

我們一起聊聊知識抽取,你學會了嗎?

一、簡介
知識抽取通常指從非結構化文字中挖掘結構化訊息,例如含有豐富語意資訊的標籤和短語。這在業界被廣泛應用於內容理解和商品理解等場景,透過從用戶生成的文本資訊中提取有價值的標籤,將其應用於內容或商品上
#知識抽取通常伴隨著對所抽取標籤或短語的分類,通常被建模為命名實體識別任務,通用的命名實體識別任務是識別命名實體成分並將成分劃分到地名、人名、機構名等類型上;領域相關的標籤詞抽取將標籤詞識別並劃分到領域自訂的類別上,如係列(空軍一號、音速9)、品牌(Nike、李寧)、類型(鞋、服裝、數碼)、風格(ins 風、復古風、北歐風)等。
為了方便描述,下文將富含資訊的標籤或短語統一稱為標籤詞
二、知識抽取分類
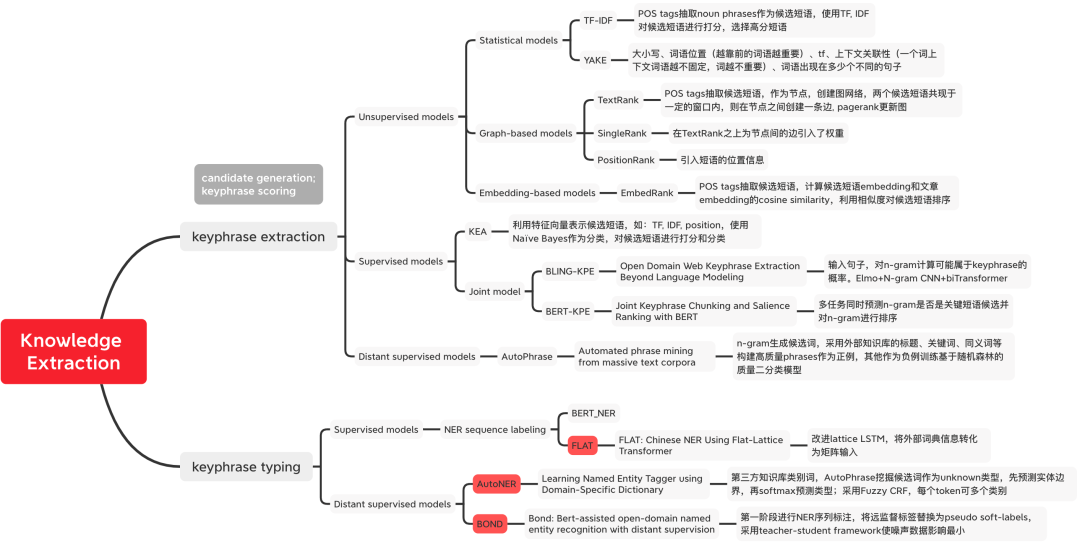 圖1 知識抽取方法分類
圖1 知識抽取方法分類
三、標籤詞挖掘
無監督方法
基於統計的方法
- TF-IDF(Term Frequency-Inverse Document Frequency) :統計每個字的 TF-IDF 評分,分數越高說明包含的資訊量越大。
重寫後的內容:計算方法:tfidf(t, d, D) = tf(t, d) * idf(t, D),其中tf(t, d) = log (1 freq(t, d)),freq(t,d)表示候選詞t 在目前文件d 中出現的次數,idf(t,D) = log(N/count(d∈D:t∈D) )表示候選詞t 出現在多少文件中,用來表示一個詞語的稀有度,假如一個詞語只在一篇文檔中出現,說明這個詞語比較稀有,信息量更豐富
特定業務場景下可以藉助外部工具對候選詞先進行一輪篩選,如採用詞性標識篩選名詞。
- YAKE[1]:定義了五個特徵來捕捉關鍵字特徵,這些特徵被啟發式地組合起來,為每個關鍵字分配一個分數。分數越低,關鍵字越重要。 1)大寫字:大寫字母的Term(除了每句的開頭單字)的重要性比那些小寫字母的Term 重要程度要大,對應到中文可能是粗體字次數;2)字位置:每段文本越開頭的部分詞的重要性比後面的詞重要程度更大;3)詞頻,統計詞出現的頻次;4)詞的上下文關係,用來衡量固定窗口大小下出現不同詞的個數,一個詞與越多不相同的詞共現,該詞的重要性越低;5)詞在不同句子中出現的次數,一個詞在更多句子中出現,相對更重要。
基於圖形的方法Graph-Based Model
- TextRank[2]:首先對文字進行分詞和詞性標註,並過濾掉停用詞,只保留指定詞性的單字來建構圖。每個節點都是一個單詞,邊表示單字之間的關係,透過定義單字在預定大小的移動視窗內的共現來建構邊。採用PageRank 更新節點的權重直至收斂;對節點權重進行倒排序,從而得到最重要的k 個字語,作為候選關鍵字;將候選詞在原始文本中進行標記,若形成相鄰詞組,則組合成多詞組的關鍵字詞組。
基於表徵的方法Embedding-Based Model
- EmbedRank[3]:透過分詞和詞性標註選擇候選詞,採用預先訓練好的 Doc2Vec 和 Sent2vec 作為候選詞和文件的向量表徵,計算餘弦相似度對候選詞進行排序。類似的,KeyBERT[4] 將 EmbedRank 的向量表徵替換為 BERT。
有監督方法
- 先篩候選詞再採用標籤詞分類:經典的模型 KEA[5] 對四個設計的特徵採用 Naive Bayes 作為分類器對 N-gram 候選詞進行評分。
- 候選詞篩選和標籤詞識別聯合訓練:BLING-KPE[6] 將原始句子作為輸入,分別用CNN、Transformer 對句子的N-gram 短語進行編碼,計算該短語是標籤詞的機率,是否是標籤詞採用人工標註Label。 BERT-KPE[7] 在 BLING-KPE 的思想基礎上,將 ELMO 替換為 BERT 來更好地表示句子的向量。
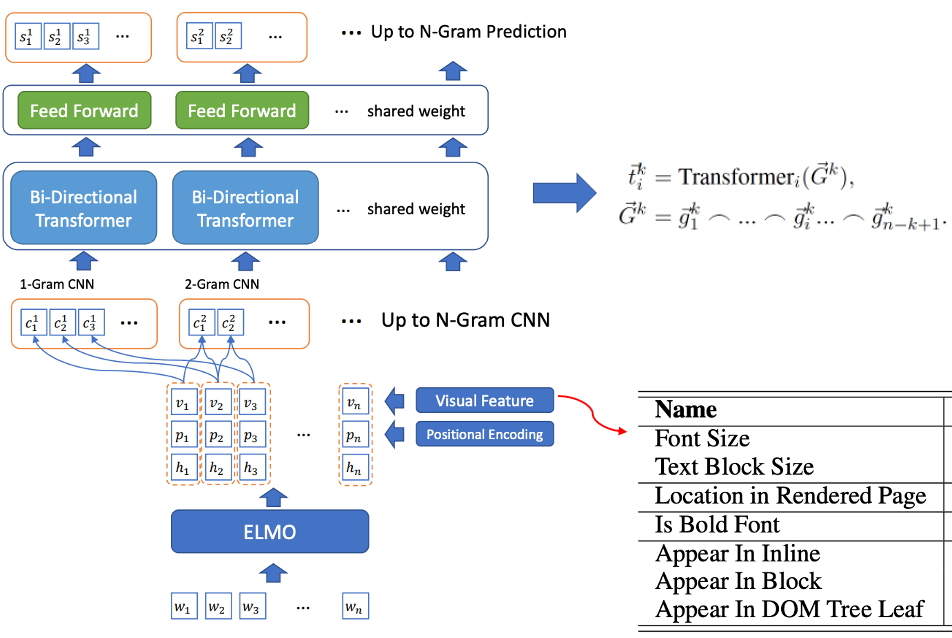 圖2 BLING-KPE 模型結構
圖2 BLING-KPE 模型結構
遠監督方法
##AutoPhrase遠監督方法的典型代表是AutoPhrase[10],在業界標籤詞探勘中被廣泛使用。 AutoPhrase 借助現有的高品質知識庫進行遠端監督訓練,避免人工標註。
- Popularit:文檔中出現的頻次夠高;
- Concordance:Token 搭配出現的頻率遠高於替換後的其他搭配,即共現的頻次;
- Informativeness:有資訊量、明確指示性,如「this is」就是沒有資訊量的負例;
- Completeness:片語及其子片語都要具有完整性。
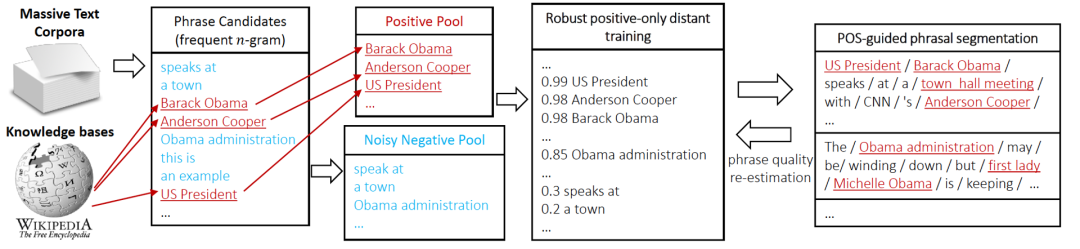 圖3 AutoPhrase 標籤挖掘流程
圖3 AutoPhrase 標籤挖掘流程
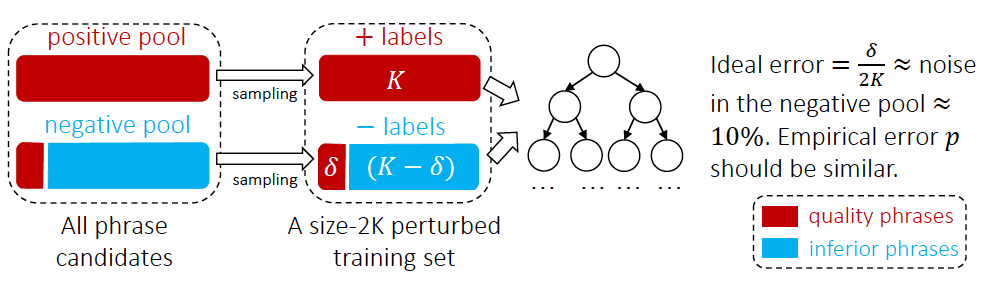 圖4 AutoPhrase標籤詞分類方法
圖4 AutoPhrase標籤詞分類方法
NER 序列標註模型
Lattice LSTM[8] 是針對中文NER 任務引入詞彙訊息的開頭之作,Lattice 是一個有向無環圖,詞彙的開始和結束字符決定了格子位置,透過詞彙訊息(字典)配對一個句子時,可以得到一個類似Lattice 的結構,如圖5(a) 所示。 Lattice LSTM 結構則融合了詞彙訊息到原生的LSTM 中,如5(b) 所示,對於當前的字符,融合以該字符結束的所有外部詞典信息,如“店”融合了“人和藥店”和「藥局」的資訊。對於每一個字符,Lattice LSTM 採取注意力機制去融合個數可變的詞單元。雖然Lattice-LSTM 有效提升了NER 任務的性能,但RNN 結構無法捕捉長距離依賴,同時引入詞彙資訊是有損的,同時動態的Lattice 結構也不能充分進行GPU 並行,Flat[9] 模型有效改善了這兩個問題。如圖5(c),Flat 模型透過Transformer 結構來捕捉長距離依賴,並設計了一種位置編碼Position Encoding 來融合Lattice 結構,將字符匹配到的詞彙拼接到句子後,對於每一個字符和詞彙都建造兩個Head Position Encoding 和Tail Position Encoding,將Lattice 結構展平,從一個有向無環圖展平為一個平面的Flat-Lattice Transformer 結構。
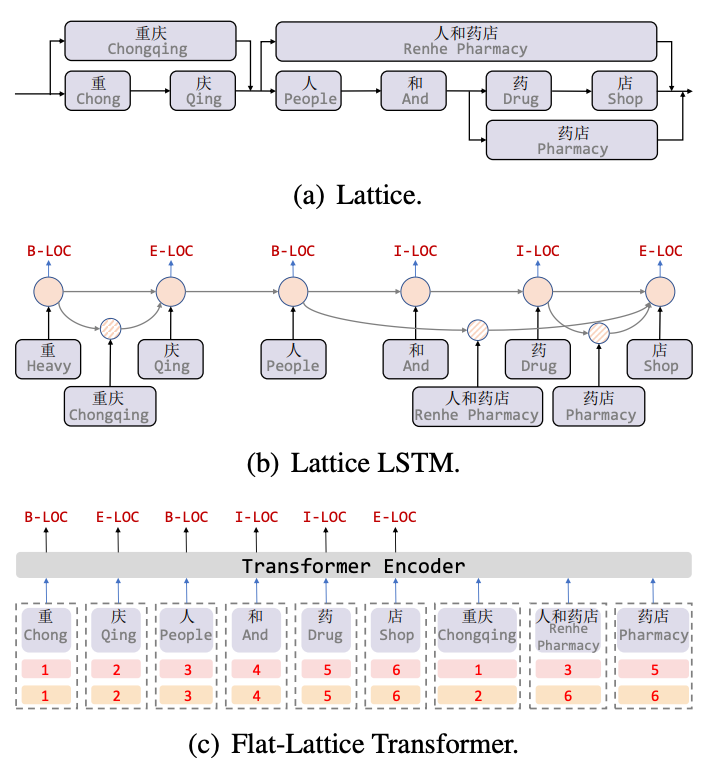 圖5 引入詞彙資訊的NER 模型
圖5 引入詞彙資訊的NER 模型
遠監督方法
AutoNER
為了解決遠監督中的噪音問題,我們採用了Tie或Break的實體邊界識別方案來取代BIOE的標註方式。其中,Tie表示當前詞和上一個詞屬於同一個實體,而Break表示當前詞和上一個詞不再同一個實體中
在實體分類階段,使用模糊CRF(Fuzzy CRF)來應對一個實體具有多種類型的情況
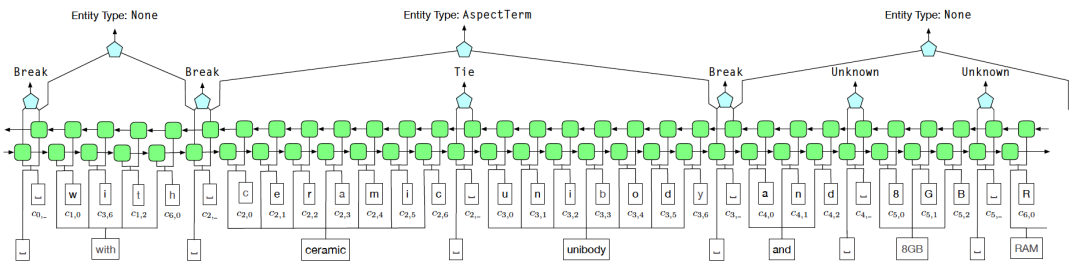 圖6 AutoNER 模型結構圖
圖6 AutoNER 模型結構圖
BOND
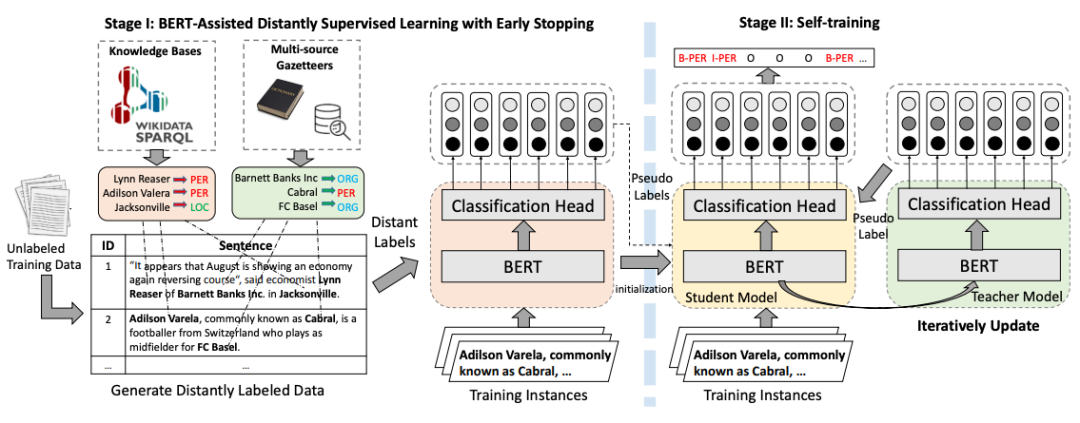 圖片
圖片
需要重新書寫的內容是:圖7 BOND訓練流程圖
五、總結
參考文獻
【1】Campos R, Mangaravite V, Pasquali A, et al. Yake! collection-independent automatic keyword extractor[ C]//Advances in Information Retrieval: 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26-29, 2018, Proceedings 40. Springer International Publishing, 2018: 806-810. /LIAAD/yake
【2】Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
3 】Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J]. arXiv preprint arXiv:1801.04470, 2018. arXiv preprint arXiv:1801.04470, 2018.KKey#BERT#://gKKey:2018. .com/MaartenGr/KeyBERT
【5】Witten I H, Paynter G W, Frank E, et al. KEA: Practical automatic keyphrase extraction[C]//Proceedings of the fourth ACM conference on Digital libraries. 1999: 254-255.
翻譯內容:【6】熊L,胡C,熊C,等。超越語言模型的開放領域Web關鍵字擷取[J]。 arXiv預印本arXiv:1911.02671,2019年
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020). Joint Keyphrase Chunking and Salience Ranking with BERT. arXiv preprint arXiv:2004.13639.
需要重寫的內容是:【8】張Y,楊J。使用格子LSTM的中文命名實體辨識[C]。 ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: Chinese NER using flat-lattice transformer[C]. ACL 2020.
#【10】Shang J , Liu J, Jiang M, et al. Automated phrase mining from massive text corpora[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. Learning named entity tagger using domain-specific dictionary[C]. EMNLP, 2018.
【12】Liang C, Yu Y, Jiang H, et al. Bond : Bert-assisted open-domain named entity recognition with distant supervision[C]//Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020: 1054-1064.#13#;搜尋中NER技術的探索與實踐,https://zhuanlan.zhihu.com/p/163256192
以上是我們一起聊聊知識抽取,你學會了嗎?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 帶你了解相當震撼的win10x系統知識
Jul 14, 2023 am 11:29 AM
帶你了解相當震撼的win10x系統知識
Jul 14, 2023 am 11:29 AM
近日,網路中有win10X系統的最新鏡像下載流出,不同於常見的ISO,此次的鏡像是.ffu格式,目前僅能用於SurfacePro7體驗。雖然很多小夥伴不能體驗,但依舊可以看看評測的相關內容,過過癮,那麼一起來看看win10x系統最新評測吧!win10x系統最新評測1、Win10X與Win10最大的不同首先就表現在開機後開始按鈕等被放在了任務欄中央,除了固定的應用程序,任務欄還可以顯示最近啟動的應用程序,類似於Android和iOS手機。 2、另外一個就是,新系統的「開始」選單不支援文
 原神胡桃一斗抽取建議
Mar 15, 2024 pm 05:07 PM
原神胡桃一斗抽取建議
Mar 15, 2024 pm 05:07 PM
原神胡桃後面的池子就是一斗,作為一個新的岩元素角色,未出先火,很多女玩家都在期待,那麼原神胡桃和一斗抽哪個?下面小編帶給大家原神胡桃一斗抽取建議,一起看看吧。原神胡桃和一斗抽哪個1、胡桃強度不弱,而且不吃聖遺物,一斗目前只爆料一點點,具體情況還不知道怎麼樣。 2.胡桃近半年內不會有替代品,還是強力火c,打深淵冰水夠了,稱得上是最強火c。 3.一斗就是大號女僕,而且比較吃命座,五星級命座很難獲取,不太划算。 4.一鬥基本上是綁定阿貝多的,雖然強度也不算低,但是有一定的培養成本。主要還是看玩家自己的角色,如
 聊天機器人是如何透過知識圖譜回答問題的?
Apr 17, 2023 am 09:13 AM
聊天機器人是如何透過知識圖譜回答問題的?
Apr 17, 2023 am 09:13 AM
前言1950年,圖靈發表了具有里程碑意義的論文《計算機器與智能》(ComputingMachineryandIntelligence),提出了一個關於機器人的著名判斷原則——圖靈測試,也被稱為圖靈判斷,它指出如果第三者無法辨別人類與AI機器反應的差別,則可以論斷該機器具備人工智慧。 2008年,漫威《鋼鐵人》中的AI管家賈維斯,讓人們知道了AI是如何精準地幫助人類(東尼)解決丟過來的各種事務的…圖1:AI管家賈維斯(圖片來源網路)2023年初,以2C的方式從科技界火爆破圈的免費聊天機器人Chat
 了解Golang:開發者必備知識
Feb 23, 2024 am 10:51 AM
了解Golang:開發者必備知識
Feb 23, 2024 am 10:51 AM
Golang,又稱為Go語言,是一種由Google開發的開源程式語言。自2007年發布以來,Golang在軟體開發領域逐漸嶄露頭角,得到了越來越多開發者的青睞。作為一種靜態類型、編譯型語言,Golang擁有許多優點,如高效的並發處理能力、簡潔的語法、強大的工具支援等,使其在雲端運算、大數據處理、網路程式設計等方面具有廣泛應用前景。本文將介紹Golang的基本概念、
 我們一起聊聊知識抽取,你學會了嗎?
Nov 13, 2023 pm 08:13 PM
我們一起聊聊知識抽取,你學會了嗎?
Nov 13, 2023 pm 08:13 PM
一、簡介知識抽取通常指從非結構化文字中挖掘結構化訊息,例如含有豐富語意資訊的標籤和短語。這在業界被廣泛應用於內容理解和商品理解等場景,透過從用戶生成的文本資訊中提取有價值的標籤,將其應用於內容或商品上知識抽取通常伴隨著對所抽取標籤或短語的分類,通常被建模為命名實體識別任務,通用的命名實體識別任務就是識別命名實體成分並將成分劃分到地名、人名、機構名等類型上;領域相關的標籤詞抽取將標籤詞識別並劃分到在領域自訂的類別上,如係列(空軍一號、音速9)、品牌(Nike、李寧)、類型(鞋、服裝、數位)、風格(
 了解Linux伺服器安全:必備的知識與技能
Sep 09, 2023 pm 02:55 PM
了解Linux伺服器安全:必備的知識與技能
Sep 09, 2023 pm 02:55 PM
了解Linux伺服器安全:必備的知識和技能隨著網路的不斷發展,Linux伺服器越來越廣泛地應用於各個領域。然而,由於伺服器儲存了大量的敏感數據,其安全性問題也成為了人們關注的焦點。本文將介紹一些必備的Linux伺服器安全知識和技能,幫助您保護您的伺服器免受攻擊。更新及維護作業系統及軟體及時更新作業系統及軟體是維持伺服器安全的重要一環。因為每個作業系統和軟體
 掌握HTML全域屬性的關鍵知識與實務技巧
Jan 06, 2024 am 08:40 AM
掌握HTML全域屬性的關鍵知識與實務技巧
Jan 06, 2024 am 08:40 AM
學習HTML全域屬性的必備知識與實踐技巧HTML(HyperTextMarkupLanguage)是一種用來建立網頁結構的標記語言。在建立網頁時,我們常常需要使用各種標籤和屬性來定義頁面的外觀與行為。而在所有的HTML屬性中,全域屬性是一類非常重要的屬性,它們可以應用於所有的HTML標籤,為網頁開發者提供了強大的彈性和自訂能力。在學習和使用HTML全
 深入了解jQuery兄弟節點的相關知識
Feb 27, 2024 pm 06:51 PM
深入了解jQuery兄弟節點的相關知識
Feb 27, 2024 pm 06:51 PM
毫無疑問,jQuery是前端開發中最常用的JavaScript程式庫之一,它提供了簡潔而強大的方法來操作HTML文件。在jQuery中,兄弟節點是指與指定元素有相同父元素的元素。深入了解jQuery兄弟節點的相關知識對於前端開發者來說是至關重要的。本文將介紹如何使用jQuery來操作兄弟節點,並附上具體的程式碼範例。 1.查找兄弟節點在jQuery中,我們可以透過
