

實現高品質影像產生的新一步:GoogleUFOGen極速取樣方法

最近一年來,以 Stable Diffusion 為代表的一系列文生圖擴散模型徹底改變了視覺創作領域。數不清的使用者透過擴散模型產生的圖片提升生產力。但是,擴散模型的生成速度是一個老生常談的問題。因為降噪模型依賴多步驟降噪來逐漸將初始的高斯雜訊變為圖片,因此需要對網路進行多次計算,導致生成速度很慢。 這導致大規模的文生圖擴散模型對一些注重即時性,互動性的應用非常不友善。 隨著一系列技術的提出,從擴散模型中採樣所需的步數已經從最初的幾百步,到幾十步,甚至只需要 4-8 步。
最近,來自Google的研究團隊提出了 UFOGen 模型,一個能極速取樣的擴散模型變體。 透過論文提出的方法對 Stable Diffusion 進行微調,UFOGen 只需要一步就能產生高品質的圖片。同時,Stable Diffusion 的下游應用,比如圖生圖,ControlNet 等能力也能保留。

請點擊以下連結查看論文:https://arxiv.org/abs/2311.09257
從下圖可以看到,UFOGen 只需一步即可產生高質量,多樣的圖片。

#提升擴散模型的生成速度並不是新的研究方向。先前關於這方面的研究主要集中在兩個方向。 一個方向是設計更有效率的數值計算方法,以求能達到利用較少的離散步數求解擴散模型的取樣 ODE 的目的。例如清華的朱軍團隊提出的 DPM 系列數值求解器,被驗證在 Stable Diffusion 上非常有效,能顯著地把求解步數從 DDIM 預設的 50 步降到 20 步以內。 另一個方向是利用知識蒸餾的方法,將模型的基於 ODE 的取樣路徑壓縮到更小的步數。 這個方向的例子是 CVPR2023 最佳論文候選之一的 Guided distillation,以及最近大火的 Latent Consistency Model (LCM)。尤其是 LCM,透過對一致性目標進行蒸餾,能夠將採樣步數降到只需 4 步,由此催生了不少即時生成的應用。
然而,Google的研究團隊在UFOGen 模型中並沒有跟隨以上大方向,而是另闢蹊徑,利用了一年多前提出的擴散模型和GAN 的混合模型思路。 他們認為前面提到的基於 ODE 的採樣和蒸餾有其根本的局限性,很難將採樣步數壓縮到極限。因此想實現一步生成的目標,需要打開新的思路。
混合模型是指結合了擴散模型和生成對抗網路(GAN)的方法。這個方法最早由英偉達的研究團隊在ICLR 2022上提出,被稱為DDGAN(《用去噪擴散GAN解決生成學習三難題》)。 DDGAN的靈感來自於普通擴散模型對降噪分佈進行高斯假設的缺陷。簡單來說,擴散模型假設降噪分佈(給定一個雜訊的樣本,產生一個雜訊較少的樣本的條件分佈)是一個簡單的高斯分佈。然而,隨機微分方程理論證明,這樣的假設只在降噪步長趨近於0時才成立。因此,擴散模型需要大量重複的降噪步驟來確保較小的降噪步長,導致生成速度較慢
DDGAN 提出拋棄降噪分佈的高斯假設,而是用一個有條件的GAN 來模擬這個降噪分佈。因為 GAN 具有極強的表示能力,能模擬複雜的分佈,所以可以取較大的降噪步長來達到減少步數的目的。然而,DDGAN 將擴散模型穩定的重建訓練目標變成了 GAN 的訓練目標,很容易造成訓練不穩定,從而難以延伸到更複雜的任務。在NeurIPS 2023 上,和創造UGOGen 的同樣的谷歌研究團隊提出了SIDDM(論文標題Semi-Implicit Denoising Diffusion Models),將重構目標函數重新引入了DDGAN 的訓練目標,使訓練的穩定性和生成品質都相比於DDGAN 大幅提升。
#SIDDM 身為 UFOGen 的前身,只需要 4 步驟就能在 CIFAR-10, ImageNet 等研究資料集上產生高品質的圖片。但是 SIDDM 有兩個問題需要解決:首先,它無法做到理想狀況的一步產生;其次,將其擴展到更受關注的文生圖領域並不簡單。 為此,Google的研究團隊提出了 UFOGen,解決這兩個問題。
具體來說,對於問題一,透過簡單的數學分析,團隊發現透過改變生成器的參數化方式,以及改變重構損失函數計算的計算方式,理論上模型可以實現一步生成。對於問題二,團隊提出利用現有的 Stable Diffusion 模型進行初始化來讓 UFOGen 模型更快、更好的擴展到文生圖任務。值得注意的是,SIDDM 就已經提出讓生成器和判別器都採用 UNet 架構,因此基於該設計,UFOGen 的生成器和判別器都是由 Stable Diffusion 模型初始化的。這樣做可以最大限度地利用 Stable Diffusion 的內部信息,尤其是關於圖片和文字的關係的信息。這樣的資訊很難透過對抗學習來獲得。訓練演算法和圖示見下。

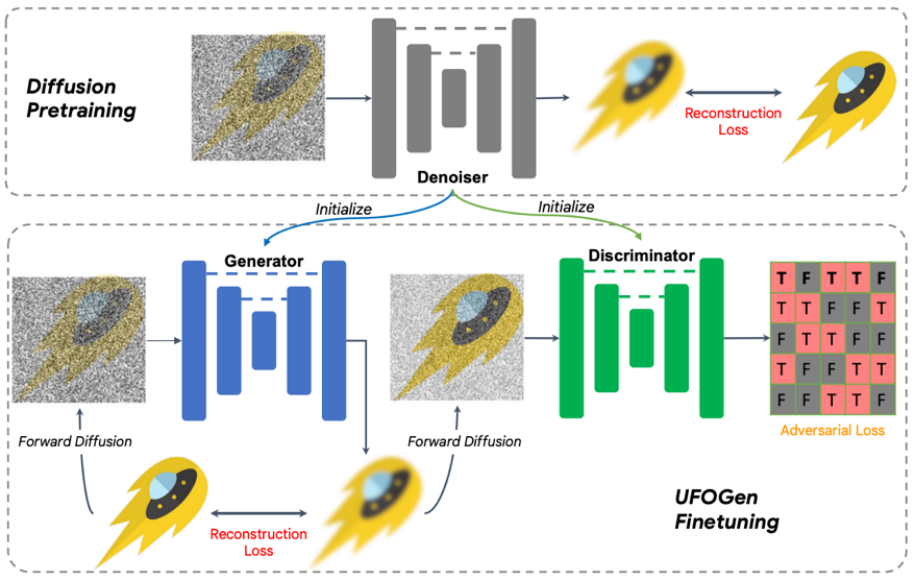
值得注意的是,在這之前也有一些利用GAN 做文生圖的工作,例如英偉達的StyleGAN-T,Adobe 的GigaGAN,都是將StyleGAN 的基本架構擴展到更大的規模,因此也能一步文生圖。 UFOGen 的作者指出,比起先前基於GAN 的工作,除了生成品質外,UFOGen 還有幾點優勢:
重寫後的內容:1. 在文生圖任務中,純粹的生成對抗網路(GAN)訓練非常不穩定。判別器不僅需要判斷影像的紋理,還需要理解影像和文字之間的匹配程度,這是一項非常困難的任務,尤其是在訓練的早期階段。因此,先前的GAN模型,如GigaGAN,引入了大量的輔助損失來幫助訓練,這使得訓練和調參變得異常困難。然而,UFOGen透過引入重構損失,使GAN在這方面發揮了輔助作用,從而實現了非常穩定的訓練
2. 直接從頭開始訓練GAN 除了不穩定還異常昂貴,尤其是在文生圖這樣需要大量資料和訓練步數的任務下。因為需要同時更新兩組參數,GAN 的訓練比擴散模型來說消耗的時間和記憶體都更大。 UFOGen 的創新設計能從 Stable Diffusion 初始化參數,大大節省了訓練時間。通常收斂只需要幾萬步訓練。
3. 文生圖擴散模型的一大魅力在於能適用於其他任務,包括不需要微調的應用比如圖生圖,已經需要微調的應用例如可控生成。之前的 GAN 模型很難擴展到這些下游任務,因為微調 GAN 一直是個難題。相反,UFOGen 擁有擴散模型的框架,因此能更簡單地應用在這些任務上。下圖展示了 UFOGen 的圖生圖以及可控生成的例子,注意這些生成也只需要一步採樣。

經過實驗表明,UFOGen 只需要一步取樣就能產生高品質、符合文字描述的圖片。與近期提出的針對擴散模型的高速取樣方法(如Instaflow和LCM)相比,UFOGen展現了強烈的競爭力。即使與需要50步驟採樣的Stable Diffusion相比,UFOGen產生的樣本在觀感上也不遜色。以下是一些比較結果:

總結
#Google團隊提出了一個名為UFOGen的強大模型,透過提升現有的擴散模型和GAN的混合模型來實現。這個模型是由Stable Diffusion微調而來的,在確保一步文產生圖的能力的同時,也適用於不同的下游應用。作為早期實現超快速文本到圖像合成的工作之一,UFOGen為高效率生成模型領域開闢了一條新的道路
以上是實現高品質影像產生的新一步:GoogleUFOGen極速取樣方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian系統中,Nginx的訪問日誌和錯誤日誌默認存儲位置如下:訪問日誌(accesslog):/var/log/nginx/access.log錯誤日誌(errorlog):/var/log/nginx/error.log以上路徑是標準DebianNginx安裝的默認配置。如果您在安裝過程中修改過日誌文件存放位置,請檢查您的Nginx配置文件(通常位於/etc/nginx/nginx.conf或/etc/nginx/sites-available/目錄下)。在配置文件中
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian郵件服務器的防火牆是確保服務器安全性的重要步驟。以下是幾種常用的防火牆配置方法,包括iptables和firewalld的使用。使用iptables配置防火牆安裝iptables(如果尚未安裝):sudoapt-getupdatesudoapt-getinstalliptables查看當前iptables規則:sudoiptables-L配置
