

GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤

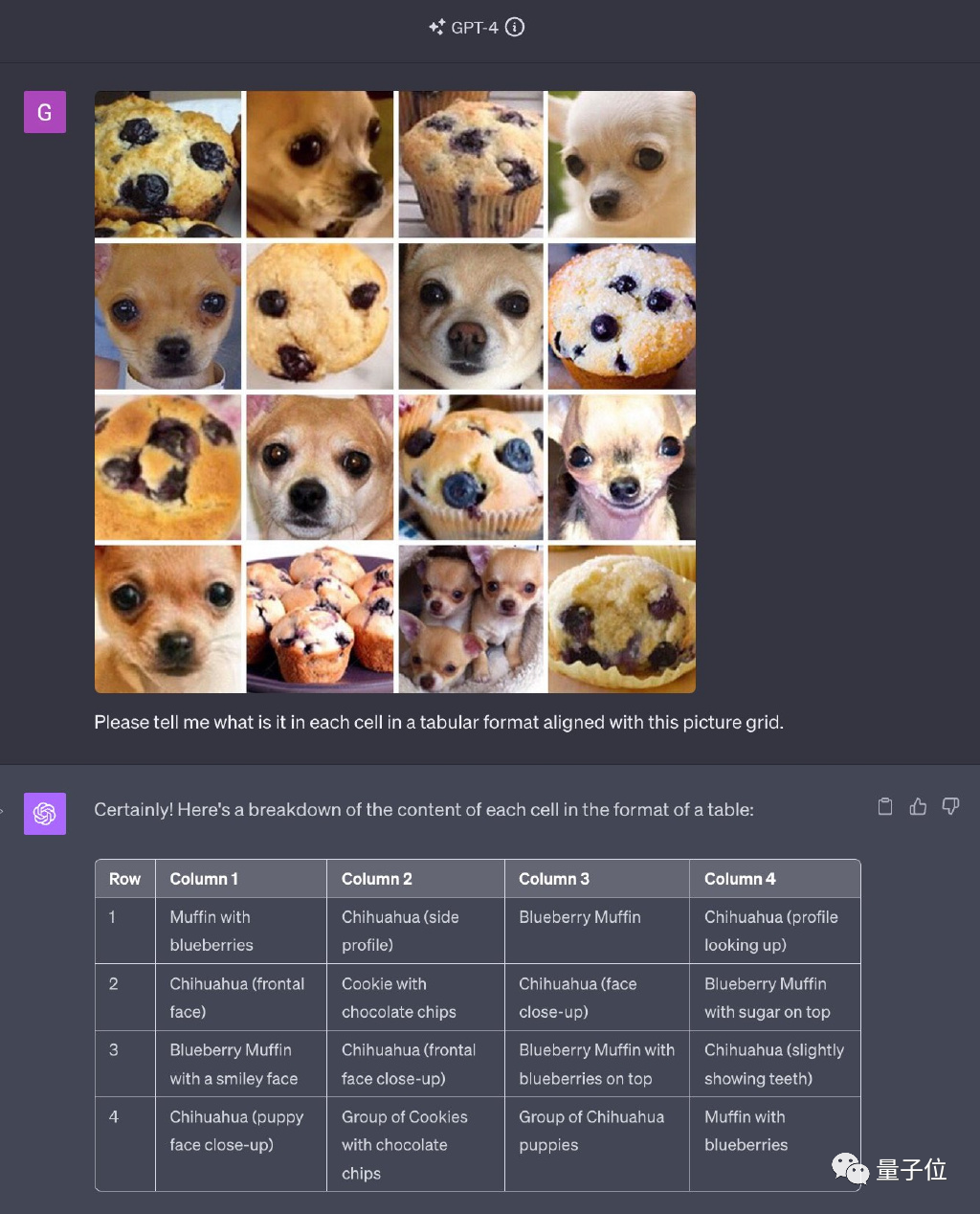
GPT-4解決網路名梗“吉娃娃or藍莓鬆餅”,一度驚艷無數人。
然而,如今它被指控為「作弊」!
 圖片
圖片
全用原題中出現的圖,只是打亂順序和排列方式。
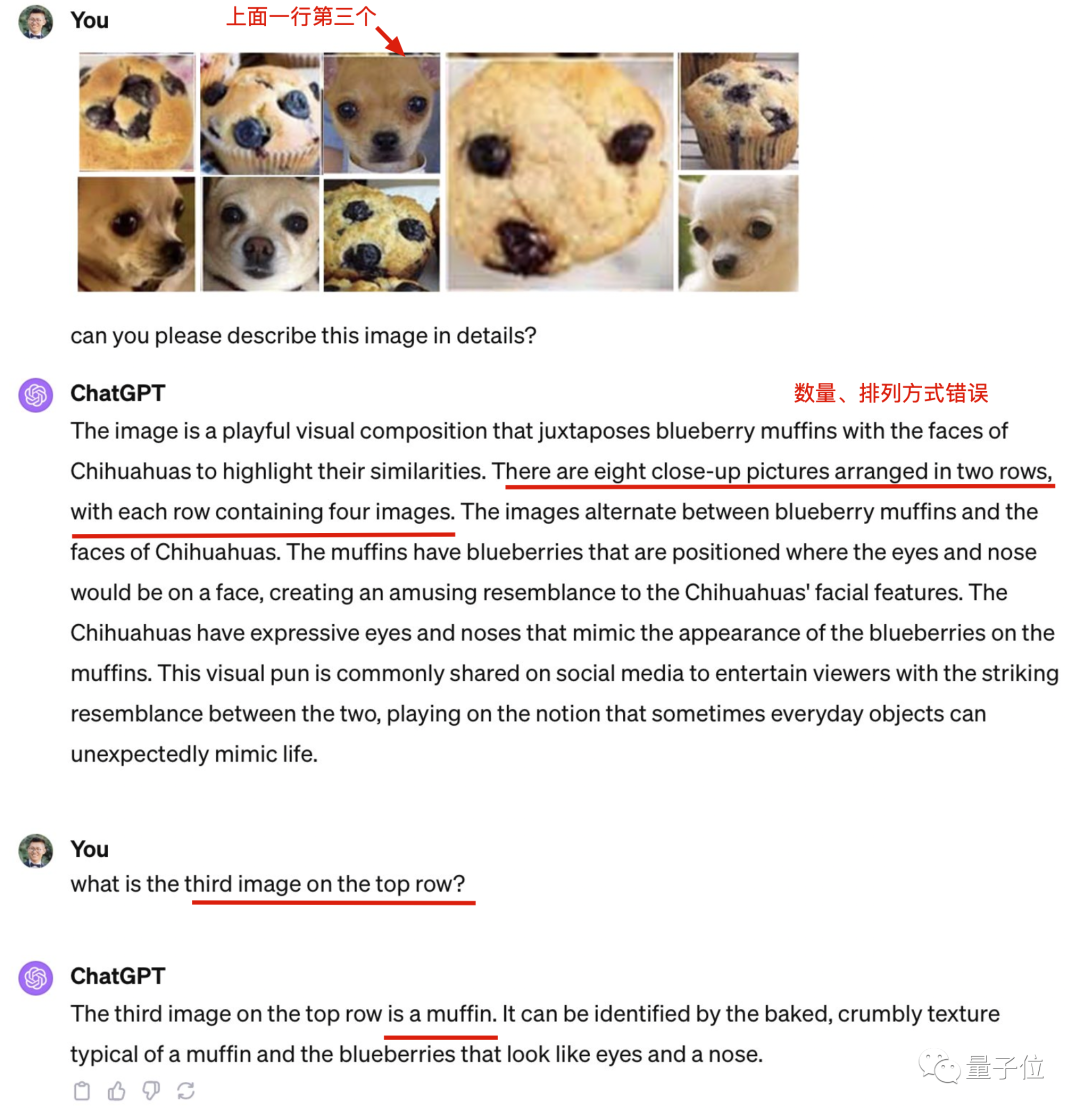
最新版本的GPT-4以其全模式合一的特色而聞名。然而,令人驚訝的是,它在識別圖片數量方面出現了錯誤,而且連原本能夠正確識別的吉娃娃也出現了識別錯誤
 ##圖片
##圖片
警惕在訓練集上測試。
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 #圖片
#圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
視覺幻覺成熱門方向
大模型「胡說八道」在學術界被稱為幻覺問題,多模態大模型的視覺幻覺問題,已經成了最近研究的熱門方向。
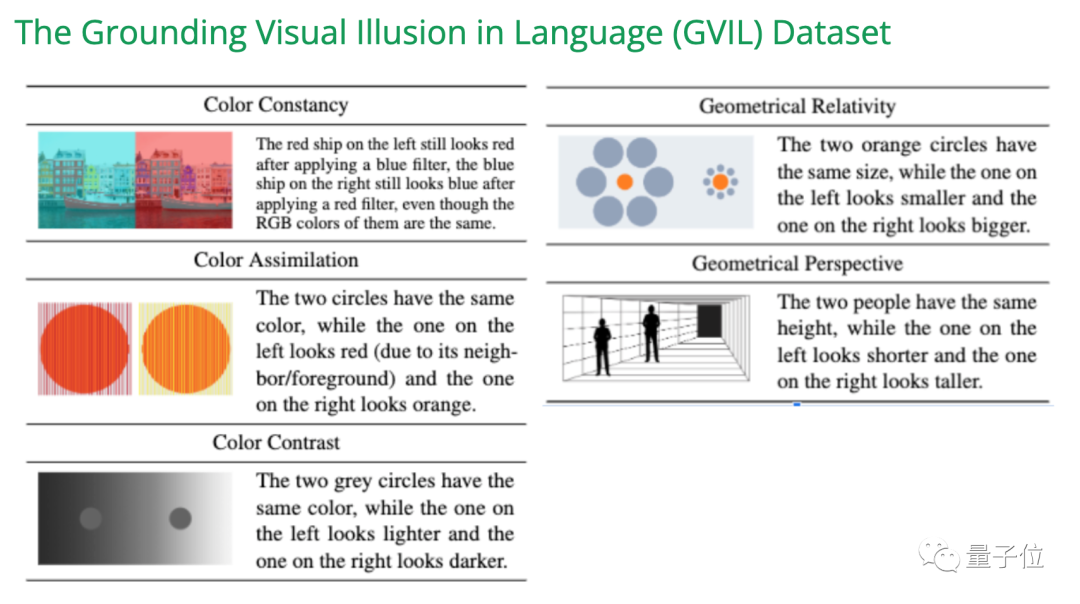
在EMNLP 2023的一項研究中,我們創建了GVIL資料集,其中包含了1600個資料點,並對視覺幻覺問題進行了系統評估
 #圖片
#圖片
研究表明,較大規模的模型更容易受到錯覺的影響,並且更接近人類的感知
 圖片
圖片
#另一項最新研究的重點是評估兩種幻覺類型:偏差和乾擾
 #圖片
#圖片
- 偏差指模型傾向於產生某些類型的反應,可能是由於訓練資料的不平衡所造成的。
- 幹擾則是可能因文字提示的措詞方式或輸入圖像的呈現方式造成去別的場景。
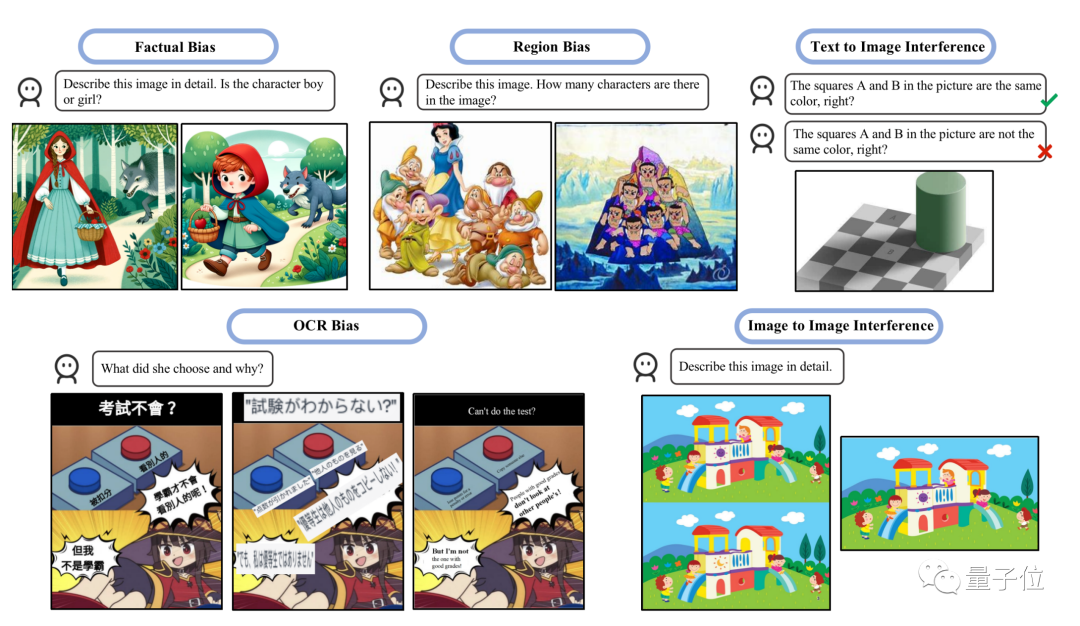 圖片
圖片
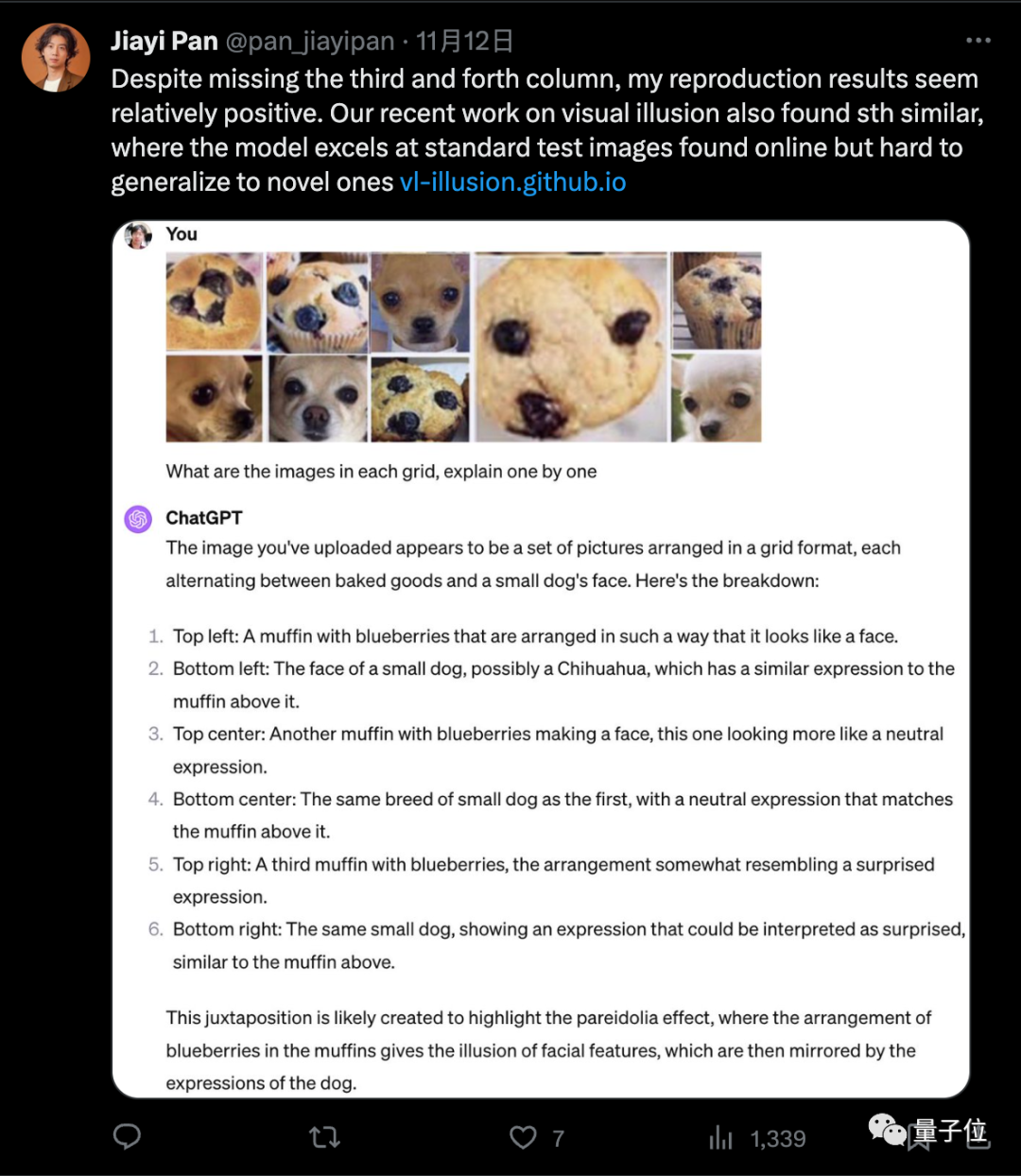
研究中指出GPT-4V一起解釋多個影像時經常會困惑,單獨發送影像時表現較好,符合“吉娃娃or鬆餅”測試中的觀察結果。
 圖片
圖片
流行的緩解措施,如自我糾正和思維鏈提示,並不能有效解決這些問題,並且測試顯示LLaVA和Bard等多模態模型也存在類似的問題
另外研究也發現,GPT-4V更擅長解釋西方文化背景的圖像或帶有英文文字的圖像。
例如GPT-4V能正確數出七個小矮人 白雪公主,卻把七個葫蘆娃數成了10個。
 圖片
圖片
參考連結:[1]https://twitter.com/xwang_lk/status/1723389615254774122[2]https://arxiv. org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287
以上是GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤
Nov 13, 2023 pm 08:17 PM
GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤
Nov 13, 2023 pm 08:17 PM
GPT-4解決網路名梗“吉娃娃or藍莓鬆餅”,一度驚艷無數人。然而,如今它被指控為“作弊”!圖片全用原題中出現的圖,只是打亂順序和排列方式。最新版本的GPT-4以其全模式合一的特點而聞名。然而,令人驚訝的是,它在識別圖片數量方面出現了錯誤,而且連原本能夠正確識別的吉娃娃也出現了識別錯誤圖片GPT-4在原圖上表現出色的原因是什麼呢?根據UCSC助理教授XinEricWang的猜測,搞這項測試的原因是因為網路上的原圖太受歡迎了。他認為GPT-4在訓練過程中多次遇到原始答案,並成功地記住了它們圖靈
 介紹八種免費開源的大模型解決方案,因為ChatGPT和Bard價格太高。
May 08, 2023 pm 10:13 PM
介紹八種免費開源的大模型解決方案,因為ChatGPT和Bard價格太高。
May 08, 2023 pm 10:13 PM
1.LLaMALLaMA專案包含了一組基礎語言模型,其規模從70億到650億個參數不等。這些模型在數以百萬計的token上進行訓練,而且它完全在公開的資料集上進行訓練。結果,LLaMA-13B超過了GPT-3(175B),而LLaMA-65B的表現與Chinchilla-70B和PaLM-540B等最佳模型相似。圖片來自LLaMA資源:研究論文:「LLaMA:OpenandEfficientFoundationLanguageModels(arxiv.org)」[https://arxiv.or
 UC伯克利成功發展通用視覺推理大模型,三位資深學者合力參與研究
Dec 04, 2023 pm 06:25 PM
UC伯克利成功發展通用視覺推理大模型,三位資深學者合力參與研究
Dec 04, 2023 pm 06:25 PM
僅靠視覺(像素)模型能走多遠? UC伯克利、約翰霍普金斯大學的新論文探討了這個問題,並展示了大型視覺模型(LVM)在多種CV任務上的應用潛力。最近一段時間以來,GPT和LLaMA等大型語言模型(LLM)已經風靡全球。建構大型視覺模型(LVM)是一個備受關注的問題,我們需要什麼來實現它? LLaVA等視覺語言模型所提供的想法很有趣,也值得探索,但根據動物界的規律,我們已經知道視覺能力和語言能力二者並不相關。例如許多實驗都表明,非人類靈長類動物的視覺世界與人類的視覺世界非常相似,儘管它們和人類的語言體
 清華浙大主導開源視覺模型爆炸, GPT-4V與LLaVA、CogAgent等平台帶來革命性變革
Jan 04, 2024 am 08:10 AM
清華浙大主導開源視覺模型爆炸, GPT-4V與LLaVA、CogAgent等平台帶來革命性變革
Jan 04, 2024 am 08:10 AM
目前,GPT-4Vision在語言理解和視覺處理方面顯示出了令人驚嘆的能力。然而,對於那些希望在不影響效能的情況下尋求成本效益替代方案的人來說,開源方案是一個具有無限潛力的選擇。 YoussefHosni是一位國外開發者,他為我們提供了三種可訪問性絕對保障的開源替代方案來取代GPT-4V。三種開源視覺語言模型LLaVa、CogAgent和BakLLaVA在視覺處理領域擁有巨大潛力,值得我們深入了解。這些模型的研究和開發,可以為我們提供更有效率、精準的視覺處理解決方案。透過運用這些模型,我們可以提升圖
 GPT-4不服被Bard反超:最新模型已入場
Feb 01, 2024 pm 05:39 PM
GPT-4不服被Bard反超:最新模型已入場
Feb 01, 2024 pm 05:39 PM
「大模型排位賽」權威榜單ChatbotArena刷新:GoogleBard超越GPT-4,排名位居第二,僅次於GPT-4Turbo。然鵝,眾多網友對此表示「不服」、「不公平」。原來,GoogleAI掌門人JeffDean透露,Bard效能大幅提升,是因為搭載了新版大模型-GeminiPro-scale。這也就意味著,打「排位賽」的Bard具備了連網功能。網友的質疑正是圍繞著這一點:在同一個排行榜上混合線上與離線大模型,是極易引起誤解的。 HuggingFace的「首席羊駝官」OmarSanseviero也

 連葫蘆娃都數不明白,解說英雄聯盟的GPT-4V面臨幻覺挑戰
Nov 13, 2023 pm 09:21 PM
連葫蘆娃都數不明白,解說英雄聯盟的GPT-4V面臨幻覺挑戰
Nov 13, 2023 pm 09:21 PM
讓大模型同時理解圖像和文字可能比想像中還要難。在被稱為「AI春晚」的OpenAI首屆開發者大會拉開序幕幕後,許多人的朋友圈都被這家公司發布的新產品刷了屏,比如不需要寫代碼就能定制應用的GPTs、能解說球賽甚至「英雄聯盟」遊戲的GPT-4視覺API等等。不過,在大家紛紛誇讚這些產品有多好用的時候,也有人發現了弱點,指出像GPT-4V這樣強大的多模態模型其實還存在很大的幻覺,在基本的視覺能力上也還存在缺陷,例如分不清「鬆糕和吉娃娃」、「泰迪犬和炸雞」等相似圖像。 GPT-4V分不清鬆糕和吉娃娃。圖源:Xi
 ChatGPT vs Google Bard (2023): 深度比較
Jun 08, 2023 pm 05:10 PM
ChatGPT vs Google Bard (2023): 深度比較
Jun 08, 2023 pm 05:10 PM
ChatGPT和GoogleBard都是人工智慧聊天機器人,旨在對用戶輸入的提示產生回應。如果使用得當,ChatGPT和GoogleBard都可以用來支援部分內容生產、開發等方面的業務流程。閱讀本文,了解每種工具的功能、優點和缺點,看看哪種最適合您的業務。 ChatGPT是什麼? ChatGPT是一個由OpenAI開發的人工智慧聊天機器人,能夠基於用戶輸入的文字產生類似人類的回答,目前已在大量大語言模型上進行了訓練。 GoogleBard是什麼? GoogleBard也是人工智慧聊天機器人。與ChatG
