

利潤預測不再困難,scikit-learn線性迴歸法讓你事半功倍

1、簡介
生成式人工智慧無疑是一個改變遊戲規則的技術,但對於大多數商業問題來說,回歸和分類等傳統的機器學習模型仍然是首選。
重寫後的內容:設想一下私募股權或創投等投資者如何利用機器學習。要回答這個問題,首先需要了解投資人關注的數據以及數據的使用方式。投資公司的決策不僅基於可量化的數據,例如支出、成長和燒錢率等,還包括創辦人的記錄、客戶回饋和產品體驗等定性數據
本文將介紹線性回歸的基礎知識,可以在這裡找到完整的程式碼。
需要重寫的內容是:【程式碼】:https://github.com/RoyiHD/linear-regression
2、專案設定
本文將使用Jupyter Notebook進行這個專案。首先導入一些庫。
匯入庫
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3、資料
為了簡化問題,本文將使用區域資料。這些數據代表了公司的支出類別和利潤。可以看到一些不同數據點的範例。本文希望使用支出資料來訓練一個線性迴歸模型並預測利潤。
重要的是要理解本文所描述的數據是關於一家公司的支出情況。只有當將支出數據與收入成長、當地稅收、攤銷和市場狀況等數據結合時,才能得出有意義的預測能力
R&D Spend |
#行政管理 |
# #Marketing |
投資收益 |
| #需要重寫的內容是:165349.2 |
136897.8 |
#需要重寫的內容是:471784.1 |
#需要改寫的內容是:192261.83 |
| #162597.7 |
#需要被重寫的內容是:151377.59 |
443898.53 |
|
153441.51 |
101145.55 |
加载数据
companies: DataFrame = pd.read_csv("companies.csv", header = 0)4、数据可视化
了解数据对于确定要使用的特征、需要进行归一化和转换的特征、从数据中删除异常值以及对特定数据点进行的处理是很重要的。
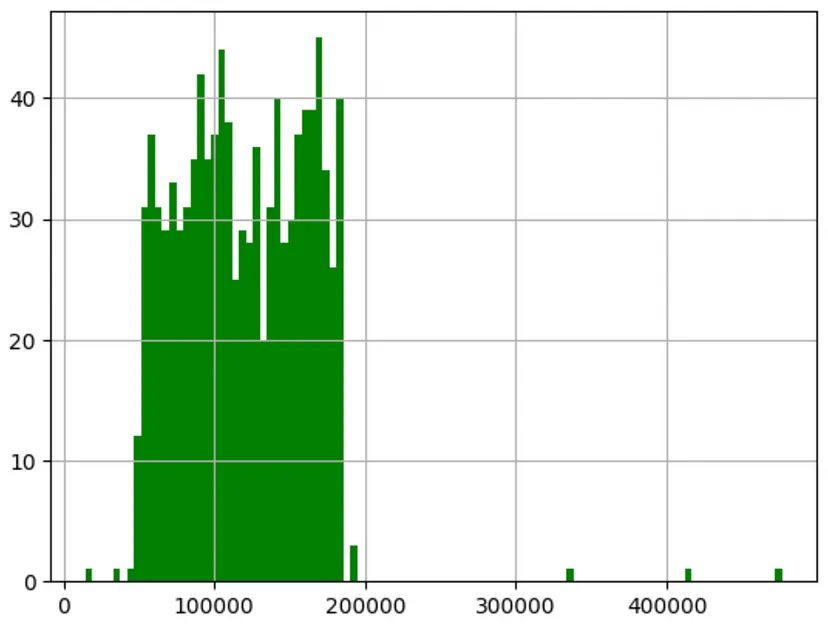
目标(利润)直方图
可以直接使用DataFrame绘制直方图(Pandas使用Matplotlib来绘制数据帧),可以直接访问利润并绘制它。
companies['Profit'].hist( color='g', bins=100);
 图片
图片
从数据中可以清楚地看出,利润超过20万美元的异常值非常罕见。这表明本文所涉及的数据代表的是规模较大的公司。鉴于异常值数量较少,可以将其保留
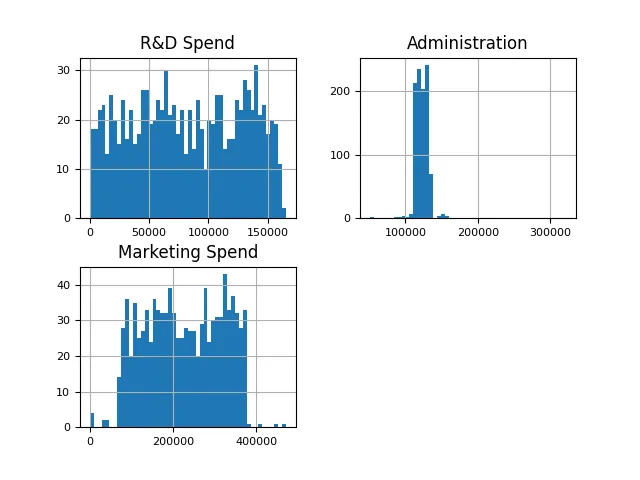
特征(支出)直方图
在这里,本文旨在使用特征的直方图,并观察其分布情况。Y轴表示数字频率,X轴表示支出
companies[["R&D Spend", "行政管理", "Marketing Spend"]].hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8)
 图片
图片
可以观察到一个健康的分布,只有很少的异常值。根据直觉,可以预期投入更多资金在研发和市场营销上的公司会获得更高的利润。从下面的散点图中可以看出,研发支出和利润之间存在明显的相关性
profits: DataFrame = companies[["Profit"]]research_and_development_spending: DataFrame = companies[["R&D Spend"]]figure, ax = plt.subplots(figsize = (9, 9))plt.xlabel("R&D Spending")plt.ylabel("Profits")ax.scatter(research_and_development_spending, profits, s=60, alpha=0.7, edgecolors="k",color='g',linewidths=0.5)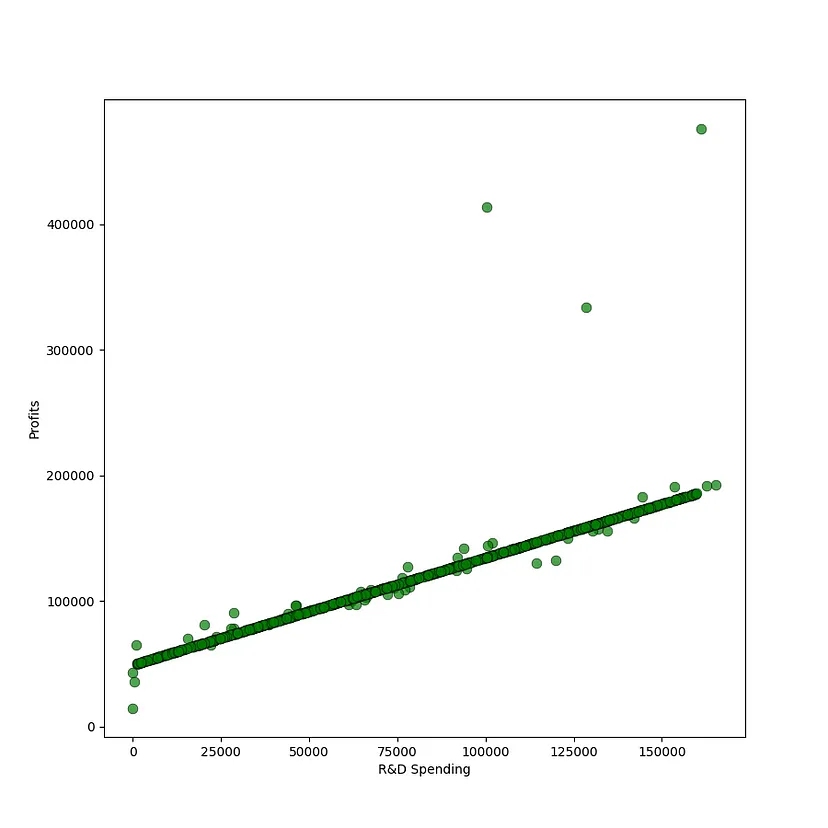 图片
图片
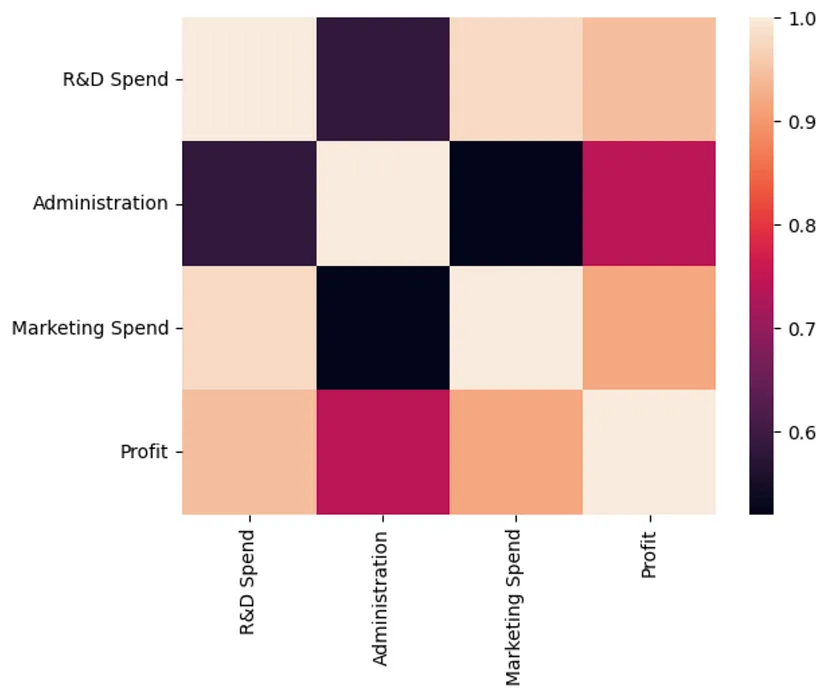
可以使用相关的热图来进一步探索支出和利润之间的关系。从图中可以观察到研发和市场营销支出与利润之间的相关性比行政支出更高
sns.heatmap(companies.corr())
 图片
图片
5、模型训练
首先需要将数据集分割为训练集和测试集两部分。Sklearn提供了一个辅助方法来完成这个任务。鉴于本文的数据集很简单且足够小,可以按照以下方式将特征和目标分离开来。
数据集
features: DataFrame = companies[["R&D Spend", "行政管理", "Marketing Spend",]]targets: DataFrame = companies[["Profit"]]train_features, test_features, train_targets, test_targets = train_test_split(features, targets,test_size=0.2)
大多数数据科学家会使用不同的命名约定,如X_train、y_train或其他类似的变体。
模型训练
现在可以创建并训练模型了。Sklearn使事情变得非常简单。
model: LinearRegression = LinearRegression()model.fit(train_features, train_targets)
6、模型评估
本文希望对模型的性能及其可用性进行评估。首先查看一下计算得到的系数。在机器学习中,系数是用来与每个特征相乘的学习到的权重或数值。期望看到每个特征都有一个学习系数。
coefficients = model.coef_"""We should see the following in our consoleCoefficients[[0.55664299 1.08398919 0.07529883]]"""
正如上述所看到的,有3个系数,每个特征对应一个系数(“研发支出”、“行政支出”、“市场营销支出”)。还可以将其绘制成图表,以便更直观地了解每个系数。
plt.figure()plt.barh(train_features.columns, coefficients[0])plt.show()
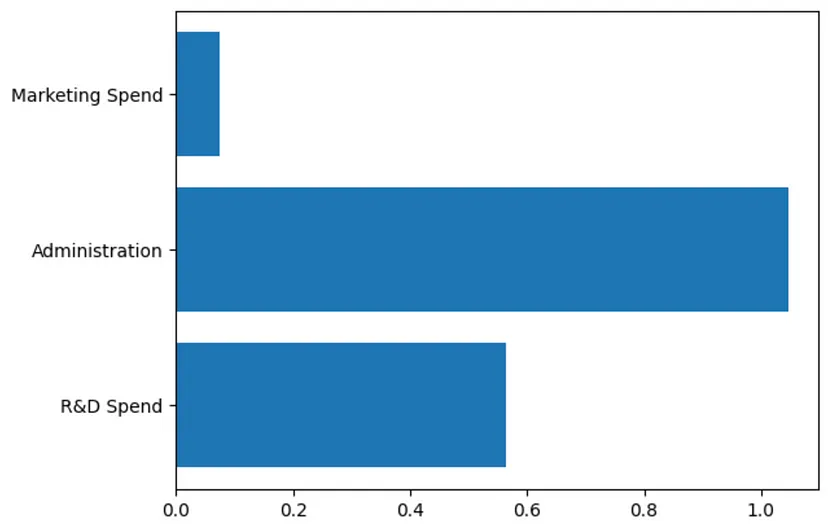 图片
图片
计算误差
希望了解模型的误差率,我们将使用Sklearn的R2得分
test_predictions: List[float] = model.predict(test_features)root_squared_error: float = r2_score(test_targets, test_predictions)"""floatWe should see an ouput similar to this0.9781424529214315"""
离1越近,模型就越准确。实际上可以用一种非常简单的方式对这一点进行测试。
使用下面的支出模型来预测利润,并希望得到一个接近192261美元的数字,可以提取数据集的第一行
"R&D Spend" |"行政管理" |"Marketing Spend" | "Profit"需要进行重写的内容是:165349.2 136897.8需要重写的内容是:471784.1需要改写的内容是:192261.83
接下来创建一个推理请求。
inference_request: DataFrame = pd.DataFrame([{"R&D Spend":需要进行重写的内容是:165349.2, "行政管理":136897.8, "Marketing Spend":需要重写的内容是:471784.1 }])运行模型。
inference: float = model.predict(inference_request)"""We should get a number that is around199739.88721901"""
现在可以看到的误差率是abs(199739-192261)/192261=0.0388。这是非常准确的。
7、结论
处理数据、搭建模型和分析数据有很多方法。没有一种解决方案适用于所有情况,当用机器学习解决业务问题时,其中一个关键过程是搭建多个旨在解决同一个问题的模型,并选择最有前途的模型
以上是利潤預測不再困難,scikit-learn線性迴歸法讓你事半功倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 我嘗試了使用光標AI編碼的Vibe編碼,這太神奇了!
Mar 20, 2025 pm 03:34 PM
我嘗試了使用光標AI編碼的Vibe編碼,這太神奇了!
Mar 20, 2025 pm 03:34 PM
Vibe編碼通過讓我們使用自然語言而不是無盡的代碼行創建應用程序來重塑軟件開發的世界。受Andrej Karpathy等有遠見的人的啟發,這種創新的方法使Dev
 2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月,Generative AI又是一個改變遊戲規則的月份,為我們帶來了一些最令人期待的模型升級和開創性的新功能。從Xai的Grok 3和Anthropic的Claude 3.7十四行詩到Openai的G
 如何使用Yolo V12進行對象檢測?
Mar 22, 2025 am 11:07 AM
如何使用Yolo V12進行對象檢測?
Mar 22, 2025 am 11:07 AM
Yolo(您只看一次)一直是領先的實時對象檢測框架,每次迭代都在以前的版本上改善。最新版本Yolo V12引入了進步,可顯著提高準確性
 Chatgpt 4 o可用嗎?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用嗎?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4當前可用並廣泛使用,與諸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和產生連貫的響應方面取得了重大改進。未來的發展可能包括更多個性化的間
 最佳AI藝術生成器(免費付款)創意項目
Apr 02, 2025 pm 06:10 PM
最佳AI藝術生成器(免費付款)創意項目
Apr 02, 2025 pm 06:10 PM
本文回顧了AI最高的藝術生成器,討論了他們的功能,對創意項目的適用性和價值。它重點介紹了Midjourney是專業人士的最佳價值,並建議使用Dall-E 2進行高質量的可定製藝術。
 Google的Gencast:Gencast Mini Demo的天氣預報
Mar 16, 2025 pm 01:46 PM
Google的Gencast:Gencast Mini Demo的天氣預報
Mar 16, 2025 pm 01:46 PM
Google DeepMind的Gencast:天氣預報的革命性AI 天氣預報經歷了巨大的轉變,從基本觀察到復雜的AI驅動預測。 Google DeepMind的Gencast,開創性
 哪個AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
哪個AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
本文討論了AI模型超過Chatgpt,例如Lamda,Llama和Grok,突出了它們在準確性,理解和行業影響方面的優勢。(159個字符)
 O1 vs GPT-4O:OpenAI的新型號比GPT-4O好嗎?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O:OpenAI的新型號比GPT-4O好嗎?
Mar 16, 2025 am 11:47 AM
Openai的O1:為期12天的禮物狂歡始於他們迄今為止最強大的模型 12月的到來帶來了全球放緩,世界某些地區的雪花放緩,但Openai才剛剛開始。 山姆·奧特曼(Sam Altman)和他的團隊正在推出12天的禮物前
