
人工智慧發展進步神速,但問題頻出。 OpenAI 新出的 GPT 視覺 API 前腳讓人感嘆效果極佳,後腳又因幻覺問題令人不禁吐槽。
幻覺一直是大模型的致命缺陷。由於資料集龐雜,其中難免會有過時、錯誤的訊息,導致輸出品質面臨嚴峻的考驗。過度重複的資訊也會使大模型形成偏見,這也是幻覺的一種。但是幻覺並非無解命題。開發過程中對資料集慎重使用、嚴格過濾,建構高品質資料集,以及最佳化模型結構、訓練方式都能在一定程度上緩解幻覺問題。
有這麼多流行的大型模型,它們對緩解幻覺的效果如何?這裡有一個明確對比它們差距的排行榜
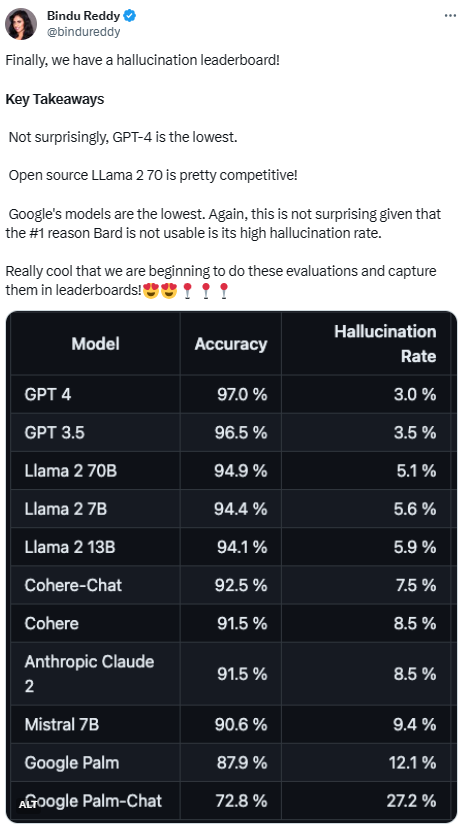
#Vectara 平台發布了這個排行榜,該平台專注於人工智能。排行榜的更新日期是2023年11月1日,Vectara 表示他們將會繼續跟進幻覺評估,以便隨著模型的更新而更新排行榜
計畫地址:https ://github.com/vectara/hallucination-leaderboard
#為了確定這個排行榜,Vectara進行了事實一致性研究,並訓練了一個模型來偵測LLM輸出中的幻覺。他們使用了一個媲美SOTA模型,並透過公共API向每個LLM提供了1000篇簡短文檔,並要求它們僅使用文檔中呈現的事實對每篇文檔進行總結。在這1000篇文件中,只有831篇文件被每個模型總結,其餘文檔由於內容限制被至少一個模型拒絕回答。利用這831份文件,Vectara計算了每個模型的整體準確率和幻覺率。每個模型拒絕響應prompt的比率詳見「Answer Rate」一欄。發送給模型的內容都不包含非法或不安全內容,但其中的觸發詞足以觸發某些內容過濾器。這些文件主要來自CNN/每日郵報語料庫
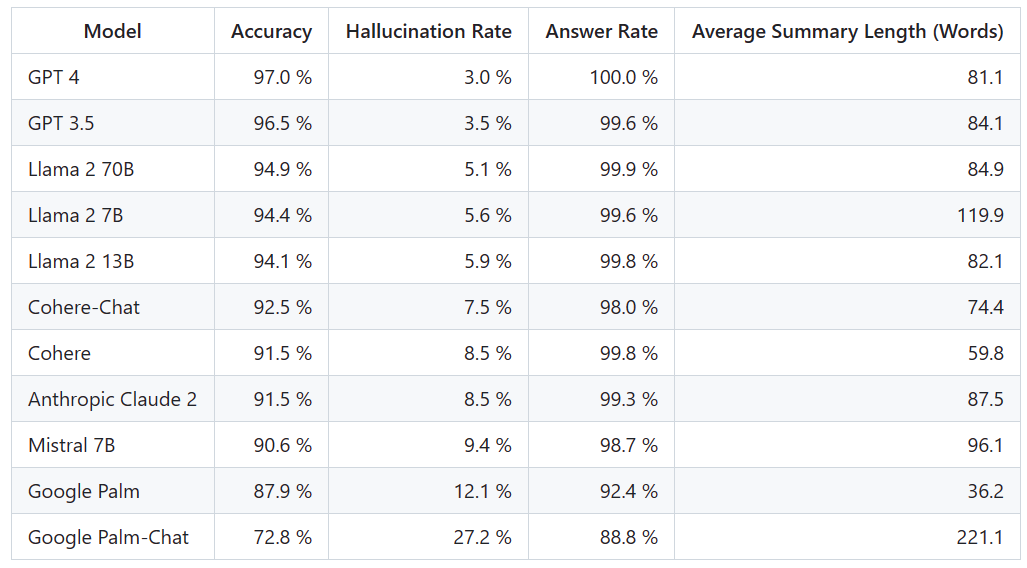
#需要注意的是,Vectara 評估的是摘要準確性,而不是整體事實準確性。這樣可以比較模型對所提供資訊的反應。換句話說,評估的是輸出摘要是否與原始檔案「事實一致」。由於不知道每個 LLM 是在什麼資料上訓練的,因此對於任何特別問題來說,確定幻覺都是不可能的。此外,要建立一個能夠在沒有參考來源的情況下確定回答是否為幻覺的模型,就需要解決幻覺問題,而且需要訓練一個與被評估的 LLM 一樣大或更大的模型。因此,Vectara 選擇在總結任務中查看幻覺率,因為這樣的類比可以很好地確定模型整體真實性。
幻覺模型的偵測位址是:https://huggingface.co/vectara/hallucination_evaluation_model
##此外,越來越多的LLM被用於RAG(Retrieval Augmented Generation,檢索增強生成)管道以回答用戶的查詢,如Bing Chat和谷歌聊天整合。在RAG系統中,模型被部署為搜尋結果的匯總器,因此該排行榜也是衡量模型在RAG系統中使用時準確性的良好指標
鑑於GPT-4一直以來的出色表現,它的幻覺率最低似乎不足為奇。然而,一些網友表示,他們對於GPT-3.5和GPT-4之間並沒有太大的差距感到驚訝

#在追趕GPT- 4和GPT-3.5之後,LLaMA 2表現出色。然而,谷歌的大型模型表現讓人不滿意。一些網友表示,Google的BARD常常用「我還在訓練中」來迴避其錯誤答案

#有了這樣的排行榜,能夠讓我們對於不同模型之間的優劣有更直觀的判斷。前幾天,OpenAI 推出了 GPT-4 Turbo,這不,立刻有網友提議將其也更新在排行榜中。

下次的排行榜會是怎樣的,有沒有大幅變動,我們拭目以待。
以上是大模型幻覺率排行:GPT-4 3%最低,GooglePalm竟然高達27.2%的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















