
在快速發展的機器學習領域,有一個方面一直保持不變:繁瑣和耗時的資料標註任務。無論是用於影像分類、目標偵測或語意分割,長期以來人工標記的資料集一直是監督學習的基礎。

然而,由於一個創新的工具 AutoDistill,這種情況可能很快就會改變。
Github程式碼連結如下:https://github.com/autodistill/autodistill?source=post_page。
AutoDistill 是一個具有開創性的開源項目,旨在徹底改變監督學習的過程。該工具利用大型、較慢的基礎模型來訓練較小、更快的監督模型,使用戶能夠從未標記的圖像直接轉到在邊緣運行的自訂模型上進行推斷,無需人工幹預。
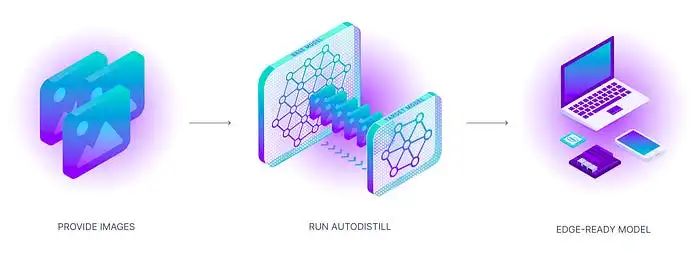
使用 AutoDistill 的過程就像它的功能一樣簡單而強大。首先將未標記的資料輸入基礎模型。然後,基礎模型使用本體來為資料集進行標註,以訓練目標模型。輸出結果是一個蒸餾模型,用於執行特定任務。
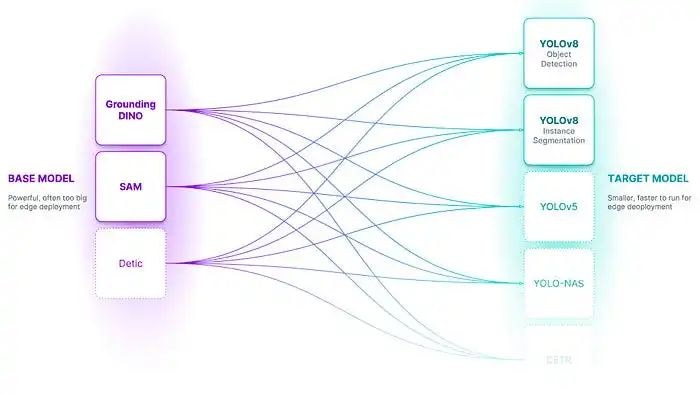
讓我們來解釋這些元件:
AutoDistill的易用性確實令人矚目:將未標記的輸入資料傳遞給基礎模型,例如Grounding DINO,然後使用本體標記資料集以訓練目標模型,最終得到一個經過加速蒸餾和微調的針對特定任務的模型
請點擊以下鏈接觀看視頻,以了解實際操作過程:https://youtu.be/gKTYMfwPo4M
電腦視覺一直以來都存在著一個主要障礙,即標註需要大量的人工勞動。 AutoDistill則邁出了解決這個問題的重要一步。該工具的基礎模型能夠自主創建許多常見用例的資料集,並且透過創造性提示和少樣本學習的方式擴展實用性,具有很大的潛力
然而,儘管這些進步令人印象深刻,但並不意味著不再需要標記的數據。隨著基礎模型的不斷改進,它們將越來越能夠在標註過程中取代或補充人類。但目前,在某種程度上,人工標註仍然是必要的。
隨著研究人員不斷提高目標偵測演算法的準確性和效率,我們預計將看到它們應用於更廣泛的實際應用領域。例如,即時目標偵測是一個關鍵的研究領域,對於自動駕駛、監控系統和體育分析等領域有許多應用。
影片中的目標偵測是一個具有挑戰性的研究領域,它涉及在多個影格之間追蹤物件並處理動態模糊。這些領域的發展將為目標偵測帶來新的可能性,同時也展示了AutoDistill 等工具的潛力
AutoDistill 代表了機器學習領域的一項令人興奮的發展。透過使用基礎模型來訓練監督模型,該工具為未來鋪平了道路,資料標註這項繁瑣任務在開發和部署機器學習模型中將不再是一個瓶頸。
以上是目標偵測標註的時代已經終結?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















