

#隨著網路的發展,企業可以獲得越來越多的資料。這些數據有助於企業更了解用戶,即客戶畫像,並可以改善用戶體驗。然而,這些數據中可能存在大量未經標記的數據。如果所有數據都採用人工標記的方法,將會面臨兩個問題。首先,人工標記的時間成本較高,效率低。隨著資料量的增加,需要雇用更多的人員和更長的時間,成本也會更高。其次,隨著使用者規模的增加,很難透過手動標記來跟上資料的成長速度
##半監督學習是指使用既有標籤的資料又有無標籤的資料訓練模型。半監督學習通常會基於有標籤的資料建構屬性空間,再從無標籤的資料中提取有效資訊填充(或重構)屬性空間。因此,通常半監督學習的初始訓練集會劃分為有標籤的資料集D1和無標籤資料集D2,然後透過預處理、特徵提取等基本步驟後訓練半監督學習模型,然後將訓練好的模型用於生產環境,為使用者提供服務。 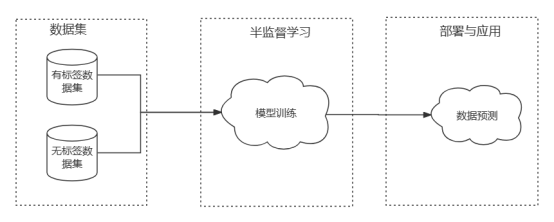
Part 02、半監督學習的假設
為了實現標籤資料有效補充標籤數據中的「有用」信息,對數據分部等方面做出一些假設。半監督學習的基礎假設是p(x)中包含p(y|x)的信息,即無標籤的數據應該包含對於標籤預測有用的且與有標籤的數據不相同的或者很難從有標籤的數據中提取出來的資訊。此外,也存在一些服務於演算法的假設。例如,相似性假設(平滑假設)是指在資料樣本建構的屬性空間中,相近或相似的樣本具有相同的標籤;低密度分離假設是指在資料樣本少的地方存在一個決策邊界能區分不同標籤的數據。
半監督學習演算法分類 半監督學習演算法眾多,可大致分為直推式學習(transductive learning)和 歸納式學習(Inductive model)## ,二者差異在於
用於模型評估的測試資料集的選擇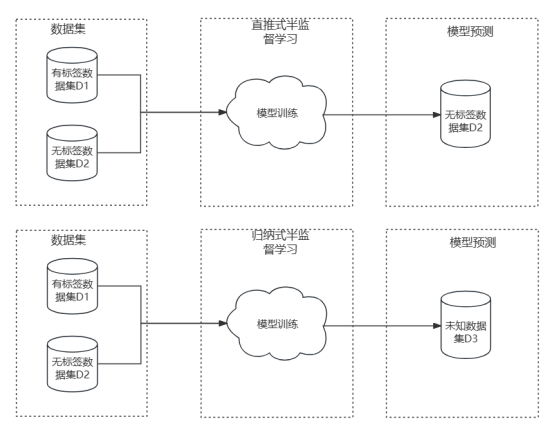
。直推式的半監督學習是指需要預測標籤的資料集就是用於訓練的無標籤資料集,學習的目的是為了進一步提高預測結果的準確性。歸納式學習則是為完全未知的資料集預測標籤。
Part 04、 總結
#半監督學習的最大的問題是在許多情況下,模型的表現依賴有標籤的數據集,並且對於有標籤資料集的品質要求較高,甚至半監督學習模型預測準確度與基於有標籤資料集的有監督模型的結果相差不大,反而半監督模型為了有效提取無標籤資料中的有效訊息,會消耗更多的資源。因此,半監督學習的發展方向是提高演算法的穩健性以及資料擷取的有效性。
############目前在半監督學習領域中,PU-Learning(正負樣本學習)是比較熱門的演算法。這類演算法主要應用於只有正樣本和無標籤資料的資料集。它的優點是在某些場景下,我們能夠相對容易地取得可靠的正樣本資料集,且資料量相對較大。舉例來說,在垃圾郵件偵測中,我們很容易取得大量的正常郵件資料######以上是重新編寫的標題:探究半監督學習的應用領域及其相關場景的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















