
數學,作為科學的基石,一直以來都是研究和創新的關鍵領域。
最近,普林斯頓大學等七家機構聯合發布了一個專門用於數學的大語言模型LLEMMA,性能媲美谷歌Minerva 62B,並公開了其模型、數據集和代碼,為數學研究帶來了前所未有的機會和資源。

論文網址:https://arxiv.org/abs/2310.10631
資料集的連結網址為:https://huggingface.co/datasets/EleutherAI/proof-pile-2
專案網址:https://github.com/EleutherAI/math-lm 需要重寫的是:
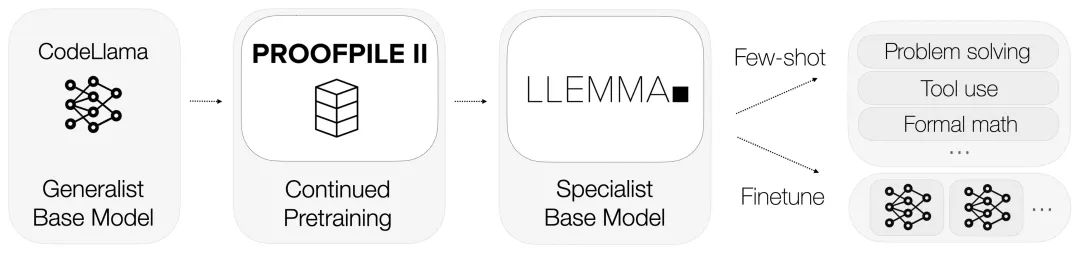
LLEMMA承襲了Code Llama的基礎,在Proof-Pile-2上進行了預訓練。
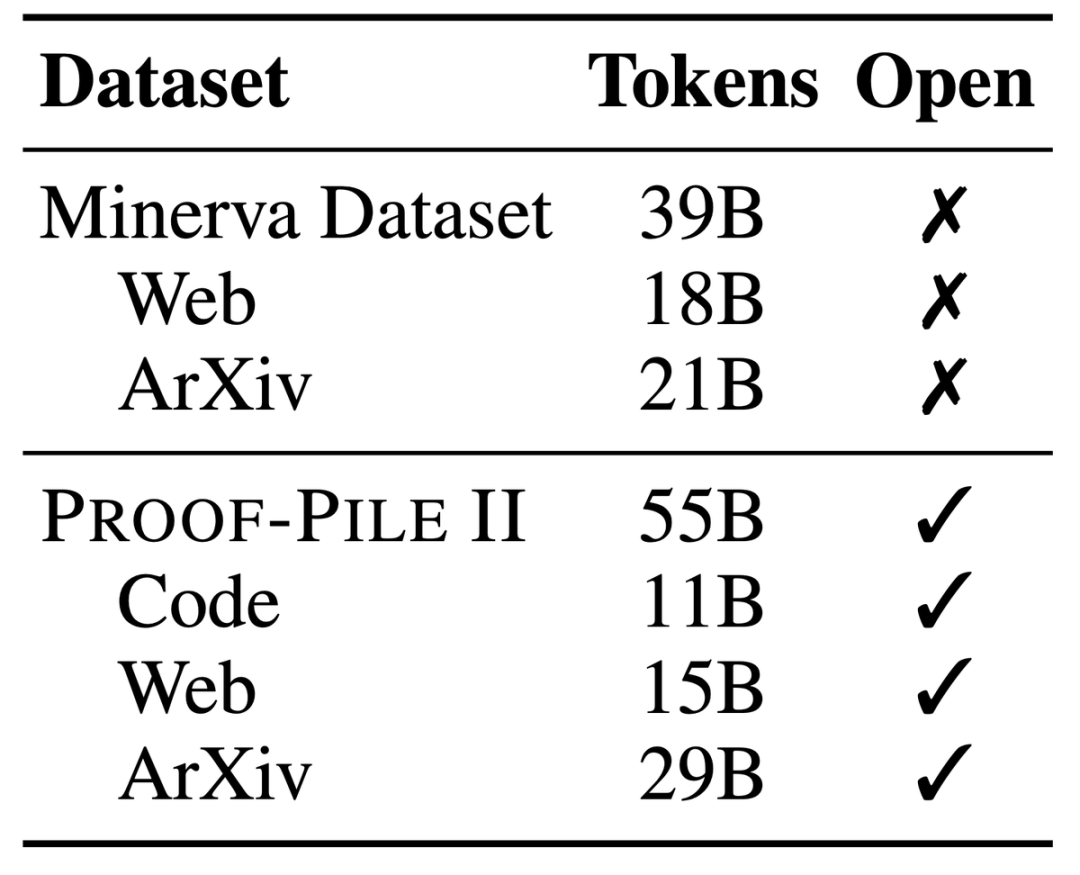
Proof-Pile-2,一個龐大的混合資料集,包含著550億token的訊息,其中包括科學論文、富含數學內容的網頁資料以及數學程式碼。
這個資料集的一部分,Algebraic Stack,更匯集了來自17種語言的11B資料集,涵蓋了數值、符號和數學證明。
擁有7億和34億個參數,在MATH基準測試中表現卓越,超越了所有已知的開源基礎模型。
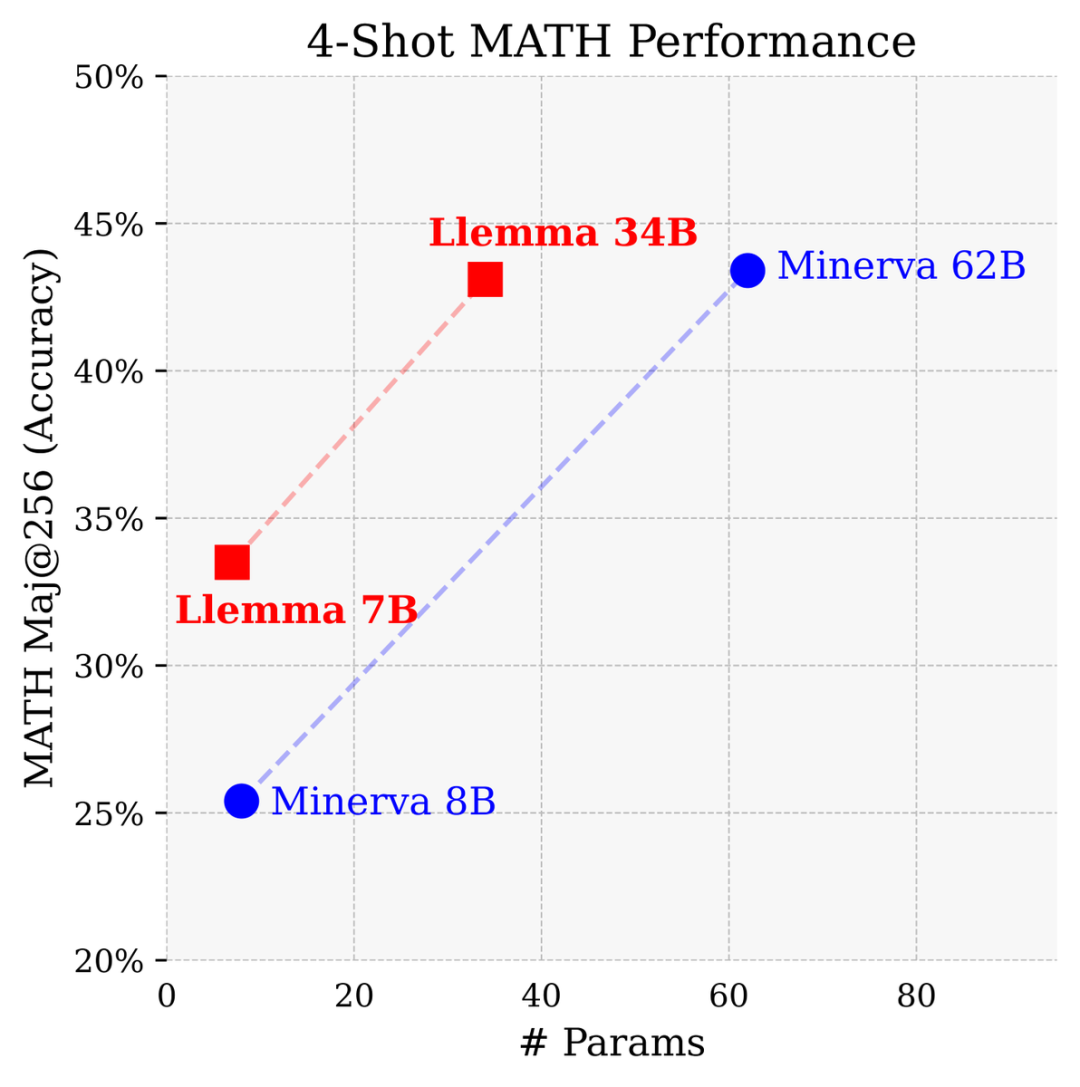
在與Google Research開發的專門用於數學的封閉模型相比,參數量只有Minerva 62B一半的條件下,Llemma 34B獲得了幾乎相同的性能。
Llemma超越了Minerva在參數基礎上解決問題的效能,它利用計算工具和形式定理證明,為數學問題的解決提供了無限的可能性
它能夠方便地使用Python解釋器和形式證明器,進一步展示了它在解決數學問題方面的能力
由於對形式證明資料的特別重視,Algebraic Stack成為了第一個展現出少樣本定理證明能力的開放基礎模型

 圖
圖
研究人員也開放共享了LLEMMA的所有訓練資料和程式碼。與以往的數學模型不同,LLEMMA是一個開源的、開放共享的模型,為整個科研社群敞開大門。
研究人員試圖量化模型記憶效果,結果令人驚訝的是,他們發現Llemma對於訓練集中出現的問題並沒有變得更加準確。由於程式碼和數據是公開的,研究人員鼓勵其他人複製並擴展他們的分析
LLEMMA是一個專門用於數學的大型語言模型,它在Code Llama的基礎上繼續在Proof-Pile-2上進行預訓練。 Proof-Pile-2是一個包含科學論文、含有數學內容的網頁資料和數學程式碼的混合資料集,包含了550億個標記
AlgebraicStack的程式碼部分包含了11B的資料集,其中包括17種語言原始碼,覆蓋數值、符號和形式數學,並已公開發布
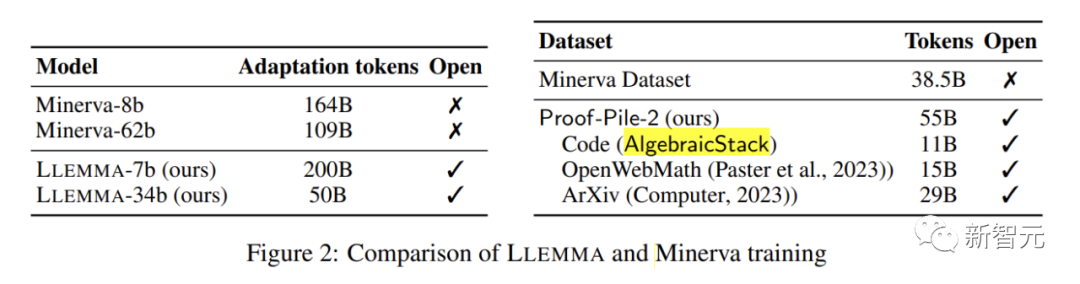
LLEMMA的每個模型都是由Code Llama進行初始化的。 Code Llama模型是僅包含解碼器的語言模型,它是從Llama 2進行初始化的
作者對Code Llama模型在Proof-Pile-2上進行了進一步的訓練,使用標準的自回歸語言建模目標。對於7B模型,作者進行了200B個標記的訓練,而對於34B模型,作者進行了50B個標記的訓練
作者使用Proof-Pile-2對Code Llama進行繼續預訓練,並且在MATH和GSM8k等多個數學問題解決任務上對LLEMMA進行few-shot評估。
研究人員發現LLEMMA在這些任務上都有顯著的提升,並且能夠適應不同的問題類型和難度。
LLEMMA 34B在極高難度的數學問題中展示了比其他開放式基礎模型更強大的數學能力

在數學基準測試上,LLEMMA在Proof-Pile-2上的持續預訓練改善了五個數學基準測試的few-shot性能。
在GSM8k上,LLEMMA 34B的改進比Code Llama高出20個百分點,在MATH上高出13個百分點。而且,LLEMMA 7B也優於相似大小的專有的Minerva模型,證明了在Proof-Pile-2上進行預訓練能有效提高大模型的數學解題能力
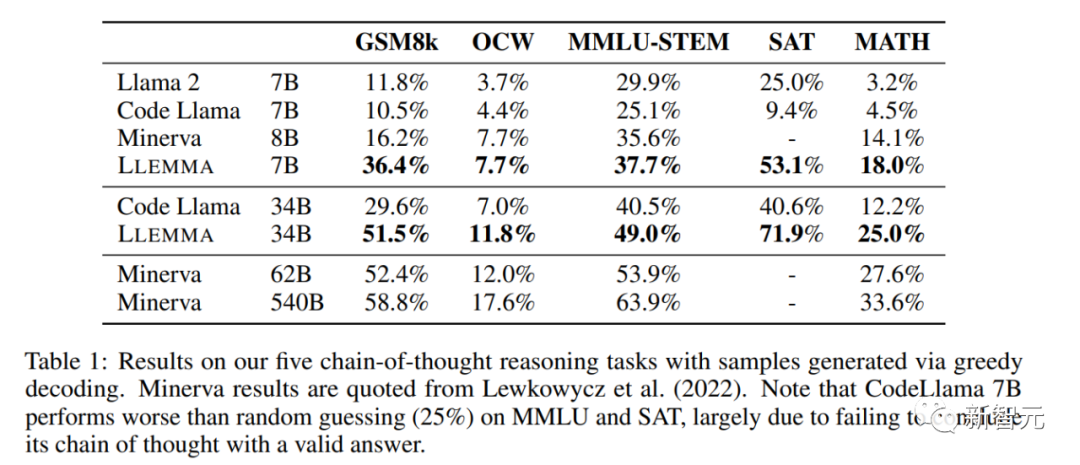
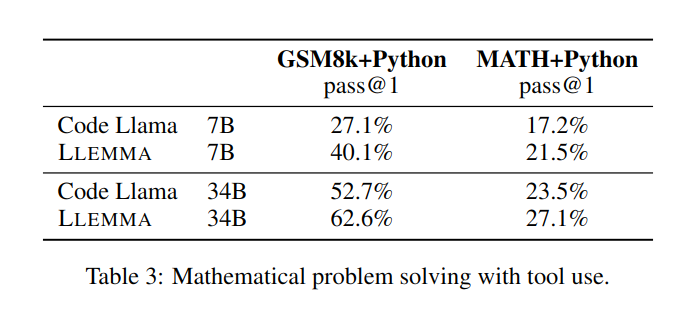
在解決數學問題時,利用計算工具如Python等,LLEMMA在MATH Python和GSM8k Python任務上都比Code Llama更出色
#在使用MATH和GSM8k資料集時,LLEMMA的效能優於沒有使用工具時的效能
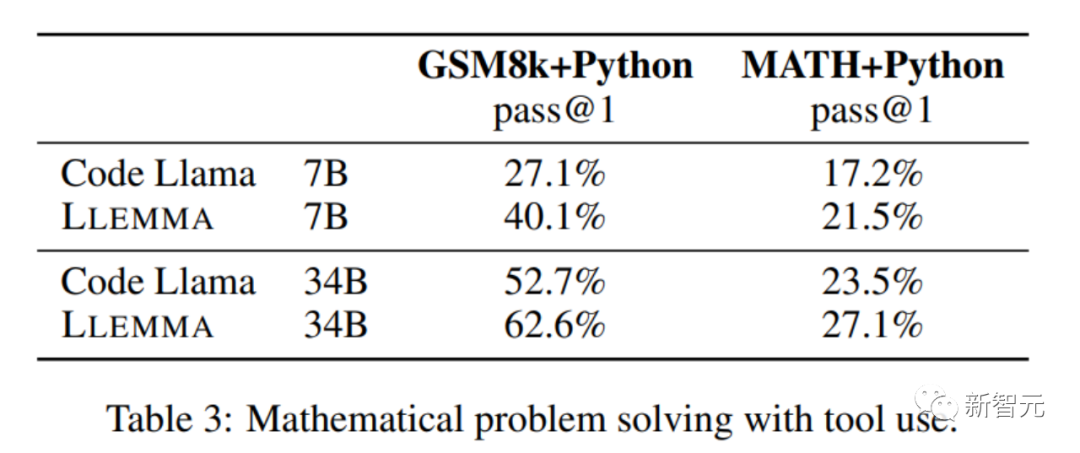
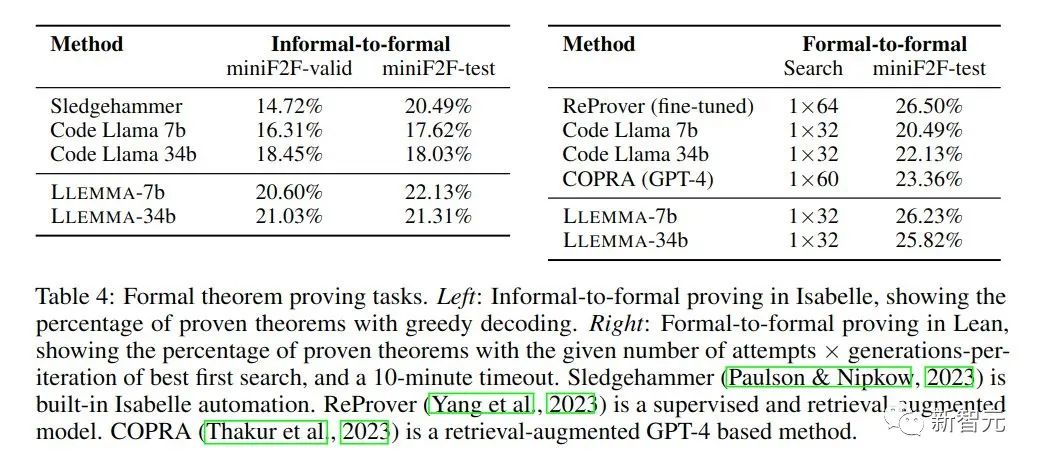
在數學證明任務中,LLEMMA表現出色
非正式到正式證明的任務目標是在給定一個正式陳述、一個非正式的LATEX陳述和一個非正式的LATEX證明的情況下,產生一個正式證明,然後透過證明助手進行驗證。
正式到正式證明則是透過產生一系列證明步驟(策略)來證明一個正式陳述。結果表明,LLEMMA在Proof-Pile-2上的持續預訓練改善了這兩個正式定理證明任務的few-shot表現。
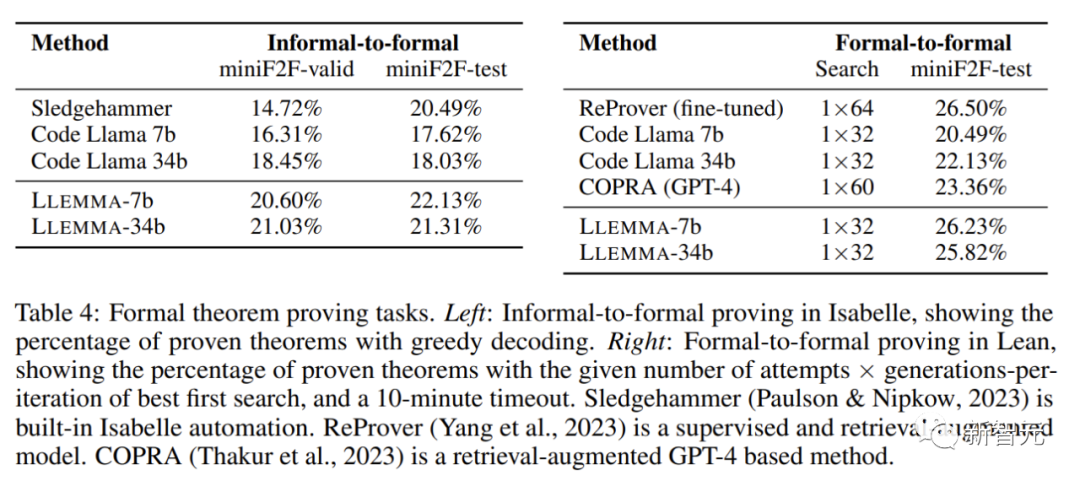
LLEMMA不僅擁有令人矚目的效能、還開放了革命性的資料集、展現了驚人的問題解決能力。
開源共享的精神,標誌著數學界進入了一個新的時代。數學的未來在這裡,而我們每一個數學愛好者、研究者和教育者都將從中受益。
LLEMMA的出現為我們提供了前所未有的工具,讓數學問題的解決變得更有效率和創新。
此外,開放共享的概念也將促進全球科學研究社群更加深入的合作,共同推動科學的進步。
以上是普林斯頓開源34B數學模型:參數減半,效能媲美GoogleMinerva,使用550億Token進行專業資料訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















