

微軟推出 '從錯誤中學習” 模型訓練法,號稱可'模仿人類學習過程,改善 AI 推理能力”

微軟亞洲研究院聯合北京大學、西安交通大學等大學,最近提出了一種名為「從錯誤中學習(LeMA)」的人工智慧訓練方法。此方法聲稱能夠透過模仿人類學習的過程,來提升人工智慧的推理能力
#當下OpenAI GPT-4 和GoogleaLM-2 等大語言模型在自然語言處理(NLP)任務,及思考鏈(chain-of-thought,CoT)推理的數學難題任務中都有不錯的表現。
但例如 LLaMA-2 及 Baichuan-2 等開源大模型,在處理相關問題時則有待加強。為了提升開源這些大語言模型的思考鏈推理能力,研究團隊提出了 LeMA 方法。這種方法主要是模仿人類的學習過程,透過“從錯誤中學習”,以改進模型的推理能力。
▲ 圖源相關論文
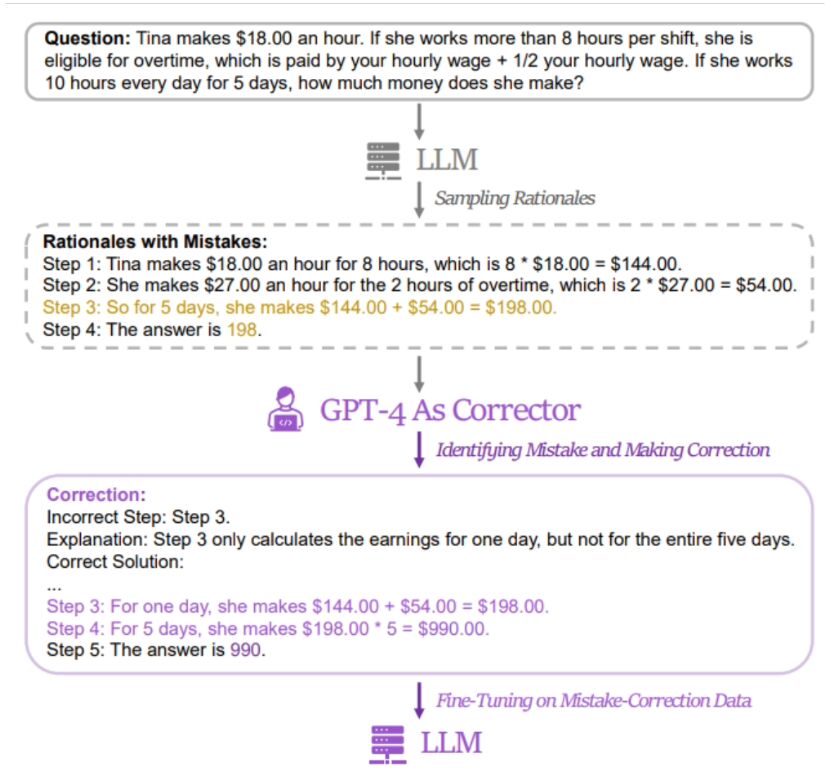
本站發現,研究人員的方法是使用一對包含「錯誤解答」與「修正後正確答案」的數據來微調相關模型。為取得相關數據,研究人員收集了 5 個不同大語言模型(包括 LLaMA 及 GPT 系列)的錯誤答案和推理過程,再以 GPT-4 作為“訂正者”,提供修正後的正確答案。
據悉,修正後的正確答案包含三類訊息,分別是原推理過程中錯誤片段、原推理過程出錯的原因、以及如何修正原方法以獲得正確答案。
研究人員使用GSM8K和MATH測試了LeMa訓練法對5個開源大模型的效果。結果顯示,在改進後的LLaMA-2-70B模型中,GSM8K的準確率分別為83.5%和81.4%,而MATH的準確率分別為25.0%和23.6%
目前研究人員已將LeMA 的相關資料公開在GitHub 上,有興趣的朋友可以點此跳轉。
以上是微軟推出 '從錯誤中學習” 模型訓練法,號稱可'模仿人類學習過程,改善 AI 推理能力”的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
譯者|布加迪審校|重樓本文介紹如何使用GroqLPU推理引擎在JanAI和VSCode中產生超快速反應。每個人都致力於建立更好的大語言模型(LLM),例如Groq專注於AI的基礎設施方面。這些大模型的快速響應是確保這些大模型更快捷響應的關鍵。本教學將介紹GroqLPU解析引擎以及如何在筆記型電腦上使用API和JanAI本地存取它。本文也將把它整合到VSCode中,以幫助我們產生程式碼、重構程式碼、輸入文件並產生測試單元。本文將免費創建我們自己的人工智慧程式設計助理。 GroqLPU推理引擎簡介Groq
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 大模型一對一戰鬥75萬輪,GPT-4奪冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
大模型一對一戰鬥75萬輪,GPT-4奪冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
關於Llama3,又有測試結果新鮮出爐-大模型評測社群LMSYS發布了一份大模型排行榜單,Llama3位列第五,英文單項與GPT-4並列第一。圖片不同於其他Benchmark,這份榜單的依據是模型一對一battle,由全網測評者自行命題並評分。最終,Llama3取得了榜單中的第五名,排在前面的是GPT-4的三個不同版本,以及Claude3超大杯Opus。而在英文單項榜單中,Llama3反超了Claude,與GPT-4打成了平手。對於這一結果,Meta的首席科學家LeCun十分高興,轉發了推文並
 大模型做時序預測也很強!華人團隊啟動LLM新能力,超越一眾傳統模式實現SOTA
Apr 11, 2024 am 09:43 AM
大模型做時序預測也很強!華人團隊啟動LLM新能力,超越一眾傳統模式實現SOTA
Apr 11, 2024 am 09:43 AM
大語言模型潛力被激發-無需訓練大語言模型就能實現高精度時序預測,超越一切傳統時序模型。蒙納士大學、螞蟻和IBM研究院共同開發了一個通用框架,成功推動了大語言模型跨模態處理序列資料的能力。該框架已成為一項重要的技術創新。時序預測有益於城市、能源、交通、遙感等典型複雜系統的決策。自此,大模型可望徹底改變時序/時空資料探勘方式。通用大語言模型重編程框架研究團隊提出了一個通用框架,將大語言模型輕鬆用於一般時間序列預測,而無需做任何訓練。主要提出兩大關鍵技術:時序輸入重編程;提示做前綴。 Time-
 七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
想了解更多AIGC的內容,請造訪:51CTOAI.x社群https://www.51cto.com/aigc/譯者|晶顏審校|重樓不同於網路上隨處可見的傳統問題庫,這些問題需要跳脫常規思維。大語言模型(LLM)在數據科學、生成式人工智慧(GenAI)和人工智慧領域越來越重要。這些複雜的演算法提升了人類的技能,並在許多產業中推動了效率和創新性的提升,成為企業保持競爭力的關鍵。 LLM的應用範圍非常廣泛,它可以用於自然語言處理、文字生成、語音辨識和推薦系統等領域。透過學習大量的數據,LLM能夠產生文本
 第二代Ameca來了!和觀眾對答如流,臉部表情更逼真,會說幾十種語言
Mar 04, 2024 am 09:10 AM
第二代Ameca來了!和觀眾對答如流,臉部表情更逼真,會說幾十種語言
Mar 04, 2024 am 09:10 AM
人形機器人Ameca升級第二代了!最近,在世界行動通訊大會MWC2024上,世界上最先進機器人Ameca又現身了。會場周圍,Ameca引來一大波觀眾。得到GPT-4加持後,Ameca能夠對各種問題做出即時反應。 「來一段舞蹈」。當被問及是否有情感時,Ameca用一系列的面部表情做出回應,看起來非常逼真。就在前幾天,Ameca背後的英國機器人公司EngineeredArts剛剛示範了團隊最新的開發成果。影片中,機器人Ameca具備了視覺能力,能看見並描述房間整個狀況、描述具體物體。最厲害的是,她還能
 全球最強模型一夜易主,GPT-4時代終結! Claude 3提前狙擊GPT-5,3秒讀懂萬字論文理解力接近人類
Mar 06, 2024 pm 12:58 PM
全球最強模型一夜易主,GPT-4時代終結! Claude 3提前狙擊GPT-5,3秒讀懂萬字論文理解力接近人類
Mar 06, 2024 pm 12:58 PM
卷瘋了卷瘋了,大模型又變天了。就在剛剛,全球最強AI模型一夜易主,GPT-4被拉下神壇。 Anthropic發布了最新的Claude3系列模型,一句話評價:真·全面碾壓GPT-4!在多模態和語言能力指標上,Claude3都贏麻了。用Anthropic的話來說,Claude3系列模型在推理、數學、編碼、多語言理解和視覺方面,都樹立了新的行業基準! Anthropic,就是曾因安全理念不合,而從OpenAI「叛逃」出的員工組成的新創公司,他們的產品一再給OpenAI暴擊。這次的Claude3,更是整了個大的
 ChatGPT和生成式人工智慧在數位轉型中的意義
May 15, 2023 am 10:19 AM
ChatGPT和生成式人工智慧在數位轉型中的意義
May 15, 2023 am 10:19 AM
開發ChatGPT的OpenAI公司在網站上展示了摩根士丹利進行的一個案例研究。其主題是「摩根士丹利財富管理部署GPT-4來組織其龐大的知識庫。」該案例研究引述摩根士丹利分析、數據與創新主管JeffMcMillan的話說,「該模型將為一個面向內部的聊天機器人提供動力,該機器人將對財富管理內容進行全面搜索,並有效地解鎖摩根士丹利財富管理的累積知識」。 McMillan進一步強調:「採用GPT-4,你基本上立刻就擁有了財富管理領域最博學的人的知識……可以把它想像成我們的首席投資策略師、首席全球經濟學家
