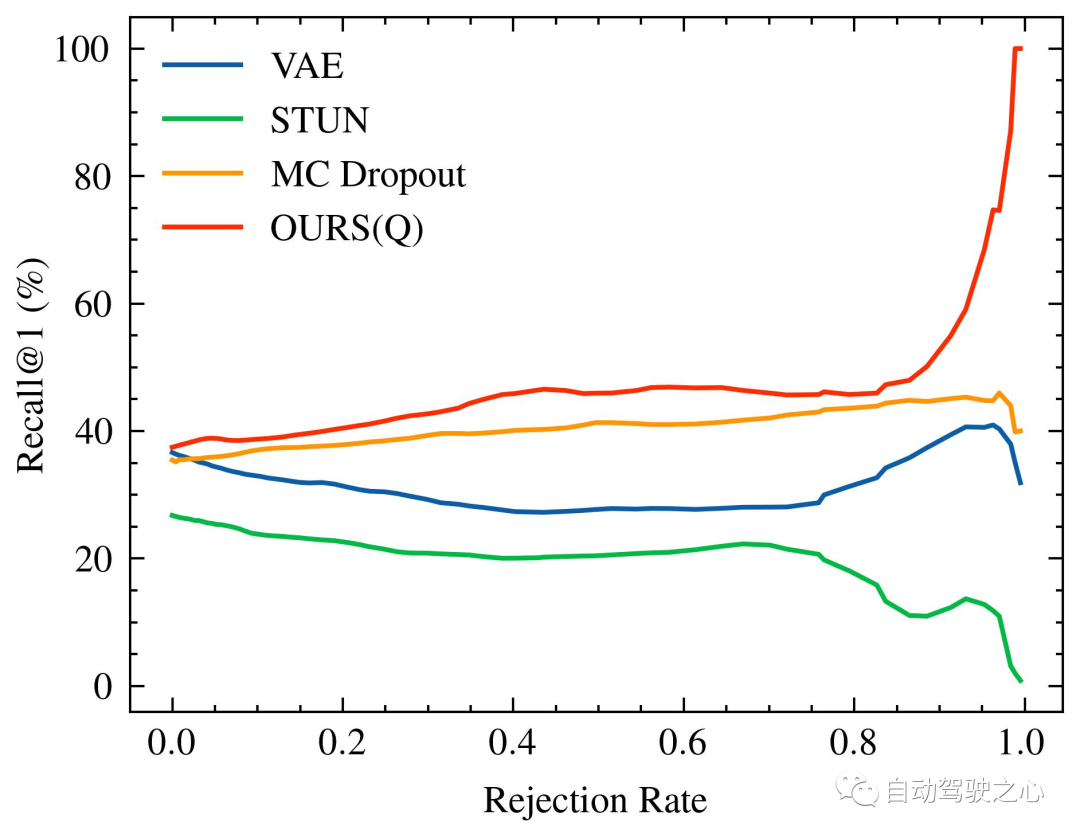
隨著被拒絕的不確定查詢的百分比增加,識別效能的變化,特別是 #Recall@1,在 Oxford Radar RobotCar 實驗中如圖1所示,在 MulRan 實驗中如圖2所示。值得注意的是,我們的方法是唯一一個在兩種實驗設定中都顯示出隨著不確定查詢拒絕率增加而持續改進的識別效能的方法。在MulRan實驗中,OURS(Q) 是唯一一個隨著拒絕率增加而持續平穩地提高 Recall@RR## 指標的方法。與VAE 和STUN 相比,這兩種方法也像我們的方法一樣估計了模型的不確定性,OURS(Q) 在 Recall@RR=0.1/0.2/0.5 上實現了(1.32/3.02/8.46)% 的改進,而VAE 和STUN 分別下降了-(3.79/5.24/8.80)% 和-(2.97/4.16/6.30)%。
Recall@1增加/減少。由於 VAE 的性能與其他方法相比較低(具體為Recall@RR=0.1/0.2/0.5的 (48.42/48.08/18.48)%),因此沒有進行視覺化。
Recall@1 增加,但其表現整體低於我們的,且隨著拒絕率進一步增加,未能實現更大的改善。最後,比較OURS(Q) 和OURS(QM) 在Oxford Radar RobotCar實驗中,我們觀察到 #Recall@RR 的變化模式相似,而它們之間存在相當大的差距。這表明內省查詢和地圖維護機制獨立地為地點識別系統做出了貢獻,每種機制都以不可或缺的方式利用了不確定性度量。
關於Off the Radar的討論
定性分析和視覺化
為了定性地評估雷達感知中的不確定性來源,我們提供了使用我們的方法估計的兩個資料集中的高/低不確定性樣本的視覺比較。如圖所示,高不確定性的雷達掃描通常顯示出重度的運動模糊和稀疏的未檢測區域,而低不確定性的掃描通常包含在直方圖中強度更強的明顯特徵。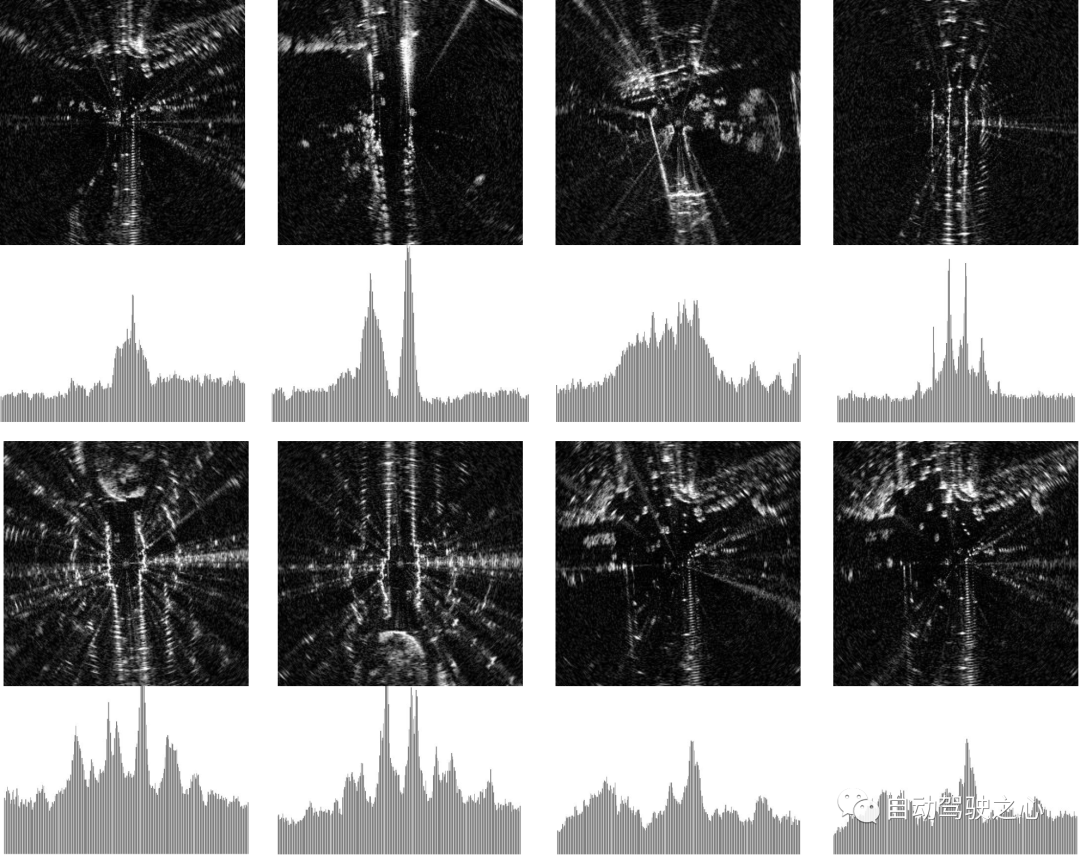
Visualization of radar scans with different levels of uncertainty. The four examples on the left are from the Oxford Radar RobotCar Dataset, while the four examples on the right are from MulRan. We show the top 10 samples with the highest (top) / lowest (bottom) uncertainty. Radar scans are displayed in Cartesian coordinates for enhanced contrast. The histogram below each image shows the RingKey descriptor features of the intensity extracted from all azimuth angles.
This further supports our hypothesis about the sources of uncertainty in radar perception and serves as qualitative evidence that our uncertainty measurements capture this data noise.
Dataset Difference
In our benchmark experiments, we observed considerable differences in recognition performance between the two datasets. We think the size of the available training data may be a legitimate reason. The training set of Oxford Radar RobotCar includes more than 300Km of driving experience, while the MulRan data set only includes about 120Km. However, also take into account the performance degradation of the RingKey descriptor method. This suggests that there may be inherent indistinguishable features in radar scene perception. For example, we found that environments with sparse open areas often resulted in identical scans and suboptimal recognition performance. We show on this dataset what happens to our system and various baselines under these high-uncertainty situations.

Original link: https://mp.weixin.qq.com/s/wu7whicFEAuo65kYp4quow
以上是FMCW雷達位置辨識如何優雅的實現(IROS2023)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
一先導與重點文章主要介紹自動駕駛技術中幾種常用的座標系統,以及他們之間如何完成關聯與轉換,最終建構出統一的環境模型。這裡重點理解自車到相機剛體轉換(外參),相機到影像轉換(內參),影像到像素有單位轉換。 3d向2d轉換會有對應的畸變,平移等。重點:自車座標系相機機體座標系需要被重寫的是:平面座標系像素座標系難點:要考慮影像畸變,去畸變和加畸變都是在像平面上去補償二簡介視覺系統一共有四個座標系:像素平面座標系(u,v)、影像座標系(x,y)、相機座標系()與世界座標系()。每種座標系之間均有聯繫,
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
 SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
原文標題:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving論文連結:https://arxiv.org/pdf/2402.02519.pdf程式碼連結:https://github.com/HKUST-Aerial-Robotics/SIMPLobotics單位論文想法:本文提出了一種用於自動駕駛車輛的簡單且有效率的運動預測基線(SIMPL)。與傳統的以代理為中心(agent-cent
 聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
最近一個月由於眾所周知的一些原因,非常密集地和業界的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火辣的特斯拉FSDV12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。如何定義端到端的自動駕駛系統,應該期望端到端解決什麼問題?依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器+分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感測器的資料(相機/LiDAR
 nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
寫在前面&出發點端到端的範式使用統一的框架在自動駕駛系統中實現多任務。儘管這種範式具有簡單性和清晰性,但端到端的自動駕駛方法在子任務上的表現仍然遠遠落後於單任務方法。同時,先前端到端方法中廣泛使用的密集鳥瞰圖(BEV)特徵使得擴展到更多模態或任務變得困難。這裡提出了一種稀疏查找為中心的端到端自動駕駛範式(SparseAD),其中稀疏查找完全代表整個駕駛場景,包括空間、時間和任務,無需任何密集的BEV表示。具體來說,設計了一個統一的稀疏架構,用於包括檢測、追蹤和線上地圖繪製在內的任務感知。此外,重
